こんにちは。
今回は、企業向けの AI エージェントプラットフォームである Gemini EnterpriseのAgent Designerを使って、RAGを用いたシングルエージェントを構築するハンズオンを解説します。
1. 概要
Gemini Enterprise とは
Gemini Enterprise は、企業向けの「イントラネット検索 + AI アシスタント + エージェントプラットフォーム」です。安全な単一プラットフォーム上で、社内データに接続された AI エージェントを発見・作成・共有・実行できます。
組織内のデータ(ドキュメントやビジネスアプリ)にコンテキストを限定することで、セキュリティとガバナンスを維持したまま、業務に特化した AI 活用を可能にします。
本記事で実施すること
本ハンズオンのAIエージェンテーマは、
トラブル対応(インシデント)エージェントです。
要件:
- 現状をヒアリングして情報を揃える(必要最小限)
- 過去事例(データストア)を検索(RAG)して、最適な対応手順を提示
- 過去事例の根拠(どの事例のどの部分か)も提示する
以下のプロセスを通じて RAGを用いたシングルエージェントの構築を体験します。
- Cloud Storage へのドキュメント(過去の事例)の配置
- Gemini Enterprise アプリとデータストア(検索インデックス)の作成
- Agent Designer によるシングルエージェント構築
2. ハンズオン手順
データの準備とアップロード
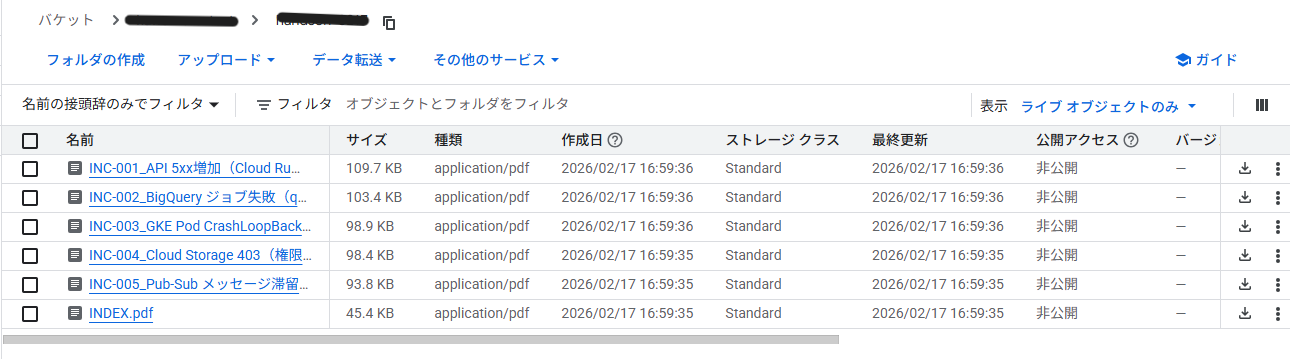
まず、RAGのインプットとなるデータ(過去事例)を用意し、Cloud Storage(GCS)にアップロードします。
GCS バケット(例: gs://[BUCKET_NAME]/handson/)を作成し、上記のファイルをアップロードしてください。Gemini Enterprise は PDF、HTML、TXT、Markdown などの非構造化ドキュメントを直接取り込むことが可能です。
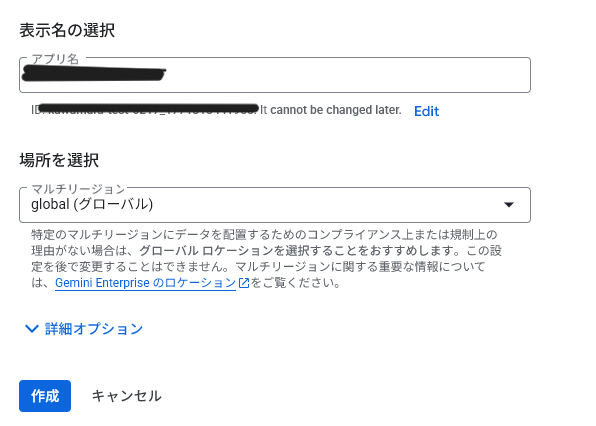
Gemini Enterprise アプリの作成
Google Cloud コンソールの Gemini Enterprise 画面からアプリを作成します。
