目的
- サービスのDBからBigQueryにimport された複雑なJSON文字列を含むデータがある
- それを利用して分析したい
※JSON文字列はスキャン量が増えるので、本当はimport する前に前処理してほしいが、全部前処理されてるわけではない
サンプルデータ
下記のようなJSONを含むテーブルです
{
"a":1,
"b":"bb",
"c":[
1,
2
],
"d":null,
"e":{
"f":1,
"g":"gg"
}
}
このJSONをBigQuery上では以下のように扱おうとしています。
| カラム名 | 型 | 値 |
|---|---|---|
| a | int64 | 1 |
| b | string | "1" |
| c | array | [1,2] |
| d | int64 | null |
| e | struct(f, g) | |
| f | int | 1 |
| g | string | "gg" |
BigQuery 上では以下のようなテーブルになっているとします。
with t as (
select
'{"a": 1, "b": "bb", "c": [1,2], "d": null, "e": {"f": 1, "g": "gg"}}' as col_1
)
select
col_1
from t
利用する関数
- json_extract, json_extract_scalar で値を取り出す
- ユーザー定義関数(Javascript) + JSON.parse で値を取り出す
- unnest によるJSON配列展開
json_extract, json_extract_scalar で値を取り出す
with t as (
select
'{"a": 1, "b": "bb", "c": [1,2], "d": null, "e": {"f": 1, "g": "gg"}}' as col_1
)
select
json_extract(col_1, '$.a') as a
, json_extract(col_1, '$.b') as b
, json_extract_scalar(col_1, '$.b') as b_scalar
, json_extract(col_1, '$.c') as c
, json_extract(col_1, '$.c[1]') as c_1
, json_extract(col_1, '$.d') as d
, json_extract(col_1, '$.e.f') as e_f
from t
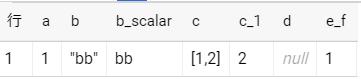
- 各値にアクセスできた
- 文字列はjson_extract_scalar でないとクォートされたままになる
取り出した値の型
- あくまで文字列から文字列を取り出した状態
- つまり string 型
- 数値は cast してあげる必要がある
- cast できない値が混入する場合があるので注意
select
-- error: json_extract(col_1, '$.a') = 1
cast(json_extract(col_1, '$.a') as int64) = 1 as int_a
from t

ユーザー定義関数(Javascript) + JSON.parse で値を取り出す
json_extract以外での扱う方法として ユーザー定義関数を利用する方法があります。利点は
- 型を定義できるので、文字列以外を返すことができる
- 必要ないデータがある場合は、定義に含めなければよい
- クエリ本体の見通しが良い
create temporary function parse_json(s string)
returns struct<
a int64
, b string
, c array<int64>
-- 除外, d int64
, e struct<
f int64
, g string
>
>
language js
as """
return JSON.parse(s);
""";
select
parse_json(col_1) as j
, parse_json(col_1).*
from t
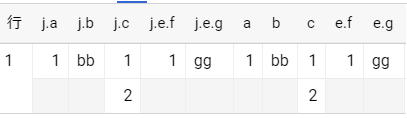
関数から戻った値はstruct なので用途に応じて展開する必要があるので注意する。
また、JSON系関数で十分であれば必要ないのでJavaScript UDFのベストプラクティス にしたがってパフォーマンスに注意する。
BigQueryでの型とJavaScriptでの型の互換性
JavaScript での SQL 型エンコーディング で以下のように説明されています。
SQL 型には JavaScript 型への直接マッピングが用意されているものと、用意されていないものがあります。
JavaScript は 64 ビット整数型をサポートしていないため、INT64 は JavaScript UDF の入力データ型または出力データ型でサポートされません。代わりに、FLOAT64 を使用して整数値を数値として表すか、STRING を使用して整数値を文字列として表します。
具体的には、
- RDBでBigIntであるIDはBigQuery JSONにおいて string として扱わないと、値が異なってしまい結合条件として使えない
- stringとしてJSON parse したあと、他のテーブルではInt64としてデータを持っているならば、結合前にcastする必要がある
unnest によるJSON配列展開
ユーザー定義関数(Javascript) + JSON.parseがどうしても必要になったのはJSONの一番外側が配列のときです。
サンプルデータのJSONが配列に含まれているとします。
[
sample_date_json,
sample_date_json
]
このときの問題点としては以下のようなものがあります。
- json_extract では何回も記述が必要である
- 配列の要素数が固定であればよいが、可変である場合クエリとして表現できない
JSON配列の展開
create temporary function parse_json(s string)
returns array<struct<
a int64
, b string
, c array<int64>
, d int64
, e struct<
f int64
, g string
>
>>
language js
as """
return JSON.parse(s);
""";
with t2 as (
select
'[{"a": 1, "b": "bb", "c": [1,2], "d": null, "e": {"f": 1, "g": "gg"}}, {"a": 1, "b": "bb", "c": [1,2], "d": null, "e": {"f": 1, "g": "gg"}}]' as col_2
)
select
parse_json(col_2) as j
from t2
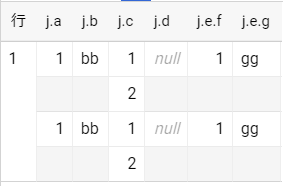
クエリの変更点は以下の2点
- ユーザー定義関数で返す型を変更
- サンプルデータの変更
配列の行展開
このままでは1行に配列が含まれたままで扱いにくいので、unnest を使って対応します。
create temporary function parse_json(s string)
returns array<struct<
a int64
, b string
, c array<int64>
, d int64
, e struct<
f int64
, g string
>
>>
language js
as """
return JSON.parse(s);
""";
select
j.*
from t2
cross join unnest(parse_json(t2.col_2)) as j
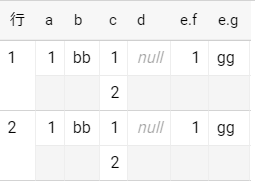
結果が2行になり、扱いやすくなりました
まとめ
- BigQueryでJSONを扱える
- 複雑でないものは json_extract で対応できる
- 文字列はjson_extract_scalar で対応する
- ユーザー定義関数(JavaScript)でParseできる
- 上記とunnest によって、可変長の配列にも対応できる