はじめに
ビジネス系部門からシステム系部門にテキスト解析して欲しいという依頼があったものの、解析対象のデータは全てWordファイル!という状況は時々あると思います。
そのような時、まずはWordファイルからテキストを抽出する必要があり、本記事ではその方法をご紹介します。
Wordファイルからのテキスト抽出
ライブラリのインストール
Pythonのpython-docxというライブラリを使えば、簡単にWordファイルからテキスト抽出ができます。
python-docxは、次のようにpipコマンドを使えば一発でインストールできます。
$ pip install python-docx
テキスト抽出対象のWordファイル
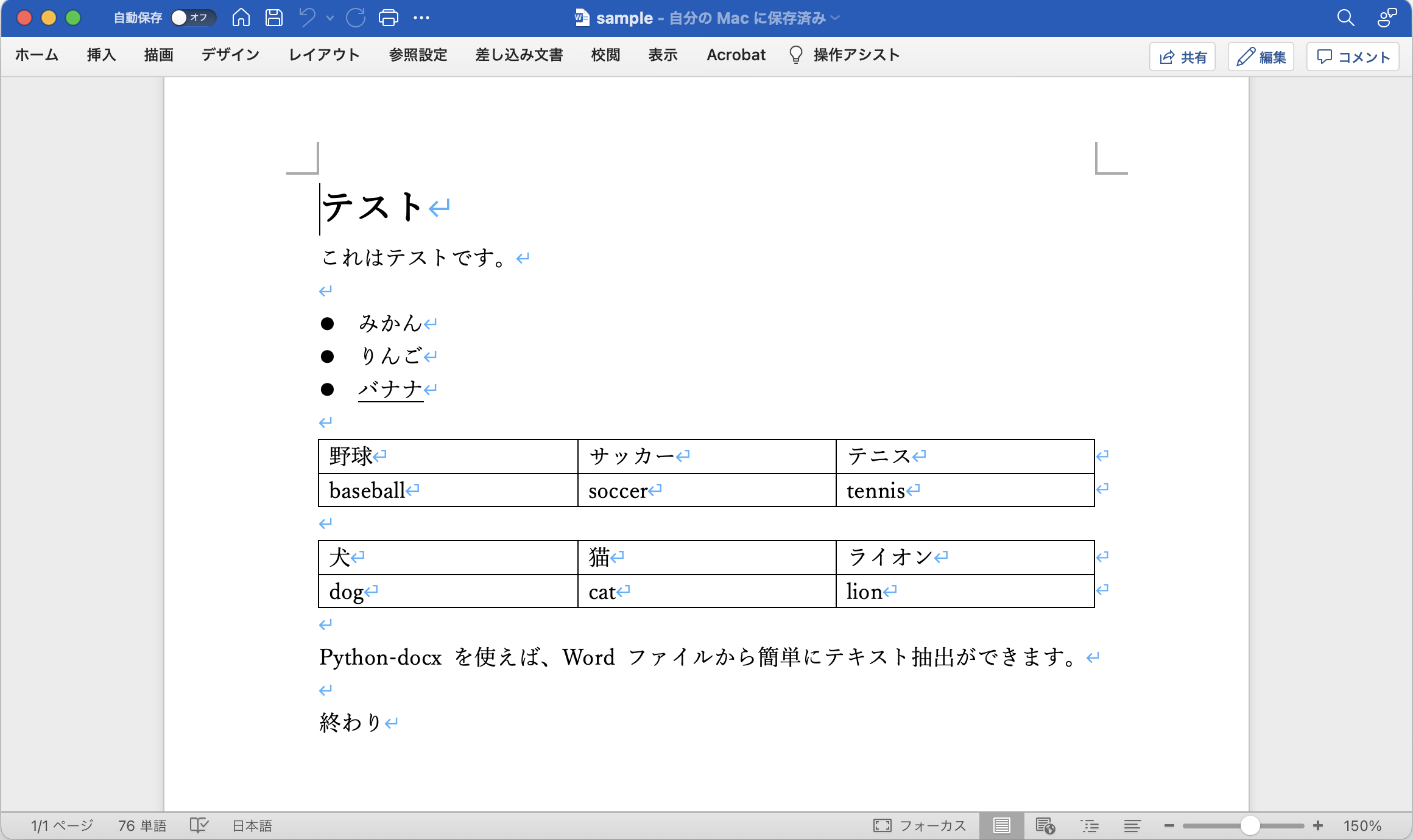
次のようなWordファイルを用意します。ファイル名はsample.docxとします。
本文中のテキスト抽出
from docx import Document
document = Document('./sample.docx')
for i, p in enumerate(document.paragraphs):
print(i, p.text)
上記のプログラムを実行すると、次のような結果が得られます。フォントサイズも関係なく、また箇条書きの文も抽出されていることが分かります。
ただし、表の中のテキストは抽出されていません。表の中のテキストを抽出するためには、別の書き方をする必要があります。
$ python sample2.py
0 テスト
1 これはテストです。
2
3 みかん
4 りんご
5 バナナ
6
7
8
9 Python-docx を使えば、Word ファイルから簡単にテキスト抽出ができます。
10
11 終わり
表中のテキスト抽出
from docx import Document
document = Document('./sample.docx')
for i, t in enumerate(document.tables):
for j, r in enumerate(t.rows):
for k, c in enumerate(r.cells):
print(i, j, k, c.text)
やや冗長な書き方になりますが、上記のプログラムを実行すると、次のような結果が得られます。
表の中のテキストをセル毎に抽出できていることが分かります。
$ python sample2.py
0 0 0 野球
0 0 1 サッカー
0 0 2 テニス
0 1 0 baseball
0 1 1 soccer
0 1 2 tennis
1 0 0 犬
1 0 1 猫
1 0 2 ライオン
1 1 0 dog
1 1 1 cat
1 1 2 lion
Wordファイルからの文字列検索
