Apache Sparkを使ってKey/ValueペアのRDDの集計をやってみました。
Hadoopでやっているようなmap, reduceの処理と同じです。
やったこと
Hadoop MapReduceアプリの勉強のときに、Hadoopを用いて米国気候データセンター(NCDC)のデータを元に各年の最高気温を求めてみたのですが、これをSparkでやってみました。
試す前に調べたこと
- Apache Sparkの概要調査とQuickStartやってみたでやった内容
- Sparkの処理はDriverプログラム一つと、複数のWorkerノードによって実行される
Driverプログラムがマスターノード的な役割。
ローカルモードの際は全てローカルマシンで1スレッドで実行される。 - RDDへの操作には二種類ある
- Transformation
あるRDDから別のRDDを作る操作。filterやmapなど。 - Action
各ノードで集計した結果をDriverプログラムに返したり、ファイルとして保存する操作。countやreduceなど。
- Transformation
- Transformationの処理はWorkerノードによって並列実行される
- Transformationは遅延評価される
つまり、RDDに対するTransformationの処理はActionが実行されるまで実行されない。
実行される際は複数のTransformationの処理が最適化されて実行されるらしく、DriverプログラムとWorkerノードのデータのやりとりを減らす仕組みのよう。 - ペアRDD
Key/ValueのMapになったRDDのこと
データフローの設計
ちょっと大げさですがデータパイプラインの流れをデータフローにしてみました。
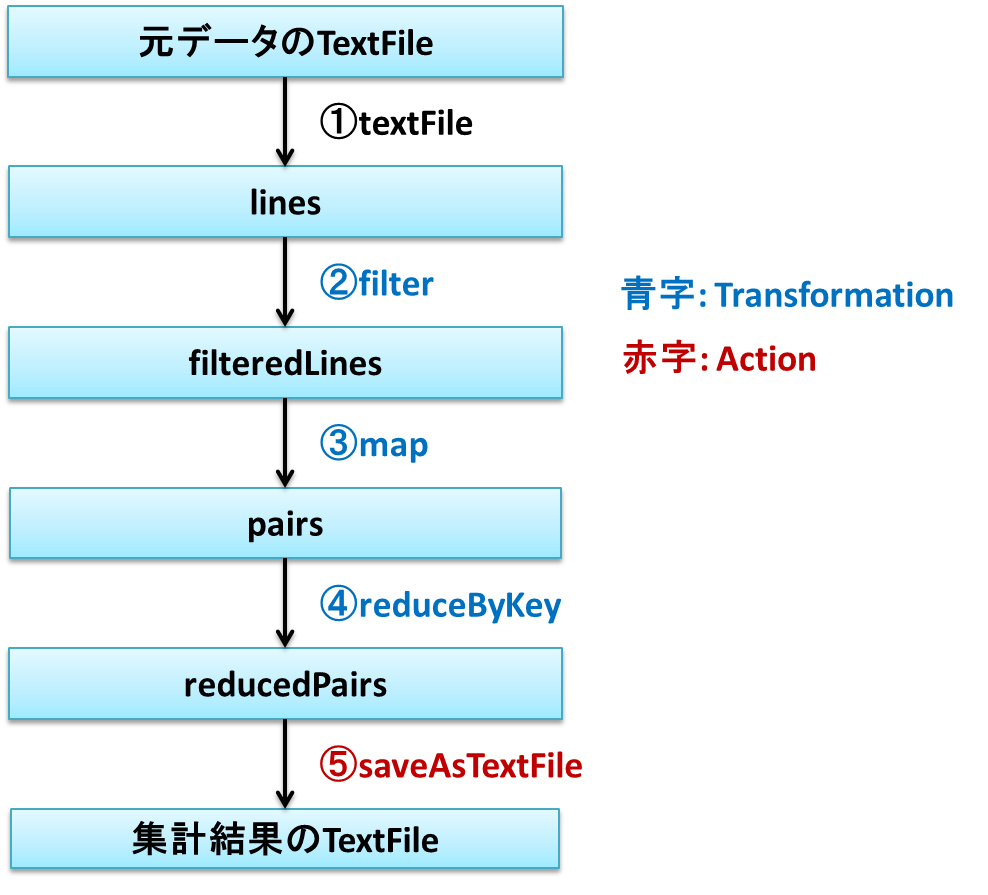
-
textFile
米国気候データセンター(NCDC)からダウンロードしたデータを読み込みます。
sc.textFileメソッドを使い、引数にはファイルのディレクトリを指定します。そうするとディレクトリ内の全てのファイルを読みこんでくれます。
読みこんだデータはラインごとに区切られたRDDになります。 -
filter
1ラインのフォーマットは下記のようになっています。 16文字から19文字目までが年、88文字から92文字までが気温を示しています。
0037010010999991937010106004+70983-008300FM-12+002399999V0203201N00461220001CN0500001N9-01001+99999098941ADDAY111999GF104991011011008001031999
気温が無い場合があるので、それをfilterでRDDから除去します。無い場合は+9999になるので、それを元に判断します。 -
map
Keyに年、Valueに温度としたmapを作ります。 -
reduceByKey
Keyごとに集計します。Keyごとに最も気温が高いもののみ残します。 -
saveAsTextFile
RDDをTextFileに保存します。
環境
試した環境は以下のとおりです。
| 環境 | バージョンなど |
|---|---|
| OS | Ubuntu(14.04.2) |
| Java | 1.8.0_25 |
| Scala | 2.11.7 |
| Gradle | 2.5 |
| Maven | 3.2.3 |
| Spark | 1.4.1 |
SparkをUbuntuにインストール(簡単に。。。)
- 下記からtgzファイルをダウンロードして、好きな所で解凍
http://spark.apache.org/downloads.html - 解凍したディレクトリ内で下記を実行
