工作と組織票を見つけ出すことは可能なのか。という疑問。1
原因
【新発見】「最近はいいねの獲得が難しくなっている」は本当か? 〜 Qiitaのいいねを可視化して分かった7つの驚愕 〜 - Qiita#おまけ② 投稿から3分以内のいいね
とコメント
SEO的に優れていて、かつ技術的に参考になる記事であれば最初に注目されなくても長く見てもらえるみたいですね。(中略) 逆にエモい記事になってしまうと最初に注目されるだけで後は全く見られなくなりますね。
を見て、さていいねを記事の質をはかる指標のひとつとして使っていた身としてはどうしたものかと悩みました。
が、いいね時間とユーザーがわかっているのだからそれとなくわかるんじゃないかなとも思いつきました。
コメントにもありますが同Organizationのいいねは個人的に除外したいなと思っていたのでそれもつけます2
動機としては昔かいた
Qiitaの記事でフォロイーのいいねを表示するユーザースクリプト - Qiita
と一緒ですね(コードも借りました)
いいねの中にも、もっと有用ないいねというものがあってそれを可視化できたらいいよね。
スクリーンショット
トレンドにあった記事で見てみると
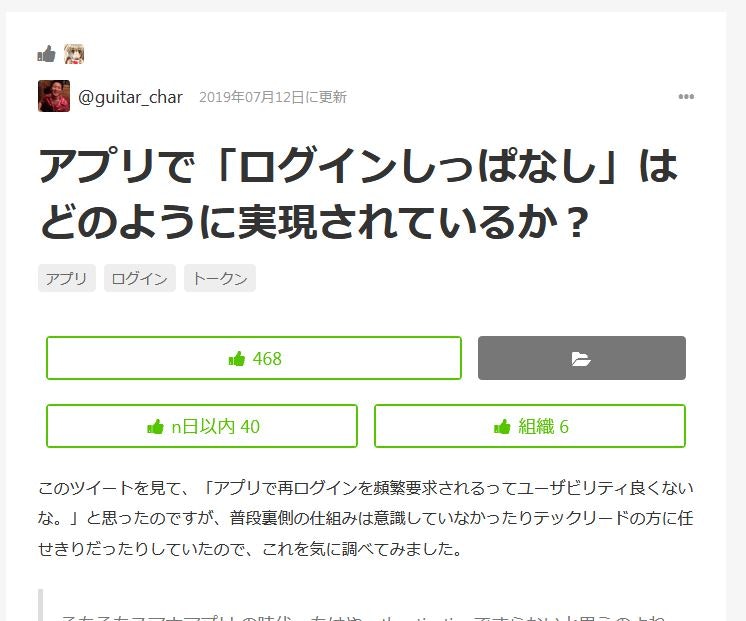
初日に40いいね、全時間を通して6人の同一Organizationの方からいいねをもらっています。となっていたらいいのですが。断言すると怖いので濁します。
コード
// ==UserScript==
// @name Qiita analyze likes
// @namespace http://tampermonkey.net/
// @version 0.1
// @description いいねの選別
// @author khsk
// @match https://qiita.com/*/items/*
// @grant GM_addStyle
// ==/UserScript==
(async function() {
'use strict';
// 記事を一時間にいっぱい見るとリクエスト上限にひっかかるかもしれないので
const token = 'your token'
const item = document.querySelector('section.it-MdContent')
addCSS()
// 記事のいいね取得
const itemId = location.pathname.split('/').pop()
const likes = await fetchAll('https://qiita.com/api/v2/items/' + itemId + '/likes?per_page=100')
// モバイル仕様のいいねボタンをコピー(普段使いがモバイルレイアウトなので…)
// が、非同期なので読み込みタイミングによって失敗。
// mutation監視よりはHTML文字列で対処する ついでにカスタマイズクラス名を追加する
//const likeButton = document.querySelector('.it-ActionsMobile').cloneNode(true)
const likeButton = new DOMParser().parseFromString("<div class=\"AnalyzeLikesActionsMobile it-ActionsMobile it-ActionsMobile-disableSticky\"><div class=\"it-ActionsMobile_like likable\" data-effect=\"solid\" data-offset=\"{'top': 0, 'right': 30}\"><button><span class=\"fa fa-fw fa-thumbs-up\" style=\"margin-right: 4px;\"></span><span>2</span></button></div><div class=\"it-ActionsMobile_stock\"><div class=\"StockButton isNextMobile\"><div class=\"StockButton isNextMobile\"><button><div class=\"StockButton__stock\"><div class=\"fa-stack\"><span class=\"fa fa-folder-open fa-stack-1x unstock\" style=\"font-size: 24px;\"></span></div></div></button></div></div></div></div>"
, "text/html").querySelector('.it-ActionsMobile').cloneNode(true)
likeButton.removeChild(likeButton.querySelector('.it-ActionsMobile_stock'))
// 投稿時刻。おそらく投稿直後はtimeタグ、更新されたらmetaタグになる。
// 更新はdateModifiedなのでitemprop="datePublished"属性だけ見ることにしてみる
// と思ったが、dateが格納されている属性も異なったので結局取得属性は分ける必要あり。(||で対応)
const publishedNode = document.querySelector('[itemprop="datePublished"]')
const publishedDate = new Date(publishedNode.getAttribute('datetime') || publishedNode.content)
// 時刻操作はちょっと一意に値書き換えだけで実現できないかな。変えたい単位で書き換えてもらう
// それかミリ秒指定なら先頭で変数化できるかな?できると思うけど日数計算が面倒
// ひとまずデフォルト例として24時間以内を調べるコード
publishedDate.setDate(publishedDate.getDate() + 1)
// 時間フィルター
// 最初は以後の数を出していたが、結局脳内で差分を取るので以内に変えてみた。本当に怪しいものを検出したいなら1時間とかn分以内に書き換える
// TODO 名前
const nonTrendLikes = likes.filter((like => (new Date(like.created_at)).getTime() < publishedDate.getTime())).length
const nonTrendButton = likeButton.cloneNode(true)
