1. はじめに
ChatGPT-4 を先生として、以下のような記事を書きつつ1年ほど強化学習を学んできましたが、最後に運よく強化学習コンペ(第3回 空戦AIチャレンジ)で金メダル(5位)を取ることができました!
記事を書こうと下書きしたまま、かれこれ1年が経ってしまいました。今更感はありますが、当時のコンペ内容を振り返りながらレポしていきたいと思います。
本コンペの課題である空戦シミュレーションの動画はこちらです!

本記事では専門的な解説はそこそこに、強化学習コンペの雰囲気を動画とともにお伝えしたいと思います!
2. コンペ概要
2.1. 空戦コンペのルール概要
コンペでは以下のような対戦を行います(冒頭の動画を併せてご確認ください)。
-
対戦形式
- 2vs2で戦います。本記事では赤が自軍、青を敵軍として表現しています。
- 冒頭の動画の対戦相手である青の Rule-Fixedと記載されている機体は,サンプルとして提供されているルールベースのモデル(強化学習モデルではなく、ある制御アルゴリズムで作られたプログラム)です。
-
誘導弾について
- 機体の横に記載されている
vが機体速度、mが誘導弾の弾数で誘導弾は全部で4発打つことができます。 - 誘導弾を発射した後、黄色線は追尾中の誘導弾の位置を、ピンク・水色線は追尾に失敗した(ロストした)誘導弾を表しています。
- 機体から出ている薄い扇型の範囲が射撃可能エリアとなります。
- 機体の横に記載されている
自機が撃墜されたり、画面外に押し出された場合はペナルティが課されます。そのため自機は、敵機を射撃可能な範囲に誘導して誘導弾を発射するタイミングを狙いつつ、同時に敵の誘導弾からの被弾を回避するように動く必要があります。
2.2. サンプルコード
本コンペでは、主催者様からあらかじめ以下の強化学習フレームワークを利用したサンプルコードと、その使い方を説明したマニュアルが配布されました。
- HandyRL
- ray RLlib
Dockerを使った環境構築方法や、サンプルコードのカスタマイズ方法も丁寧に記載されていて、(読むのは大変ですが)初心者でもスムーズに開始することができました。
私の場合は、自力で強化学習アルゴリズムを組むほどの力がなかったため、提供されたHandyRLサンプルコードを改修する形で作業を行いました。
2.3. 学習環境
コンペに使用した PC のスペックは以下の通りです。
- OS: Windows 11(WSL2 と Docker を利用)
- CPU: Core i7-13700
-
GPU: RTX4070Ti
※使用したアルゴリズムでは学習時に GPU は利用しませんでした。 - メモリ: 64GB
コンペ期間中はCPUのコアをすべて使って並列シミュレーションを行っていました。CPUはできるだけ速く、コアの多いものを使った方がいいと思います。
3. Agent1の作成
3.1. Rewardsの変更
強化学習用に事前にPCの更新を行ったのですが、それでも1回の学習に3~5日かかるため、学習効率を向上させるために、過去に学習で得られた良好なエージェントの重みを次回学習の初期値として使用する方法を採用しました。
5回目の学習を終えた後のモデルを使った対戦動画は以下になります。

(赤が自軍です。あっさり撃墜されています)
