はじめに
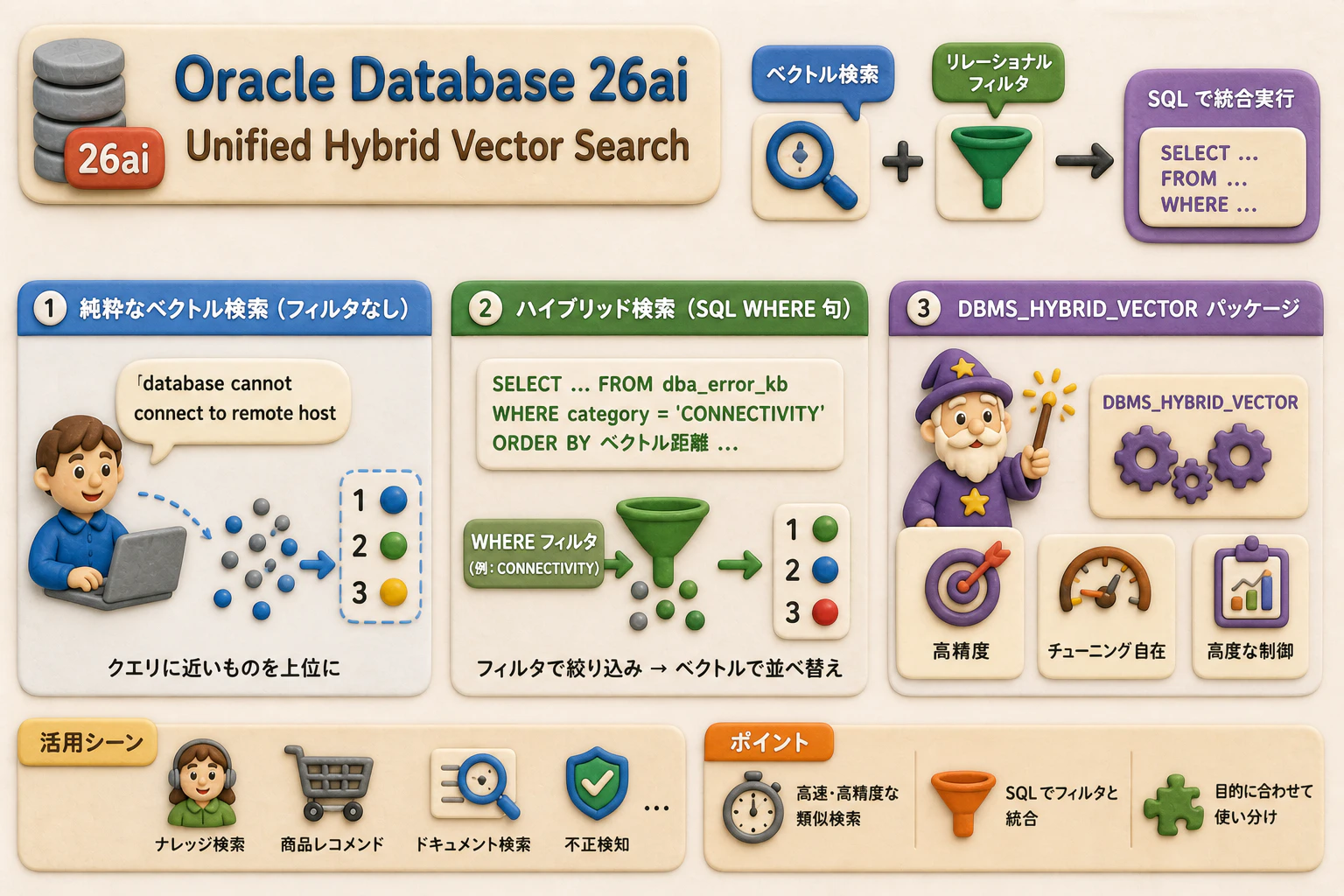
Oracle Database 26ai では、Unified Hybrid Vector Search という新しいアプローチが導入されました。この機能は、ベクトルによるセマンティック検索と、リレーショナル・フィルタリング(WHERE 句による絞り込み)を、標準 SQL の中で統合的に実行できる仕組みです。
ベクトルインデックスには以下の 2 種類があります。用途に応じて使い分けてください。
| インデックス種別 | 概要 | 推奨用途 |
|---|---|---|
| HNSW(Hierarchical Navigable Small World) | インメモリのグラフ型インデックス。最も高速な類似検索を実現します | 高速応答が必要な場合、データセットがメモリに収まる場合 |
| IVF(Inverted File Index) | 大規模データセット向けのディスクベースインデックス | データ量が多くインメモリが困難な場合 |
Oracle エラーナレッジベースのサンプルテーブルを作成し、以下の 3 つのパターンを順番に試してみました。
- ベクトル検索(リレーショナルフィルタなし)
- リレーショナルフィルタを組み合わせたハイブリッド検索(SQL WHERE 句)
-
DBMS_HYBRID_VECTORパッケージを使用したフル機能のハイブリッドインデックス検索
事前準備
- Oracle Database 26ai がインストール済みであること
- ONNX 形式の埋め込みモデルがロード済みであること(本記事では
all_MiniLM_L12_v2を使用します) -
VECTORデータ型が利用可能であること -
DBMS_HYBRID_VECTORパッケージが利用可能であること -
DBMS_VECTORパッケージへのアクセス権限があること
この記事には書いていない作業
本記事では以下の事前設定については手順を省略しています。必要に応じて公式ドキュメントを参照してください。
| 作業 | 参考ドキュメント |
|---|---|
| Oracle Database 26ai のインストール / アップグレード | Oracle Database Documentation |
ONNX 埋め込みモデル(all_MiniLM_L12_v2)のロード |
Oracle AI Vector Search ユーザーズガイド(DBMS_VECTOR.LOAD_ONNX_MODEL 手順) |
手順
Step 1: テーブルの作成
Oracle エラーナレッジベース用のテーブルを作成します。embedding 列が VECTOR 型で、エンベディングを格納します。
DROP TABLE dba_error_kb PURGE;
CREATE TABLE dba_error_kb (
id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
error_code VARCHAR2(20),
error_desc VARCHAR2(4000),
category VARCHAR2(50),
severity NUMBER(1),
embedding VECTOR
);
Step 2: サンプルデータの登録
代表的な Oracle エラーコードとその説明をテーブルに登録します。embedding 列はこの時点ではまだ空のままです。
INSERT INTO dba_error_kb (error_code, error_desc, category, severity)
VALUES ('ORA-12541',
'TNS no listener. The listener process is not running on the remote host.',
'CONNECTIVITY', 3);
INSERT INTO dba_error_kb (error_code, error_desc, category, severity)
VALUES ('ORA-04031',
'Unable to allocate memory in the shared pool. Consider increasing SGA_TARGET or flushing the shared pool.',
'MEMORY', 4);
INSERT INTO dba_error_kb (error_code, error_desc, category, severity)
VALUES ('ORA-00060',
'Deadlock detected while waiting for resource. A deadlock cycle was found between sessions.',
'LOCKING', 3);
INSERT INTO dba_error_kb (error_code, error_desc, category, severity)
VALUES ('ORA-12154',