nonTrendButton.querySelector('span:last-child').textContent = 'n日以内 ' + nonTrendLikes // TODO 簡潔な説明。
item.parentElement.insertBefore(nonTrendButton, item)
// 現在時刻からの時間フィルター(~から今までのいいね)
// 後付で追加。新着を追うときに無駄に圧迫しないように投稿時間でも判定する
const recentRangeDate = new Date()
// 例として一年以内を調べる
recentRangeDate.setFullYear(recentRangeDate.getFullYear() - 1)
// 投降時間より昔ならいいね全体を調べることと同義なのでチェックしない
if (recentRangeDate.getTime() > (new Date(publishedNode.getAttribute('datetime') || publishedNode.content)).getTime()) {
const recentLikes = likes.filter(like => (new Date(like.created_at)).getTime() > recentRangeDate.getTime()).length
const recentLikesButton = likeButton.cloneNode(true).firstChild // 枠は追加なので不要。いいねボックスだけ
recentLikesButton.querySelector('span:last-child').textContent = '最近 ' + recentLikes
nonTrendButton.appendChild(recentLikesButton)
}
// 組織票フィルター
// 複数のOrganizationに属することが出来るので
// document.querySelector('.ai-Organization_name')
// ではなく小アイコンから取得
const organizations = document.querySelectorAll('.ai-User_header > span[itemprop="memberOf"] > a')
if (!organizations.length) {
return
}
const members = []
organizations.forEach(async organization => {
Array.prototype.push.apply(members, await fetchMenbers(organization.href + '/members'))
})
const organizationLikes = likes.filter(like => members.includes(like.user.id)).length
const organizationLikesButton = likeButton.cloneNode(true).firstChild // 枠は追加なので不要。いいねボックスだけ
organizationLikesButton.querySelector('span:last-child').textContent = '組織 ' + organizationLikes
nonTrendButton.appendChild(organizationLikesButton)
/////////// 関数宣言
// 表示したいモバイルレイアウトのCSSがwidthで非表示になるが、子要素の親クラス名参照のためにクラス名は残したいので
// 同一値でより優先度の高いカスタムクラスを追加する (要素名追加で優先度ポイントを超えさせる)
async function addCSS() {
/*
.it-ActionsMobile {
display:none
}
@media(max-width:1200px) {
.it-ActionsMobile {
display:flex;
justify-content:space-between;
width:100%;
margin-bottom:24px;
position:-webkit-sticky;
position:sticky;
top:10px;
will-change:transform;
z-index:100
}
}
*/
GM_addStyle(`
div.AnalyzeLikesActionsMobile {
display:flex;
justify-content:space-between;
width:100%;
margin-bottom:24px;
position:-webkit-sticky;
position:sticky;
top:10px;
will-change:transform;
z-index:100
}
}
`)
}
// 昔作ったかコピペった関数を持ってくる https://qiita.com/khsk/items/4ac21bd483b9b2be653a
// 昔は気取ってlinkヘッダーを見てましたけどやっぱり要素数チェックのほうがラクチン
// 数チェックするならpar_pageもちゃんと引数化しないと(レス0チェックだと)無駄リクエストがでるので今回はコピペで済ます
// レスポンスがないとnextがわからないのでオーバーヘッドがだいぶある。
// いいねやフォロイー総数から事前にページ数を計算すれば非同期並列で取得して最後にPromise.allで合算、で高速化できそうなんだけれども、手間がかかる。
// 計算せずとも最初のlinkにラストページが表示されるのでその数までループ、なら総数取得は無しに出来るかも。初回1本+以降並列。
// TODO 進捗表示のためにいちループごとに何か出来るコールバック作るか
async function fetchAll(url, callback = (v) =>{return v}) {
let next = url
let result = []
while (next) {
// 直列で時間がかかるのでinfoだしておく
console.info('取得中…: ' + next)
let response = await fetch(next, {
headers: new Headers({ Authorization: 'Bearer ' + token,}),
})
if (response.ok == false || response.status != 200) {
return result
}
next = li().parse(response.headers.get('Link')).next
