tldr
KggleのAdult Census IncomeをHigh Performance Income Prediction - Data Every Day #029に沿ってやっていきます。
実行環境はGoogle Colaboratorです。
インポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.preprocessing as sp
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import tensorflow as tf
データのダウンロード
Google Driveをマウントします。
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
KaggleのAPIクライアントを初期化し、認証します。
認証情報はGoogle Drive内(/content/drive/My Drive/Colab Notebooks/Kaggle)にkaggle.jsonとして置いてあります。
import os
kaggle_path = "/content/drive/My Drive/Colab Notebooks/Kaggle"
os.environ['KAGGLE_CONFIG_DIR'] = kaggle_path
from kaggle.api.kaggle_api_extended import KaggleApi
api = KaggleApi()
api.authenticate()
Kaggle APIを使ってデータをダウンロードします。
dataset_id = 'uciml/adult-census-income'
dataset = api.dataset_list_files(dataset_id)
file_name = dataset.files[0].name
file_path = os.path.join(api.get_default_download_dir(), file_name)
file_path
Warning: Looks like you're using an outdated API Version, please consider updating (server 1.5.10 / client 1.5.9)
'/content/adult.csv'
api.dataset_download_file(dataset_id, file_name, force=True, quiet=False)
100%|██████████| 450k/450k [00:00<00:00, 49.3MB/s]
Downloading adult.csv.zip to /content
True
import zipfile
zip_path = file_path + '.zip'
with zipfile.ZipFile(zip_path) as existing_zip:
existing_zip.extractall('/content')
データの読み込み
Padasを使ってダウンロードしてきたCSVファイルを読み込みます。
data = pd.read_csv(file_path)
data
| age | workclass | fnlwgt | education | education.num | marital.status | occupation | relationship | race | sex | capital.gain | capital.loss | hours.per.week | native.country | income | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 90 | ? | 77053 | HS-grad | 9 | Widowed | ? | Not-in-family | White | Female | 0 | 4356 | 40 | United-States | <=50K |
| 1 | 82 | Private | 132870 | HS-grad | 9 | Widowed | Exec-managerial | Not-in-family | White | Female | 0 | 4356 | 18 | United-States | <=50K |
| 2 | 66 | ? | 186061 | Some-college | 10 | Widowed | ? | Unmarried | Black | Female | 0 | 4356 | 40 | United-States | <=50K |
| 3 | 54 | Private | 140359 | 7th-8th | 4 | Divorced | Machine-op-inspct | Unmarried | White | Female | 0 | 3900 | 40 | United-States | <=50K |
| 4 | 41 | Private | 264663 | Some-college | 10 | Separated | Prof-specialty | Own-child | White | Female | 0 | 3900 | 40 | United-States | <=50K |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 32556 | 22 | Private | 310152 | Some-college | 10 | Never-married | Protective-serv | Not-in-family | White | Male | 0 | 0 | 40 | United-States | <=50K |
| 32557 | 27 | Private | 257302 | Assoc-acdm | 12 | Married-civ-spouse | Tech-support | Wife | White | Female | 0 | 0 | 38 | United-States | <=50K |
| 32558 | 40 | Private | 154374 | HS-grad | 9 | Married-civ-spouse | Machine-op-inspct | Husband | White | Male | 0 | 0 | 40 | United-States | >50K |
