Fractional Cascading
FD-Tree
FD-Tree (Flash Disk Tree)と呼ばれる2010年ごろに提案された B-Tree Variantsが存在します。
このTreeの目的としてはSSDへのアクセスをシークエンシャルにすることで、従来のランダムなアクセスで発生したWrite AmplificationやGarbage Collectionの回数を下げるというものです。
このTreeではキーを効率よく検索するため、Fractional Cascadingと呼ばれる複数のレベルにわたる配列の値を効率よく探すための方法が採用されています。この記事ではその実際の動き方についてまとめています。(FD-Treeを1度に理解するのが自分では難しかったので、要素分解したい意図が大きいです)
Fractional Cascading
概要
Fractional Cascadingとはざっくり言うと、複数の配列が存在する場合に各要素を同じ値を持つ1つの配列から別の配列の同じ値を持つ要素に向けてBridgeと呼ばれる形で繋ぐことで、効率的な値の検索を実現するアルゴリズムのことです。
Bridgeとなる要素は、一定の間隔(N)で決められます。例えばN=2の場合、array[1], array[3], array[5]... がBridgeとなる要素になります。 (array[i*N-1] for i in range(1, size_of_array / N ))
例を示して動きを見てみます。
Example
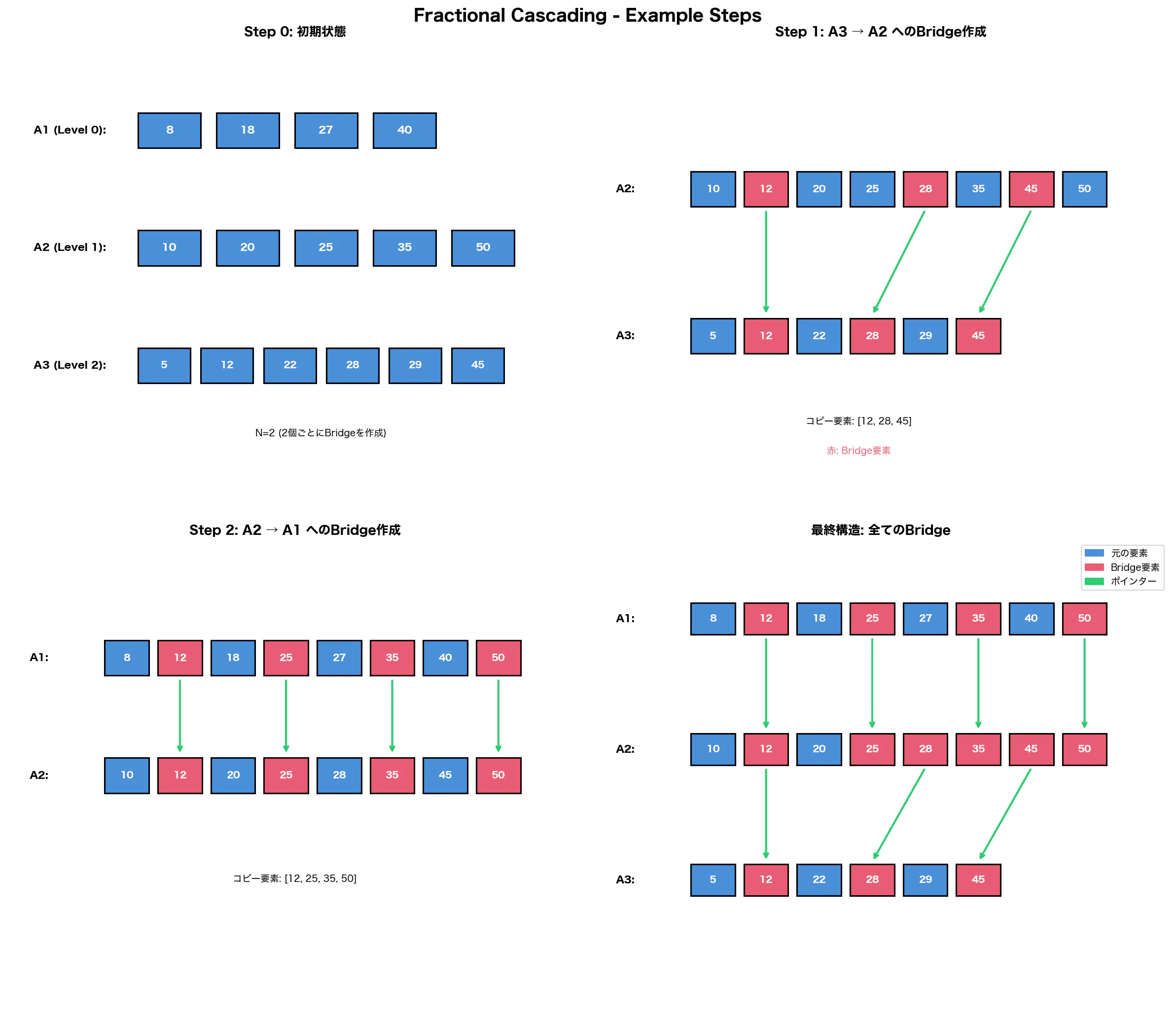
A1, A2, A3の3つの配列があり、それぞれLevel 0, Level 1, Leve 2とします。
前提:各配列はソート済み
A1 = [8, 18, 27, 40] - Level 0
A2 = [10, 20, 25, 35, 50] - Level 1
A3 = [5, 12, 22, 28, 29, 45] - Level 2
Fractional Cascading構造の作成
- Bridges(配列 at level[i] -> 配列 at level[i+1]へのポインター)を作成する。ここでは
N=2とします
-
Step 1 — Pull from A3 → A2
A3の配列から2個ごとに要素をA2にコピーをし、A3→A2の要素に向けてポインターを作成します。- コピーする要素:
[12, 28, 45] - コピー後の配列:
A2 = [10, 12, 20, 25, 28, 35, 45, 50] - ポインター
A2[1] -> A3[1]A2[4] -> A3[3]A2[6] -> A3[5]
- コピーする要素:
-