let responseData = await response.json()
// ここデフォルト引数付けずに無いならmapしない方が性能いいけど
Array.prototype.push.apply(result, responseData.map(callback))
}
return result
}
/////////// 外部ライブラリ(コピペ)
// MITライセンス表示はこれで大丈夫かしら
/**
* Author : José F. Romaniello <jfromaniello@gmail.com> (http://joseoncode.com)
* License : MIT 2014 - JOSE F. ROMANIELLO https://opensource.org/licenses/mit-license.php
* URL : https://github.com/jfromaniello/li
**/
function li () {
// compile regular expressions ahead of time for efficiency
var relsRegExp = /^;\s*([^"=]+)=(?:"([^"]+)"|([^";,]+)(?:[;,]|$))/;
var keysRegExp = /([^\s]+)/g;
var sourceRegExp = /^<([^>]*)>/;
var delimiterRegExp = /^\s*,\s*/;
return {
parse: function (linksHeader, options) {
var match;
var source;
var rels;
var extended = options && options.extended || false;
var links = [];
while (linksHeader) {
linksHeader = linksHeader.trim();
// Parse `<link>`
source = sourceRegExp.exec(linksHeader);
if (!source) break;
var current = {
link: source[1]
};
// Move cursor
linksHeader = linksHeader.slice(source[0].length);
// Parse `; attr=relation` and `; attr="relation"`
var nextDelimiter = linksHeader.match(delimiterRegExp);
while(linksHeader && (!nextDelimiter || nextDelimiter.index > 0)) {
match = relsRegExp.exec(linksHeader);
if (!match) break;
// Move cursor
linksHeader = linksHeader.slice(match[0].length);
nextDelimiter = linksHeader.match(delimiterRegExp);
if (match[1] === 'rel' || match[1] === 'rev') {
// Add either quoted rel or unquoted rel
rels = (match[2] || match[3]).split(/\s+/);
current[match[1]] = rels;
} else {
current[match[1]] = match[2] || match[3];
}
}
links.push(current);
// Move cursor
linksHeader = linksHeader.replace(delimiterRegExp, '');
}
if (!extended) {
return links.reduce(function(result, currentLink) {
if (currentLink.rel) {
currentLink.rel.forEach(function(rel) {
result[rel] = currentLink.link;
});
}
return result;
}, {});
}
return links;
},
stringify: function (headerObject, callback) {
var result = "";
for (var x in headerObject) {
result += '<' + headerObject[x] + '>; rel="' + x + '", ';
}
result = result.substring(0, result.length - 2);
return result;
}
};
}
// https://qiita.com/organizations/*/members を走査
async function fetchMenbers(url, callback = (v) =>{return v}) {
console.info('取得中…: ' + url)
// 最大数はわからないが、107人のゆめみでアイコン表示で全員出ているっぽいのでページ遷移せずここから取る
const response = await fetch(url)
if (response.ok == false || response.status != 200) {
return []
}
// https://tech-1natsu.hatenablog.com/entry/2017/12/09/010811
const page = await response.text().then(text => new DOMParser().parseFromString(text, "text/html"))
// https://blog.sushi.money/entry/2017/04/19/114028
const users = Array.from(page.querySelectorAll('.op-Members a'), a => a.href.split('/').pop())
return users
}
///////////////
})();
前述の記事やコメントのとおり、チェックする時間をたとえば3分以内にすると、「読んでないのにされたいいね」扱いにできたり、
逆に1年と長くとると
差分が多いほど「実用的な記事」(継続的にいいねされ続けている)、
差分が少ないほど「エモい記事」。
と言えたりするんじゃないかなと考えていました。
「一定時間内の同一Organization」ではないです。それは要らないかな?
