はじめに
2025年12月からデータサイエンスに関する講座を受講しており、その修了課題としてwebアプリ開発に取り組みました。
本稿では、その開発内容をまとめてみました。
作成したアプリの概要
5〜10秒ほどの歩行動画をアップロードすると、和装に合う歩き方ができているかを判定し、アドバイスが返ってくるという内容のアプリ。
その名も 「雅 walk AI」 です!
私は歩き方がガニ股で腰が高く、たまに着物や浴衣を着ると裾がはだけてしまったり、まったく風流ではありません・・・。
このような悩みを抱えている人は他にもいるのではないかと思い、このテーマを選びました。
開発言語: Python
また、フロントエンド開発には Streamlitを使用しました。
アプリはこちらからお試しいただけます。
※ Streamlit Community CloudのCPUやメモリの制限で、推論には2分ほど時間を要します。
トップ画面
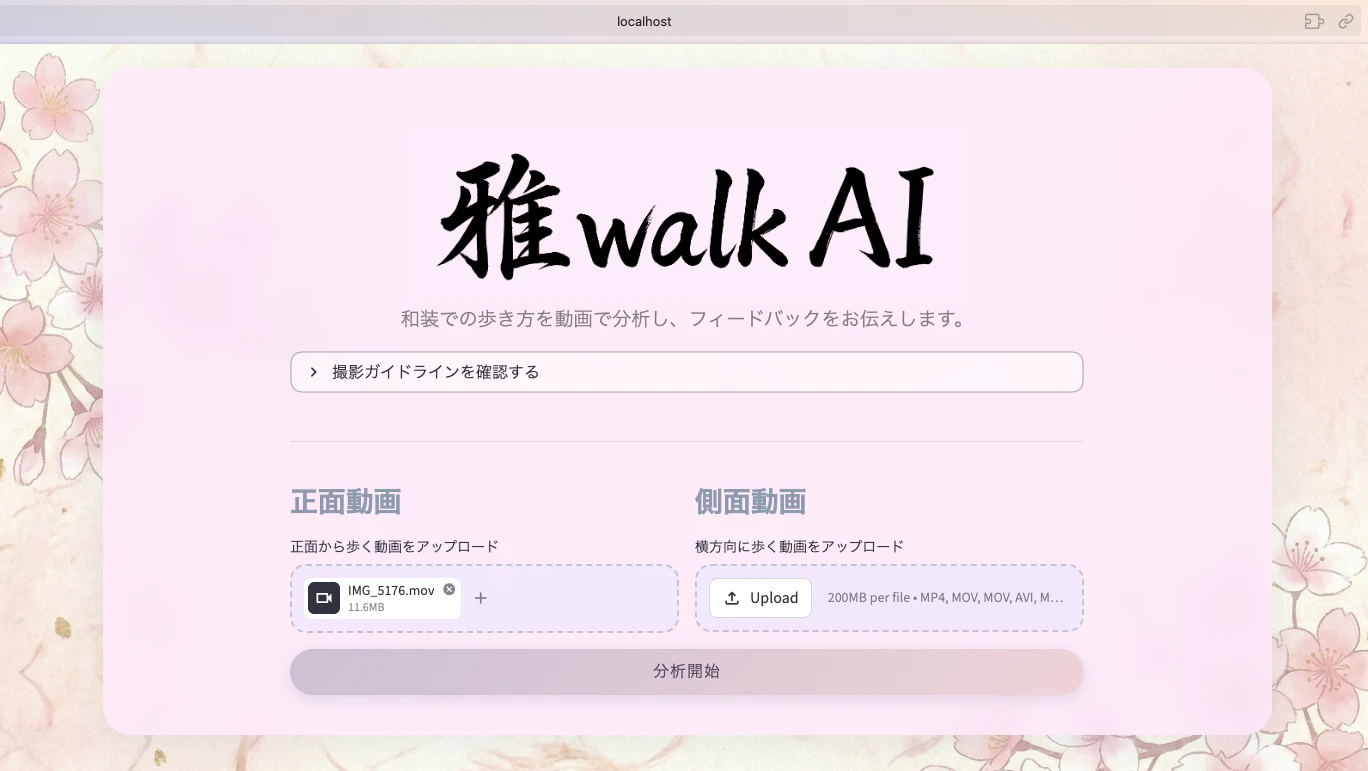
正面から撮影した動画と、側面から撮影した動画に対応しており、それぞれ別の観点で評価を行います。
どちらか片方だけでの診断も可能です。
診断結果(正面・側面)
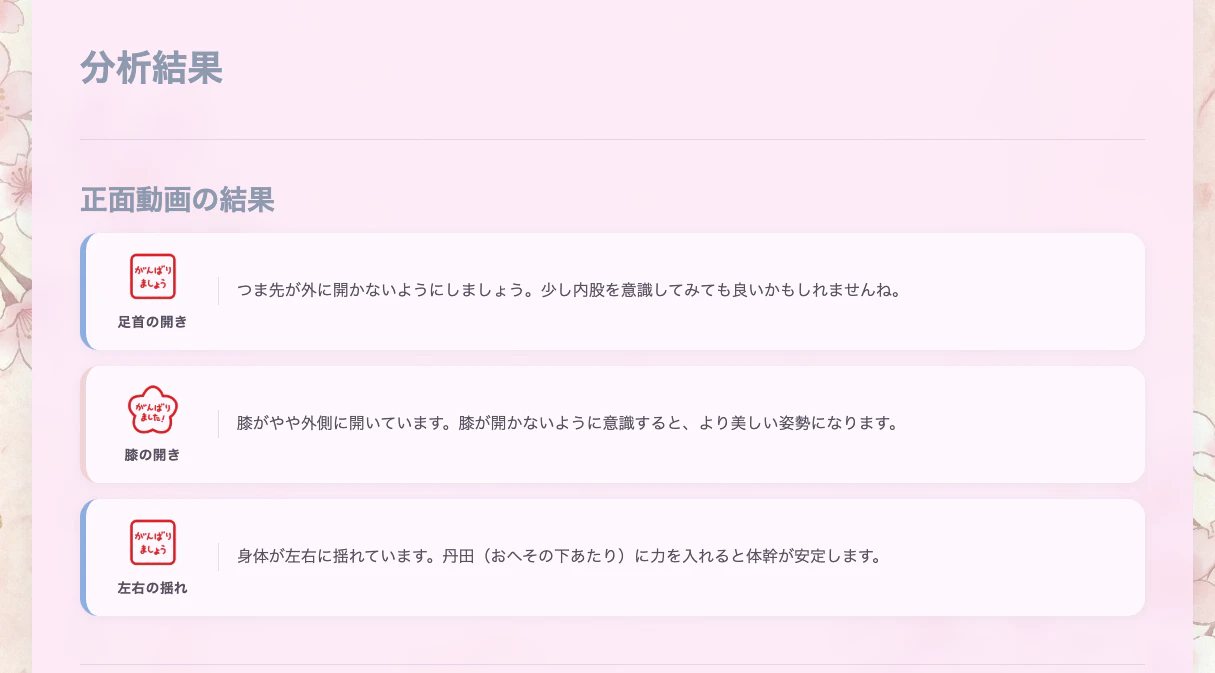

評価項目は正面・側面あわせて6個です。
- 足首の開き :つま先が外を向いていないか
- 膝の開き :ガニ股になっていないか
- 左右の揺れ :左右にぶれていないか
- 歩幅 :大きすぎないか
- 踏み出す足の角度 :踵から着地してしまっていないか
- 腰の高さ・膝の伸び:腰が高くなっていないか
それぞれ3段階評価です。
動画によるフィードバック

キーポイントを付与したオーバーレイ動画も返します。
推論の仕組み
バックエンドでは、骨格推定 → 歩き方の診断 という二段階の処理を行っています。
内部で利用しているモデルや仕組みについて順番に説明します。
骨格推定
骨格推定には RTMWというモデルを利用しました。
正確には、rtmlibというライブラリを用いています。
RTMWとは
OpenMMLabが開発したオープンソースの骨格推定モデル。RTMWとは Real-Time Multi-person Whole-body の略で、全身133点のキーポイント(身体の関節点や特徴点のこと)の抽出が可能。
※ それ以前にOpenMMLabが公開したRTMPoseというモデルをベースにしているため、まとめて表現されることもある。
rtmlibとは
RTMWやRTMPoseといった骨格推定モデルを、最低限の依存関係で簡単に動かせるようにしたオープンソースライブラリ。Apache 2.0ライセンスで配布されており、商用利用も可能。
GitHubはこちら
RTMW(rtmlib)を採用した理由
- 他の骨格推定モデルと比べ、和装に対しても比較的高精度なキーポイント検出が可能
- 全身133点のキーポイント検出が可能
骨格推定モデルでは YOLOなどのモデルも有名ですが、YOLOは鼻〜足首までの17点検出のモデルです。
一方で、RTMWでは足首より下の足親指・足小指・踵といった細かいキーポイント検出が可能です。今回のタスクでは、足の着地などにも注目する必要があったことから、RTMWを採用しました。
rtmlibの実装
from rtmlib import Wholebody
import cv2