Step 2 — Pull from A2 → A1
A2の配列から2個ごとに要素をA1にコピーします。- コピーする要素:
[12, 25, 35, 50] - コピー後の配列:
A1 = [8, 12, 18, 25, 27, 35, 40, 50] - ポインター
A1[1] -> A2[1]A1[3] -> A2[3]A1[5] -> A2[5]A1[7] -> A2[7]
- コピーする要素:
作成された構造
上記の2つのステップの後の全体構造(配列 at levels[i] -> 配列 at levels[i+1]に向けてポインタ(Bridge)が作成されている)
A1 = [8, 12, 18, 25, 27, 35, 40, 50]
↓ ↓ ↓ ↓
| | | |
A2 = [10,12, 20, 25, 28, 35, 45, 50]
↓ ↓ ↓
| | |
A3 = [5, 12, 22, 28, 29, 45]
キーの検索
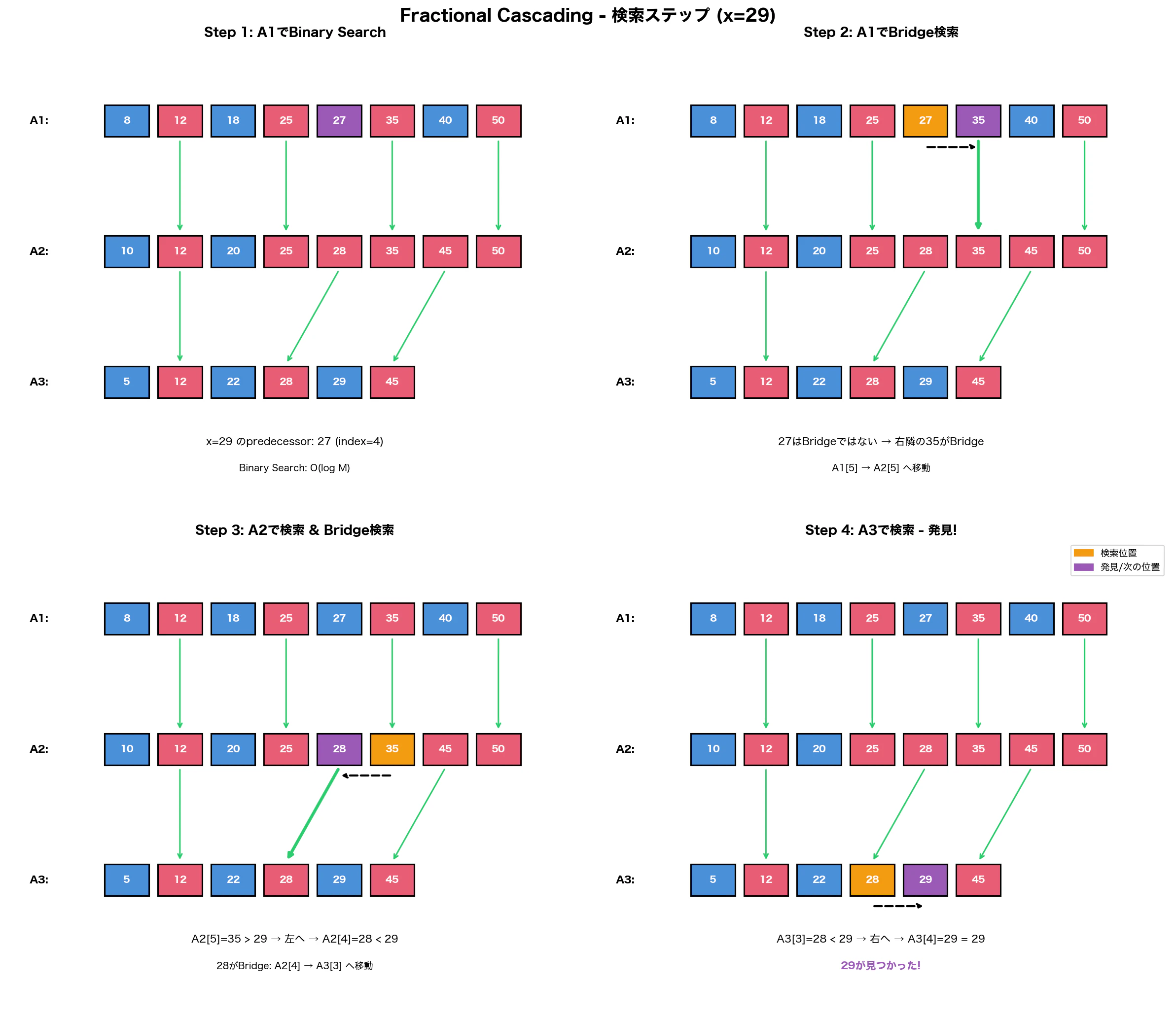
x = 29が3つの配列に含まれているかを上記の構造を利用して検索します。
検索は配列のレベルが低いほうから高いほうに向けて行います。(配列 at levels[i] -> 配列 at levels[i+1]、この例ではA1 -> A2 -> A3の順番]
Step 1 — A1内の検索
一番レベルが低い(Level0)のA1の配列に29のpredecessor(x <= 29となる最大の値)が存在するかを検索します。ここでは配列がソートされているためBinary Searchを実行し値を検索します。この配列では27がpredecessorとなります。
Binary SearchのためTime Complexityはlog(M)となります。(配列の要素数をMとする)
Step 2 — A1内でBridgeの検索
predecessorである27がBridgeであるか(Level1の配列A2に向けてポインターを作成しているか)を確認します。この例の場合Bridgeではないため、27から右の方向に(インデックスの大きい方向に)順にBridge要素を検索していきます。(27 < 29のため)
この例では27の右隣の35がBridgeであることを確認します。
Time Complexityはpredecessorと右隣の要素からbridgeが存在するかどうかの2回の確認で、log(1)となります。ここでの検索する要素の数は最大でNとなります。
Step3 - Bridgeから次の配列への移動し、A2内で検索
A1[5] -> A2[5]のポインターに従って、A2[5]に到着します。A2[5]を起点として、A2内のpredecessorを検索します。