最近のいいねも計算する
ここまで、この後を含むこの項以外の記事を書き上げ振り返ってみると、
ちょっと後ろ向き過ぎないかなと思いました。
これでは自分すら常用するか怪しかったので、もう少し有用な道を探りました。
そこで追加したのが「最近のいいね数」です。
私は知らない新しいことを調べるときは、古い情報をはじくためにGoogle検索の「期間指定」で「1年以内」をよく使います。
また、Qiita内のたくさんいいねがある古い記事に対して、「今でも通用する内容なのかな?」と悩んだりもします。
そこで、投稿後ではなく今から見て一定時間内のいいねをとってみることにしました。
サンプルとして…なにがいいかわからないのですが、
CoffeeScriptというaltJSの記事を見てみます。
(私は当時、ES2015以前のJSと比較してCoffeeScriptに好印象を抱いていたのでとてもdisれませんが)
CoffeeScriptは今現在廃れたという声を目にするものと思っていただければ。
そんなタグのストック数第二位の記事を見ます。
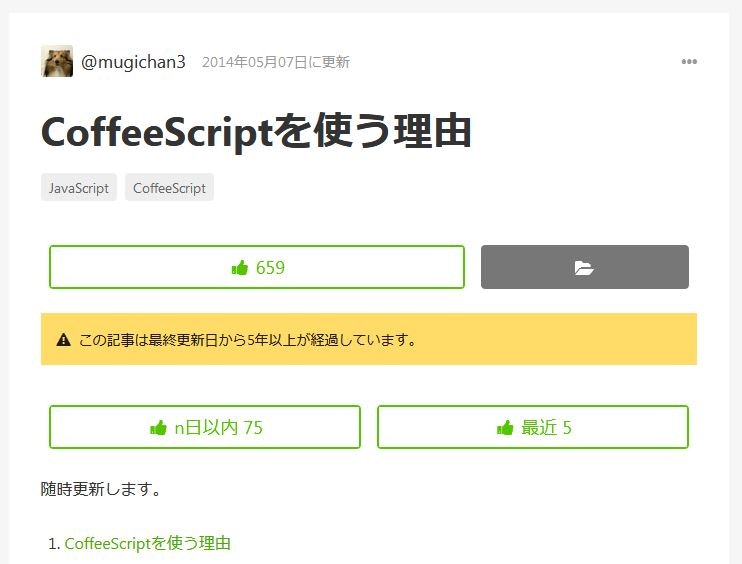
全体では650いいねありますが、ここ一年では5いいねしかありません。
こうみるとちょっと怪しいのですぐには飛びつかず、CoffeeScriptについてもう少し調べてみるか、となるかもしれませんね。
他に汎用そうな例として、bashタグのストック一位も見てますと
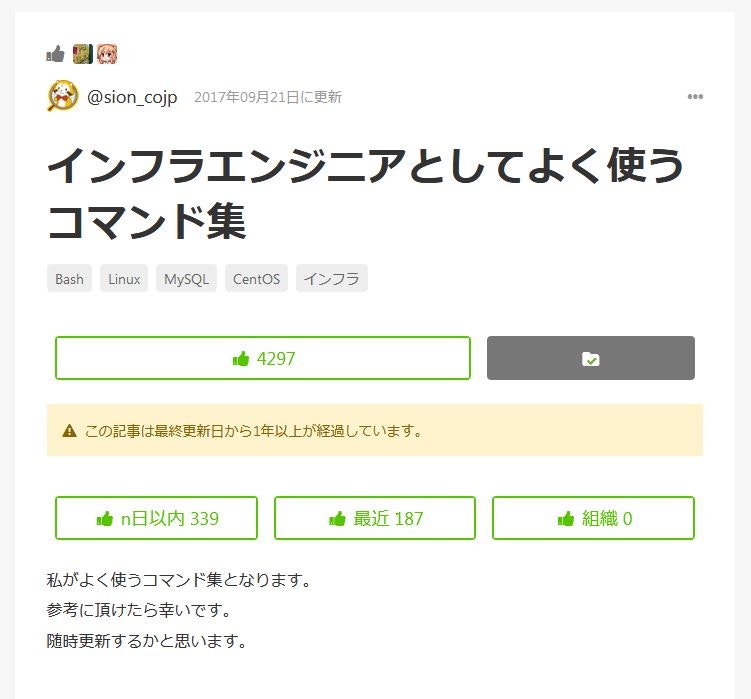
2014年投稿、2017年更新でも過去一年で187いいねを集めています。
これならば少なくとも2018年でも通用していた、と見ることができるかもしれません。
…ただしこのいいね数になるといいね収集に43リクエストが発生するので読んだほうがはやいかもしれません。
トレンドをあさるなど流行を追うためには役に立ちませんが、困りごとがあって本当にQiitaに技術的記事を求めているときには役に立つんじゃないかな立って欲しいなと思います。
そういえば、古い記事警告追加のときに、ただ古いだけで警告を出して欲しくないという意見も見た記憶があるので、古いけれど有用な記事の見つけ方はもっと工夫できるかもしれませんね。
organizationの怪
下記のコードコメントにめっちゃ書いていますが、簡潔に。
APIで取得できるユーザー情報のorganizationは
「公開用プロフィール」の「所属している組織・会社」の値でQiitaのグループとしてのOrganizationとは無関係。
