初めに
初めまして!kenpiro0207と言います。
今投稿が初投稿のため、至らぬ点や改善点など多々あるかと思いますが、
最後までお付き合いいただけますと幸いです。
前置きはこのくらいにしておきます。
このページでは、社内チャットボット(以下CB)の管理者画面機能を開発時にStreamlitを用いたため、
使用感・調査結果・開発途中で感じたことを皆さんに共有できればと思っています。
作成した管理者機能は以下の通りです。
同じように機能を作成したいという方の助けになれば幸いです。
・Cosmos DBの評価データ確認
・評価データフィルタリング
・評価データをExcelファイルで保存
・Blob storage内の格納ファイル確認・削除・格納
Streamlitとは
Pythonを使用して簡単にweb画面を作成できるオープンソースのフレームワークのこと。
また、Excelとの連携や表・グラフの表示・分析が可能なため、データの可視化や分析結果の共有が簡単に行うことができる。
メリット
- Pythonの知識のみでWeb画面を作成可能(Java script・HTML・CSSの知識が必要ない)
- 機能が豊富で、「これ実装したい」と思ったものは大体存在する
- オープンソースのため、無料で利用できる
- Excelや後述するAzureとの連携も容易なため、幅広い活用性
デメリット
- よりこだわったものを作成しようとするとCSSの知識が必要になる。(Streamlit内でCSSを設定可能)
- カスタマイズ性には限界があるため、自社にしかないデザインのものを作りたい場合は不向き
- Streamlit自体が新しいフレームワークのため、他のフレームワークに比べるとドキュメントや機能が不足している(個人的には現時点で十分満足)
どんな人に向いてる?
- フロントエンド言語を経験したことはないが、WEBサイトを作成したい人
- すぐにWeb画面を用意したい!という人
どんな人に向いてない?
- じっくりとフロントエンドを学びたいと思ってる人
- オリジナリティあふれるWEB画面を作成したい人
以上が簡単にStreamlitを説明したものになります。
ここまでの情報をまとめると、
Pythonの知識があればすぐにweb画面を作成できるフレームワーク。ただし、カスタマイズ性については高くない。
Streamlitを使用するに至った経緯
CBを開発するにあたり、質問内容・質問者・評価結果を確認できる管理者用の画面が
必要になったため、この機能を開発しました。
管理者画面の作成案については2つあって、片方を試してうまくいかなかったため、Streamlitを使用しています。
作成案について
- Microsoftが提供するチュートリアルを用いて、Azure Cosmos DBとStatic Web Appを連携させ、JavaScript・HTMLを使って画面を表示する方法
- Streamlitを用いて、PythonのコードでAzure Cosmos DBを画面上で表示させる方法
1の方法Azure Static Web Apps でのデータベース接続の構成 (プレビュー)は、
チュートリアル通りに実行しましたが、ローカルでの動作確認段階でCosmosDBとの接続が出来ないため、断念しました。
(もし、この方法で上手く行った方いれば教えていただきたいです!)
1の方法は、カスタマイズ性はあったのですが、実装できないということで
カスタマイズ性は減るが、Pythonの知識があれば実装できるStreamlitを用いた画面の開発となりました。
今回実装したコード
今回作成したコードを記載します。(APIキーやエンドポイントといった個人の情報がわかるデータはあらかじめ省いています。)
後述でブロック分けして解説しています。
import streamlit as st
import pandas as pd
from azure.cosmos import CosmosClient
from io import BytesIO
from azure.storage.blob import BlobServiceClient
from datetime import timezone, timedelta
# Azure Cosmos DB 接続情報を入力する
cosmos_endpoint = "YOUR_COSMOSDB_ENDPOINT"
cosmos_key = "YOUR_COSMOSDB_KEY"
database_name = 'YOUR_DATABASE_NAME'
cosmos_container_name = 'YOUR_CONTAINER_NAME'
# クライアントの初期化
cosmos_client = CosmosClient(cosmos_endpoint,cosmos_key)
database = cosmos_client.get_database_client(database_name)
cosmos_container = database.get_container_client(cosmos_container_name)
# Azure Blob Storageの接続情報
blob_endpoint = "YOUR_BLOB_ENDPOINT"
blob_container_name = "YOUR_BLOB_CONTAINER_NAME"
# BlobServiceClientの作成
blob_service_client = BlobServiceClient.from_connection_string(blob_endpoint)
blob_container_client = blob_service_client.get_container_client(blob_container_name)
# データの取得
query = "SELECT * FROM c ORDER BY c._ts DESC"
# それぞれをリストに格納し、items変数に格納する
items = list(cosmos_container.query_items(query, enable_cross_partition_query=True))
# 必要なフィールドのリストを定義
need_fields = ['current_time','user', 'input', 'response', 'title', 'chunk_id_1', 'chunk_id_2', 'chunk_id_3', 'id']
# フィールドを抽出した新しいリストを作成
filtered_items = [{key: item[key] for key in need_fields if key in item} for item in items]
