はじめに
近年、大規模言語モデル(LLM)を活用したシステム開発の事例が増加傾向にあります。高度なAPIの普及により、アプリケーションへのLLM実装は容易になりながらも、利用形態はAPIの呼び出しに終始しがちで、どうしても、AIモデルの内部機構をブラックボックスとして扱う状況が常態化しつつある点に懸念が残ります。
2WINSでは、隔週に社内勉強会を開催しています。本稿では、勉強会の第15回で扱った「TransformerとGPTの仕組み」をベースに内部構造を理解し、モデルの実装および学習プロセスを自律的に構築できる技術者の育成を企図し、GPT(Generative Pre-trained Transformer)の根幹を成す理論的背景について解説したいと思います。
1. GPTの定義
GPTは「Generative Pre-trained Transformer」の略で、GPTの基本原理を理解する上で、その基盤アーキテクチャである「Transformer」の構造的理解が不可欠となります。
2. Transformerの概要とその技術的優位性
Transformerとは、2017年にGoogle BrainやGoogle Researchの研究者によて発表された論文『Attention Is All You Need』において提唱されました。主に、自然言語処理などの系列変換タスクを目的とするニューラルネットワークモデルです。
ここで、RNN(Recurrent Neural Network:回帰型ニューラルネットワーク)とTransformerを比較してみましょう。Transformerの登場以前、自然言語処理においてはRNNが主流でした。RNNは、時刻 $t$ における隠れ状態ベクトル $h_t$ を、以下の漸化式によって更新します。
$$h_t = f(W_{hh} h_{t-1} + W_{hx} x_t + b_h)$$
ここで、RNNを使ったテキスト生成するPythonコードを示します。ここで活性化関数は$\tanh$を採用しました。RNNでは双曲線関数である$\tanh$がよく用いられています。データセットであるテキストファイルは、太宰治の小説の一部をスクレイピングしたものを充てました。
import os
import re
import random
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import MeCab
from pathlib import Path
import urllib.request
#====================================================
# 1. パラメータ設定 (Config)
#====================================================
class Config:
FILE_PATH = ""#こちらにデータセットのファイルパスを入れてください
BATCH_SIZE = 32
EMBED_DIM = 128
HIDDEN_DIM = 256
NUM_LAYERS = 2
EPOCHS = 5
LEARNING_RATE = 0.001
SEED = 42
MAX_LEN_GENERATION = 100
SEQ_LEN = 30
def set_seed(seed):
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
set_seed(Config.SEED)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
#====================================================
# 2. データセットクラス
#====================================================
class TextDataset(Dataset):
def __init__(self, data, sequence_length):
self.data = data
self.sequence_length = sequence_length
def __len__(self):
return len(self.data) - self.sequence_length
def __getitem__(self, idx):
x = self.data[idx : idx + self.sequence_length]
y = self.data[idx + 1 : idx + self.sequence_length + 1]
return torch.tensor(x, dtype=torch.long), torch.tensor(y, dtype=torch.long)
#====================================================
# 3. RNN 言語モデル
#====================================================
class RNNModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_layers):
super(RNNModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.rnn = nn.RNN(
input_size=embed_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=True,
nonlinearity="tanh"
)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden=None):
embedded = self.embedding(x)
if hidden is not None:
out, hidden = self.rnn(embedded, hidden)
else:
out, hidden = self.rnn(embedded)
logits = self.fc(out)
return logits, hidden
#====================================================
# 4. 前処理 & トークン化
#====================================================
def preprocess_text(text):
text = text.replace('\u3000', ' ')
text = re.sub(r'\r?\n', ' ', text)
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'[()()\[\]{}「」『』]', '', text)
text = re.sub(r'[、。,.!?]', '', text)
text = text.strip()
return text
def tokenize_with_mecab(text):
try:
import ipadic
mecab = MeCab.Tagger(ipadic.MECAB_ARGS + " -Owakati")
except Exception:
mecab = MeCab.Tagger("-Owakati")
parsed = mecab.parse(text)
if parsed is None:
return []
return parsed.strip().split()
def build_vocab(tokens):
vocab = sorted(list(set(tokens)))
stoi = {token: i for i, token in enumerate(vocab)}
itos = {i: token for i, token in enumerate(vocab)}
return stoi, itos
#====================================================
# 5. 学習関数
#====================================================
def train_model(model, dataloader, criterion, optimizer, device):
model.train()