| 32559 | 58 | Private | 151910 | HS-grad | 9 | Widowed | Adm-clerical | Unmarried | White | Female | 0 | 0 | 40 | United-States | <=50K |
| 32560 | 22 | Private | 201490 | HS-grad | 9 | Never-married | Adm-clerical | Own-child | White | Male | 0 | 0 | 20 | United-States | <=50K |
32561 rows × 15 columns
下準備
欠損値の処理
data.isnull().sum()
age 0
workclass 0
fnlwgt 0
education 0
education.num 0
marital.status 0
occupation 0
relationship 0
race 0
sex 0
capital.gain 0
capital.loss 0
hours.per.week 0
native.country 0
income 0
dtype: int64
値に「?」が入っている数を数えます
data.isin(['?']).sum()
age 0
workclass 1836
fnlwgt 0
education 0
education.num 0
marital.status 0
occupation 1843
relationship 0
race 0
sex 0
capital.gain 0
capital.loss 0
hours.per.week 0
native.country 583
income 0
dtype: int64
data = data.replace('?', np.NaN)
data.isna().sum()
age 0
workclass 1836
fnlwgt 0
education 0
education.num 0
marital.status 0
occupation 1843
relationship 0
race 0
sex 0
capital.gain 0
capital.loss 0
hours.per.week 0
native.country 583
income 0
dtype: int64
educationとeducation.num列は同じ情報をエンコードしただけなので、educationは削除します。
data.loc[:, ['education', 'education.num']]
| education | education.num | |
|---|---|---|
| 0 | HS-grad | 9 |
| 1 | HS-grad | 9 |
| 2 | Some-college | 10 |
| 3 | 7th-8th | 4 |
| 4 | Some-college | 10 |
| ... | ... | ... |
| 32556 | Some-college | 10 |
| 32557 | Assoc-acdm | 12 |
| 32558 | HS-grad | 9 |
| 32559 | HS-grad | 9 |
| 32560 | HS-grad | 9 |
32561 rows × 2 columns
data = data.drop('education', axis=1)
オブジェクト型の処理
data.dtypes
age int64
workclass object
fnlwgt int64
education object
education.num int64
marital.status object
occupation object
relationship object
race object
sex object
capital.gain int64
capital.loss int64
hours.per.week int64
native.country object
income object
dtype: object
categorical_features = [
'workclass',
'marital.status',
'occupation',
'relationship',
'race',
'sex',
'native.country']
def get_uniques(df, columns):
uniques = dict()
for column in columns:
uniques[column] = list(df[column].unique())
return uniques
get_uniques(data, categorical_features)
{'marital.status': ['Widowed',
'Divorced',
'Separated',
'Never-married',
'Married-civ-spouse',
'Married-spouse-absent',
'Married-AF-spouse'],
'native.country': ['United-States',
nan,
'Mexico',
'Greece',
'Vietnam',
'China',
'Taiwan',
'India',
'Philippines',
'Trinadad&Tobago',
'Canada',
'South',
'Holand-Netherlands',
'Puerto-Rico',
'Poland',
'Iran',
'England',
'Germany',
'Italy',
'Japan',
'Hong',
'Honduras',
'Cuba',
'Ireland',
'Cambodia',
'Peru',
'Nicaragua',
'Dominican-Republic',
'Haiti',
'El-Salvador',
'Hungary',
'Columbia',
'Guatemala',
'Jamaica',
'Ecuador',
'France',
'Yugoslavia',
'Scotland',
'Portugal',
'Laos',
'Thailand',
'Outlying-US(Guam-USVI-etc)'],
'occupation': [nan,
'Exec-managerial',
'Machine-op-inspct',
'Prof-specialty',
'Other-service',
'Adm-clerical',
'Craft-repair',
'Transport-moving',
'Handlers-cleaners',
'Sales',
'Farming-fishing',
'Tech-support',
'Protective-serv',