# Wholebodyのインスタンス化(CPU利用の場合)
wholebody = Wholebody(mode="balanced", backend="onnxruntime", device='cpu')
# 静止画からのキーポイント検出
img = cv2.imread('ファイル名')
# keypoints:xy座標, scores:各キーポイントの信頼度
keypoints, scores = wholebody(img)
Wholebody()の戻り値は以下の通りです。
- keypoints : (検出人数, 133, 2)のnumpy.ndarray型
- scores : (検出人数, 133)のnumpy.ndarray
133というのはキーポイントの数、2というのはx座標とy座標を表します。
実際のアプリでは、 cv2.VideoCaptureから各フレームを取り出し、計算を軽くするために2フレームに1回の割合でキーポイント検出を行っています。
また、2人以上の人物が検出された場合には、scoresの平均値が高い方のみを対象とする仕様にしています。
このようにして検出したkeypointsの値(キーポイントごとのxy座標の値)を元にして、次の歩き方の診断へと移ります。
歩き方の診断
実はここでは機械学習モデルは利用していません。
代わりに、
各キーポイントの位置関係に基づいて、2点間の距離や、3点で形成される角度を算出
→ 予め設定した閾値を超えるかどうかで結果を判定
というルールベースの手法を用いました。
例えば、以下のようなルールです。
- 膝の開きの判定
- 膝〜腰ベクトルと、膝〜足親指の角度 :
knee_angleを算出- 評価A : 176度 <=
knee_angle - 評価B : 170度 <=
knee_angle< 176度 - 評価C :
knee_angle< 170度
- 評価A : 176度 <=
- 膝〜腰ベクトルと、膝〜足親指の角度 :
- 歩幅の判定
- 腰〜足首の距離(左右短い方):
ref_lenを算出 - 両足首のx座標の距離 :
ankle_distを測定- 評価A :
ankle_dist / ref_len<= 0.52 - 評価B : 0.52 <
ankle_dist / ref_len<= 0.58 - 評価C : 0.58 <
ankle_dist / ref_len
- 評価A :
- 腰〜足首の距離(左右短い方):
# キーポイントのインデックス番号
LEFT_HIP, RIGHT_HIP = 11, 12
LEFT_ANKLE, RIGHT_ANKLE = 15, 16
def analyze_step_width(frames_data):
"""
歩幅判定のための関数
引数:
frames_data:[(keypoints, scores), ...] => 各フレームの座標と信頼度スコア
"""
ng_count = 0
warning_count = 0
valid = 0
for kpts, scrs in frames_data:
# ── 基準長(腰〜足首)を算出 ──────────────────────────────
# 左右の短い方を採用
left_len = np.linalg.norm(kpts[LEFT_HIP] - kpts[LEFT_ANKLE])
right_len = np.linalg.norm(kpts[RIGHT_HIP] - kpts[RIGHT_ANKLE])