まず起点であるA2[5](=35) と29を比較します。35 > 29のため、これより左の要素を順に検索していきます。左隣の要素A2[4](28)と29を比較します。28 < 29 のため28がpredecessorとなります。次にpredecessorとなったA2[4]を起点としてBridgeを検索します。ここではA2[4](28)がBridgeとなります。Time ComplexityはA2[4](28)がBridgeであるかどうかの確認で、log(1)となります。
Step4 - Bridgeから次の配列への移動し、A3内で検索
A2[4] -> A3[3]のポインターに従って、A3[3]に到着します。A3[3]を起点にして、predecessorを検索します。
まず起点であるA3[3](=28) と29を比較します。28 < 29のため、これより右の要素を順に検索していきます。右隣の要素A3[4](=29)と29を比較します。29 = 29 のため配列に29が存在していることがわかりました。Time Complexityはpredecessorと右隣の要素との比較でlog(1)となります。
コスト
- A1でのBinary Searchによる検索 -
O(logM) - A1でのBridge検索 -
O(1) - A2でのBridge検索 -
O(1) - A3でのBridge検索 -
O(1)
k = 配列の数とすると合計 O(logM + k)になります。
Bridgeを使用しない場合は、A1->A2->A3と順番にBinary Searchを実行してキーを検索するためTime ComplexityはO(logM * k)となります。
Code
サンプルコード
from dataclasses import dataclass
from typing import Optional
@dataclass
class Item:
level: int
value: int
bridged_index: Optional[int] = None
def transform_items(level: int, run: list[int]) -> list[Item]:
return [Item(level, value) for value in run]
def binary_search_predecessor(run: list[Item], value: int) -> tuple[Optional[int], int]:
"""
Return:
(exact_value_or_predecessor_value, predecessor_index)
If value exists, predecessor_index is the exact-match index.
