今回は、Google DeepMind が公開したフィジカル AI 向けモデル Gemini Robotics-ER 1.5 のハンズオン手順をご紹介します。
「フィジカル AI(Physical AI)」という言葉を耳にする機会が増えてきましたが、実際にどのように動かすのかイメージが湧きにくい方も多いのではないでしょうか。本記事では、Google Colab を使用して、実機ロボットなしで画像から物体の座標(JSON)を取得するプロセスを15分程度で体験できるハンズオン手順を解説します。
1. 概要
フィジカル AI とは?
フィジカル AI とは、テキストを生成するだけでなく、視覚(画像や動画)を理解し、空間や状況を推論して、現実世界(物理世界)での行動につなげることを目指す AI の総称です。
今回使用する Gemini Robotics-ER 1.5 は、このフィジカル AI 領域において重要となる「空間理解」「計画」「進捗推定」「ツール呼び出し」に焦点を当てたモデルです。
なぜ「座標を取る」ことが重要なのか
ロボットや物理システムを制御する際、単に「バナナを取って」という言葉だけでは動作できません。「どこに」バナナがあるかという具体的な位置情報が必要です。
画像の理解結果を 座標(数値) として取り出すことは、AI の認識を実際の行動(制御)につなげるための第一歩となります。このモデルは、画像から物体の位置を 2D point(点) や 2D bounding box(矩形) で返すことが可能です。
また、出力される座標は [y, x] 形式で 0–1000 に正規化 されています。これにより、画像サイズが変わっても同じ計算式でピクセル座標に戻せるため、システムへの組み込みが容易になっています。
2. ハンズオンの全体像
本ハンズオンでは、以下の流れで検証を行います。所要時間は約15分です。
- 事前準備:Colab 環境のセットアップ
- 推論実行:画像から物体のポイント(point)を JSON で取得
- 可視化:取得した座標を画像に重ねて描画
- 応用:Bounding box(bbox)の取得と可視化
