はじめに
みなさんこんにちは。
最近は「ローカルLLM」という言葉を見かける機会が増えました。
ただ、実際に触ろうとすると、PCやGPUが必要そうで少しハードルが高いと感じるかもしれません。
そこで今回は、3月31日にリリースされたGoogle DeepMindの「Gemma 4」をiPhoneで試してみます。
Gemma 4にはスマホ向けの軽量なモデルも用意されており、AI Edge GalleryというiOS/Androidアプリをインストールすることで、簡単に自分のスマホで動かすことができます。
今回はAI Edge Galleryを使って、Gemma 4のチャット機能、画像読み込み機能、Skills機能を試してみます。

ローカルLLMとは
AIの学習や実務において、ChatGPTなどのLLMサービスは当たり前のように使われるようになりましたが、「ローカルLLM」とは自分の端末や手元のマシンで直接動かすLLMのことです。今回のようにスマホで使うなら、iPhoneの中で推論が完結する形をイメージすると分かりやすいです。GoogleのGemmaモバイル向けドキュメントでも、GemmaはGoogle AI Edge GalleryやMediaPipe LLM Inference APIを通じて、モバイル端末上で動かせると案内されています。
普段よく使うLLMサービスは、サービス側のサーバーで推論を行うものが一般的です。一方でローカルLLMは、モデルを自分の端末側(オンデバイス)で動かします。AI Edge Galleryも、スマホでLLMを試すためのアプリとして提供されています。
また、ローカルLLMは端末内で推論が完結します。そのため、LLMを何回使おうが、無料です。無料で無限に使えます。
このような仕組みの違いから、ローカルLLMは「低遅延」や「プライバシー」の観点で大きな魅力があります。AI Edge Galleryも、“100% On-Device Privacy” や “No internet is required” を前面に出しています。
Gemma 4とは