動画冒頭でRed1号機がどこかに行ってしまっていますが、この段階では不可解な動きをすることが多いです。敵機を撃墜するシーンはたまにあるのですが、敵機に突っ込みそのまま自機も撃墜されるということがよくありました。
初期のエージェントは回避行動が非常に弱く、回避に対する報酬を加えても、逆に無駄な旋回運動が増えるなど、効果的な調整が難しかったため、最終的には墜落や撃墜時のペナルティを強化する方向に絞って調整を行いました。
3.2. 学習アルゴリズムの変更
サンプルコードの学習アルゴリズムやパラメータ設定は、R2D2(Recurrent Experience Replay in Distributed Reinforcement Learning)の手法を参考にしているように感じたため、R2D2をベースとした改良を追加しました。
変更点
- R2D2の論文では
gamma=0.997が使用されていたため、gammaの値を大きくなるように調整しました。 - PER (Prioritized Experience Replay) を追加しました。
- R2D2はこちらのリポジトリ horoiwa/deep_reinforcement_learning_gallery を参考にさせていただきました。
これらの変更内容はChatGPTにコードを見せて、議論しながら決定しました。もちろんコードの変更も手伝ってもらっています。
3.3. Agent1の評価
Agent1の学習過程におけるRatingの推移が以下になります(このRatingは、学習中に対戦した相手との勝ち負けから計算されます)。Agent1学習時は、対戦相手としてサンプルで提供されているRule-Random を使用しました。
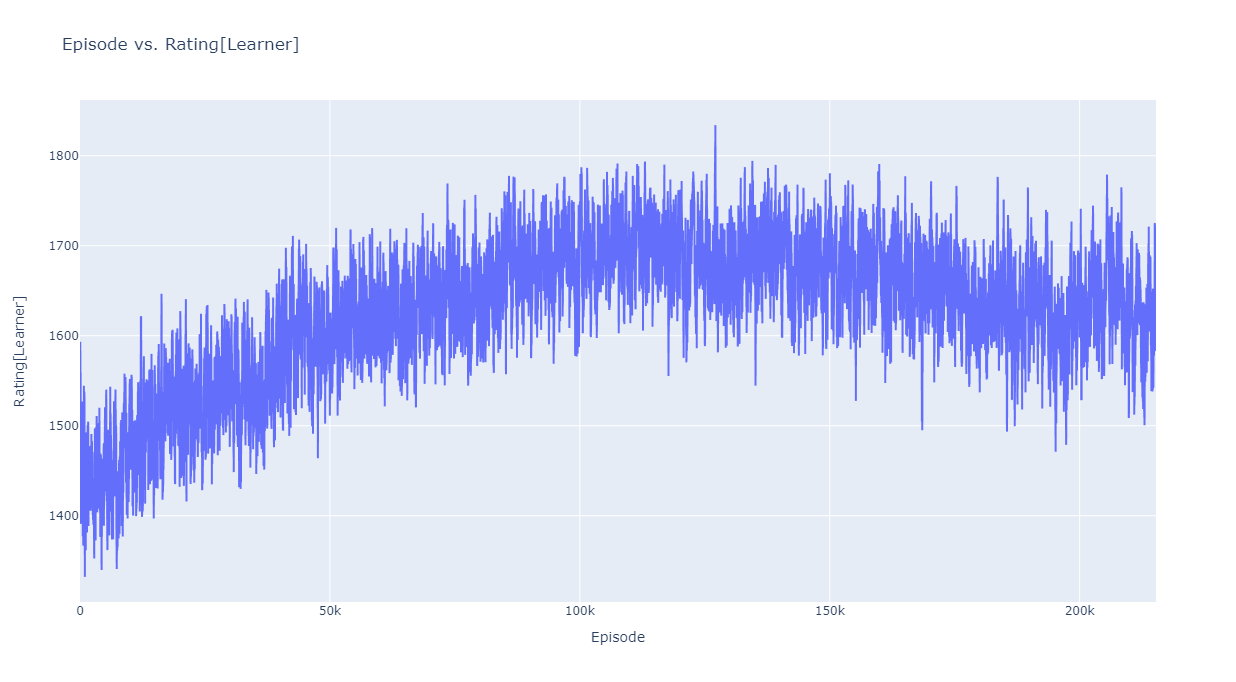
合計で68時間、21万エピソードの学習を実施し、約15万エピソードあたりのエージェントを採用しました。
対戦動画はこちらです。

先に紹介した学習5回目のエージェントと比較すると、かなりちゃんとした、敵機を追い詰めるような行動を取るようになりました!
4. 最終エージェントの作成と評価
4.1. 初期対戦相手の追加
Agent1は、学習時の対戦相手としてRule-Random(各パラメータがランダムに決まるエージェント)を使用していたため、Rule-Randomには強い一方で、パラメータが良い値に固定されたRule-Fixedにはあまり勝てませんでした。
それぞれ100回戦ってみた結果は以下の通りです。
| opponent | Wins | Losses | Draws |
|---|---|---|---|
| Rule-Random | 72 | 17 | 11 |
| Rule-Fixed | 57 | 26 | 17 |
そこで、以降の学習では、初期相手として Rule-Fixed と先ほどの Agent1 (およびそれ以降に得られた強いエージェント)を追加して学習するようにしました。
4.2. 学習アルゴリズムの変更2
3.2.項でアルゴリズムの変更を行いましたが、さらに追加で以下の変更を行いました。
変更点
- 初期対戦相手を追加しても、Agent1よりも強いエージェントが得られなかったため、より多くの過去情報を活用できるようにするため、LSTMのサイズを256から512に拡大しました。
- この変更で、PCのメモリが不足するようになったので買いに走りました。