If value does not exist, predecessor_index is the index of the
largest element <= value.
If value is smaller than all elements, returns (None, -1).
"""
if not run:
return None, -1
left = 0
right = len(run) - 1
pred_index = -1
while left <= right:
mid = (left + right) // 2
mid_value = run[mid].value
if mid_value == value:
return mid_value, mid
elif mid_value < value:
pred_index = mid
left = mid + 1
else:
right = mid - 1
if pred_index == -1:
return None, -1
return run[pred_index].value, pred_index
def sample_lower_run(lower_run: list[Item], n: int, start: int = 1) -> list[Item]:
"""
Pull every n-th element from the lower run.
Each pulled-up item keeps a bridge to its original index in lower_run.
"""
sampled: list[Item] = []
for lower_index in range(start, len(lower_run), n):
sampled.append(
Item(
level=lower_run[lower_index].level - 1,
value=lower_run[lower_index].value,
bridged_index=lower_index,
)
)
return sampled
def merge_upper_with_sampled(upper_run: list[Item], sampled: list[Item]) -> list[Item]:
"""
Linear merge of two sorted lists:
- upper_run: original items already in the upper level
- sampled: pulled-up items from the lower level, each with a bridged_index
If the same value exists in both, keep the original upper item and skip
the pulled-up duplicate.
"""
merged: list[Item] = []
i = 0
j = 0
while i < len(upper_run) and j < len(sampled):
upper_value = upper_run[i].value
sampled_value = sampled[j].value
if upper_value < sampled_value:
merged.append(upper_run[i])
i += 1
elif upper_value > sampled_value:
merged.append(sampled[j])
j += 1
else:
merged.append(upper_run[i])
i += 1
j += 1
while i < len(upper_run):
merged.append(upper_run[i])
i += 1
while j < len(sampled):
merged.append(sampled[j])
j += 1
return merged
def build_data_structure(runs: dict[int, list[int]], max_level: int, n: int) -> dict[int, list[Item]]:
"""
Build fractional cascading structure bottom-up.
Steps:
1. Convert raw ints to Item objects.
2. For each level from bottom to top:
- sample every n-th item from lower run
- merge sampled items into upper run in linear time
"""
item_runs: dict[int, list[Item]] = {}
for level in range(max_level + 1):
item_runs[level] = transform_items(level, runs[level])
for level in range(max_level, 0, -1):
lower_run = item_runs[level]
upper_run = item_runs[level - 1]
sampled = sample_lower_run(lower_run, n=n, start=1)
item_runs[level - 1] = merge_upper_with_sampled(upper_run, sampled)
return item_runs
def print_runs(runs: dict[int, list[Item]]) -> None:
for level in sorted(runs.keys()):
print(f"Level {level}:")
for idx, item in enumerate(runs[level]):
print(
f" idx={idx:2d}, value={item.value:2d}, "
f"bridged_index={item.bridged_index}"
)
print()
def find_bridge_index(built: dict[int, list[Item]], idx: int, level: int) -> int:
"""
Find the nearest bridge to the next level starting from position idx.
Search forward first (for elements >= current position),
then backward if no forward bridge found.
Returns the bridged_index pointing to the next level, or -1 if no bridge found.