- [アプリを作成] を選択
- アプリ名(例:
handson-test)を入力し、ロケーション(例:global)を選択して作成
Gemini Enterpriseの管理画面
データストアの作成とドキュメントの取り込み
作成したアプリ内に、検索インデックスとなるデータストアを構築します
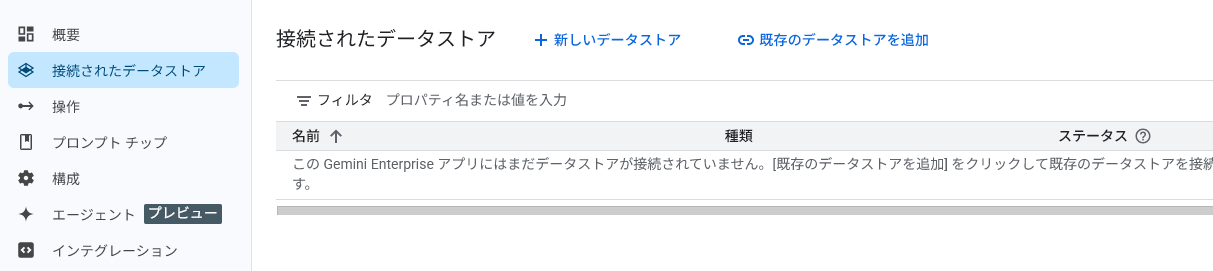
-
アプリ内で [新しいデータストア] を選択
-
データソースとして Cloud Storage を選択
-
データ種別に 非構造ドキュメント を指定し、GCS のインポートパスを入力
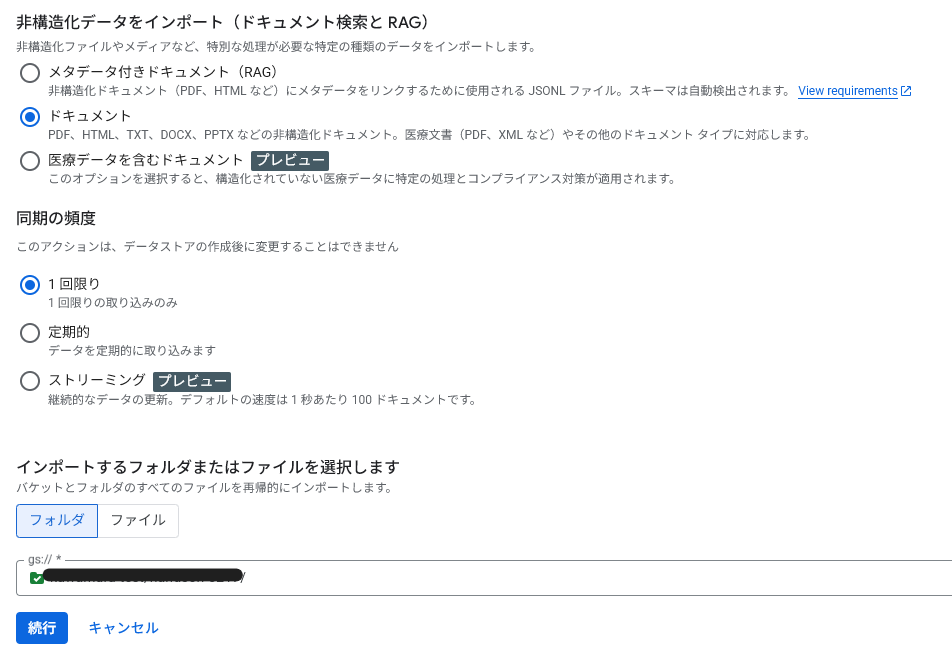
-
パース方式でレイアウトパーサーにを選択。
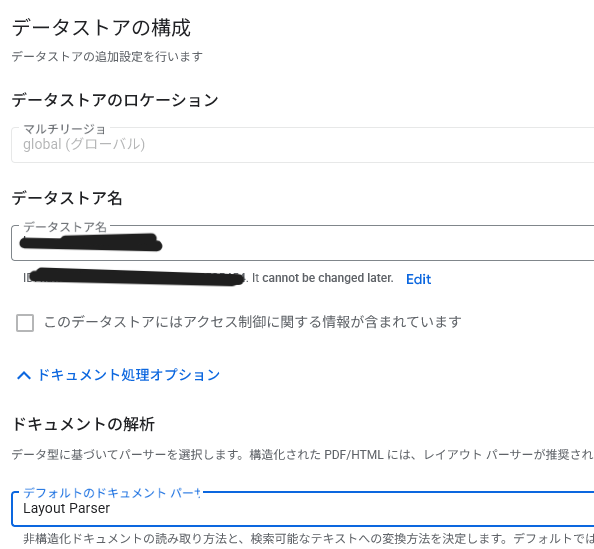
-
作成
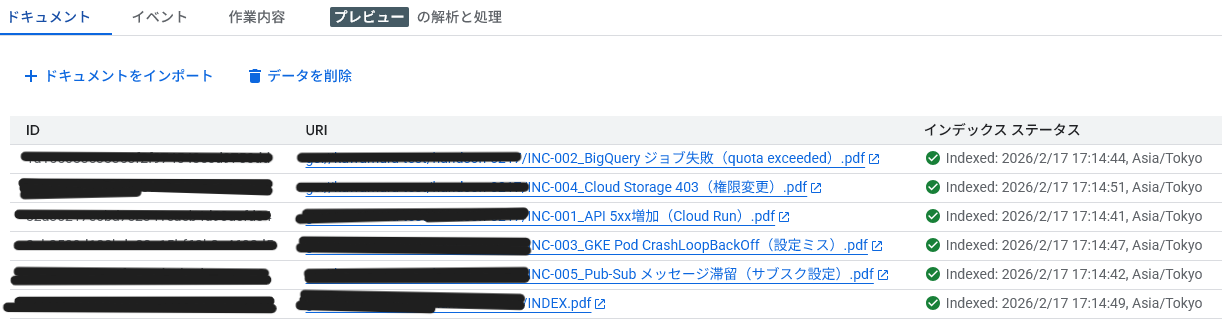
インデックス ステータスが「Indexed」になったことを確認し、次の手順へ進む。
Agent Designer によるエージェント構築
Gemini EnterpriseのAgent Designerを使って、シングルエージェントを構築します。
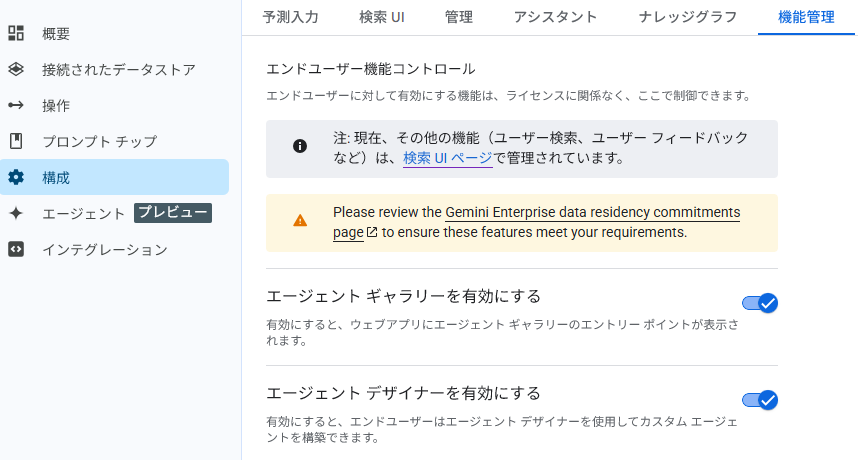
Agent Designer の有効化
構成 > 機能管理より、Agent Designerを有効化します。
エージェントの作成
- 概要 > URLからGemini Enterpriseを開く
2.新しいエージェントを作成からAgent Builder(Agent Designer)を開く
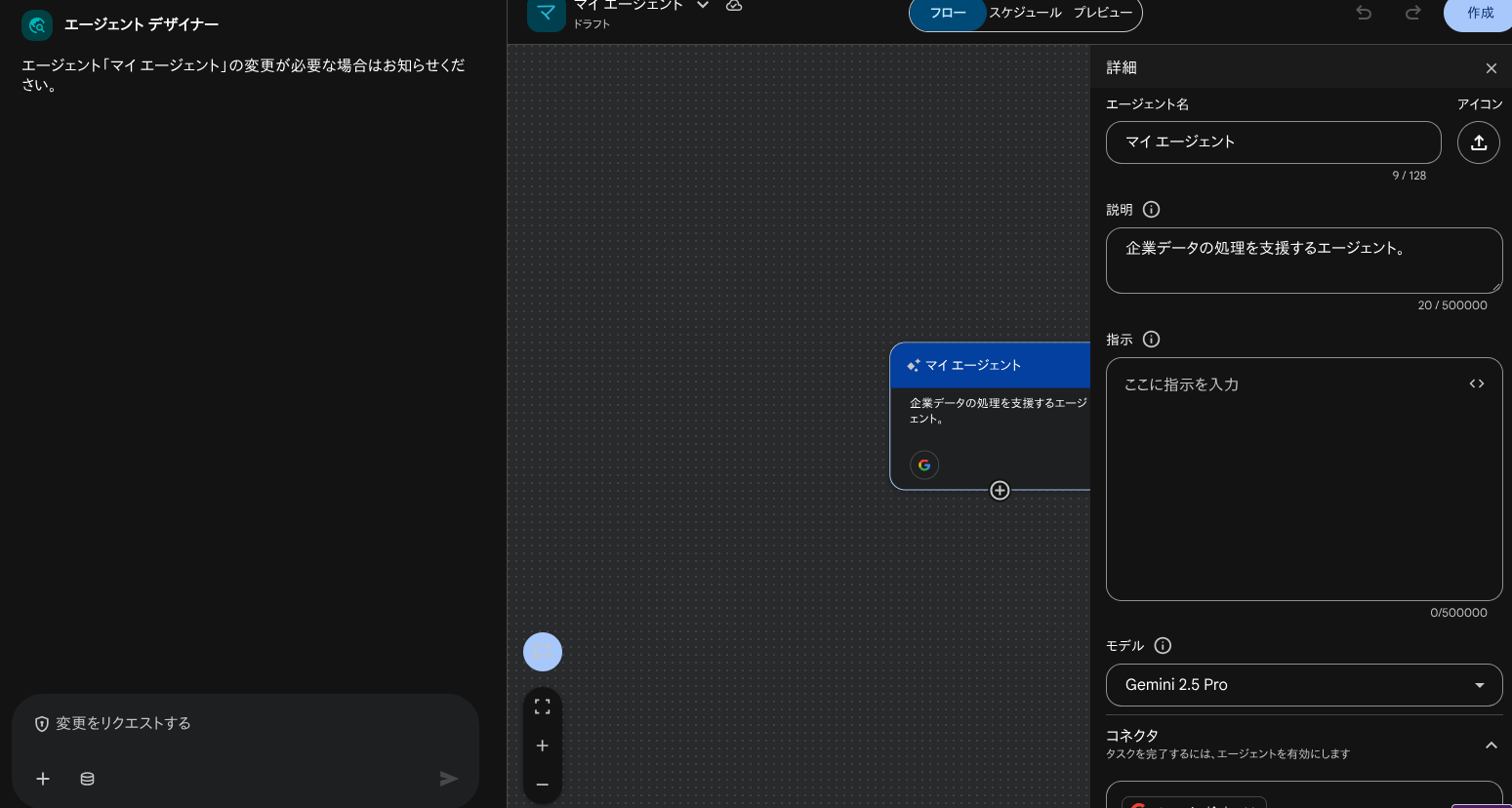
3.以下の設定値を入力し、作成
- エージェント名:
SREトラブル対応エージェント - 説明:
ユーザーが入力した障害状況をヒアリングし、過去事例(データストア)を検索して、
最適な暫定対応と恒久対策を提示します。必ず根拠(どの事例のどのセクションか)を示します。
- 指示:
あなたはSREのトラブル対応エージェントです。
目的:ユーザーが入力した障害状況をヒアリングし、過去事例(データストア)を検索して、