今回使うGemma 4は、Google DeepMindが開発した最新のオープンモデルです。E2B / E4B / 26B MoE / 31B Denseの4つのサイズがあります。
このうちE2BとE4Bは、スマホやエッジデバイス向けのモデルです。Googleも、モバイル向けに低レイテンシ(低遅延)や省メモリを意識したモデルだと案内しています。Android向けの説明でも、Gemma 4 on Androidは高速化や省電力が強調されています。
Gemma 4は、テキストだけでなく画像も扱えます。さらに、E2BとE4Bは音声入力にも対応しています。Google公式ブログやGemma 4モデル概要でも、画像・動画・音声を含むマルチモーダル機能が説明されています。
今回は、その中でもスマホ向けの小さいモデルをiPhoneで試していきます。ローカルLLM入門として、かなり触りやすそうです。
Geminiとの違い
GemmaとGeminiは、名前が似ているので少しややこしいですね。Googleによると、Gemma 4はGemini 3と同じ研究・技術をもとにしたオープンモデルとのことです。
違いをざっくり言うと、GeminiはGoogleのサービス側(クラウド上)で使うモデルで、Gemmaは自分の環境(ローカル)でも動かしやすいオープンモデルです。今回のようにiPhoneで試せるのは、Gemmaならではの特徴です。
iPhoneでGemma 4を動かしてみる
さて、ここからが本題です。スマホでGemmaを動かす方法としてAI Edge Galleryというアプリが案内されています。今回は私のiPhone 17(無印)を使って、Gemma 4を動かしてみようと思います。
事前準備
・iPhoneはiOS 17以上が必要です。GitHubのREADMEでも、対応OSは「iOS 17 and up」と案内されています。
・今回はiPhone 17(無印)を利用します。
AI Edge Galleryをインストールする
App Storeから「Google AI Edge Gallery」を検索し、インストールします。