total_loss = 0
for batch_idx, (x, y) in enumerate(dataloader):
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
logits, _ = model(x)
loss = criterion(logits.transpose(1, 2), y)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
#====================================================
# 6. 生成関数
#====================================================
def generate_text(model, stoi, itos, device, prompt="", max_length=50):
model.eval()
prompt_tokens = tokenize_with_mecab(prompt)
input_ids = [stoi.get(token, 0) for token in prompt_tokens if token in stoi]
if len(input_ids) == 0:
input_ids = [0]
input_tensor = torch.tensor([input_ids], dtype=torch.long).to(device)
hidden = None
generated_tokens = [itos[idx] for idx in input_ids]
with torch.no_grad():
for _ in range(max_length):
logits, hidden = model(input_tensor, hidden)
last_logits = logits[0, -1, :]
probs = torch.softmax(last_logits, dim=0).cpu().numpy()
next_id = np.random.choice(len(probs), p=probs)
generated_tokens.append(itos[next_id])
input_tensor = torch.tensor([[next_id]], dtype=torch.long).to(device)
return ' '.join(generated_tokens)
#====================================================
# 実行ブロック
#====================================================
if not os.path.exists(Config.FILE_PATH):
raise FileNotFoundError(f"{Config.FILE_PATH} が見つかりません")
with open(Config.FILE_PATH, 'r', encoding='utf-8') as f:
raw_text = f.read()
text = preprocess_text(raw_text)
tokens = tokenize_with_mecab(text)
print(f"Original Text Length: {len(raw_text)}")
print(f"Token Count: {len(tokens)}")
if len(tokens) < Config.SEQ_LEN + 1:
print("エラー: テキストが短すぎて学習できません。")
else:
stoi, itos = build_vocab(tokens)
vocab_size = len(stoi)
print("Vocabulary Size:", vocab_size)
indexed_data = [stoi[token] for token in tokens]
dataset = TextDataset(indexed_data, Config.SEQ_LEN)
dataloader = DataLoader(dataset, batch_size=Config.BATCH_SIZE, shuffle=True)
model = RNNModel(
vocab_size=vocab_size,
embed_dim=Config.EMBED_DIM,
hidden_dim=Config.HIDDEN_DIM,
num_layers=Config.NUM_LAYERS
).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=Config.LEARNING_RATE)
print("\nTraining Start...")
for epoch in range(Config.EPOCHS):
loss = train_model(model, dataloader, criterion, optimizer, device)
print(f"Epoch [{epoch+1}/{Config.EPOCHS}] - Loss: {loss:.4f}")
print("Training Finished.\n")
test_prompts = ["私", "先生", "海"]
print("--- 生成結果サンプル ---")
for p in test_prompts:
gen = generate_text(model, stoi, itos, device, prompt=p, max_length=Config.MAX_LEN_GENERATION)
print(f"\nPrompt: {p}")
print(f"Generated: {gen}")
こちらのコードの実行結果は次の通りです。
Using device: cuda
Original Text Length: 314980
Token Count: 165766
Vocabulary Size: 13169
Training Start...
Epoch [1/5] - Loss: 3.2621
Epoch [2/5] - Loss: 1.1535
Epoch [3/5] - Loss: 0.7392
Epoch [4/5] - Loss: 0.6130
Epoch [5/5] - Loss: 0.5555
Training Finished.
--- 生成結果サンプル ---
Prompt: 私
Generated: 私 は 見 た でしょ う 昔 という もの が 無い あの 薬屋 は もう いや 一 日 一 日 一 者 の 子供 たち と 外 が 寒く て いけ ねえ かず子 ああ 自分 はね 昔 から だ が どうも いつ だ から 始末 だ ん か と 子供 で 絶望 の 酔い 特有 の 直治 な おじ が いつか お 酒 を 飲み ながら 姉 に 冷たく し なけれ ば なら ない 天気 の 良い 日 を 選ん で 行く ここ の バス の 女 車掌 は 遊覧 客 といふ 所 謂 つ ぽ つた つ たとい いい やう
Prompt: 先生
Generated: 先生 たち は お 照 さん に 怒ら れ て しまう に … … お母さま は 拒否 借り て 帰っ て 来 た ふう の 新 知識 を め た の は お母さま が 嘘 昨夜 の 感じ です か ? 私 に は いま と いい ほとんど か つ て 下さい な ので お母さま は お座敷 の 隅 すみ の 新宿 の 傍 に 坐り 硝子 事 でし た 中央 地区 と 言っ た か 何 地区 と 言っ た か おれ も 思わず 私 は 噴き出し た の だ お 照 さん は ここ へ 来 て 遠慮 なんか
Prompt: 海
Generated: 海 を する の を 聞い た 事 が あり ます けれども 女 に は からきし 意気地 が 無い ん です ね いやいや 高貴 な お方 に もはや て も 何 を し て も そんなに 驚嘆 し て 隠し て 行き ませ ん でし た 自分 は 銀座 の 部屋 と も 見え て 自分 は 彼 を 極度 と 人 より は 上品 を 見つけ 半 遠く から もつ と 柔か では かなくさう し て へん に 嫋々 たる 余韻 が ある 菊 の 露 薄 ごろ も 夕 空き ぬた 浮寝 きぎ す どれ で も ない 風流
どうでしょうか?
