AWS Data Pipelineとは
AWS DataPipelineとはデータの移動や変換を自動化できるウェブサービスになります。DataPipelineは保存場所にあるデータに定期的にアクセスし、必要なスケールのリソースを使用して変換と処理を行っていきます。
実際に触ってみる。
それではさっそく触っていきたいと思います。
ロールの作成
まずは二つのロールを作成します。IAMのロールのところからロールの作成を選択し作成します。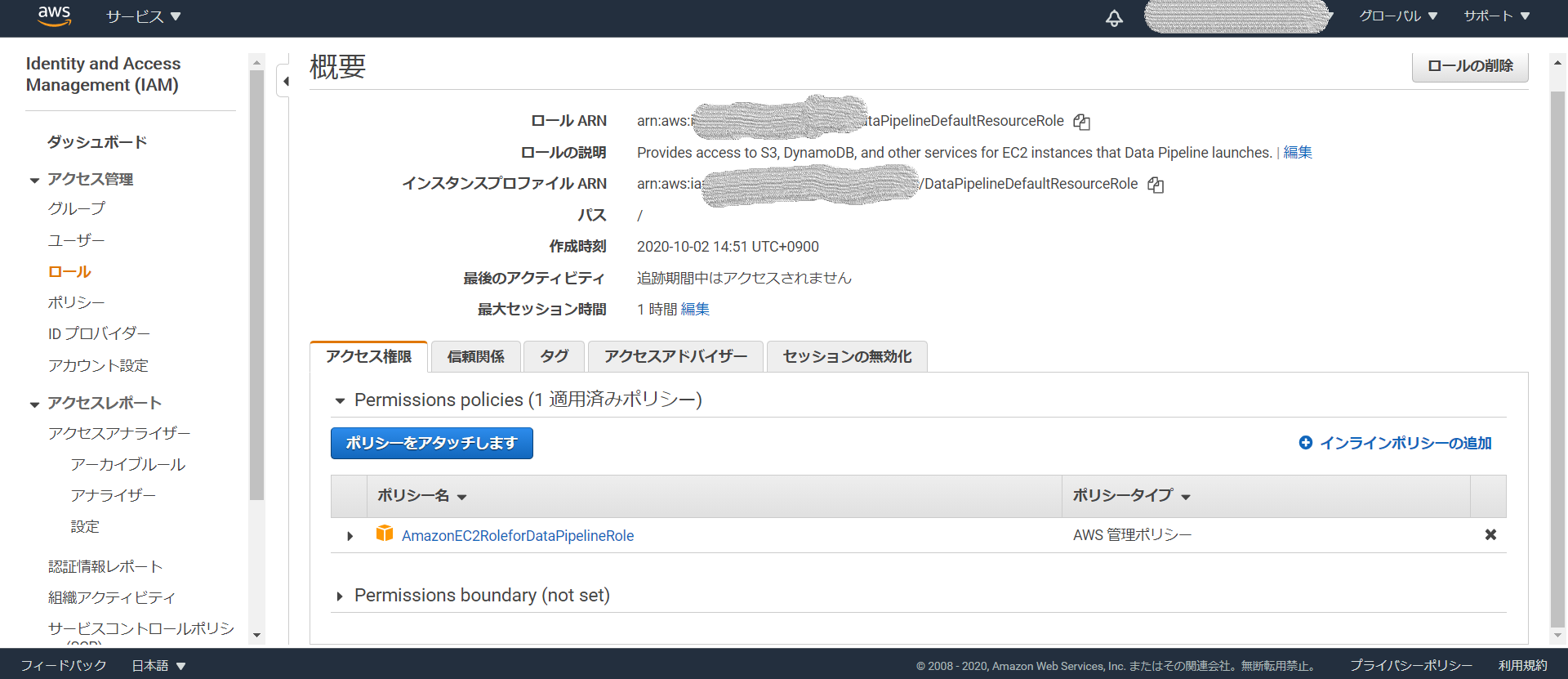

DynamoDB テーブルの作成
DynamoDBに以下のようなテーブルを作成しました。

S3バケットの作成
DynamoDBデータをエクスポートする先になるS3バケットを作成します。

パイプラインの作成
Data Pipelineを作成します。
Name:自分自身で設定
Source:Build using a templateを選択しExport DynamoDB table to S3を選択します
Parameters:ここでDynamoDBにあるS3にExportしたいテーブルを選択し、Export先のS3のフォルダを指定します。DynamoDBのRegionも間違えないように設定をします。