'Armed-Forces',
'Priv-house-serv'],
'race': ['White',
'Black',
'Asian-Pac-Islander',
'Other',
'Amer-Indian-Eskimo'],
'relationship': ['Not-in-family',
'Unmarried',
'Own-child',
'Other-relative',
'Husband',
'Wife'],
'sex': ['Female', 'Male'],
'workclass': [nan,
'Private',
'State-gov',
'Federal-gov',
'Self-emp-not-inc',
'Self-emp-inc',
'Local-gov',
'Without-pay',
'Never-worked']}
各データの特性を見て
- Labelエンコード
- Onehotエンコード
- Ordinalエンコード
のどれでエンコードするか判断する
binary_features = ['sex']
nominal_features = [
'workclass',
'marital.status',
'occupation',
'relationship',
'race',
'native.country',
]
Binary エンコード
def binary_encode(df, columns):
label_encoder = sp.LabelEncoder()
for column in columns:
df[column] = label_encoder.fit_transform(df[column])
return df
Onehotエンコード
def onehot_encode(df, columns):
for column in columns:
dummies = pd.get_dummies(data[column])
df = pd.concat([df, dummies], axis=1)
df = df.drop(column, axis=1)
return df
data = binary_encode(data, binary_features)
data = onehot_encode(data, nominal_features)
スケーリング
y = data['income']
X = data.drop('income', axis=1)
label_encoder = sp.LabelEncoder()
y = label_encoder.fit_transform(y)
y_mappings = {index: label for index, label in enumerate(label_encoder.classes_)}
scaler = sp.MinMaxScaler()
X = pd.DataFrame(scaler.fit_transform(X), columns=X.columns)
Training
Tensorflowを使ってモデルを構築します。
最後のレイヤーの活性化関数はSimoidを使用します。
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8)
model = tf.keras.Sequential([
tf.keras.layers.Dense(16, activation='relu', input_shape=(88, )),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
model.summary()
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
metrics = [
tf.keras.metrics.BinaryAccuracy(name='acc'),
tf.keras.metrics.AUC(name='auc'),
]
model.compile(
optimizer=optimizer,
loss='binary_crossentropy',
metrics=metrics,
)
batch_size = 32
epochs = 100
history = model.fit(
X_train,
y_train,
validation_split=0.2,
batch_size=batch_size,
epochs=epochs,
verbose=0,
)
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_10 (Dense) (None, 16) 1424
_________________________________________________________________
dense_11 (Dense) (None, 16) 272
_________________________________________________________________
dense_12 (Dense) (None, 1) 17
=================================================================
Total params: 1,713
Trainable params: 1,713
Non-trainable params: 0
_________________________________________________________________
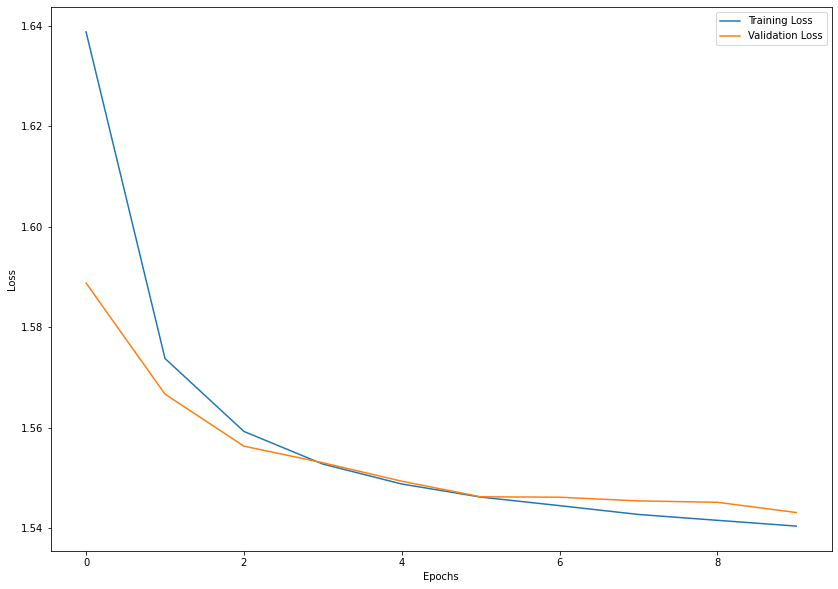
結果
plt.figure(figsize=(14,10))
epochs_range = range(1, epochs + 1)
train_loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
model.evaluate(X_test, y_test)
204/204 [==============================] - 0s 1ms/step - loss: 0.3338 - acc: 0.8475 - auc: 0.9050
[0.33379316329956055, 0.8475356698036194, 0.9049904346466064]
過学習になる前のValidation lossが最も小さいときのepochsを割り出します
np.argmin(val_loss)
18
上記のepochsで学習を停止させると最も汎用的なモデルが得られます。