生成された文章は一見すると日本語の文法的には破綻していませんが、文脈が途中から脱線したり、話題が唐突に飛んだりしており、「長い文章の途中で何を話していたか」をうまく覚え続けられていないことが分かります。
このように、RNN では入力が長くなるにつれて、だんだんと過去の情報を保持したり更新したりすることが難しくなる、という性質があります。
Transformerは後述するSelf-Attention機構によって、系列内の任意の要素間の関係性を距離に依存せず直接的に計算するため、離れた要素間の依存関係を効果的に捕捉することが可能です。
3. Transformerの基本アーキテクチャ
Transformerのアーキテクチャは、主として「Encoder(エンコーダ)」と「Decoder(デコーダ)」という2つの主要モジュールによって構成されています。なお、本稿の主題であるGPTシリーズは、このアーキテクチャのうちDecoderモジュールのみを採用した「Decoder-only」モデルです。Decoderの自己回帰的な性質を利用することで、高精度なテキスト生成を実現しています。
-
Encoder: 入力系列(単語トークンの列)を処理し、高次元の文脈表現ベクトルへと変換する役割を担う。
-
Decoder: Encoderによって生成された文脈表現ベクトルを参照しつつ、自己回帰的に次のトークンを予測し、出力系列を生成する。
以下の画像にTransformerの構成図を示します。ちなみに、通常Transformerはこのブロックが何層にも積み重なり構成されています。

引用元:Vaswani, A. et al.(2017) Attention Is All You Need
また、図から分かるようにTransformerは、以下の6つの要素により構成されています。上から入力→出力順に要素を紹介します。
- 位置符号...トークンの「並び順・位置」の情報をベクトルとして埋め込みに足し込む仕組みです。
- QKV注意機構(マルチヘッド注意機構)...各トークン同士がどこにどれだけ注目するかを、Query・Key・Value という3種類のベクトルを使って計算する仕組みです。
- 残差結合...あるブロックの入力を出力に足し戻すことで、情報を素通ししつつ「差分」だけを学習しやすくするための経路です。
- 層正規化...各層の出力のスケールや分布を整えて、学習を安定させるための正規化処理です。
- フィードフォワード層...各トークンごとに同じ小さな全結合ネットワークを通し、特徴量を非線形に変換して表現力を高める層です。
次の節では、特にQKV注意機構について解説していきたいと思います。
4. 中核的機構としての「Self-Attention(自己注意機構)」
Transformerの性能を決定づける中核的な技術が「Self-Attention」です。これは概念的に表現すれば、「文章が自分自身の中の関係性を学ぶ」メカニズムであると言えます。具体的に、以下の数式で定義される「Scaled Dot-Product Attention」によって表現されます。
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
この抽象的な数式の意味を、「I love cat」という入力系列を例に、具体的な4つの処理ステップに分解して解釈します。
ステップ1:単語のベクトル化と位置情報の付加
まず、入力されたテキストを単語(トークン)ごとに連続値ベクトルへ変換し、系列内の順番を示す位置情報を付加します。
ステップ2:Q、K、Vベクトルの生成
次に、各トークンのベクトルに対して学習可能な重み行列($W_Q, W_K, W_V$)を乗算し、役割の異なる3つのベクトル、すなわちQuery($Q$:検索クエリ)、Key($K$:キー、索引)、およびValue($V$:バリュー、情報)を生成します。

ステップ3:「誰が」「誰を」参照するかの計算(関連度の算出)
続いて、Query行列($Q$)とKey行列の転置($K^T$)の内積を計算し、$d_k$(Keyの次元数)の平方根でスケーリングを行います。これにより、系列内の各トークン間の「関連度(類似度)」が算出されます。
この関連度行列に対して行ごとに ソフトマックス関数 を適用します。これにより、スコアの和が1となるように正規化され、「誰が(行)」、「誰を(列)」どれだけ参照すべきかを示す「Attention Weight(注意重み)」が得られます。