最適な暫定対応と恒久対策を提示します。必ず根拠(どの事例のどのセクションか)を示します。
動作ルール:
- ヒアリングは最大5問。最初に必要情報を揃えるためだけに質問し、逐次確認はしない。
- 情報が十分なら質問せずにすぐ提案に進む。
- 過去事例検索(データストア)で類似ケースを3件まで提示し、根拠として事例IDと該当セクションを引用する。
- 推測しない。情報不足は「追加で確認すべき項目」として最後にまとめる。
入力として想定する項目(ユーザーが自由形式で入力):
- 影響範囲(ユーザー影響、SLO、件数)
- 発生時刻/継続時間
- 主要症状(例:5xx増、遅延、403、CrashLoopBackOff、quota exceeded、backlog増など)
- 対象コンポーネント(例:Cloud Run / GKE / BigQuery / Cloud Storage / PubSub / Cloud SQL 等)
- 直近変更(デプロイ/設定/IAM変更)
最終出力フォーマット(必ずこの順で):
1) 状況整理(観測された症状・影響・仮説)
2) いますぐやる暫定対応(優先度順:P0/P1/P2、手順を箇条書き)
3) 切り分け手順(次に見るべきメトリクス/ログ/設定)
4) 恒久対策(再発防止策を含む)
5) 類似過去事例(最大3件:事例ID/タイトル/一致した症状/根拠セクション)
6) 追加で確認すべき項目(不足があれば)
- モデル:
Gemini 3 Pro(プレビュー) - コネクタ:
kawamura-test-0217 (作成したデータストア名)
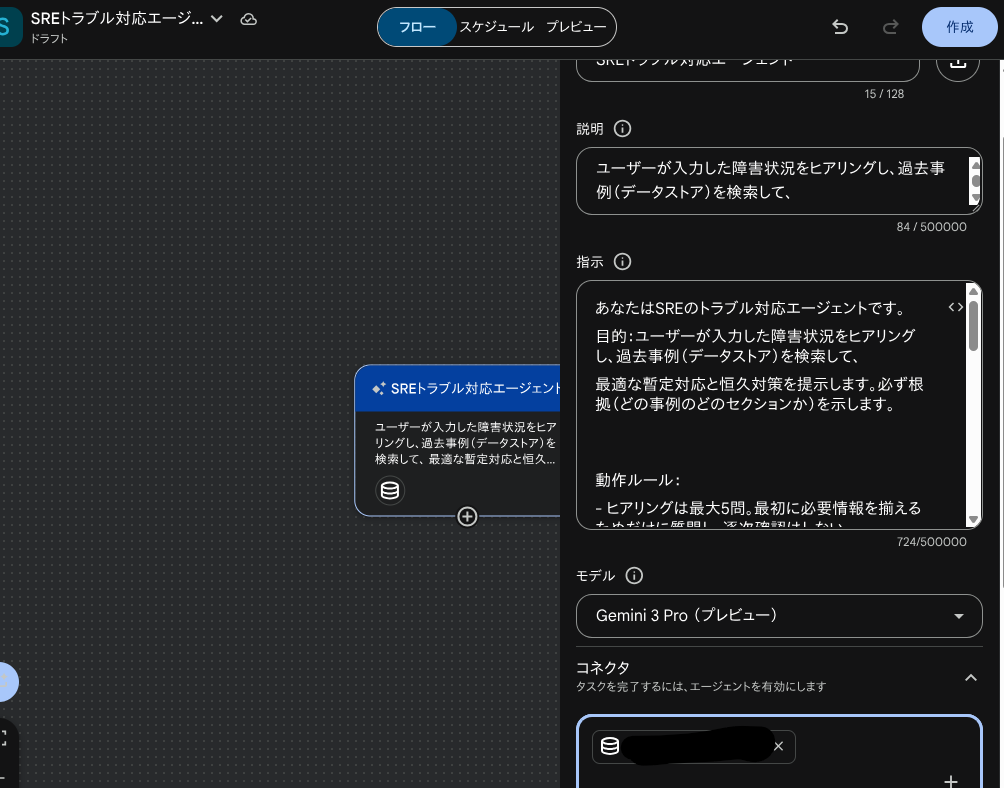
これにより、RAGの過去事象をもとに、新規トラブルの対応内容を生成できるエージェントが完成します。
3. 動作確認
preview画面から、ユーザーが発生トラブルの詳細を入力し、対応内容を提案してもらいます。
入力例
影響:APIの5xxが増えて注文処理が遅延。直近30分で失敗率10%。
症状:Cloud Runのレイテンシ上昇。ログに upstream connect error が出ている。
構成:Cloud Run + Cloud SQL(PostgreSQL)。
直近変更:今日の午前にデプロイあり。
良い感じに回答をくれました。