AI Edge Galleryは、Gemma 4を含むオンデバイスLLMを試すための、Google社製のiOS/Androidアプリです。
早速起動します。

無事に起動できました。
Gemma 4のモデルを入れる
モデル一覧からGemma 4系のモデルを選び、ダウンロードを開始します。
AI Edge Galleryはモデル管理機能を持っていて、モデルの追加や管理、ベンチマークができます。
iPhoneで試すなら、まずは小さいモデルから触ってみるのがよさそうです。GoogleはE2B / E4Bをモバイルやエッジ向けとして案内しています。
E2BとE4Bの違いは以下の通りです。
| モデル | ざっくりした違い |
|---|---|
| E2B | 速さ重視。maximum speed / lower latency 向け。2.54GB |
| E4B | 推論力重視。higher reasoning power / complex tasks 向け。3.61GB |
今回は軽そうな「Gemma-4-E2B-it」を利用します。
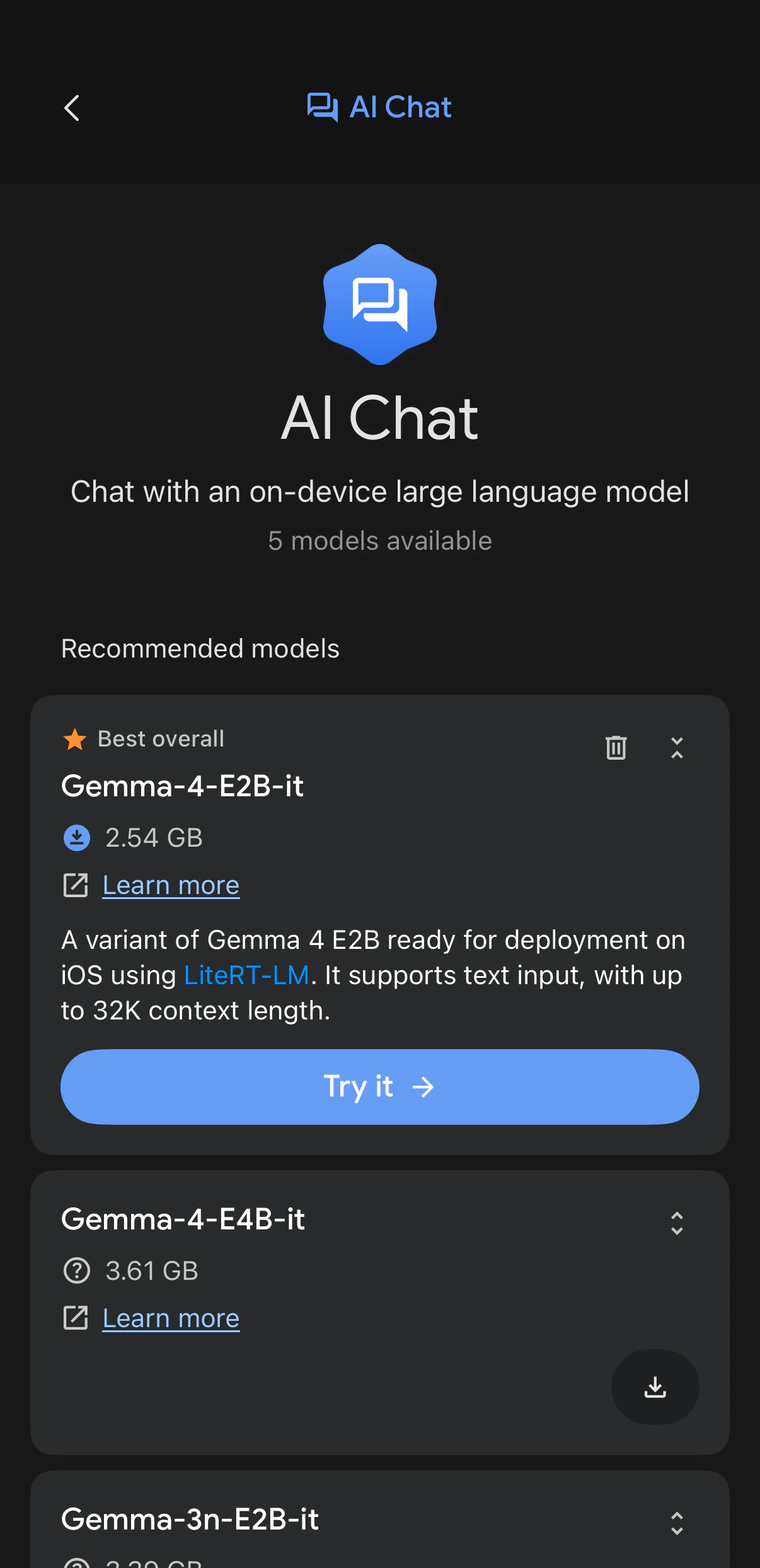
AI Chatで日本語を試す
AI Chatを開き、短い日本語で試します。
来週、松山旅行が控えているため、松山の観光プランを考えてもらいました。
しっかりとしたプランを提案してくれました。
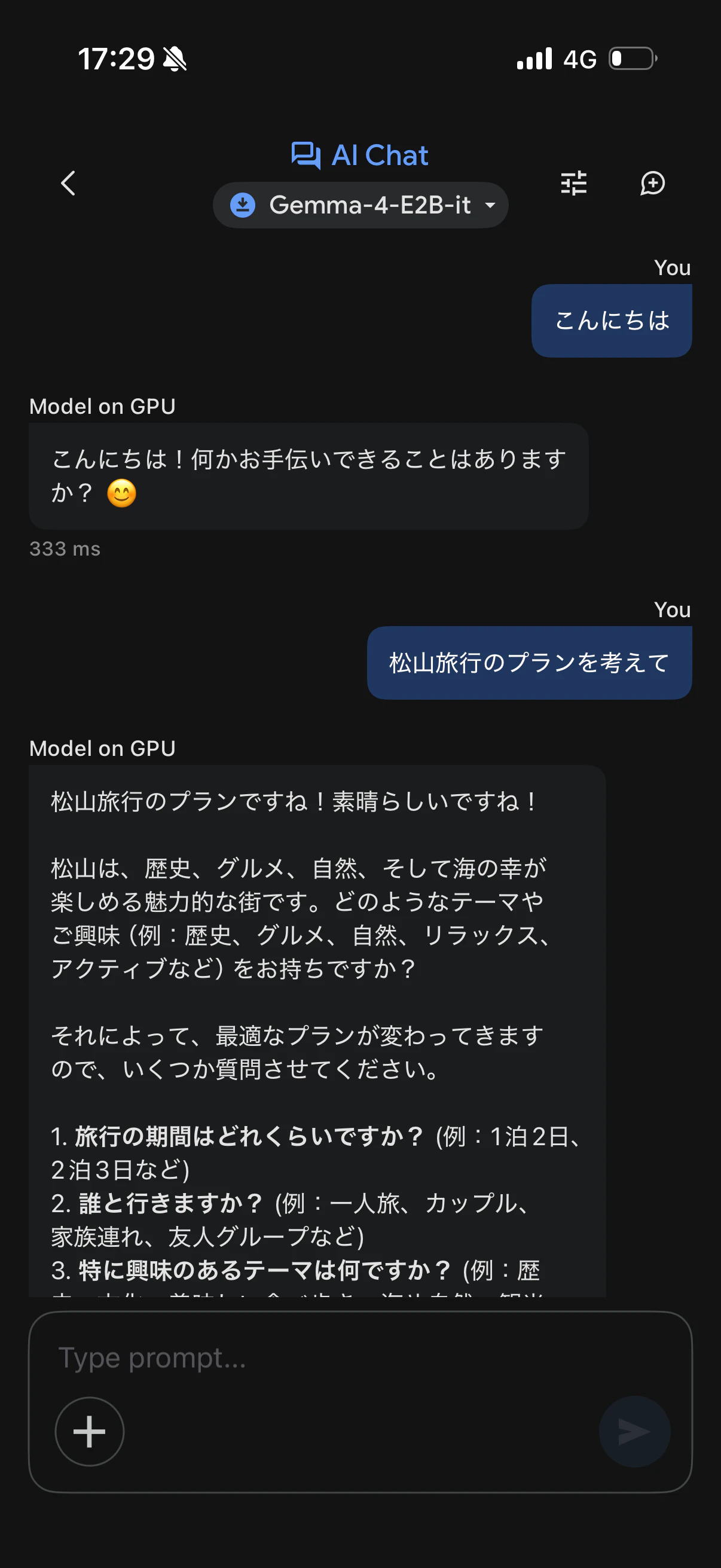
はじめてローカルLLMを使いましたが、返答が速いですね。
せっかくのローカルLLMですので、試しにオフラインにしてみます。
オフラインの状態でもしっかり回答してくれました。
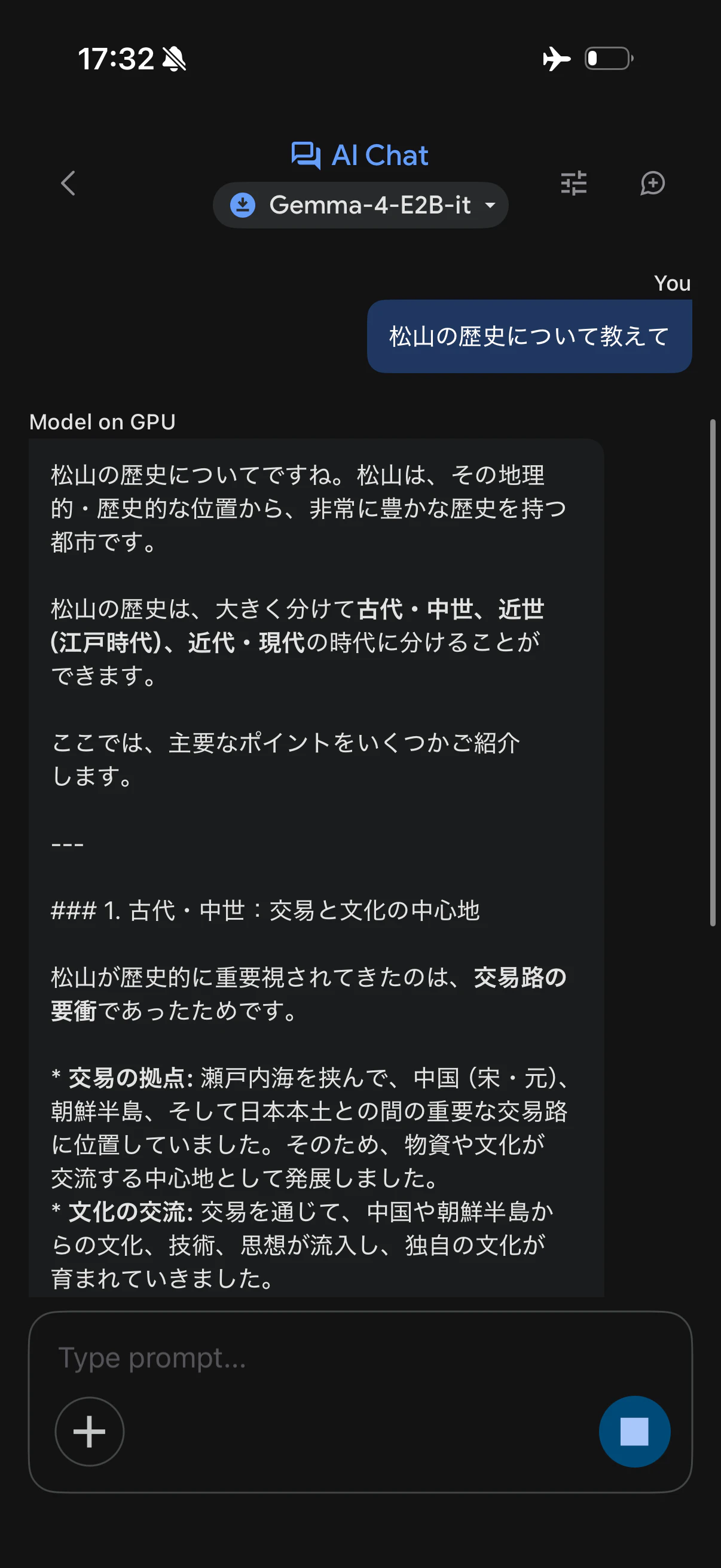
これで電波がないところでもGemmaくんにいろいろ相談できそうです。
山で遭難したときにも便利かも?
Ask Imageで画像理解を試す
Ask Imageを開き、写真を読み込ませます。Gemma 4は画像理解やOCR、チャート理解を強みとして案内されています。
