Apache FlumeやApache Kafkaはリアルタイムなイベント処理のバックエンドとして広く利用されています。これら2つのシステムは似ている部分もありますが、ユースケースによりどちらか一方、あるいは量を組み合わせて使う場合もあります。
FlumeとKafkaの違いは次のブログも参考になります。
https://www.linkedin.com/pulse/flume-kafka-real-time-event-processing-lan-jiang
Apache Kafka
Apache Kafkaはpub-sub、出版-購読型のシステムで、多数のシステムとの連携に広く利用されています。

[画像はhttps://kafka.apache.org/より引用]
しかし、Kafkaを使う場合、一般的にプロデューサやコンシューマのためのコードを記述する必要があります。
- Producerのコードの例 (https://github.com/bkimminich/apache-kafka-book-examples/blob/master/src/test/kafka/SimpleProducer.java)
- Consumerのコードの例
(https://github.com/bkimminich/apache-kafka-book-examples/tree/master/src/test/kafka/consumer)
kafka-topics.shやkafka-console-producer.shのようなユーティリティコマンドを使用してコマンドラインからKafkaを利用することもできますが、都度コマンドを叩くのは難しいですし、アプリケーションと連携する場合はコードを記述することになるでしょう。
しかし、Flafkaを使えば、コードを記述することなくKafkaと連携することができます。
Flafkaとは?
FlafkaはFlumeとKafka連携の俗名(?)です。KafkaをFlumeのソース(入力)やシンク(出力)、またはチャンネル(バッファ)として利用することができます。つまり、FlumeのプロパティファイルにKafkaの設定を行うだけで、コードを利用せずに連携できるということです。とっても簡単。
2016/10/25補足: 下記はFlume 1.6での設定です。Flume1.7ではKafka 0.9対応のため、プロパティの記述方法が変更されています。1
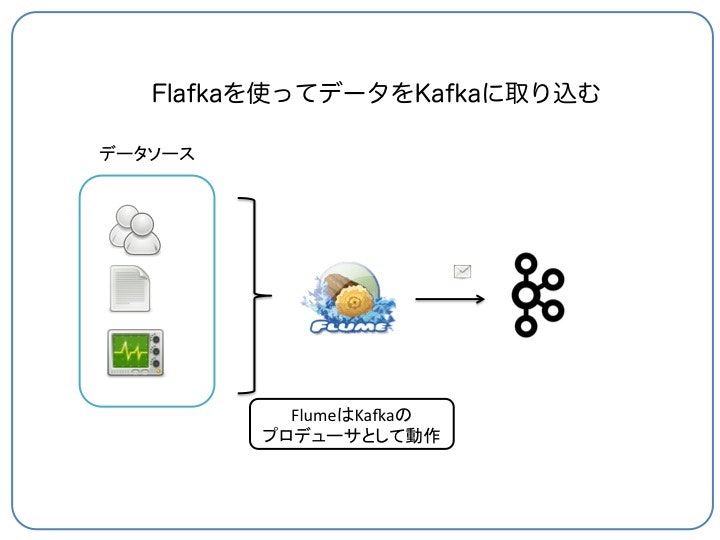
Kafkaのトピックにデータを書き出す (Kafka Sink)
Flumeのさまざまなデータソース(ファイルのtail、あるディレクトリに出力されたファイル、twitterなど)をKafkaに取り込む例です。Flumeのデータソースやシンクの細かい設定はユーザーガイドを参照
https://flume.apache.org/FlumeUserGuide.html
Kafka Sinkの設定ファイル
FlumeのspoolDirを使うとディレクトリを監視して、このディレクトリに追加されたファイルの内容を1行毎にレコードとして取り込みます。また、シンクの設定でKafkaのトピックを指定しています。
- 監視ディレクトリ: /flume/weblogs
- Kafkaのトピック: eventtopic
この場合の設定ファイル(spooldir_sample.conf)は以下のようになります。
# エージェントのコンポートの名前
agent.sources = webserver-log-source
agent.sinks = kafka-sink
agent.channels = memory-channel