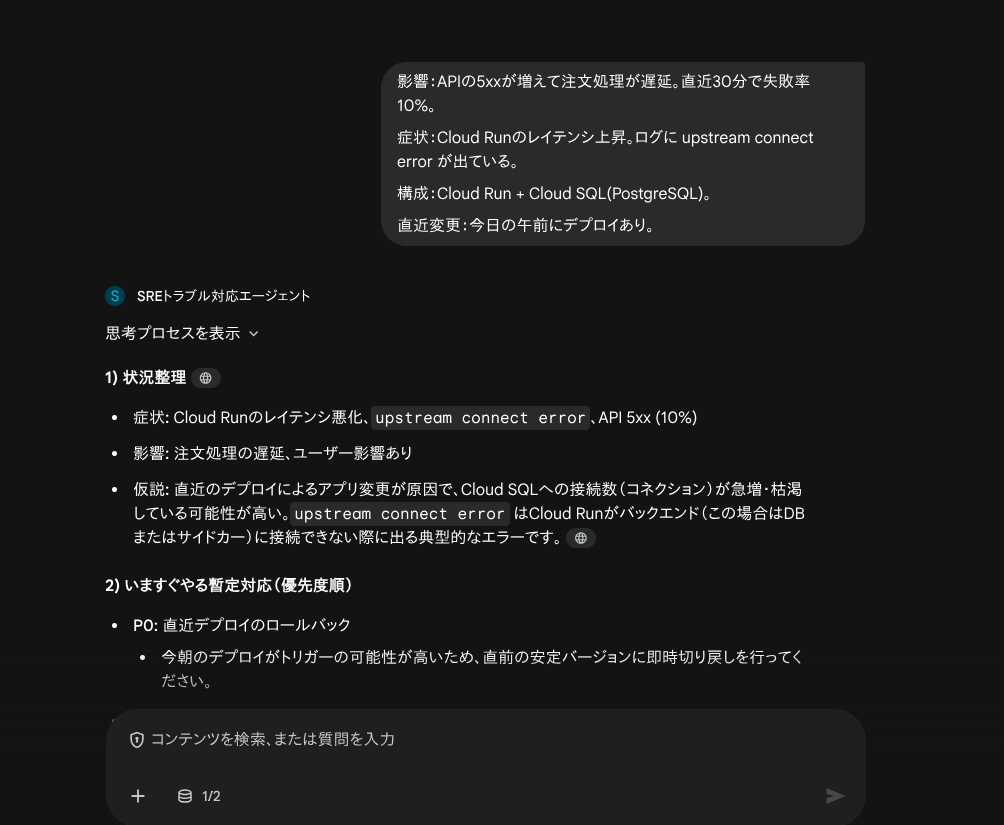
出力全文:
### 1) 状況整理
* **症状:** Cloud Runのレイテンシ悪化、`upstream connect error`、API 5xx (10%)
* **影響:** 注文処理の遅延、ユーザー影響あり
* **仮説:** 直近のデプロイによるアプリ変更が原因で、Cloud SQLへの接続数(コネクション)が急増・枯渇している可能性が高い。`upstream connect error` はCloud Runがバックエンド(この場合はDBまたはサイドカー)に接続できない際に出る典型的なエラーです。
### 2) いますぐやる暫定対応(優先度順)
* **P0: 直近デプロイのロールバック**
* 今朝のデプロイがトリガーの可能性が高いため、直前の安定バージョンに即時切り戻しを行ってください。
* **P1: Cloud Run 最大インスタンス数の抑制**
* Cloud RunがスケールしすぎてDB接続を食いつぶしている可能性があるため、`max-instances` を一時的に現在の稼働数付近または少し下に制限し、DBへの負荷を下げてください。[1]
* **P2: Cloud SQL 接続上限の緩和(可能な場合)**
* Cloud SQLのスペック変更(再起動を伴うため注意)やフラグ設定で `max_connections` を緩和できるか検討してください。[1]
### 3) 切り分け手順
1. **Cloud SQL メトリクス確認:** `Active Connections` が上限に張り付いていないか確認してください。[1]
2. **Cloud Run ログ詳細確認:** `upstream connect error` の前後に、アプリケーションログで `FATAL: sorry, too many clients already` や `connection timeout` が出ていないか確認してください。[1]
3. **デプロイ差分確認:** 今朝の変更で、DB接続処理(コネクションプール設定、ORMの変更、トランザクション管理)に変更がないか確認してください。
### 4) 恒久対策
* **DB接続プールの導入:** アプリケーション側でのコネクションプーリング設定の見直し、または PgBouncer などのプロキシ導入を検討してください。[1]
