はじめに
Autonomous Databaseには、Oracle Machine Learningユーザー・インタフェースが用意されており、OML Notebooks、OML AutoML UI、OML Models、テンプレート・サンプル・ノートブックなどのOracle Machine Learningのコンポーネントおよび機能にすばやくアクセスできます。
OML Notebooks(ノートブック)を使用してPL/SQLを使った機械学習をしてみました。
OML ノートブック
モデル開発用の共同共有ワークスペースとして提供され、Autonomous Database内のすべてのデータへの直接接続します。
データおよび機械学習の結果を表示するビジュアル・パレットがあり、ディスカッション、ドキュメント、実行および結果が一緒に表示される共有プラットフォームです。
利用するには、Autonomous DatabaseのユーザでOMLを有効化します。
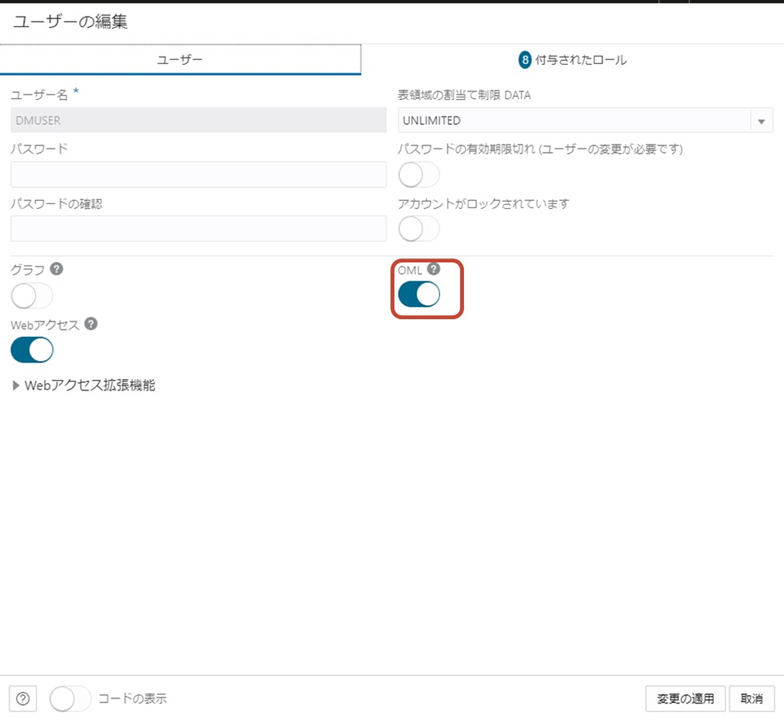
サンプルシナリオ
SQL Developer に含まれるチュートリアル用データを使います。
以下のスクリプトを作ってサンプルデータを作成します。
alter session set nls_date_language = 'AMERICAN';