# Flumeのソースの設定。/flume/weblogsディレクトリに書かれたファイルの内容をKafkaのトピックに出力させる
agent.sources.webserver-log-source.type = spooldir
agent.sources.webserver-log-source.spoolDir = /flume/weblogs
agent.sources.webserver-log-source.channels = memory-channel
# Flumeの出力をKafkaのeventtopicトピックにする
agent.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.kafka-sink.topic = eventtopic
agent.sinks.kafka-sink.brokerList = localhost:9092
agent.sinks.kafka-sink.batchSize = 20
agent.sinks.kafka-sink.channel = memory-channel
# Flumeのバッファはメモリ
agent4.channels.memory-channel.type = memory
agent4.channels.memory-channel.capacity = 100000
agent4.channels.memory-channel.transactionCapacity = 1000
Flumeエージェントの実行例
下記のコマンドを実行すると、/flume/weblogsにファイルが追加される毎に、Kafkaのトピック(eventtopic)にデータを送信します。
$ flume-ng agent --conf /etc/flume-ng/conf ¥
--conf-file /home/kawasaki/spooldir_sample.conf ¥
--name agent ¥
-Dflume.root.logger=INFO,console
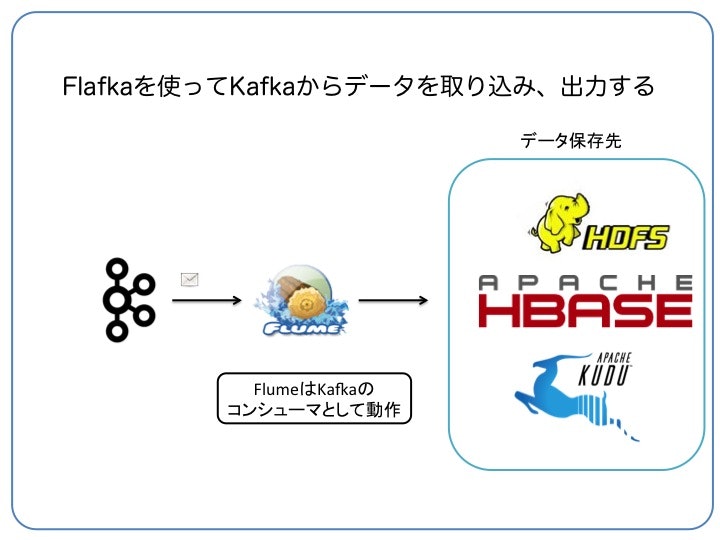
Kafkaのトピックからデータを読み込んで出力する (Kafka Source)
Kafkaのトピックから取り込み、Flumeのさまざまなシンク(HDFSやHBase、Kuduなど)に書き出します。
Kafka Sourceの設定ファイル
FlumeのKafka Source及びhdfs-sinkを使うと、Kafkaのトピックから取り込んだデータをHDFSに出力します。
- Kafkaのトピック: eventtopic
- HDFSの出力ディレクトリ: /user/kawasaki/hdfsstore
この場合の設定ファイル(kafka_hdfs.conf)は以下のようになります。
# エージェントのコンポート名
agent.sources = kafka-source
agent.sinks = hdfs-sink
agent.channels = memory-channel
# KafkaをFlumeのソースにする (Kafkaのトピックはeventtopic)
agent.sources.kafka-source.type = org.apache.flume.source.kafka.KafkaSource
agent2.sources.kafka-source.channels = memory-channel
agent2.sources.kafka-source.zookeeperConnect = localhost:2181
agent2.sources.kafka-source.topic = eventtopic