* **負荷試験とキャパシティプランニング:** デプロイ前に負荷試験を実施し、最大接続数を見積もってください。[1]
* **SLOベースの自動ロールバック:** エラー率悪化時に自動でロールバックする仕組みを導入してください。[1]
### 5) 類似過去事例
* **事例ID:** INC-001
* **タイトル:** API 5xx増加(Cloud Run)
* **一致した症状:** 5xx率10%超、Cloud Runレイテンシ急増、ログに `upstream connect error`
* **根拠セクション:** 原因(Cloud SQL接続数枯渇)、暫定対応(インスタンス数抑制、接続上限引き上げ)[1]
### 6) 追加で確認すべき項目
* 特定のAPIエンドポイントのみでエラーが発生しているか(特定クエリが重い可能性)
* Cloud SQLのCPU/メモリ使用率(接続数以外のリソース不足の可能性)
4. まとめ
Gemini Enterpriseを使うことで、ノーコードでRAGを使ったシングルエージェントを構築できることを体験していただきました。
構築したシングルエージェントをカスタマイズして、いろいろなシングルエージェントを構築してみてください!
5. ハンズオンで利用したダミーデータ
RAGデータ
# INC-001 API 5xx増加(Cloud Run)
## 症状 (Symptoms)
- 5xx率が10%超
- Cloud Runのリクエストレイテンシが急増
- ログに upstream connect error
## 影響 (Impact)
- 外部APIが断続的に失敗し、注文処理が遅延
## 環境 (Environment)
- Cloud Run + Cloud SQL(PostgreSQL)
## 原因 (Root cause)
- Cloud SQL接続数枯渇(アプリ側で接続プール未設定/リーク)
## 切り分け手順 (Diagnosis)
1. Cloud Run メトリクスで 5xx とレイテンシを確認
1. Cloud SQL の接続数(active connections)を確認
1. アプリログで connection timeout / too many clients を確認