'TNS could not resolve the connect identifier. Check tnsnames.ora or LDAP configuration.',
'CONNECTIVITY', 2);
INSERT INTO dba_error_kb (error_code, error_desc, category, severity)
VALUES ('ORA-01555',
'Snapshot too old. Rollback segment too small or long-running query encountering wrap-around.',
'IO', 3);
INSERT INTO dba_error_kb (error_code, error_desc, category, severity)
VALUES ('ORA-00257',
'Archiver error. Connect internal only until freed. Archive log destination full.',
'IO', 4);
COMMIT;
Step 3: EMBEDDINGの生成
VECTOR_EMBEDDING 関数を使用して、error_desc 列のテキストをベクトルに変換し、embedding 列を更新します。all_minilm_l12_v2 は Oracle が同梱する 384 次元の ONNX モデルです。
UPDATE dba_error_kb
SET embedding = vector_embedding(
all_minilm_l12_v2
USING error_desc AS data
);
COMMIT;
注意:
all_minilm_l12_v2モデルが事前にロードされていない場合、このステップはエラーになります。DBMS_VECTOR.LOAD_ONNX_MODELでモデルをロードしてから再実行してください。
Step 4: EMBEDDINの確認
VECTOR_DIMS および VECTOR_NORM 関数でエンベディングが正しく生成されたことを確認します。
SELECT id, error_code,
VECTOR_DIMS(embedding) AS dims,
VECTOR_NORM(embedding) AS l2_norm
FROM dba_error_kb
ORDER BY id;
ID ERROR_CODE DIMS L2_NORM
---------- -------------------- ---------- ----------
1 ORA-12541 384 1.0E+000
2 ORA-04031 384 1.0E+000
3 ORA-00060 384 1.0E+000
4 ORA-12154 384 1.0E+000
5 ORA-01555 384 1.0E+000
6 ORA-00257 384 1.0E+000
Step 5: HNSW ベクトルインデックスの作成
embedding 列に対して HNSW 型のベクトルインデックスを作成します。距離メトリクスには COSINE を使用し、検索精度の目標値を 95% に設定します。
CREATE VECTOR INDEX dba_errors_hnsw_idx
ON dba_error_kb (embedding)
ORGANIZATION INMEMORY NEIGHBOR GRAPH
DISTANCE COSINE
WITH TARGET ACCURACY 95;
Step 6: インデックス作成の確認
v$vector_index ビューでインデックスが正常に作成されたことを確認します。
SELECT index_name,
index_organization,
num_vectors,
distance_type,
index_dimensions,
default_accuracy
FROM v$vector_index
WHERE index_name = 'DBA_ERRORS_HNSW_IDX';
INDEX_NAME
--------------------------------------------------------------------------------
INDEX_ORGANIZATION
--------------------------------------------------------------------------------
NUM_VECTORS
-----------
DISTANCE_TYPE
--------------------------------------------------------------------------------
INDEX_DIMENSIONS DEFAULT_ACCURACY
---------------- ----------------
DBA_ERRORS_HNSW_IDX
INMEMORY NEIGHBOR GRAPH
6
COSINE
384 95
Step 7: 純粋なベクトル検索の実行