@C:\sqldeveloper\dataminer\scripts\instInsurCustData.sql {username}
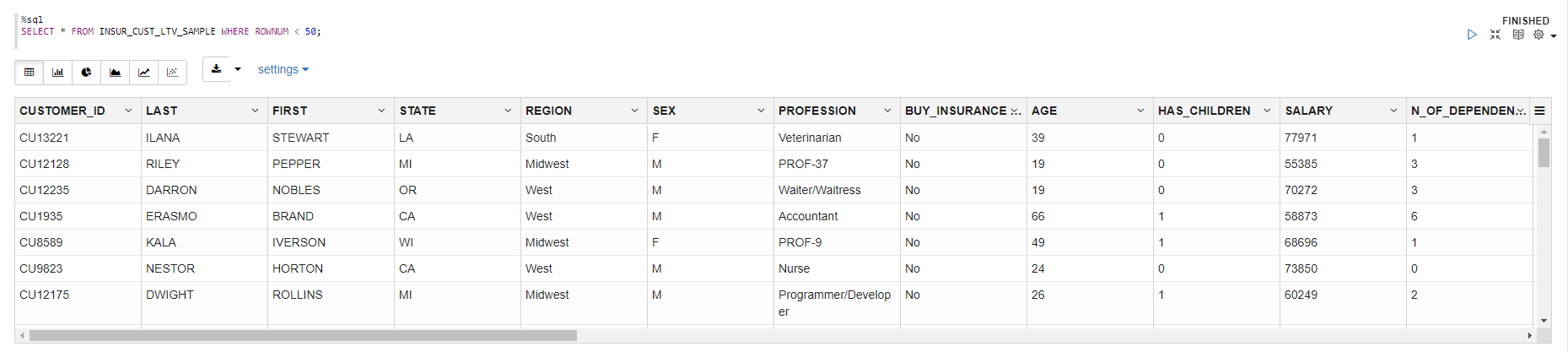
INSUR_CUST_LTV_SAMPLE表は、保険商品を購入したかしなかったか結果が入った顧客情報表です。
BUY_INSURANCE列を教師データとして、分類モデル3つのアルゴリズムで作成し、モデルを比較します。
精度のよいモデルを使って予測を実施します。
OMLノートブックをはじめる
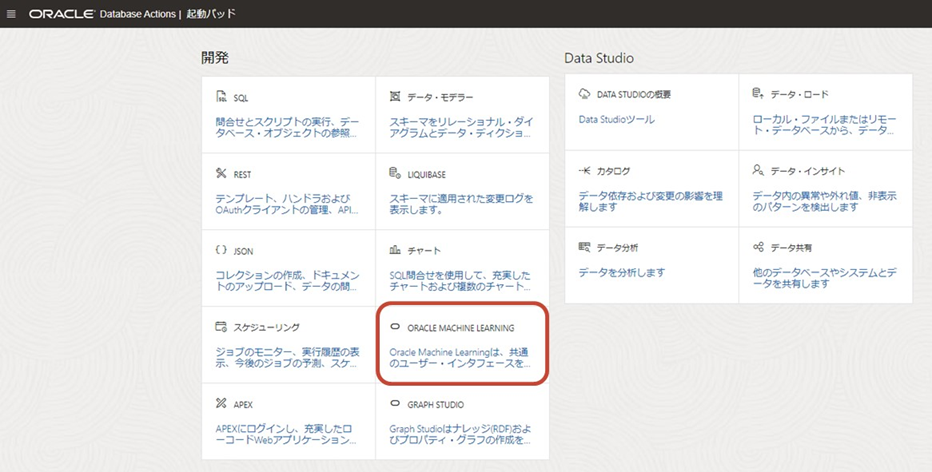
データベース・アクションでOML UIの起動
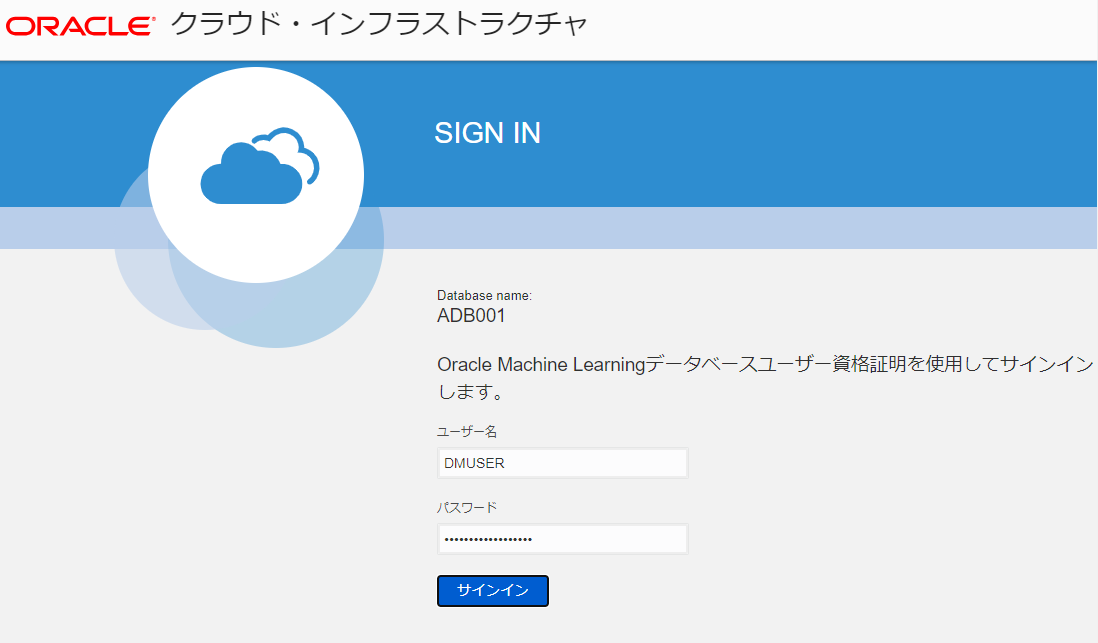
OMLを有効化したユーザでログイン
左上のハンバーガーメニューから「プロジェクト」>「ノートブック」を選択
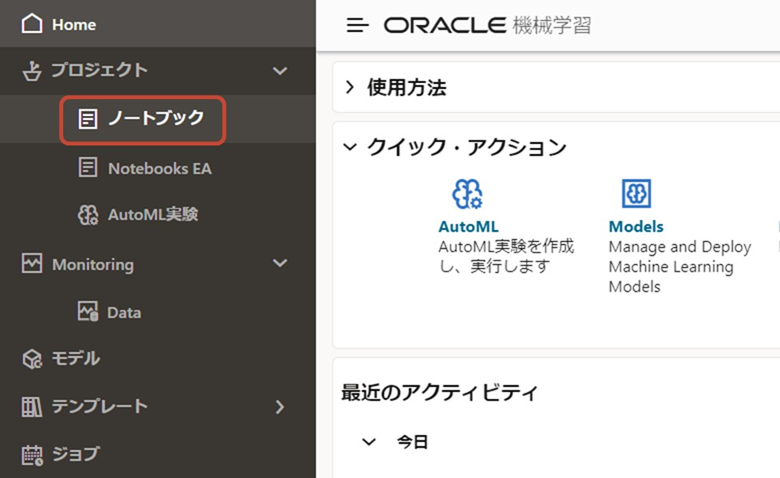
ノートブックの作成
[作成」をクリックし、名前を入力しノートブックを作成します。
作成したノートブックを選択しノートブックを起動します。
データの確認
教師データの確認
%sql
SELECT * FROM INSUR_CUST_LTV_SAMPLE WHERE ROWNUM < 50;