ref_len = min(left_len, right_len)
# ── 歩幅比率を算出 ─────────────────────────────────────────
# x座標の差を算出
ankle_dist = abs(kpts[LEFT_ANKLE][0] - kpts[RIGHT_ANKLE][0])
# 基準長との割合を算出
ratio = ankle_dist / ref_len
valid += 1
if ratio > 0.58:
ng_count += 1
warning_count += 1
elif ratio > 0.52:
warning_count += 1
# ── フレーム全体の比率で最終判定 ──────────────────────────────
# 1フレームでNGになった時点ではなく、全体の2割以上でNGが出たかで判定する
frame_ratio_thr = 0.2
if ng_count / valid >= frame_ratio_thr:
status = "ng"
elif warning_count / valid >= frame_ratio_thr:
status = "warning"
else:
status = "ok"
ルールベースの手法を用いた理由
骨格推定モデルで取得したキーポイントの座標を入力変数として、機械学習モデルを通して、判定を推論する手段もありました。
ですが今回、そうではなくルールベースの手法を用いた理由は主に2つあります。
- 機械学習に比べると、学習サンプルが少なくても精度を高められる
- 手動で閾値を設定するため、判定の観点が明確
機械学習を利用することで、人間では気付かない法則性を見出すこともできますが、個人開発においてはそのためのデータ収集で挫折することが多くあります。
また、機械学習には内部の推論過程がブラックボックス化してしまうリスクがあります。
改善案
ひとまず自分がイメージしたアプリを作ることができました!
ですが、もっとこうすれば良かったと感じる点もあります。
ドメインの絞り込み
今回は「和装」という広いテーマにしてしまいましたが、実際には、「男性向けか女性向けか」、「履き物は下駄か草履か」といったところで正しい歩き方も変わってくるのだろうと思います。
専門家の監修
歩き方の判定に用いる基準や閾値は、私が色々な方の歩き方を分析しながら設定しました。ですが、そもそもそれが正しいのか、という問題があります。
今回は講座の修了課題として動くものを作る、というのが主目的でしたが、実際にサービスを提供するような場合には専門家に監修をお願いした方が良いと感じました。
骨格推定モデルのファインチューニング
和装は腰から下のシルエットが裾で隠れるため、洋服に比べてキーポイント検出の精度が落ちやすいです。
先述の通り、RTMWは他のモデルと比べると、比較的和装に対しても高い精度で検出ができましたが、それでも時々誤った検出があります。
和装の学習データでファインチューニングを行うことで、そのあたりの精度が向上するのか、試してみる価値はあると感じました。
おわりに
数ヶ月間データサイエンスについて学習を続けてきて、無事に修了課題をクリアすることができました。
学習を進めれば進めるほど、機械学習モデル(広義ではAI)は凄い!と感じましたが、万能ではないということにも気付かされました。
今後はこの経験を活かし、機械に頼る部分と、人力の強みを組み合わせていきたいと思います。