Wordファイルからのテキスト抽出ができれば、そこから文字列検索もできます。
特定の単語の出現有無を自動判定したいというのは、ビジネス上のユースケースとしてよくあると思います。
サンプルプログラムを下記に載せておきます。
from docx import Document
document = Document('./sample.docx')
text = ''
# 本文中のテキスト抽出
for i, p in enumerate(document.paragraphs):
text += p.text
# 表中のテキスト抽出
for i, t in enumerate(document.tables):
for j, r in enumerate(t.rows):
for k, c in enumerate(r.cells):
text += c.text
# 特定の単語(例:バナナ)の文字列検索
if 'バナナ' in text:
print('Found.')
else:
print('Not found.')
おわりに
Wordファイルからのテキスト抽出、および文字列検索の方法をご紹介しました。
本記事では、元のファイルからテキストを抜き出す処理に焦点を絞りましたが、python-docxは元のファイルにテキストを追加する処理もできるようです。
サンプルコードに載っているように、テキストや表の書き込みだけでなく画像貼り付けもできます。ご興味がある方は是非チャレンジして下さい。
また、本記事ではあえて触れませんでしたが、WordファイルからではなくPDFファイルからテキストを抽出したいという場面もあると思います。
ビジネスの現場では、WordファイルよりもPDFファイルの方が使用頻度が高いはずです。
その場合、pdf2docxのようなPDFファイルをWordファイルに変換するライブラリを利用し、PDFファイルをWordファイルに変換した上で本記事でご紹介した方法を試すという解決策が考えられます。
ただし、PDFファイルをWordファイルに変換する過程で、意図しない箇所(Wordは見た目は改行されれていも文が続いていればそれを内部で把握しているが、PDFは見た目が改行されていると文が続いていたとしてもそこで改行されていると見なす)に改行が入ります。
そのため、文単位でテキスト処理をしたい場合、不具合が生じることがあります。
これはPDFの仕様上仕方がないことであり、詳しく知りたい方はこちらの記事をご覧下さい。
その場合、PDFファイルではなくWordファイルを使うように業務側のフローを変更するなどの対応が必要になります。
大きな組織では業務側のフロー変更はハードルが高いことが多いですが、Wordファイルであればテキスト抽出からテキスト処理まで自動で処理できるようになるため得られるメリットは非常に大きいはずです。