agent2.sources.kafka-source.groupId = flume
agent2.sources.kafka-source.kafka.consumer.timeout.ms = 100
# Flumeの出力をHDFSにする
agent.sinks.hdfs-sink.type = hdfs
agent.sinks.hdfs-sink.hdfs.path = /user/kawasaki/hdfsstore
agent.sinks.hdfs-sink.channel = memory-channel
# Flumeのバッファはメモリを使う
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 100000
agent.channels.memory-channel.transactionCapacity = 1000
Flumeエージェントの実行例
下記のコマンドを実行すると、Kafkaのトピック(eventtopic)からデータを取り出してHDFSに書き込みます。
$ flume-ng agent --conf /etc/flume-ng/conf ¥
--conf-file /home/kawasaki/kafka_hdfs.conf ¥
--name agent ¥
-Dflume.root.logger=INFO,console
FlumeのチャンネルとしてKafkaを使用する(Kafka Channel)
Flumeはソースから取り込んだデータをチャンネルに書き込み、その後シンクへと出力します。先ほどの2つの例ではチャンネルをメモリに設定していましたが、何らかの理由でマシンが落ちたりするとデータロストが生じるため、信頼性はありません(速いですが)。通常はチャンネルをファイルやDBにして耐障害性を持つようにしますが、FlumeのチャンネルをKafkaに設定することもできます。
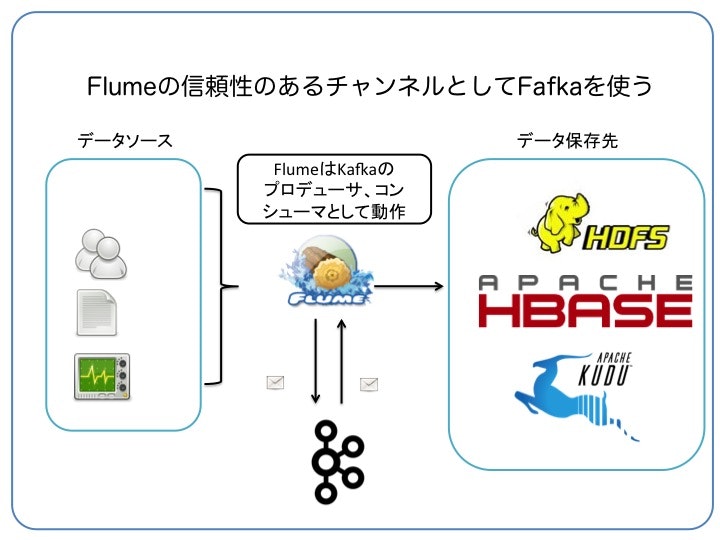
この応用として、外部アプリケーションが直接Kafkaに送信しているような場合、データソースを使わずにKafkaチャンネルから取り込むようなこともできます(ソースレス)
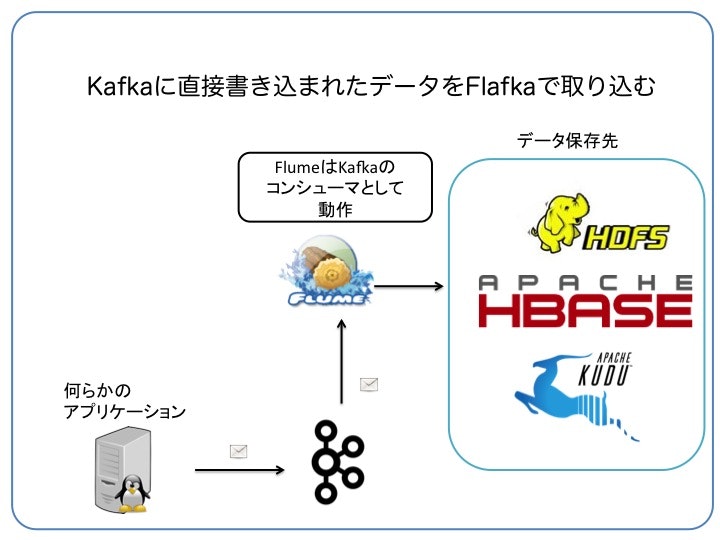
Kafka Channelの設定ファイル
FlumeのKafka Channelの例
- 監視ディレクトリ: /flume/weblogs
- HDFSの出力ディレクトリ: /user/kawasaki/hdfsstore
- Kafkaのトピック: eventtopic
この場合の設定ファイル(kafka_channel.conf)は以下のようになります。
# エージェントのコンポート名
agent.sources = webserver-log-source
agent.sinks = hdfs-sink
agent.channels = kafka-channel
# Flumeのソースの設定。/flume/weblogsディレクトリに書かれたファイルの内容をKafkaのトピックに出力させる
agent.sources.webserver-log-source.type = spooldir
agent.sources.webserver-log-source.spoolDir = /flume/weblogs
agent.sources.webserver-log-source.channels = kafka-channel
# Flumeの出力をHDFSにする
agent.sinks.hdfs-sink.type = hdfs