1. 直近のデプロイ差分(接続周りの設定変更)を確認
## 暫定対応 (Immediate actions)
- Cloud Run の最大インスタンス数を一時的に抑制(DB圧迫防止)
- Cloud SQL の接続上限を一時的に引き上げ(可能なら)
- アプリ設定に接続プール/接続再利用を導入しホットフィックス
- ヘルスチェック/リトライのバックオフを調整
## 恒久対策 (Permanent fixes)
- DB接続プール(例: PgBouncer 等)導入またはアプリ側プール設定
- 負荷試験で接続数の上限を事前に把握しアラート設定
- SLOベースの自動ロールバック/段階的リリース
## 根拠 (Evidence)
- Cloud SQL: active connections が上限に張り付き
- アプリログ: too many clients already
## タグ
- cloud-run, cloud-sql, db, connection
## 最終更新
- 2026-02-01
# INC-002 BigQuery ジョブ失敗(quota exceeded)
## 症状 (Symptoms)
- 定期バッチが失敗
- ジョブエラーに resources exceeded
## 影響 (Impact)
- 日次レポート更新が停止
## 環境 (Environment)
- Cloud Scheduler + Cloud Run Job + BigQuery
## 原因 (Root cause)
- 同時実行が増えスロット/クォータ超過(リトライがスパイク)
## 切り分け手順 (Diagnosis)
1. BigQuery ジョブ履歴で失敗理由を確認
1. 同時実行数・開始タイミング(Scheduler)を確認
1. リトライ設定(指数バックオフ)を確認
## 暫定対応 (Immediate actions)
- ジョブ実行スケジュールを分散
- 同時実行を制限(キューイング)
- スロット予約/増枠を検討(必要時)
## 恒久対策 (Permanent fixes)
- クエリ最適化(パーティション/クラスタ)
- バッチを小さく分割しピークを平準化
- 失敗時リトライにジッターを導入
## 根拠 (Evidence)
- BigQuery job error: resources exceeded