- 加えてR2D2に実装されていた再スケーリング関数(rescaling function)を組み込むようにしました。
こちらもChatGPTの力を借りて、サンプルコードの改修を行いました。
4.3. Agent2, Agent3の学習時のログ
LSTMのサイズを大きくしたことで学習の進み方が遅くなったため、学習時間も倍に増やしました。最後のAgentの学習にかかった時間は 143時間 42万エピソードで、採用したは30万エピソード付近です。
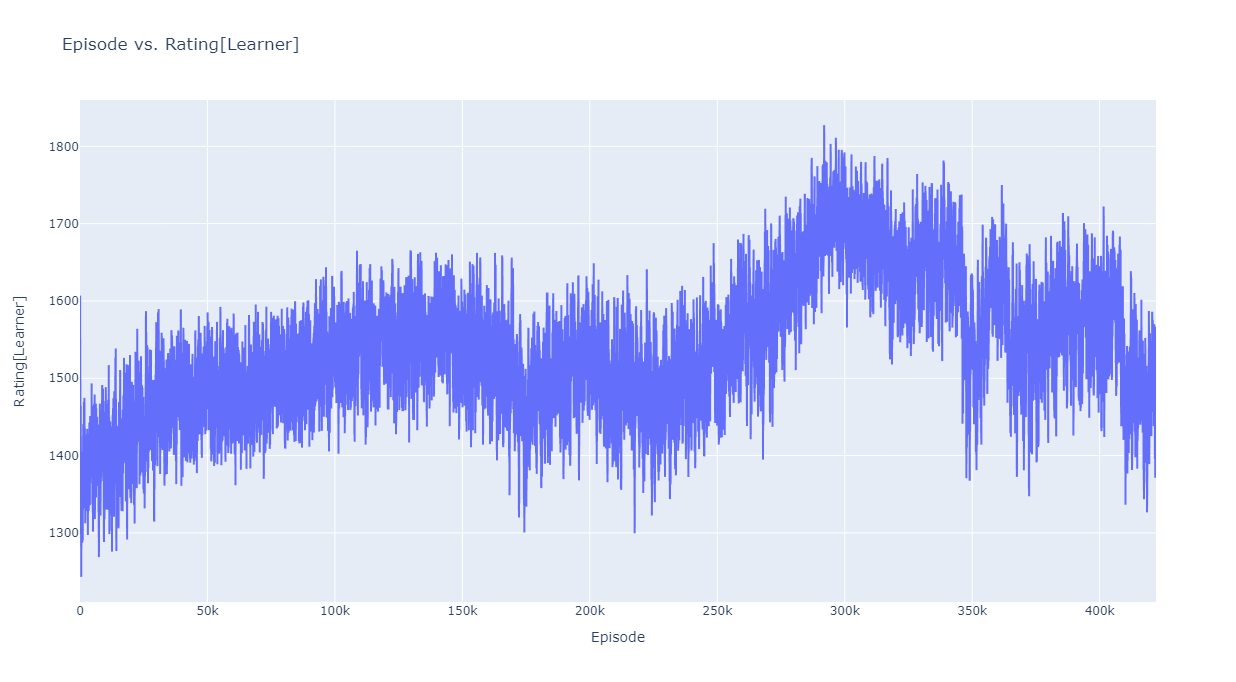
コンペ終了の1週間前、29万エピソード付近から驚くほど学習がうまく進みました。最後は運が良かったと思います。
学習中の1000エピソードごとに異なるモデルが保存されるため、最終的に投稿するエージェントは、お互いを戦わせて最も勝率が高いものから選択しました。
1位がAgent3, 2位がAgent2で、それがそのまま最終スコアに反映されています。
今回最もスコアの良かったAgent3で、それぞれ100回戦った結果は以下の通りです。Agent1の時よりも大幅に性能が向上しました。
| opponent | Wins | Losses | Draws |
|---|---|---|---|
| Rule-Random | 90 | 5 | 5 |
| Rule-Fixed | 87 | 9 | 4 |
| Agent1 | 81 | 14 | 5 |

Agent1と比較して、2機がお互いの動きをカバーするような動きを取ることが増えたように思います。
4.4. 最終戦績について
本コンペでは、締め切り後に参加者全員の機体で最終評価(対戦)を実施しました。私が提出した各エージェントの最終戦績は以下の通りです。
| ファイル名 | スコア | 対戦回数 | 対戦成績 |
|---|---|---|---|
| Agent1 | 1,718.96 | 600 | 405勝 130負 65分 |
| Agent2 | 1,804.55 | 600 | 462勝 89負 49分 |
| Agent3 | 1,819.05 | 600 | 469勝 83負 48分 |
機械学習コンペでよく遭遇するどんでん返しはなく、最終評価前のリーダーボードとそこまで大きな変動はありませんでした。
Agent1でも十分勝てていますが、金メダルにはAgent2以上の力が必要だったので、最終調整がうまくいって嬉しかったです。
本コンペですが、1位の方は強化学習ではなくルールベースだったそうです。
全戦全勝で、誰も勝つことができませんでした!
5. 振り返り
- 私の使用したアルゴリズムでは学習にすごく時間がかかりましたが、もしかするとちょっとした工夫で学習速度を上げることができたかもしれません。
- 自機の悪い動きを見つけても、強化学習では直接手を当てる方法がよくわかりませんでした。日々の対戦ログの結果から、直接改良できるのがルールベースの強みかもしれません。
- PCが24hフル稼働していたので部屋が暖かったです。
- 当時はo1やo3がまだなかったので、GPT4と試行錯誤しながら進めましたが、今ならもっとよい改善方法が見つかるかも...
強化学習を1年学習してみて、強化学習の難しさを実感しつつも、雰囲気くらいは語れるくらいには成長できました!
ChatGPTのおかげです。みなさんも遊んでみてね。