QiitaのグループとしてのどのOrganizationに所属しているかはユーザー情報APIからはおそらく判別不能。
また、QiitaのグループとしてのOrganizationの情報を取得するAPIもない。
ということで、最初はlikesにくっついているuserのorganizationをつき合わせていたんですが、どうみても同一Organizationなのにカウントされなかったり、
そもそも所属しているのにorganizationが空ということが頻発して頭を悩ませました。
調査した結果、APIのorganizationはGitHubでいうところのCompanyらしいということが判明。ややこしい!!
結局
https://qiita.com/organizations/*/members
から引っ張ってくる形になりました。
ただし、ユーザーページのurlからユーザーIDを取ってるので、記号あたりでなにか見落としがあるかもしれません。
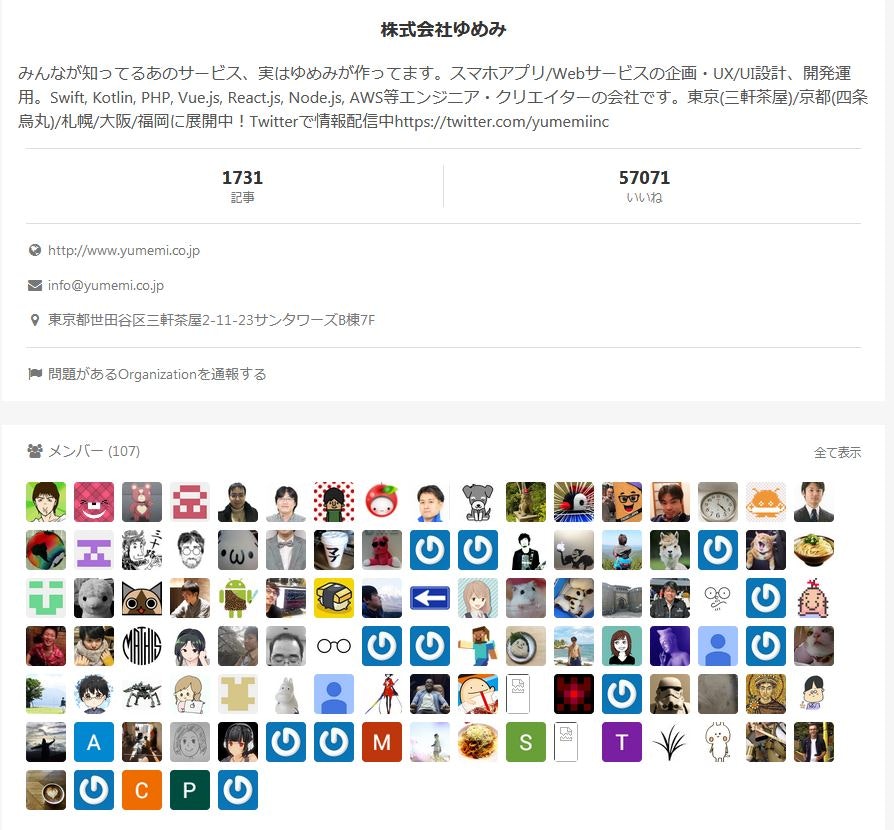
このアイコンリンクから取得しています。
不採用コード
const organization = document.querySelector('.ai-Organization_name').textContent
//console.log('organization',organization)
// ~~たぶん、いいね当時の所属。あとから入った場合のorganizationは反映されないっぽい?~~
// ~~例: https://qiita.com/ihcamonoihS/items/fc8487d55a4feefa5dba/likers "user":{"description":"I’m the coder.(意:私はザコーダーです。)","facebook_id":"","followees_count":449,"followers_count":2012,"github_login_name":"jzmstrjp","id":"Yametaro","items_count":34,"linkedin_id":"","location":"","name":"無職 やめ太郎(本名)","organization":"","permanent_id":295452,"profile_image_url":"https://qiita-image-store.s3.amazonaws.com/0/295452/profile-images/1554676443","team_only":false,"twitter_screen_name":"Yametaro1983","website_url":"https://jzmstrjp.netlify.com"}~