agent.sinks.hdfs-sink.hdfs.path = /user/kawasaki/hdfsstore
agent.sinks.hdfs-sink.channel = kafka-channel
agent.sinks.hdfs-sink.hdfs.fileType = DataStream
# Flumeのバッファ(チャンネル)はKafkaにする
agent.channels.kafka-channel.type = org.apache.flume.channel.kafka.KafkaChannel
agent.channels.kafka-channel.brokerList = localhost:9092
agent.channels.kafka-channel.zookeeperConnect = localhost:2181
agent.channels.kafka-channel.topic = eventtopic
Flumeエージェントの実行例
下記のコマンドを実行すると、/flume/weblogsに書き込まれたファイルを読み出し、HDFSに書き込みます。
$ flume-ng agent --conf /etc/flume-ng/conf ¥
--conf-file /home/kawasaki/kafka_channel.conf ¥
--name agent ¥
-Dflume.root.logger=INFO,console
応用
KafkaとFlumeをを組み合わせることで、応用として次のようなことができます。
- ストリームングでKafkaにデータを取り込み、一方はSpark Streamingでニアリアルタイムに処理
- もう一方はHDFSやHBaseに保存してバッチ処理で利用
Clouderaのブログに、Kafkaを使ったクレジットカードの不正検知アーキテクチャの設計についての絵があるので参考にしてみてください。(http://blog.cloudera.com/blog/2015/07/designing-fraud-detection-architecture-that-works-like-your-brain-does/)
例えば、Flumeを使ってこんな構成を簡単に設定することができます。
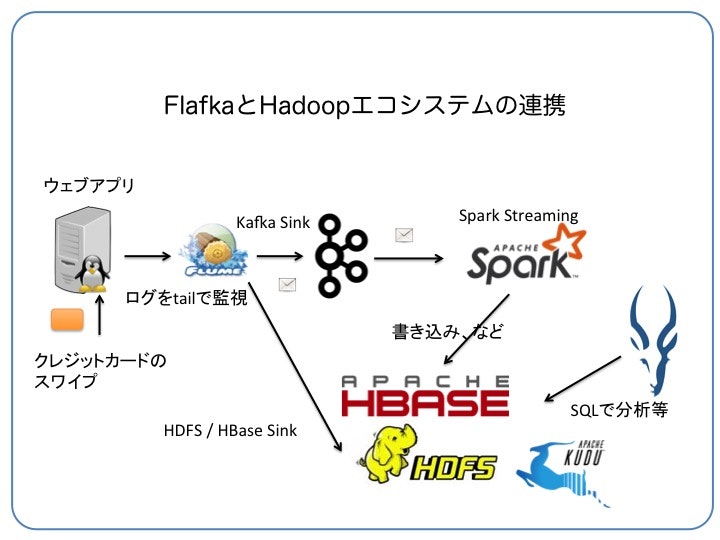
KafkaとSpark Streamingとの連携の話は別の機会に...
まとめ
FlumeはCDHに含まれており、Cloudera Managerを使えば簡単に導入、設定できます。以前紹介したStreamSetsなどを用いてデータフローを定義することもできますが、Flafkaの良いところは外部システムを使うこともなく、シンプル(ですが強力)に構築できるところですね。
参考資料
- http://blog.cloudera.com/blog/2014/11/flafka-apache-flume-meets-apache-kafka-for-event-processing/
- http://blog.cloudera.com/blog/2016/08/new-in-cloudera-enterprise-5-8-flafka-improvements-for-real-time-data-ingest/
- http://blog.cloudera.com/blog/2015/07/designing-fraud-detection-architecture-that-works-like-your-brain-does/
- https://www.linkedin.com/pulse/flume-kafka-real-time-event-processing-lan-jiang