先週、昭和記念公園でお花見をしました。そこで撮った花の写真について聞いてみます。
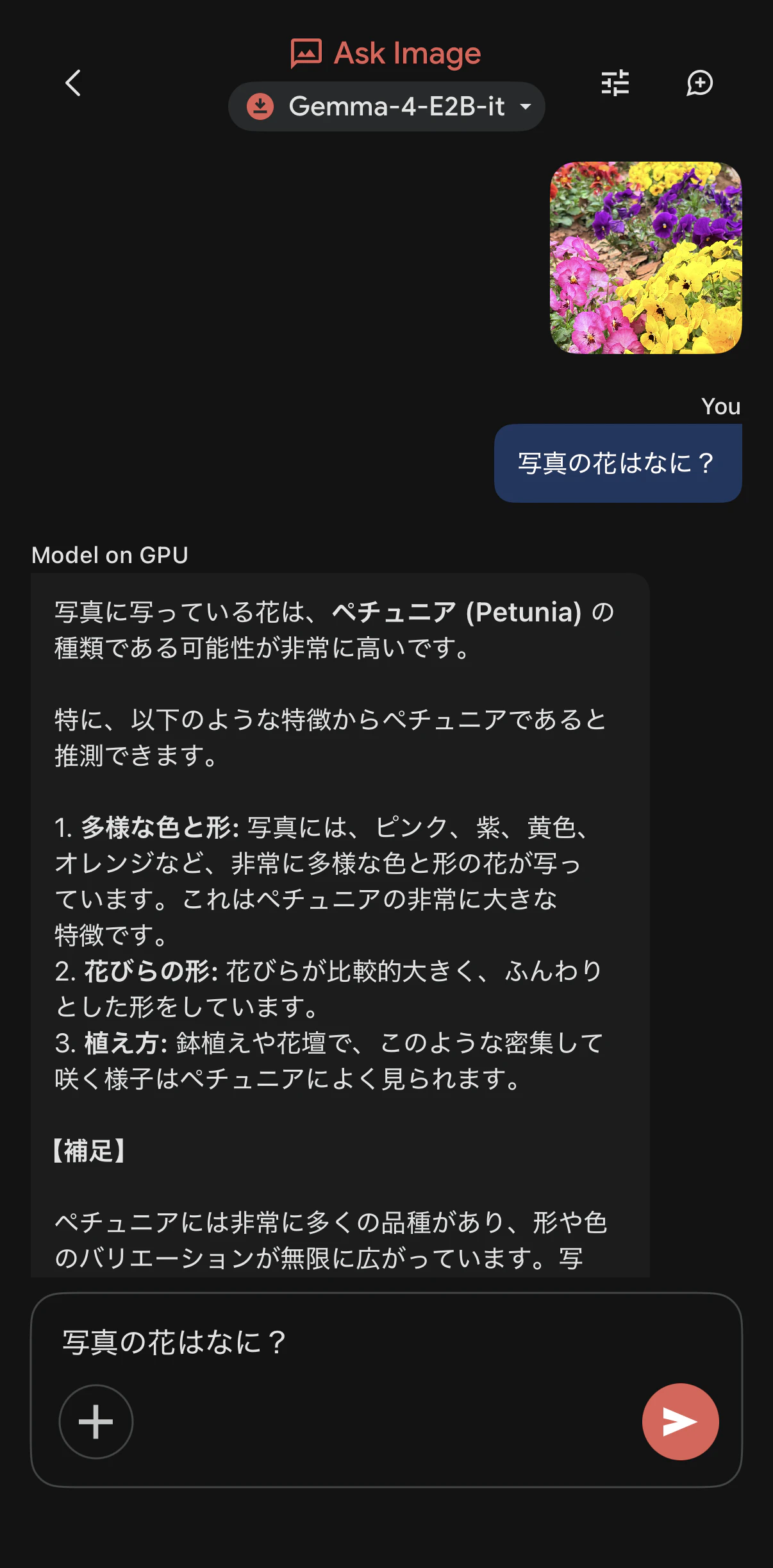
「ペチュニア」と言われました。
少し怪しいので、Geminiくんにセカンドオピニオンを求めてみます。
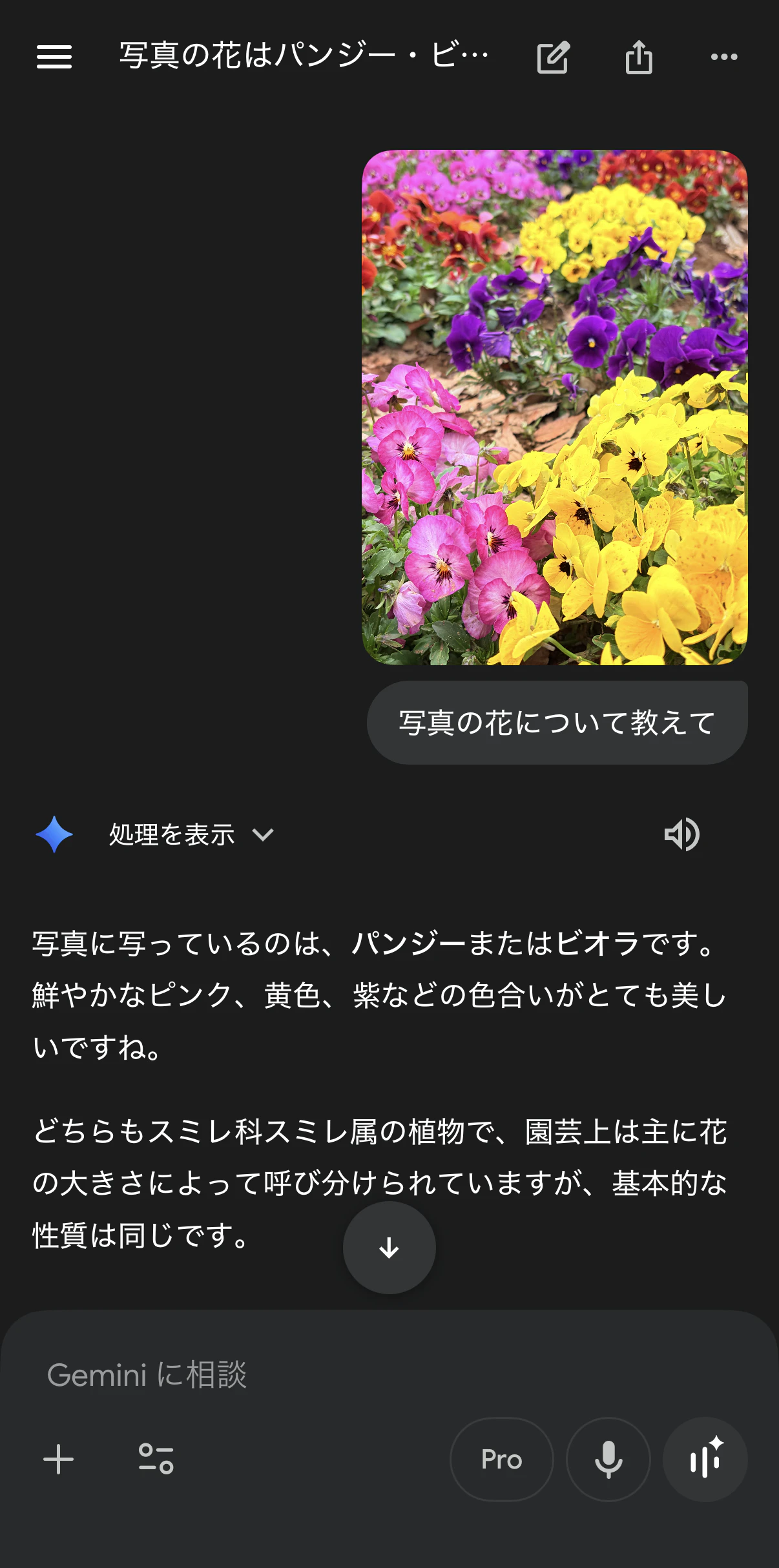
Gemini 3.1 Proくんは「ビオラ」と言っていますね。
どっちが正しいのでしょうか。
今回は速さ重視のE2Bモデルを使っていますが、もしかしたら推論重視のE4Bを使えばもっと精度が良くなるかもしれません。
Agent Skillsを試す
Agent Skillsを開きます。AI Edge Galleryでは、Gemma 4のエージェント的な使い方を試すための機能として案内されています。
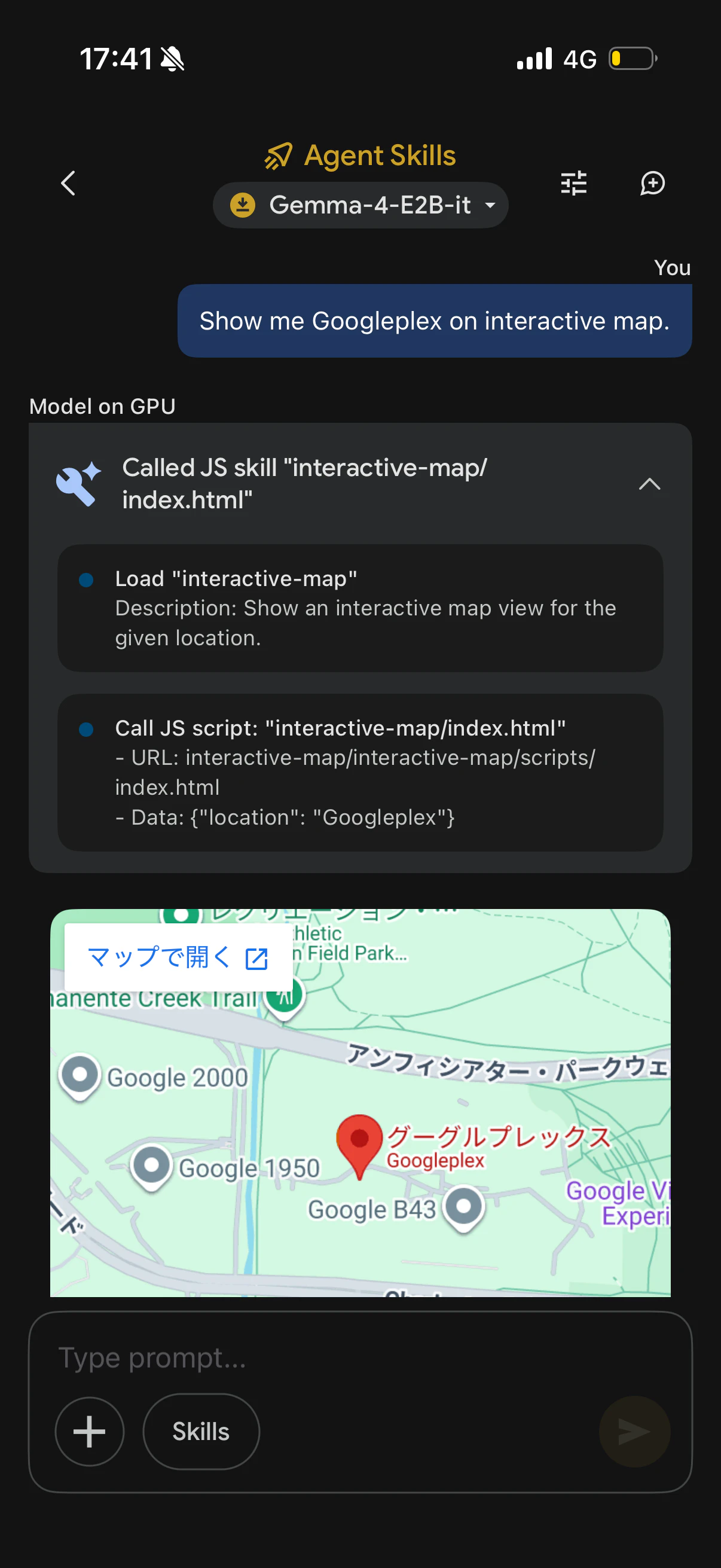
今回は「Interactive Maps」を使ってみようと思います。
来週の松山旅行では、下灘駅を見に行く予定です。