ターゲット列の値のサマリ
%sql
SELECT BUY_INSURANCE, COUNT(*)
FROM INSUR_CUST_LTV_SAMPLE
GROUP BY BUY_INSURANCE
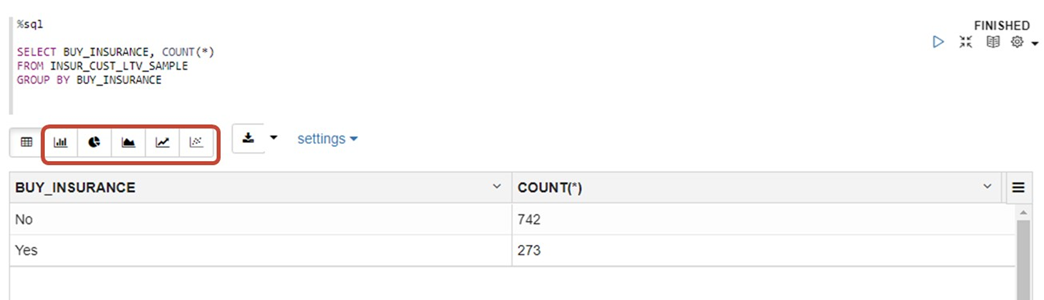
ボタンをクリックしグラフ表示が可能
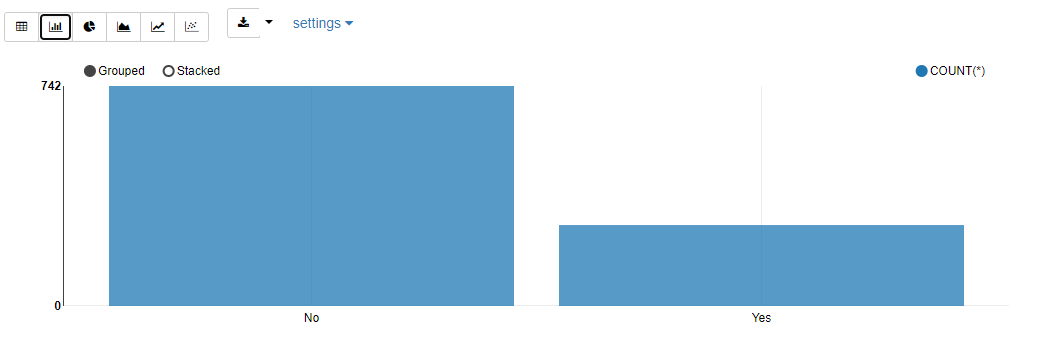
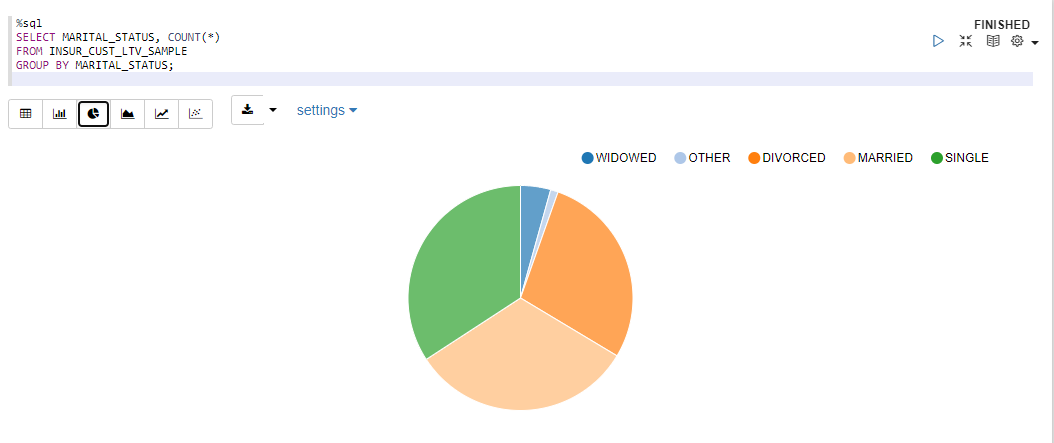
顧客情報 (MARITAL_STATUS列)
SELECT MARITAL_STATUS, COUNT(*)
FROM INSUR_CUST_LTV_SAMPLE
GROUP BY MARITAL_STATUS;
BUY_INSURANCEの値に影響がある列の調査
%script
BEGIN DBMS_DATA_MINING.DROP_MODEL('ai_explain_output_buy_insur_bin');
EXCEPTION WHEN OTHERS THEN NULL; END;
DECLARE
v_setlst DBMS_DATA_MINING.SETTING_LIST;
BEGIN
v_setlst('ALGO_NAME') := 'ALGO_AI_MDL';