// かと思っていたが、そうでもなさそう。
// https://qiita.com/api/v2/users/ikasama
// https://qiita.com/api/v2/users/Yametaro
// https://qiita.com/api/v2/docs#%E3%83%A6%E3%83%BC%E3%82%B6
//organization
// 所属している組織
// Example: "Increments Inc"
// Type: null, string
// 他の組織でも起きているので、反映に時間がかかる? https://qiita.com/api/v2/users/afadhli
// いや、かなり広範囲におきている。 設定されているほうがまれかも。
// グループ上は同一organizationでも表示名が違うorz
// https://qiita.com/api/v2/users/koji_magi 株式会社インフィニットループ
// https://qiita.com/api/v2/users/sj-i 株式会社インフィニットループ仙台支社
// ~~organizationに加盟したうえで、自分で任意(初期空)のorganizationプロフィールを入力するのかな?~~
// https://qiita.com/mpyw
// ~~そのようだ。そもそも複数のorganizationに参加できるのにstringな時点で…~~
// ということでorganizationのルールとして「この値をプロフィールに入れてね」とされていないと機能しないので簡易版とします。
// **というかOrganization設定ではなく公開用プロフィールの「所属している組織・会社」欄でした。**
// 正しくやるなら、投稿者のorganization取得
// APIがないのでorganizationのWebページからメンバー一覧をスクレイピング
// いいねユーザーと突合せ (面倒…)
// https://qiita.com/organizations/yumemi/members ページングorz
// さすがに常用には向かない処理量なので見送るか…監視用としてWebアプリとして公開すればいいんじゃないでしょうか
// cheerioとかがないとしんどそう
const organizationLikes = likes.filter(like => like.user.organization == organization).length