ステップ4:文脈を取り込んだ表現の完成
最後に、ステップ3で得られたAttention Weightと、Value行列($V$)の行列積を計算します。前述の例において、「love」の最終的な出力表現は、各トークンのValueベクトルを注意重みで加重平均した値($0.05 \times V_{\text{I}} + 0.10 \times V_{\text{love}} + 0.85 \times V_{\text{cat}}$)となります。すなわち、「love」という単語の表現に、「cat」の情報が85%混入されることになります。
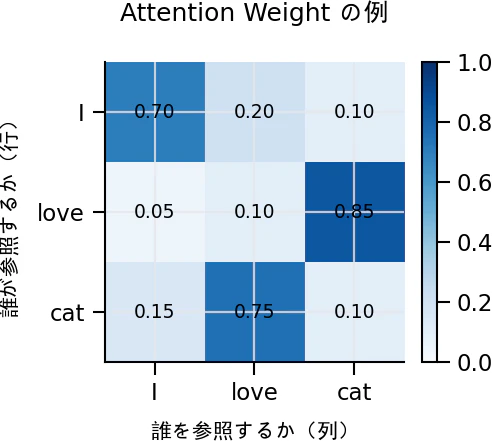
結果として、各単語は文脈から独立した記号としてではなく、周囲の情報の関連度に応じて動的に重み付け加算された、文脈ベクトルとして獲得されるのです。
5. GPTの「事前学習」プロセス:自己教師あり学習と最尤推定
Transformerアーキテクチャを備えたモデルが「GPT」として機能するためには、大規模な 事前学習(Pre-training) のプロセスが不可欠です。
GPTの事前学習は、ラベル付けされたデータを用いない自己教師あり学習の形式をとります。具体的には、インターネット上の膨大なテキストデータを入力とし、「与えられた先行文脈から、次に出現する単語(トークン)を予測する」という極めて単純なタスクを反復的に解かせる仕組みを取ります。このプロセスは、統計的機械学習における最尤推定の枠組みに基づいています。(最尤推定の解説については省略させていただきます。)モデルは先行文脈($x_1, x_2, \dots, x_{t-1}$)に基づき、次のトークン($x_t$)が出現する条件付き確率 $P(x_t | x_1, \dots, x_{t-1}; \theta)$ をモデル化します。ここで $\theta$ は、ニューラルネットワークを構成するパラメータ群です。
最適化の観点から、学習データセットに含まれる正解系列 $X = (x_1, \dots, x_T)$ が生成される同時確率(尤度)を最大化するため、尤度関数の対数をとり符号を反転させた負の対数尤度(Negative Log-Likelihood; NLL)を損失関数(Loss) $\mathcal{L}(\theta)$ として定義します。
$$\mathcal{L}(\theta) = - \sum_{t=1}^{T} \log P(x_t | x_1, \dots, x_{t-1}; \theta)$$
実際の学習プロセス(誤差逆伝播法)においては、この損失関数 $\mathcal{L}(\theta)$ のパラメータ $\theta$ に対する勾配(Grad)を計算し、その勾配情報を用いてパラメータを反復的に更新します。すなわち、正解トークンに対する予測確率が1に近づくほど対数尤度の値は0に漸近します。この「次単語予測」のプロセスを数千億トークンといった規模で最適化し続けることにより、GPTは単なる単語の出現確率を超え、文法規則、事実知識を内部パラメータ $\theta$ に「事前学習」として埋め込むのです。
6.まとめ
本稿では理論的な解説として、GPTの基盤技術であるTransformerの概要、その優位性を支える並列処理性能およびSelf-Attentionの数学的機構、ならびに最尤推定に基づく学習の最適化プロセスについて概説しました。
次稿においては、本稿で構築した理論的基礎に基づき、GPTの基本構造を約200行のPythonコードで実装した「microgpt」を対象とし、具体的な学習プロセスおよび推論プロセスについて、コードレベルでの詳細な分析を試みる予定です。
7.引用元
・https://service.shiftinc.jp/column/11655/
株式会社SHIFTさんのRNNについての概説です
・https://note.com/koshi_ai/n/n7c0a3e3f5203
こちらは「コシ」さんという方が書いたnote記事です.RNNが長期依存が苦手であることを、図を用いて説明してくださってます。
・https://omomuki-tech.com/archives/6226
ソフトマックス関数についての概要です。ディープラーニングにおける役割を分かりやすく解説しています。