V_setlst('PREP_AUTO') := 'ON';
DBMS_DATA_MINING.CREATE_MODEL2(
MODEL_NAME => 'ai_explain_output_buy_insur_bin',
MINING_FUNCTION => 'ATTRIBUTE_IMPORTANCE',
DATA_QUERY => 'select * from INSUR_CUST_LTV_SAMPLE',
SET_LIST => v_setlst,
CASE_ID_COLUMN_NAME => 'CUSTOMER_ID',
TARGET_COLUMN_NAME => 'BUY_INSURANCE');
END;

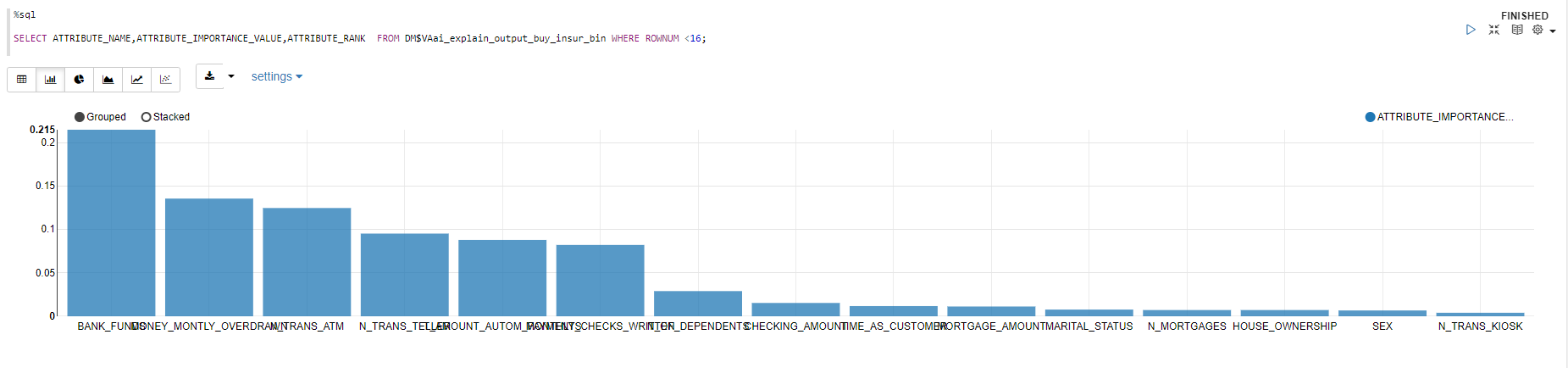
BUY_INSURANCEの値に影響がある列の上位15を表示
%sql
SELECT * FROM DM$VAai_explain_output_buy_insur_bin WHERE ROWNUM <16;
DBMS_DATA_MINING_TRANSFORMS パッケージを使ったヒストグラムの作成
%script
-- Create a view that bins ALL the numeric columns.