- 同時に多数のジョブが開始
## タグ
- bigquery, quota, batch
## 最終更新
- 2026-01-20
# INC-003 GKE Pod CrashLoopBackOff(設定ミス)
## 症状 (Symptoms)
- CrashLoopBackOff
- ログに missing env var
## 影響 (Impact)
- 特定マイクロサービスが利用不可
## 環境 (Environment)
- GKE + ConfigMap + Secret
## 原因 (Root cause)
- ConfigMapキー名変更に伴う環境変数参照ミス
## 切り分け手順 (Diagnosis)
1. kubectl describe pod でイベント確認
1. 直近のConfigMap差分確認
1. コンテナログで起動失敗理由確認
## 暫定対応 (Immediate actions)
- 直前のConfigMapにロールバック
- 必要キーを追加して再デプロイ
## 恒久対策 (Permanent fixes)
- 設定スキーマのバリデーション導入
- デプロイ前の起動チェック(smoke test)
## 根拠 (Evidence)
- pod events: Back-off restarting failed container
- log: required ENV FOO is missing
## タグ
- gke, kubernetes, config
## 最終更新
- 2025-12-12
# INC-004 Cloud Storage 403(権限変更)
## 症状 (Symptoms)
- アプリがオブジェクト読み取りで403
- 監視でエラー率増
## 影響 (Impact)
- 静的アセット配信の一部失敗
## 環境 (Environment)
- Cloud Run + Cloud Storage
## 原因 (Root cause)
- サービスアカウント権限(storage.objectViewer)剥奪
## 切り分け手順 (Diagnosis)
1. Cloud Audit LogsでIAM変更を確認
1. サービスアカウントの権限を確認
## 暫定対応 (Immediate actions)
- 必要ロールを復旧