mvn -DskipTests clean package - 解凍したディレクトリ/binを環境変数PATHに通す
これでspark-shell等実行できるようになります。
実装
下記のようになりました。すごくシンプルです。
第一引数に入力ファイルのディレクトリのパス、第二引数に出力ファイルのディレクトリのパスを指定します。
※プログラム引数のチェックなど省いています。
sample/PairRDDSample.scala
package sample
import org.apache.spark.{SparkContext, SparkConf}
object PairRDDSample {
private val YEAR_BEGIN = 15
private val YEAR_END = 19
private val TEMP_BEGIN = 87
private val TEMP_END = 92
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("spark-standalone-sample")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0)).cache()
val filteredLines = lines.filter {
line => !line.substring(TEMP_BEGIN, TEMP_END).contains("+9999")}
val pairs = filteredLines.map(line =>
(line.substring(YEAR_BEGIN, YEAR_END),
line.substring(TEMP_BEGIN, TEMP_END)))
val reducedPairs = pairs.reduceByKey((x, y) => if (x.toInt >= y.toInt) x else y)
reducedPairs.saveAsTextFile(args(1))
}
}
出力結果の例は下記です。
part-00000
(1937,+0200)
このプログラムを実行すると、正しい結果を得ることが出来ました。
ちなみに、Transformationの処理に.cache()をつけると、結果がキャッシュされ別の計算に使いまわすことができます。
実際に手元で実行する場合は下記のようにGitHubからソースを取得し実行すればOKです。
$ git clone git@github.com:khiraiwa/spark-learning.git
$ cd spark-learning/spark-standalone-sample
$ gradle shadowJar
$ spark-submit --class sample.PairRDDSample build/libs/spark-standalone-sample-0.1-all.jar [入力ファイルのディレクトリ] [出力ファイルのディレクトリ]
追記
Inputがgzのような圧縮ファイルの場合、1ファイルごとに1パーティションが作られるようで、Outputについてもpart-00000,part-00001,...とパーティションごとにファイル出力されていました。
Apache Spark を使ってアクセスログを解析して、その結果をCSVファイルに出力してみた。を見ると、最後にrepartition(1)を実行すればよいとのこと。
そこで、最後の行を下記のように変更すれば1ファイルにすべての結果が出力されました。
reducedPairs.repartition(1).saveAsTextFile(args(1))