BEGIN
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE bin_num_tbl';
EXCEPTION WHEN OTHERS THEN NULL;
END;
BEGIN
EXECUTE IMMEDIATE 'DROP VIEW mining_data_bin_view';
EXCEPTION WHEN OTHERS THEN NULL;
END;
dbms_data_mining_transform.create_bin_num(
bin_table_name => 'bin_num_tbl');
dbms_data_mining_transform.insert_autobin_num_eqwidth(
bin_table_name => 'bin_num_tbl',
data_table_name => 'INSUR_CUST_LTV_SAMPLE',
bin_num => 5,
max_bin_num => 10,
exclude_list => dbms_data_mining_transform.COLUMN_LIST('CUSTOMER_ID'));
dbms_data_mining_transform.xform_bin_num(
bin_table_name => 'bin_num_tbl',
data_table_name => 'INSUR_CUST_LTV_SAMPLE',
xform_view_name => 'mining_data_bin_view');
END;
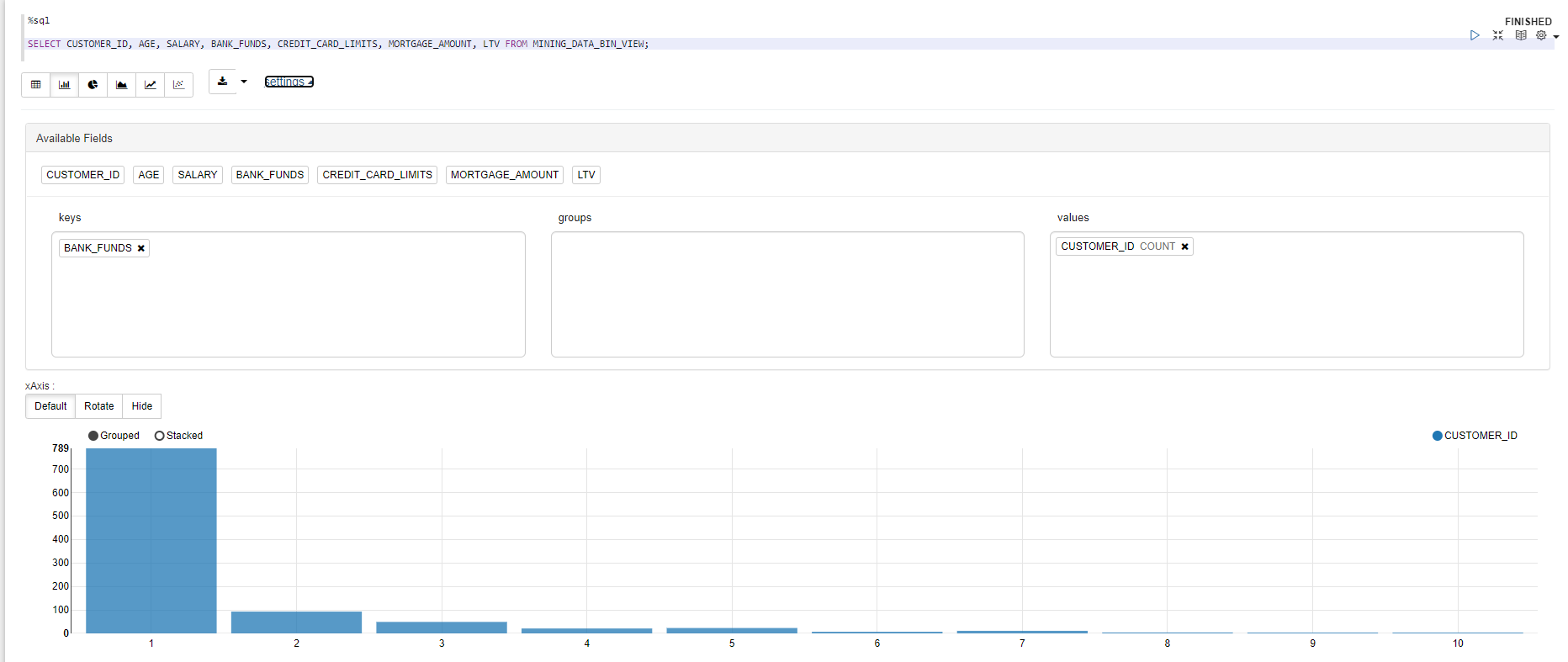
ヒストグラムの表示 例:BANK_FUNDS
%sql
SELECT CUSTOMER_ID, AGE, SALARY, BANK_FUNDS, CREDIT_CARD_LIMITS, MORTGAGE_AMOUNT, LTV FROM MINING_DATA_BIN_VIEW;
モデルの作成
ディシジョンツリー(DT)、サポートベクターマシン(SVM)、ランダムフォレストのアルゴリズムを使ったモデルを作成します。
ディシジョンツリー(DT)モデルの作成
%script
BEGIN
DBMS_DATA_MINING.DROP_MODEL('N2_CLASS_MODEL_DT');
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
DECLARE
v_setlst DBMS_DATA_MINING.SETTING_LIST;
BEGIN
v_setlst('PREP_AUTO') := 'ON';
v_setlst('ALGO_NAME') := 'ALGO_DECISION_TREE';
DBMS_DATA_MINING.CREATE_MODEL2(
MODEL_NAME => 'N2_CLASS_MODEL_DT',
MINING_FUNCTION => 'CLASSIFICATION',
DATA_QUERY => 'SELECT * FROM INSUR_CUST_LTV_SAMPLE',
SET_LIST => v_setlst,
CASE_ID_COLUMN_NAME => 'CUSTOMER_ID',
TARGET_COLUMN_NAME => 'BUY_INSURANCE');
END;
ディシジョンツリー(DT)モデルの評価値の計算
%script
-- Drop result tables
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE N2_APPLY_RESULT_DT PURGE';