Pipeline configuration:ここでlogを出力するバケットを指定します。

Acitveを行いStatusがFinishedになるまで待ちます。
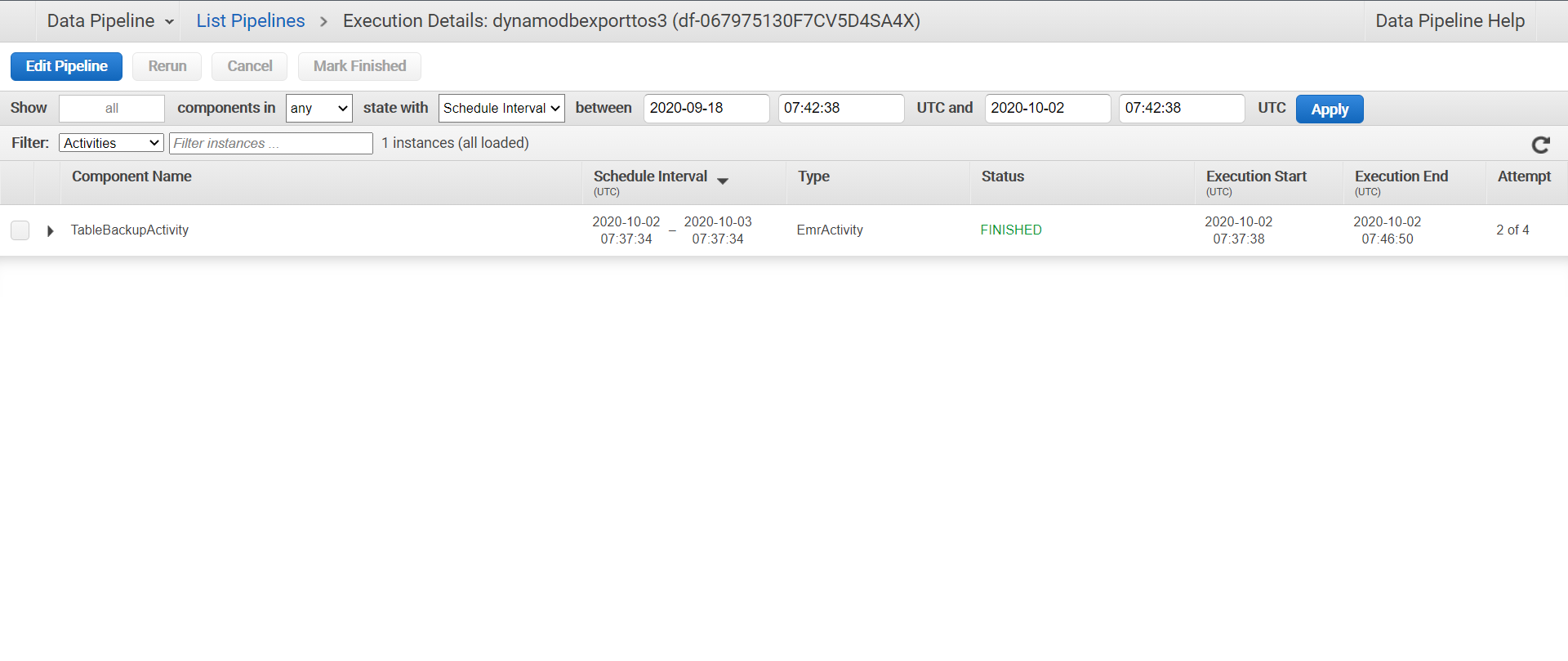
S3にあるか確認する
S3バケットにデータがあるか確認してみます。実際にバケットに移動してみると以下のようなファイルが作成されていました。しっかりとデータが入っているのかを確認するためにエディタで確認してみます
しっかりとデータが入っているのかを確認するためにエディタで確認してみます。そうするとしっかりとデータがS3にエクスポート出来ているのが分かります。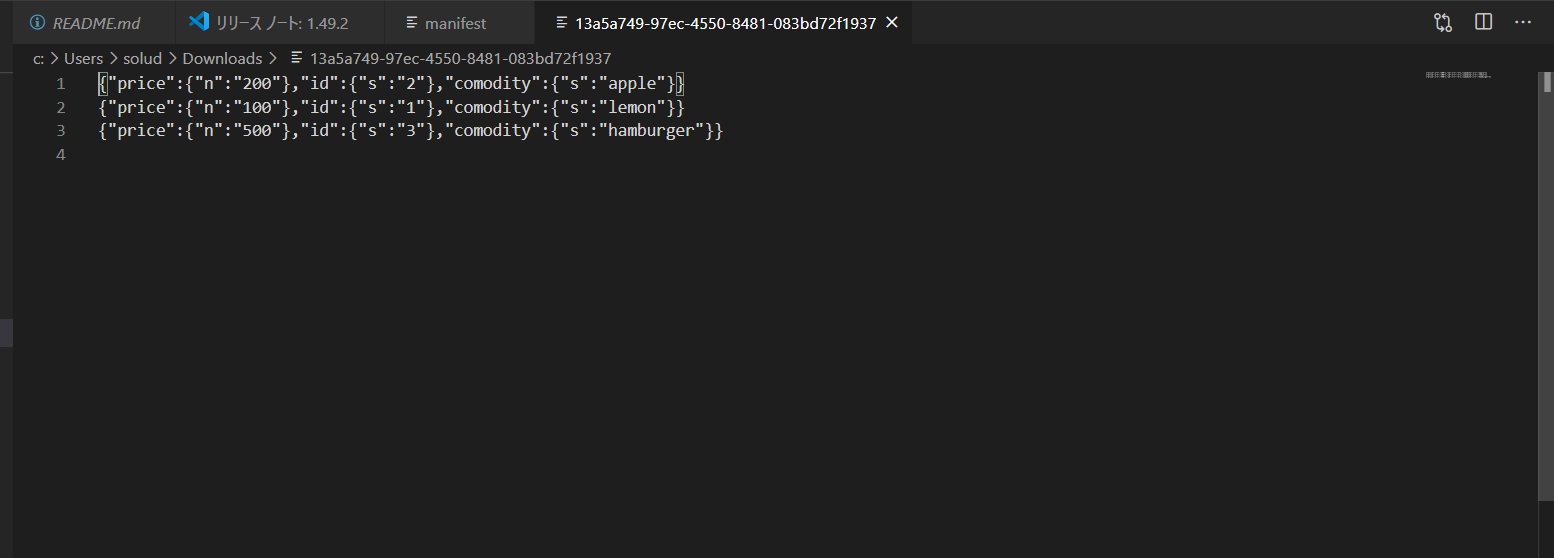
<参考資料>
AWSエンジニア入門:AWS Data Pipelineとは
AWS再入門 AWS Data Pipeline編
AWS Data Pipeline を使用して DynamoDB データをエクスポートおよびインポートする