はじめに
Data Refineryとは、IBMのWatson StudioとWatson Knowledge Catalogの両方に搭載される、データの可視化・加工を行う機能です。
Data Refineryを触っていて、以下の扱われ方に微妙な違いがあることに気づきメモしておこうと考えた次第です。少しでもご参考になれば幸いです。
- 空白のみの文字列
- 文字数が0の文字列
- 値なし(missing)
Data Refinery自体の説明については、@ishida330さんが下記の記事でわかりやすくご説明されているので、どうぞご参照ください。
-分析データの準備作業を楽に!~Watson Studioに標準搭載された「Data Refinery」をザクッと紹介してみる
テストデータ
下記のCSVデータをData Refineryで処理して、微妙な違いを確認してみます。
2行目には**「半角の空白1つ」が2列目と3列目に、3行目には「文字数が0の文字列」**が2列目、3列目に指定されています。
ID,テキスト,数値
1,One,1
2, ,
3,,
データの加工処理
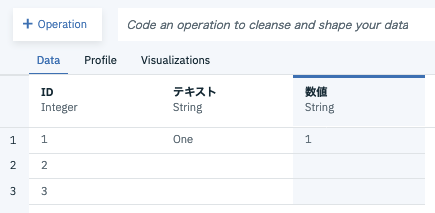
1.初期状態
Refine開始時点では、1行目の「One」と「1」が表示されていて、2行目、3行目は何も表示されていない状態です。
なお、ID列のデータタイプはData Refineryの機能により、データの内容から数値データと判別され、自動的にInteger型になっていますが、その他の列はString型となっています。
2.数値列のデータタイプ変換
Operationから、Convert column typeを選び、数値列をIntegerに変換します。
2行目、3行目の数値列は「NA」という表示になりました。

3.テキスト列のmissingへの変換
OperationからConvert column value to missingを選び、テキスト列の「One」という値をmissingに変換します。
テキスト列は3行ともに画面上には何も表示されない状態になりました。

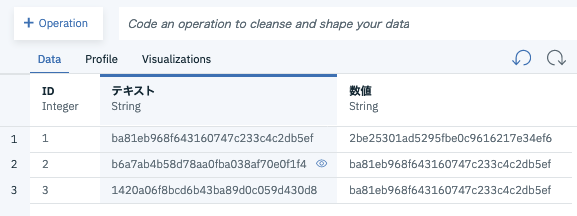
4.データの匿名化
テキスト列、数値列に対して、それぞれOperationからSubstitute(匿名化)を行います。これにより、テキスト列の3行はそれぞれ異なる値であることがわかり、
数値列の2行目、3行目は同じ値、さらにテキスト列の1行目とも同じ値であったことがわかります。
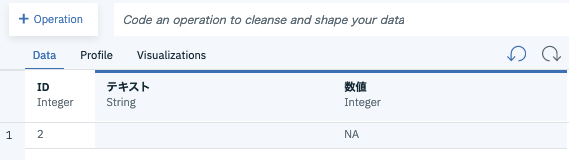
5.空行(empty rows)の除去
再び、3.テキスト列のmissingへの変換後の状態で、テキスト列に対して、OperationからRemove empty rowsを行います。
1行目、3行目が削除されました。(空白のみの文字列はemptyとは見なさない)
まとめ
上述の結果から、以下であることがわかりました。
- String型の列(今回のテキスト列)では、missing(1行目)、空白1文字(2行目)、文字数0の文字列 は区別されるが、画面上の表示では違いを区別できない。
- Convert column typeにより変換できない値は(今回の数値列の2行目、3行目)はmissingとなる。画面上の表示は「NA」
- Remove empty rowsは、String型の列の場合、missingや文字数0の文字列が削除の対象となる(「空白」の文字列は、対象外)