まず、リレーショナルフィルタを使用しない純粋なベクトル検索を試します。「database cannot connect to remote host」というクエリに意味的に近い行を検索します。
SELECT e.error_code,
e.category,
e.severity,
e.error_desc,
VECTOR_DISTANCE(
e.embedding,
vector_embedding(all_minilm_l12_v2 USING 'database cannot connect to remote host' AS data),
COSINE
) AS similarity_distance
FROM dba_error_kb e
ORDER BY similarity_distance
FETCH FIRST 3 ROWS ONLY;
ERROR_CODE CATEGORY SEVERITY
-------------------- -------------------------------------------------- ----------
ERROR_DESC
------------------------------------------------------------------------------------------------------------------------
SIMILARITY_DISTANCE
-------------------
ORA-12154 CONNECTIVITY 2
TNS could not resolve the connect identifier. Check tnsnames.ora or LDAP configuration.
6.117E-001
ORA-12541 CONNECTIVITY 3
TNS no listener. The listener process is not running on the remote host.
6.346E-001
ORA-00257 IO 4
Archiver error. Connect internal only until freed. Archive log destination full.
7.449E-001
実行計画
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 6180 | 2 (50)| 00:00:01 |
|* 1 | COUNT STOPKEY | | | | | |
| 2 | VIEW | | 6 | 12360 | 2 (50)| 00:00:01 |
|* 3 | SORT ORDER BY STOPKEY | | 6 | 36936 | 2 (50)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID| DBA_ERROR_KB | 6 | 36936 | 1 (0)| 00:00:01 |
| 5 | VECTOR INDEX HNSW SCAN | DBA_ERRORS_HNSW_IDX | 6 | 36936 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Step 8: リレーショナルフィルタを使ったハイブリッド検索
WHERE 句でカテゴリと重要度を絞り込み、偽陽性を排除します。これが Unified Hybrid Vector Search の基本的な使い方です。
SELECT e.error_code,
e.category,
e.severity,
e.error_desc,
VECTOR_DISTANCE(
e.embedding,
vector_embedding(all_minilm_l12_v2 USING 'database cannot connect to remote host' AS data),
COSINE
) AS similarity_distance
FROM dba_error_kb e
WHERE e.category = 'CONNECTIVITY'
AND e.severity >= 2
ORDER BY similarity_distance
FETCH FIRST 3 ROWS ONLY;
ERROR_CODE CATEGORY SEVERITY
-------------------- -------------------------------------------------- ----------
ERROR_DESC
------------------------------------------------------------------------------------------------------------------------
SIMILARITY_DISTANCE
-------------------
ORA-12154 CONNECTIVITY 2
TNS could not resolve the connect identifier. Check tnsnames.ora or LDAP configuration.