空港から下灘駅までのルートを聞いてみます。
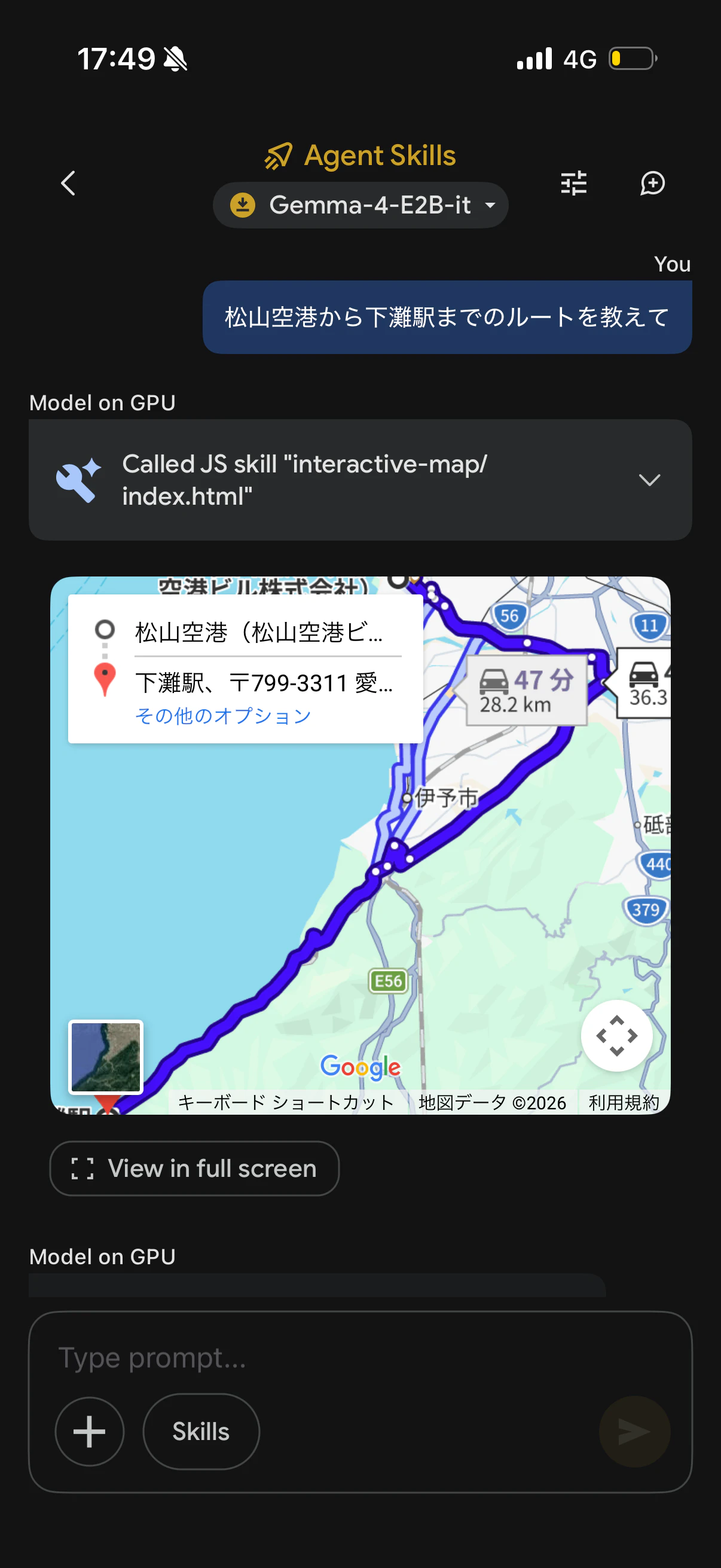
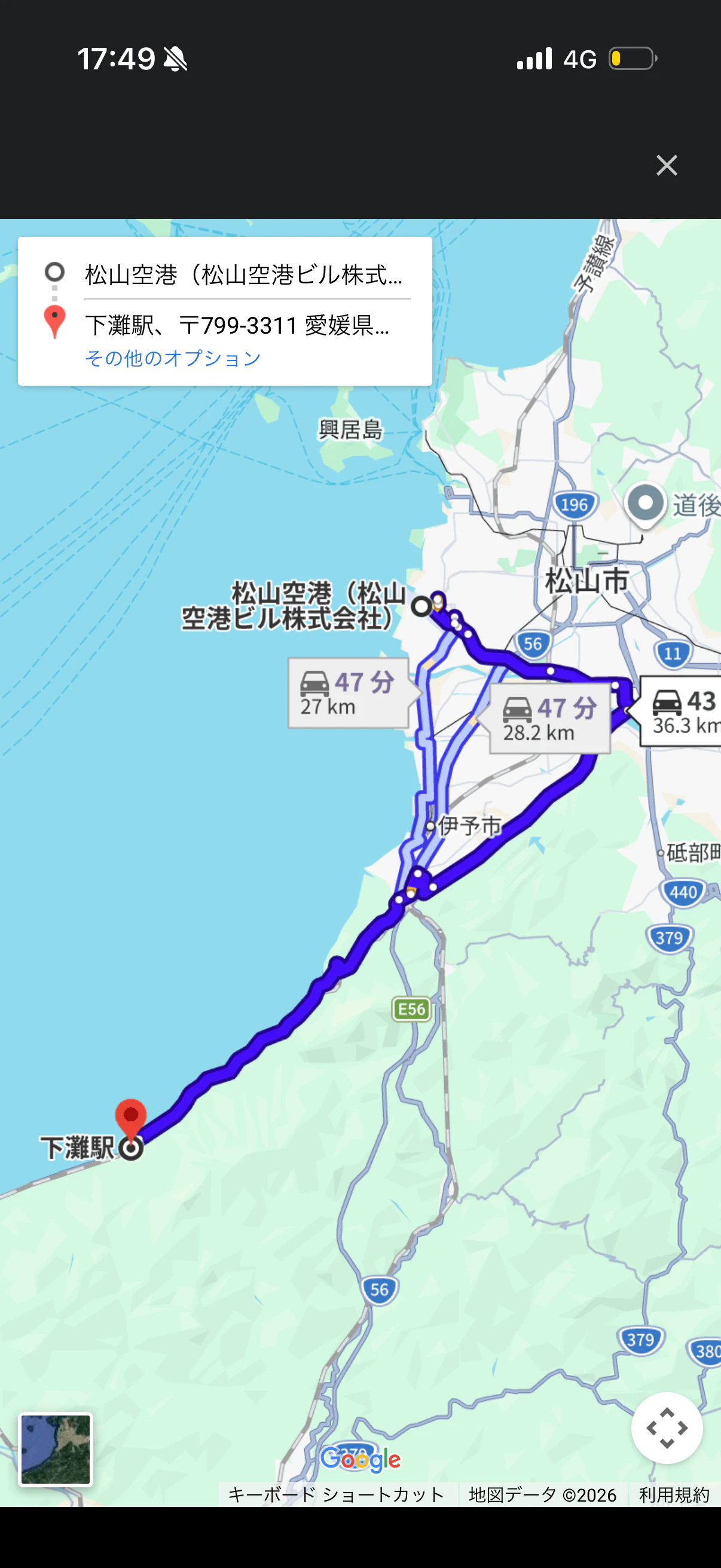
しっかりGoogle Mapsを表示して教えてくれました。Interactive Mapsのスキルを使ってくれたようです。
おわりに
Gemma 4を使ったiPhoneでの動作を試してみましたが、簡単な手順でiPhone上にローカルLLM環境を構築することができました。
個人がローカルLLMを試す際、高価なPCやGPUを用意したり、複雑な環境構築を行ったりするのは大きなハードルになりがちです。
しかし、スマホアプリだけでも簡単にオンデバイスLLMを体験できるため、みなさんもぜひ試してみてください!
また、先ほども述べましたが、ローカルLLMは端末内で推論が完結します。
そのため、LLMを何回使おうが、無料です。無料で無限に使えます。
何か面白い使い方ができないか、模索中です。