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE N2_LIFT_TABLE_DT PURGE';
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
-- Score the data and compute lift
BEGIN
DBMS_DATA_MINING.APPLY('N2_CLASS_MODEL_DT','INSUR_CUST_LTV_APPLY','CUSTOMER_ID','N2_APPLY_RESULT_DT');
DBMS_DATA_MINING.COMPUTE_LIFT('N2_APPLY_RESULT_DT','INSUR_CUST_LTV_SAMPLE','CUSTOMER_ID','BUY_INSURANCE','N2_LIFT_TABLE_DT','Yes','PREDICTION','PROBABILITY',100);
END;
サポートベクターマシン(SVM)モデルの作成
%script
BEGIN
DBMS_DATA_MINING.DROP_MODEL('N2_CLASS_MODEL_SVM');
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
DECLARE
v_setlst DBMS_DATA_MINING.SETTING_LIST;
BEGIN
v_setlst('PREP_AUTO') := 'ON';
v_setlst('ALGO_NAME') := 'ALGO_SUPPORT_VECTOR_MACHINES';
v_setlst('SVMS_KERNEL_FUNCTION') := 'SVMS_GAUSSIAN';
DBMS_DATA_MINING.CREATE_MODEL2(
MODEL_NAME => 'N2_CLASS_MODEL_SVM',
MINING_FUNCTION => 'CLASSIFICATION',
DATA_QUERY => 'SELECT * FROM INSUR_CUST_LTV_SAMPLE',
SET_LIST => v_setlst,
CASE_ID_COLUMN_NAME => 'CUSTOMER_ID',
TARGET_COLUMN_NAME => 'BUY_INSURANCE');
END;
サポートベクターマシン(SVM)モデルの評価値の計算
%script
-- Drop result tables
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE N2_APPLY_RESULT_SVM PURGE';
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE N2_LIFT_TABLE_SVM PURGE';
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
-- Score the data and compute lift
BEGIN
DBMS_DATA_MINING.APPLY('N2_CLASS_MODEL_SVM','INSUR_CUST_LTV_APPLY','CUSTOMER_ID','N2_APPLY_RESULT_SVM');