const organizationLikesButton = likeButton.cloneNode(true).firstChild // 枠は追加なので不要。いいねボックスだけ
organizationLikesButton.querySelector('span:last-child').textContent = '(簡易版)組織 ' + organizationLikes
nonTrendButton.appendChild(organizationLikesButton)
参考
JavaScriptのFetch APIで返ってきたものをDOMとして扱う - ひと夏の技術
ブラウザJSからスクレイピングとはどうするんだ…と悩んでいたので助かりました。
OrganizationとOrganizationsでタグが分散しているので組織にしておこうかな…
いくつかのOrganizationの新着記事で動作テストしていた中ではOrganizationに関してはそんなに露骨~なものはないのかなという印象でした。
偶然見つけられてせいぜい5いいねぐらいでしょうか。
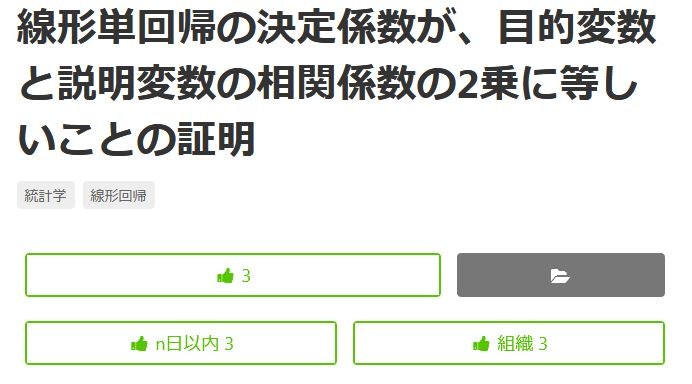
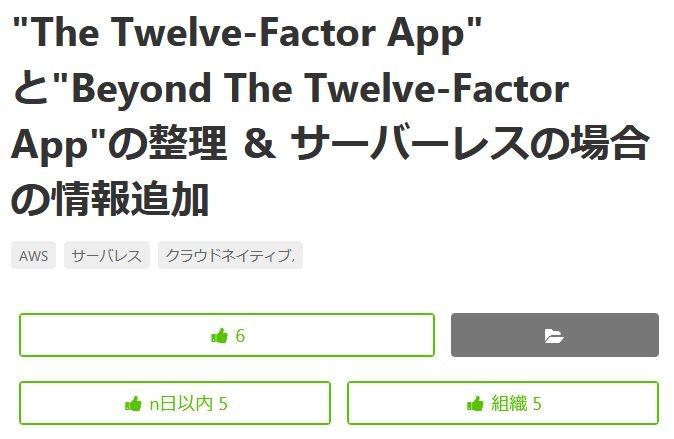
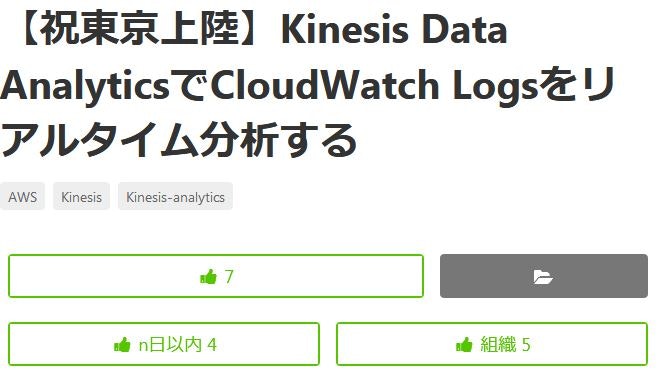
同じ仕事をしているので当然参考になって「いいね」となりますし悪い「いいね」でもないです。
ただ、Organizationの9割の投稿に最低1いいねがついていたりするので組織内に一人でもよくいいねする「いいな~」が居るとそれがOrganization全体の振る舞いとして受け取ってしまいかねないかもしれません。
それでも上記例の5という数字は全メンバーの半数以下ですし、そもそも活動量ランキングを見てみてもメンバー数が20を超えるOrganizationは少ないですし…
投稿直後の数いいねが大事だということは肌感覚でもわかりますが、質の指標としてはどこまで勘案するべきか…
こんなわけ方で逆に変に自分の中の誤解を助長してしまう可能性もあるなと思いましたので、この機能を使うにしてもよく考えて自制しないとなと思いました。
私はどうしても邪推してしまう人間なので、
いいね通知はもらえる。
Contributionも増える。
けど記事のいいねには含まれない。
ぐらいが書くほうも見るほうもいいねするほうも気軽になるんじゃないかなあと愚考しました。