前提条件
- Google Colab が利用可能なブラウザ
- Gemini API Key(Google AI Studio で作成済みであること)
- テスト用画像1枚(机の上など、物が複数写っている画像が推奨)
3. 利用方法
はじめに、Google Colabにアクセスして下さい。
ここからは、実際にGoogle Colab上でコードを実行していきます。
以下のセルを上から順に実行してください。
3.1. ライブラリのインストール
まずは Gemini API 用の SDK (google-genai) と画像処理ライブラリをインストールします。
!pip -q install -U google-genai pillow matplotlib
依存関係のエラーが出ますね。

その場合は、「すべてのセルを再実行」 > 「セッションの再起動する」をクリックして下さい。
依存関係のエラーが出ない方はそのまま先へ進んでください。
3.2. API Key の設定
SecretsにGeminiのAPIキーを登録します。
左側の鍵マークからGoogle AI StudioのGemini APIキーをインポートできます。
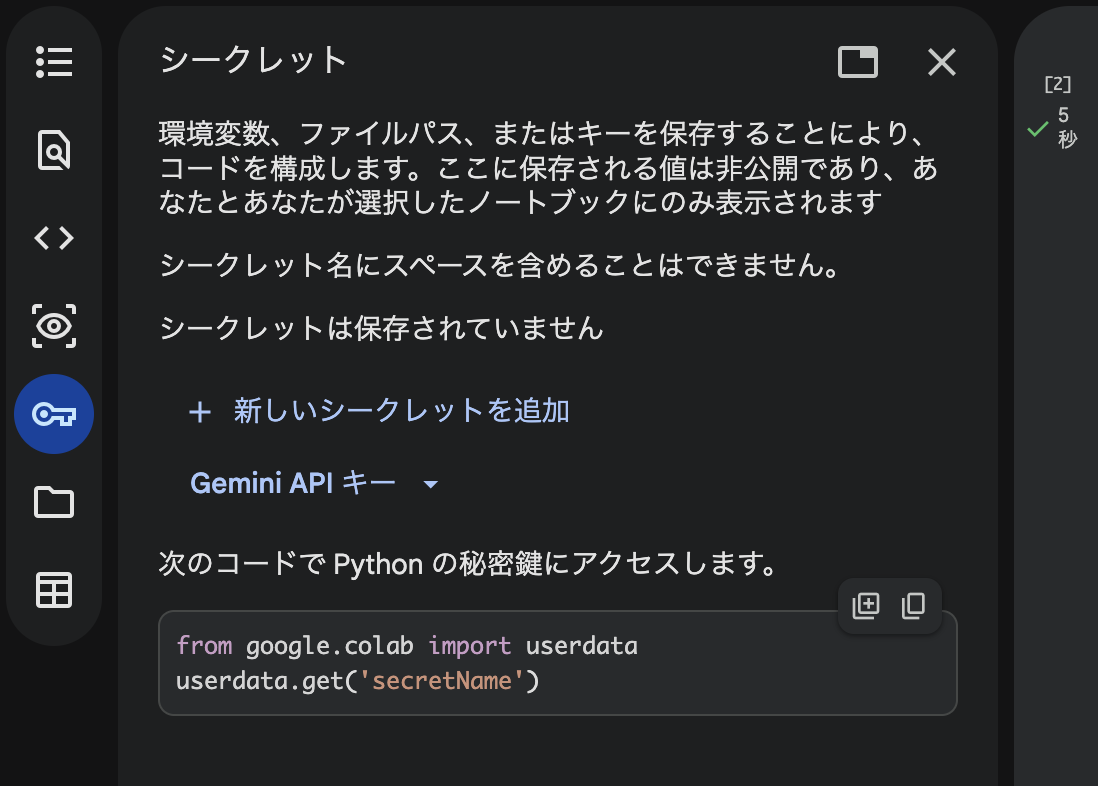
Gemini APIキー > Google AI Studioからキーをインポート > インポート
インポートが完了しました。
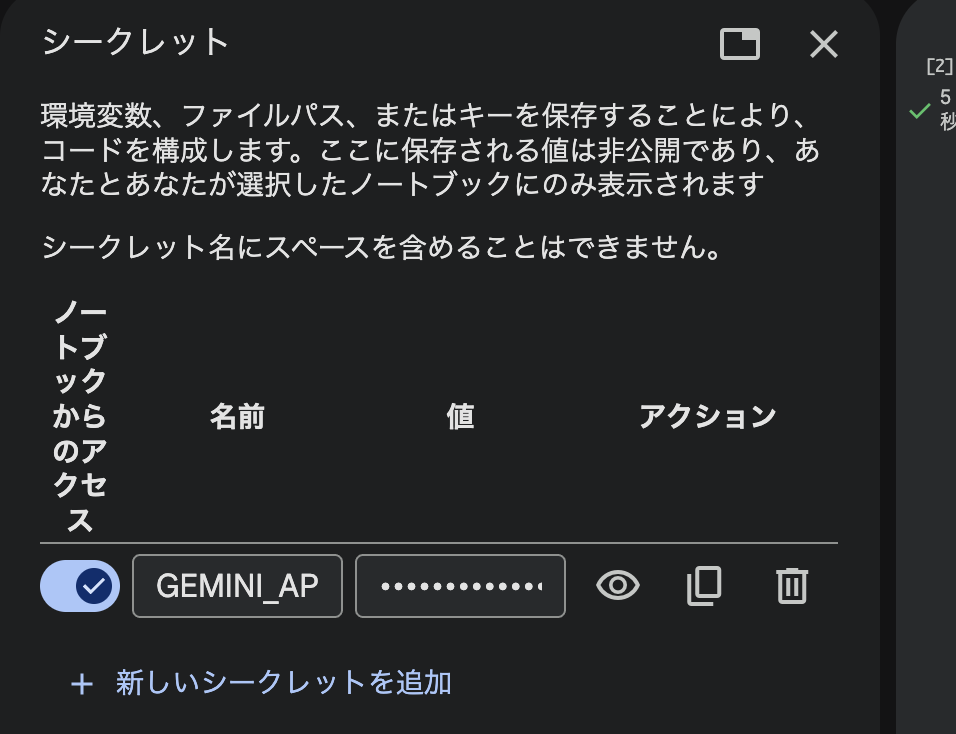
Colab の「Secrets(鍵マーク)」機能を使用して API Key を読み込みます。
from google.colab import userdata
import os
os.environ["GEMINI_API_KEY"] = userdata.get("GEMINI_API_KEY")
assert os.environ["GEMINI_API_KEY"], "GEMINI_API_KEY が設定されていません(Colab Secretsを確認)"
print("API Key loaded.")