6.117E-001
ORA-12541 CONNECTIVITY 3
TNS no listener. The listener process is not running on the remote host.
6.346E-001
実行計画
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 4120 | 4 (25)| 00:00:01 |
|* 1 | COUNT STOPKEY | | | | | |
| 2 | VIEW | | 2 | 4120 | 4 (25)| 00:00:01 |
|* 3 | SORT ORDER BY STOPKEY| | 2 | 12312 | 4 (25)| 00:00:01 |
|* 4 | TABLE ACCESS FULL | DBA_ERROR_KB | 2 | 12312 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Step 9: ハイブリッドインデックスの作成(テキスト+ベクトル統合)
DBMS_HYBRID_VECTOR パッケージを使用したフル機能のハイブリッドインデックスを作成します。まず Oracle Text 用のデータストアプリファレンスを作成し、その後ハイブリッド検索インデックスを作成します。
BEGIN
ctx_ddl.create_preference('KB_DATASTORE', 'DIRECT_DATASTORE');
END;
/
CREATE HYBRID VECTOR INDEX dba_kb_hybrid_idx
ON dba_error_kb(error_desc)
PARAMETERS ('MODEL all_minilm_l12_v2 VECTOR_IDXTYPE HNSW');
Step 10: DBMS_HYBRID_VECTOR.SEARCH によるハイブリッド検索の実行
DBMS_HYBRID_VECTOR.SEARCH パッケージを使い、テキスト検索とベクトル検索を組み合わせたハイブリッド検索を実行します。p_vector_weight パラメータでスコアリングの重み付けを調整できます。
SELECT DBMS_HYBRID_VECTOR.SEARCH(
json(
'{
"hybrid_index_name" : "DBA_KB_HYBRID_IDX",
"search_text" : "listener not reachable on remote server",
"search_scorer" : "RSF",
"vector" : { "score_weight" : 7 },
"text" : { "score_weight" : 3 },
"return" : { "topN" : 3 }
}'
)
)
FROM DUAL;
DBMS_HYBRID_VECTOR.SEARCH は名前付きパラメータではなく、単一の JSON 引数を受け取る関数です。主要なキーの意味は以下のとおりです。
| JSON キー | 説明 |
|---|---|
hybrid_index_name |
検索対象のハイブリッドインデックス名 |
search_text |
ベクトル検索・テキスト検索の両方に使用するクエリ文字列 |
search_scorer |
スコアリングアルゴリズム(RSF:相対スコア融合、RRF:逆順位融合) |
vector.score_weight |
RSF におけるベクトルスコアの相対的な重み |
text.score_weight |
RSF におけるテキストスコアの相対的な重み |
return.topN |
返却する最大件数 |
上記の例では vector.score_weight : 7・text.score_weight : 3 とすることで、セマンティック 70%・キーワード 30% のブレンドスコアリングになります。純粋なセマンティック検索にしたい場合は "search_fusion" : "VECTOR_ONLY" を指定してください。
[
{"rowid":"AAAg5DAAQAAHK3+AAA","score":61.48,"vector_score":76.26,"text_score":27,"vector_rank":1,"text_rank":1,"chunk_text":"TNS no listener. The listener process is not running on the remote host.","chunk_id":"1"},
{"rowid":"AAAg5DAAQAAHK3+AAD","score":40.5,"vector_score":57.85,"text_score":0,"vector_rank":2,"text_rank":12,"chunk_text":"TNS could not resolve the connect identifier. Check tnsnames.ora or LDAP configuration.","chunk_id":"1"},
{"rowid":"AAAg5DAAQAAHK3+AAC","score":39.62,"vector_score":56.6,"text_score":0,"vector_rank":3,"text_rank":12,"chunk_text":"Deadlock detected while waiting for resource. A deadlock cycle was found between sessions.","chunk_id":"1"}
]
Step 11: クリーンアップ
検証が完了したら、作成したオブジェクトを削除します。
-- ハイブリッド検索インデックスの削除
DROP INDEX dba_kb_hybrid_idx;
-- HNSW ベクトルインデックスの削除
DROP INDEX dba_errors_hnsw_idx;
-- テーブルの削除