DBMS_DATA_MINING.COMPUTE_LIFT('N2_APPLY_RESULT_SVM','INSUR_CUST_LTV_SAMPLE','CUSTOMER_ID','BUY_INSURANCE','N2_LIFT_TABLE_SVM','Yes','PREDICTION','PROBABILITY',100);
END;
ランダムフォレスト(RM)モデルの作成
%script
BEGIN
DBMS_DATA_MINING.DROP_MODEL('N2_CLASS_MODEL_RF');
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
DECLARE
v_setlst DBMS_DATA_MINING.SETTING_LIST;
BEGIN
v_setlst('PREP_AUTO') := 'ON';
v_setlst('ALGO_NAME') := 'ALGO_RANDOM_FOREST';
DBMS_DATA_MINING.CREATE_MODEL2(
MODEL_NAME => 'N2_CLASS_MODEL_RF',
MINING_FUNCTION => 'CLASSIFICATION',
DATA_QUERY => 'SELECT * FROM INSUR_CUST_LTV_SAMPLE',
SET_LIST => v_setlst,
CASE_ID_COLUMN_NAME => 'CUSTOMER_ID',
TARGET_COLUMN_NAME => 'BUY_INSURANCE');
END;
/
ランダムフォレスト(RM)モデルの評価値の計算
%script
-- Drop result tables
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE N2_APPLY_RESULT_RF PURGE';
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE N2_LIFT_TABLE_RF PURGE';
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
-- Score the data and compute lift
BEGIN
DBMS_DATA_MINING.APPLY('N2_CLASS_MODEL_RF','INSUR_CUST_LTV_APPLY','CUSTOMER_ID','N2_APPLY_RESULT_RF');
DBMS_DATA_MINING.COMPUTE_LIFT('N2_APPLY_RESULT_RF','INSUR_CUST_LTV_SAMPLE','CUSTOMER_ID','BUY_INSURANCE','N2_LIFT_TABLE_RF','Yes','PREDICTION','PROBABILITY',100);
END;
/
モデルの比較
比較用ビューの作成
%script
CREATE OR REPLACE VIEW ALL_LIST_DATA_V AS
SELECT QUANTILE_NUMBER, GAIN_CUMULATIVE, CAST('DECISION_TREE' AS VARCHAR(50)) AS ALGO_NAME
FROM N2_LIFT_TABLE_DT
UNION
SELECT QUANTILE_NUMBER, GAIN_CUMULATIVE, CAST('SVM' AS VARCHAR(50)) AS ALGO_NAME
FROM N2_LIFT_TABLE_SVM
UNION
SELECT QUANTILE_NUMBER, GAIN_CUMULATIVE, CAST('RANDOM_FOREST' AS VARCHAR(50)) AS ALGO_NAME