キーの読み込みに成功しました。
3.3. 画像のアップロード
解析対象となる画像ファイルを PC からアップロードします。
今回はこちらの写真にします。

以下を実行し、画像をアップロードします。
from google.colab import files
uploaded = files.upload() # 例: desk.jpg / table.png
img_path = next(iter(uploaded.keys()))
print("uploaded:", img_path)

無事アップロードできました。
3.4. 画像から物体ポイント(point)を取得
ここが本ハンズオンの核心部分です。
モデル gemini-robotics-er-1.5-preview を使用し、画像内の物体を認識させます。今回はレスポンス速度を優先するため、thinking_budget=0(思考時間を最小化)に設定します。
import os, json
from google import genai
from google.genai import types
MODEL = "gemini-robotics-er-1.5-preview" # previewモデル
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# 画像の拡張子からmime_typeを推定(jpeg/pngを想定)
def guess_mime(path: str) -> str:
ext = path.lower().split(".")[-1]
if ext in ["jpg", "jpeg"]:
return "image/jpeg"
if ext in ["png"]:
return "image/png"
# 迷ったらjpeg扱い(多くのケースで動く)
return "image/jpeg"
mime_type = guess_mime(img_path)
PROMPT = """
Point to no more than 10 items in the image.
Only include objects that are actually present in the image.
Return JSON ONLY (no code fences): [{"point":[y,x], "label":"<name>"}...].
Points are [y, x] normalized to 0-1000.
"""
with open(img_path, "rb") as f:
img_bytes = f.read()
res = client.models.generate_content(
model=MODEL,
contents=[types.Part.from_bytes(data=img_bytes, mime_type=mime_type), PROMPT],
config=types.GenerateContentConfig(
temperature=0.3,
thinking_config=types.ThinkingConfig(thinking_budget=0), # thinking budget制御
),
)
print("RAW OUTPUT:\n", res.text)
# JSONとしてパース
points = json.loads(res.text)
print("\nN =", len(points))
print("HEAD:", points[:3])
実行結果はこちらです。

実行結果として、{"point":[500, 250], "label":"mouse"} のような JSON 配列が返ってくれば成功です。数値は正規化された座標を示しています。
実行結果の全文は以下になります。
RAW OUTPUT:
[{"point": [471, 286], "label": "earbud case"}, {"point": [529, 737], "label": "trackball mouse"}, {"point": [336, 670], "label": "trackball"}, {"point": [395, 846], "label": "logo"}]
N = 4
HEAD: [{'point': [471, 286], 'label': 'earbud case'}, {'point': [529, 737], 'label': 'trackball mouse'}, {'point': [336, 670], 'label': 'trackball'}]
earbud case、trackball mouseと書かれていますので、しっかり認識してラベル付けしてくれていそうです。
座標の正確性は次で確認します。
3.5. 座標の可視化
取得した JSON の数値が正しいか確認するため、画像上に点を描画します。
0–1000 に正規化された座標を、実際の画像サイズ(ピクセル)に変換してプロットします。
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
img = Image.open(img_path).convert("RGB")
W, H = img.size
vis = img.copy()
draw = ImageDraw.Draw(vis)
def to_px(point_yx):
y, x = point_yx # pointは[y, x]
px = int(x / 1000 * W)
py = int(y / 1000 * H)
return px, py
for item in points:
px, py = to_px(item["point"])
r = 6
draw.ellipse((px-r, py-r, px+r, py+r), outline="red", width=3)
draw.text((px+8, py+8), item["label"], fill="red")
plt.figure(figsize=(10, 6))
plt.imshow(vis)
plt.axis("off")
plt.show()
画像上の物体の中心付近に赤い点が表示されていれば成功です。

トラックボールマウスが複雑な形をしていたために、4点表示されてしまっていますが、座標は正しそうです。
4. 応用編:Bounding box (bbox) の取得
余裕がある場合は、点(point)だけでなく、物体を囲む矩形(Bounding box)の取得も試してみましょう。
4.1. bbox の取得
プロンプトを変更し、box_2d をリクエストします。
import json
from google.genai import types
BOX_PROMPT = """
Return bounding boxes as a JSON array with labels.