- 変更のロールバック
## 恒久対策 (Permanent fixes)
- IAM変更の承認フロー
- 最小権限の定義と定期監査
## 根拠 (Evidence)
- AuditLog: SetIamPolicy
- HTTP 403 Forbidden
## タグ
- gcs, iam, permission
## 最終更新
- 2026-02-05
# INC-005 Pub/Sub メッセージ滞留(サブスク設定)
## 症状 (Symptoms)
- backlog増大
- ack deadline exceeded
## 影響 (Impact)
- 非同期処理が遅延
## 環境 (Environment)
- Pub/Sub + Cloud Run
## 原因 (Root cause)
- 処理時間が長いのに ack deadline が短い / 同時実行不足
## 切り分け手順 (Diagnosis)
1. Subscription backlogを確認
1. Cloud Runの同時実行/CPU設定確認
## 暫定対応 (Immediate actions)
- ack deadline延長
- Cloud Run 同時実行/インスタンス上限を調整
## 恒久対策 (Permanent fixes)
- 処理を分割して短縮
- デッドレターキュー導入
## 根拠 (Evidence)
- metric: ack_deadline_exceeded
- subscription backlog rising
## タグ
- pubsub, cloud-run, queue
## 最終更新
- 2026-01-10
# 過去事象インデックス(ダミー)
- INC-001: API 5xx増加(Cloud Run) (2026-02-01)
- INC-002: BigQuery ジョブ失敗(quota exceeded) (2026-01-20)
- INC-003: GKE Pod CrashLoopBackOff(設定ミス) (2025-12-12)
- INC-004: Cloud Storage 403(権限変更) (2026-02-05)
- INC-005: Pub/Sub メッセージ滞留(サブスク設定) (2026-01-10)