"""
run = built[level]
run_len = len(run)
# Search forward from idx
for i in range(idx, run_len):
if run[i].bridged_index is not None:
return run[i].bridged_index
# Search backward from idx-1 if no forward bridge found
for i in range(idx - 1, -1, -1):
if run[i].bridged_index is not None:
return run[i].bridged_index
return -1
def local_search_predecessor(run: list[Item], start_idx: int, search_key: int, window: int) -> int:
"""
Search for the predecessor of search_key in a local window around start_idx.
The window size is determined by the sampling rate n.
Returns the index of the largest element <= search_key within the window,
or -1 if no such element exists.
"""
run_len = len(run)
# Calculate search bounds
left_bound = max(0, start_idx - window)
right_bound = min(run_len - 1, start_idx + window)
# Find the largest element <= search_key in the window
best_idx = -1
for i in range(left_bound, right_bound + 1):
if run[i].value <= search_key:
if best_idx == -1 or run[i].value > run[best_idx].value:
best_idx = i
return best_idx
def search(
built: dict[int, list[Item]],
num_levels: int,
search_key: int,
n: int
) -> list[tuple[int, Optional[int]]]:
"""
Search for search_key across all levels using fractional cascading.
Returns a list of (level, index) tuples where:
- index is the position of the exact match if found
- index is the position of the largest element <= search_key (predecessor)
- index is None if search_key is smaller than all elements in that level
Time complexity: O(log m + k) where m is the size of level 0 and k is number of levels.
"""
results: list[tuple[int, Optional[int]]] = []
if not built or 0 not in built or not built[0]:
return results
# Binary search on level 0
_, idx = binary_search_predecessor(built[0], search_key)
if idx == -1:
results.append((0, None))
else:
results.append((0, idx))
current_idx = idx if idx >= 0 else 0
# Cascade through remaining levels
for level in range(num_levels):
# Find bridge to next level
bridge_idx = find_bridge_index(built, current_idx, level)
if bridge_idx == -1:
# No bridge found, need to do binary search on next level
_, next_idx = binary_search_predecessor(built[level + 1], search_key)
results.append((level + 1, next_idx if next_idx >= 0 else None))
current_idx = next_idx if next_idx >= 0 else 0
else:
# Use bridge and do local search
next_idx = local_search_predecessor(built[level + 1], bridge_idx, search_key, n)
results.append((level + 1, next_idx if next_idx >= 0 else None))
current_idx = next_idx if next_idx >= 0 else bridge_idx
return results
def find_exact_match(
built: dict[int, list[Item]],
num_levels: int,
search_key: int,
n: int
) -> Optional[tuple[int, int]]:
"""
Search for an exact match of search_key across all levels.
Returns (level, index) of the first exact match found, or None if not found.
"""
results = search(built, num_levels, search_key, n)
for level, idx in results:
if idx is not None and built[level][idx].value == search_key:
return level, idx
return None
def main(runs: dict[int, list[int]], num_levels: int, search_key: int, n: int) -> Optional[tuple[int, int]]:
"""
Build the fractional cascading structure and search for search_key.
Returns (level, index) if exact match found, otherwise (None, None).
"""
built = build_data_structure(runs, max_level=num_levels, n=n)
print_runs(built)
# Search across all levels
results = search(built, num_levels, search_key, n)
print(f"\nSearch results for key {search_key}:")
for level, idx in results:
if idx is not None:
value = built[level][idx].value
match_type = "EXACT" if value == search_key else "predecessor"
print(f" Level {level}: idx={idx}, value={value} ({match_type})")
else:
print(f" Level {level}: no predecessor found")
# Check for exact match
exact_match = find_exact_match(built, num_levels, search_key, n)
if exact_match:
level, idx = exact_match
print(f"\nSearch key {search_key} found at level {level}, index {idx}")
return level, idx
else:
print(f"\nSearch key {search_key} not found (no exact match)")
return None, None
if __name__ == "__main__":
runs = {
0: [8, 18, 27, 40],
1: [10, 20, 25, 35, 50],
2: [5, 12, 22, 28, 29, 45],
}
n = 2
num_levels = 2
search_key = 29
main(runs, num_levels, search_key, n)
まとめ
Bridgeという形で連結された配列を使用することで、効率的にキーの検索ができることが分かりました。