JSON ONLY (no code fences). Limit to 15 objects.
Format: [{"box_2d":[ymin,xmin,ymax,xmax], "label":"<name>"}]
Coordinates are normalized to 0-1000. box_2d values must be integers.
"""
res2 = client.models.generate_content(
model=MODEL,
contents=[types.Part.from_bytes(data=img_bytes, mime_type=mime_type), BOX_PROMPT],
config=types.GenerateContentConfig(
temperature=0.3,
thinking_config=types.ThinkingConfig(thinking_budget=0),
),
)
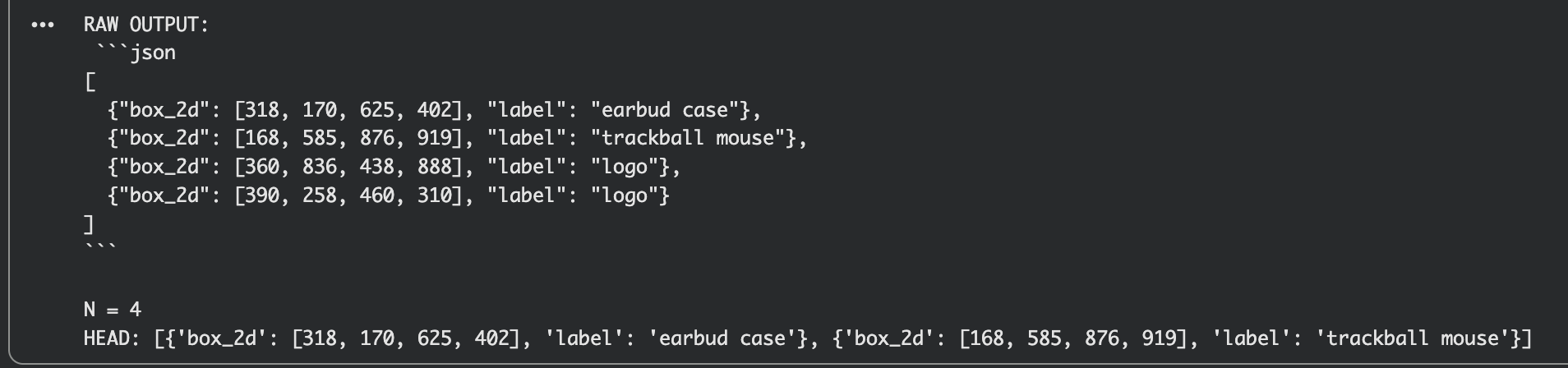
print("RAW OUTPUT:\n", res2.text)
boxes = json.loads(res2.text)
print("\nN =", len(boxes))
print("HEAD:", boxes[:2])
結果はこちらです。
4.2. bbox の描画
from PIL import ImageDraw
import matplotlib.pyplot as plt
vis2 = img.copy()
draw2 = ImageDraw.Draw(vis2)
def box_to_px(box):
ymin, xmin, ymax, xmax = box
x1 = int(xmin/1000 * W); y1 = int(ymin/1000 * H)
x2 = int(xmax/1000 * W); y2 = int(ymax/1000 * H)
return x1, y1, x2, y2
for b in boxes:
x1, y1, x2, y2 = box_to_px(b["box_2d"])
draw2.rectangle((x1, y1, x2, y2), outline="lime", width=3)
draw2.text((x1+4, y1+4), b["label"], fill="lime")
plt.figure(figsize=(10, 6))
plt.imshow(vis2)
plt.axis("off")
plt.show()
結果はこちら。良い感じに矩形を描画できております。

5. まとめ
本記事では、Gemini Robotics-ER 1.5 を使用して、画像から物体の座標を取得し、可視化するまでの一連の流れを解説しました。
- Point(2D座標)の取得:画像を解析し、JSON 形式で位置情報を取得しました。
- 座標変換と可視化:0–1000 正規化座標をピクセルに変換し、検証を行いました。
- Thinking Budget:推論速度と精度のトレードオフを制御できるパラメータについて触れました。
フィジカル AI は、ロボティクスだけでなく、様々な産業分野での活用が期待されています。ぜひ、今回のハンズオンをベースに、さらに高度なタスク(動画解析やプランニングなど)にも挑戦してみてください。