DROP TABLE dba_error_kb PURGE;
-- Oracle Text プリファレンスの削除
BEGIN
ctx_ddl.drop_preference('KB_DATASTORE');
END;
/
おわりに
今回の検証で確認できたポイントを以下にまとめます。
- Oracle Database 26ai では、VECTOR 型・
VECTOR_EMBEDDING関数・HNSW インデックスを組み合わせたセマンティック検索を、標準 SQL のみで実現できることを確認しました - WHERE 句によるリレーショナルフィルタとベクトル検索を同一クエリで組み合わせることで、純粋なベクトル検索に比べて偽陽性を大幅に削減できることを確認しました
-
DBMS_HYBRID_VECTOR.SEARCHのp_vector_weightパラメータにより、キーワード検索とセマンティック検索の重み付けを柔軟に調整できることを確認しました
参考情報
- Oracle AI Database 26ai: Unified Hybrid Vector Search Is The Real Deal
- DBMS_HYBRID_VECTOR パッケージ
- DBMS_VECTOR パッケージ
補足:DBMS_HYBRID_VECTOR.SEARCH の結果の読み方
Step 10 で実行したハイブリッド検索の実際の出力例と、各フィールドの意味を解説します。
出力例
[
{"rowid":"AAAg5DAAQAAHK3+AAA","score":61.48,"vector_score":76.26,"text_score":27,"vector_rank":1,"text_rank":1,"chunk_text":"TNS no listener. The listener process is not running on the remote host.","chunk_id":"1"},
{"rowid":"AAAg5DAAQAAHK3+AAD","score":40.5,"vector_score":57.85,"text_score":0,"vector_rank":2,"text_rank":12,"chunk_text":"TNS could not resolve the connect identifier. Check tnsnames.ora or LDAP configuration.","chunk_id":"1"},
{"rowid":"AAAg5DAAQAAHK3+AAC","score":39.62,"vector_score":56.6,"text_score":0,"vector_rank":3,"text_rank":12,"chunk_text":"Deadlock detected while waiting for resource. A deadlock cycle was found between sessions.","chunk_id":"1"}
]
各フィールドの意味
| フィールド | 意味 |
|---|---|
rowid |
マッチした行の Oracle ROWID |
score |
RSF による最終的なブレンドスコア(高いほど関連性が高い) |
vector_score |
ベクトル類似スコア(クエリとテキストの意味的な近さ) |
text_score |
キーワード検索スコア(Oracle Text CONTAINS による一致度) |
vector_rank |
ベクトル検索での順位 |
text_rank |
テキスト検索での順位 |
chunk_text |
マッチしたテキスト内容 |
chunk_id |
チャンクの識別子 |
各行の読み解き
1位:ORA-12541(TNS no listener)score: 61.48
vector_rank: 1・text_rank: 1 とベクトル検索・キーワード検索の両方で1位を獲得しています。text_score: 27 は「listener」「remote host」などの語がドキュメント内に実際に含まれており、キーワードとしても強くヒットしていることを示します。最も信頼性の高い結果です。
2位:ORA-12154(TNS could not resolve)score: 40.5
text_score: 0 なのでキーワード検索ではヒットしていません。text_rank: 12 はキーワード検索の結果集合に含まれなかった(最低順位扱い)ことを意味します。「TNS 接続できない」という意味がクエリと近いため、ベクトル検索が 2 位に引き上げています。ハイブリッド検索のベクトル成分が機能した例です。
3位:ORA-00060(Deadlock)score: 39.62
一見「接続できない」とは無関係なデッドロックエラーが 3 位に入っています。これは "waiting for resource" という表現が埋め込みモデル内で「応答を待っているが得られない」という意味的ベクトルを持ち、クエリの "not reachable" と近いと判断されたためです。text_score: 0 なのでキーワード的には完全に無関係で、ベクトル検索の偽陽性が表れています。Step 8 のように WHERE category = 'CONNECTIVITY' などリレーショナルフィルタを組み合わせることで排除できます。
RSF スコアの考え方
今回の設定(vector.score_weight: 7・text.score_weight: 3)では、最終スコアはベクトル成分が 70%・テキスト成分が 30% の重み付けで計算されます。
score ∝ (vector_score × 7) + (text_score × 3) ← 正規化して合成
ORA-12541 が圧倒的に高い score: 61.48 を得たのは両方のスコアが高かったためです。2位と3位はベクトルスコアがほぼ同じ(57.85 vs 56.6)でテキストスコアが両方 0 のため、僅差になっています。