FROM N2_LIFT_TABLE_RF;
モデルの比較
%sql
SELECT A.ALGO_NAME, A.QUANTILE_NUMBER, ROUND(A.GAIN_CUMULATIVE*100,2) GAIN_CUMULATIVE, B.RANDOM_GUESS
FROM ALL_LIST_DATA_V A,
(SELECT ALGO_NAME, QUANTILE_NUMBER, QUANTILE_NUMBER RANDOM_GUESS FROM ALL_LIST_DATA_V) B
WHERE A.QUANTILE_NUMBER = B.QUANTILE_NUMBER AND A.ALGO_NAME = B.ALGO_NAME;
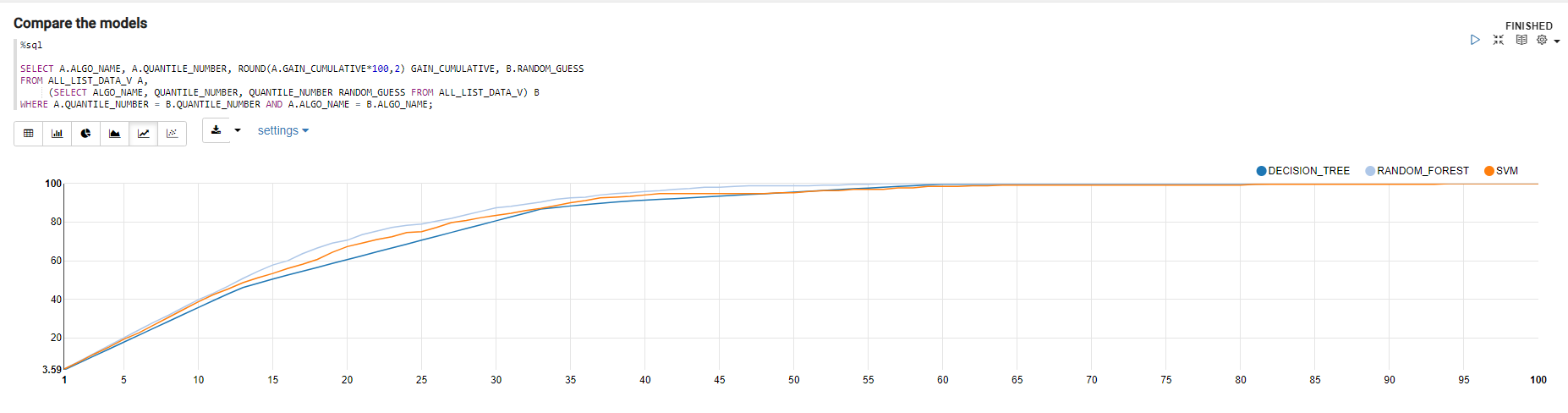
今回の結果では、ランダムフォレストがよりよいモデルとなりました。
予測
新しい顧客にモデルを適用して、BUY_INSURANCEが「はい」になる可能性が高い顧客を予測
新しい顧客データがINSUR_CUST_LTV_APPLY表として用意
%sql
SELECT CUSTOMER_ID, BUY_INSURANCE, PREDICTION(N2_CLASS_MODEL_RF USING *) PREDICTION, ROUND(PREDICTION_PROBABILITY(N2_CLASS_MODEL_RF, NULL USING *)*100,2) PROB_BUY_INSURANCE
FROM INSUR_CUST_LTV_APPLY
ORDER BY PROB_BUY_INSURANCE DESC
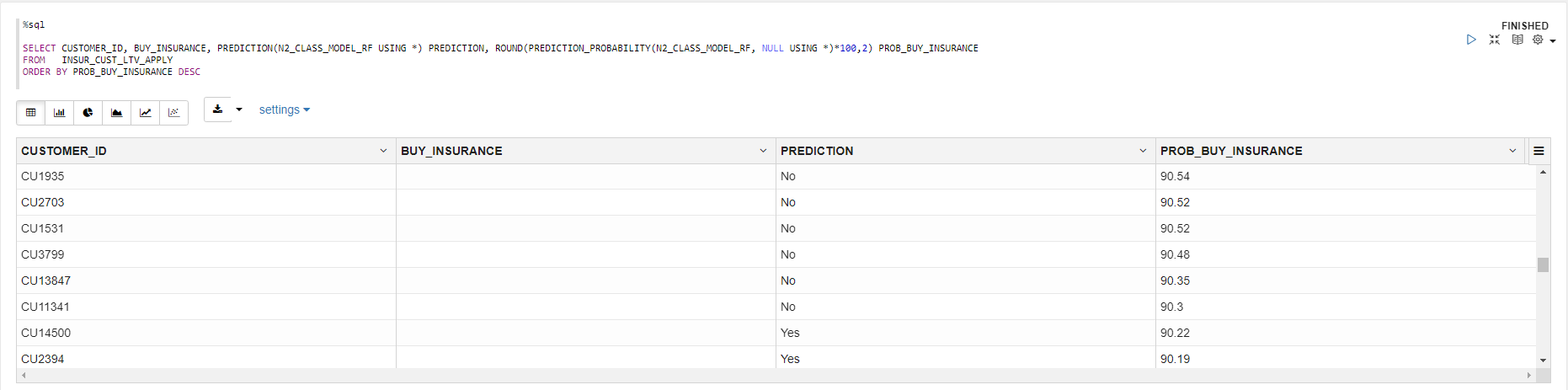
データ可視化ツールで利用しやすいように、モデルの予測と確率で新しい表を作成します。
%script
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE BUY_INSUR_NEW_PREDICTIONS PURGE';
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
CREATE TABLE BUY_INSUR_NEW_PREDICTIONS AS
SELECT A.CUSTOMER_ID
, A.PREDICTION
, A.PROB_BUY_INSUR
, B.STATE, B.AGE, B.SALARY, B.BANK_FUNDS, B.CREDIT_CARD_LIMITS, B.MORTGAGE_AMOUNT, B.LTV, B.MARITAL_STATUS
FROM (SELECT CUSTOMER_ID, PREDICTION(N2_CLASS_MODEL_RF USING *) PREDICTION, round(PREDICTION_PROBABILITY(N2_CLASS_MODEL_RF, 'Yes' USING *),2) PROB_BUY_INSUR FROM INSUR_CUST_LTV_APPLY) A
, INSUR_CUST_LTV_APPLY B
WHERE A.CUSTOMER_ID = B.CUSTOMER_ID;

作成したBUY_INSUR_NEW_PREDICTIONS表から「Yes」の顧客をPROB_BUY_INSURでソートして確認します。
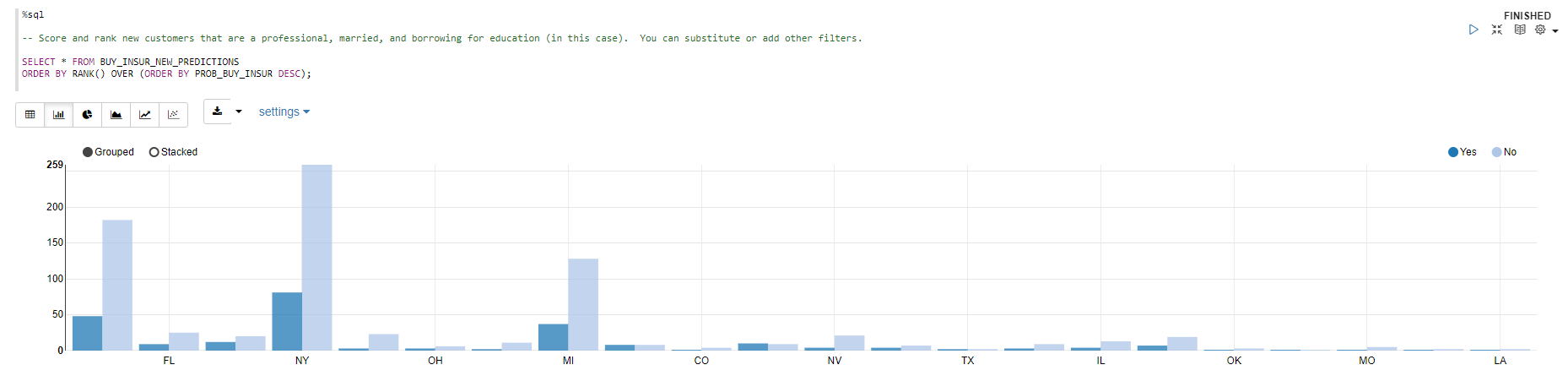
おわりに
OMLノートブックを使って結果をグラフ化しながら機械学習モデル作成、評価ができました。