# Streamlit アプリの構築---------------------------------------------------------
#ページ全体の幅を広げる(これは一番初めに書く!書かないとエラーになる)
st.set_page_config(layout="wide")
# サイドバーにセレクトボックスを追加
page = st.sidebar.selectbox("ページを選択してください", ["評価一覧/検索", "ファイルアップロード","格納ファイル一覧表示","インデクシング"])
#評価一覧確認機能の実装------------------------------------------------------------------
if page == "評価一覧/検索":
st.title("評価一覧/検索")
# データをデータフレームに変換し、選択された件数分表示
dataframe = pd.DataFrame(filtered_items)
# 表示件数の選択(今回の場合だとページが読み込まれた際に10件表示される)
display_count = st.slider('表示する件数を選択してください:', min_value=1, max_value=len(filtered_items), value=10)
#検索フィールドを作成
search_low = st.selectbox("検索する列を選択してください", dataframe.columns)
search_query = st.text_input("検索したいキーワードを入力してください")
#検索キーワードと一致するデータをフィルタリング処理
if st.button("検索"):
if search_query:
filtered_df = dataframe[dataframe[search_low].astype(str).str.contains(search_query, case=False, na=False)]
else:
filtered_df = dataframe
else:
filtered_df = dataframe
# フィルタリング結果を表示
st.dataframe(filtered_df.head(display_count), use_container_width=True)
#Excel形式で出力する際に使用する変数(既存のダウンロードだと文字化けしたため)
def to_excel(dataframe):
#メモリ内にバッファを作成し、書き出したり書き込んだりを行う
output = BytesIO()
with pd.ExcelWriter(output, engine='xlsxwriter') as writer:
dataframe.to_excel(writer, index=False, sheet_name='Sheet1')
return output.getvalue()
excel_data = to_excel(filtered_df)
st.download_button(
label="データをダウンロード",
data=excel_data,
file_name='cosmosdb_data.xlsx',
mime='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'
)
#ファイルアップロード機能の実装--------------------------------------------------------------------------
elif page == "ファイルアップロード":
st.title("ファイルアップロード")
# フォームの作成(フォームにすることで、入力が終了した後に、自動で値を空にできる)
with st.form(key='upload_form', clear_on_submit=True):
# ファイルアップローダーを作成
uploaded_file = st.file_uploader("ファイルを選択してください", type=["csv", "xlsx", "txt", "pdf"])
#空のmetadataを設定
metadata ={}
# メタデータ入力フィールド(デフォルトで名前が入っているようにする。)
default_keys = ["metadata_storage_path","sharepoint_url"]
default_values = ["",""]
#metadataを2つ設定させる
for i in range(2):
key = st.text_input(f"メタデータ キー{i+1}", value=default_keys[i], key=f"key_{i}")
value = st.text_input(f"メタデータ 値{i+1}", value=default_values[i], key=f"value_{i}")
if key and value:
metadata[key]=value
# フォームの送信ボタン
submit_button = st.form_submit_button(label='アップロード')
# アップロードボタン
if submit_button:
try:
if uploaded_file is not None:
# BlobClient の作成
blob_client = blob_service_client.get_blob_client(container=blob_container_name, blob=uploaded_file.name)
# ファイルをアップロードし、メタデータを設定
blob_client.upload_blob(uploaded_file, metadata=metadata, overwrite=True)
st.success(f"{uploaded_file.name} をアップロードしました。")
else:
st.error("ファイルを選択してください。")
except:
st.error("metadataの値に日本語は使用できません。")
#アップロードされているファイル確認画面の実装--------------------------------------------------------------
elif page=="格納ファイル一覧表示":
st.title("格納ファイル一覧表示")
def get_blob_info_list():
#blob_listにblobstorage内のデータを格納
blob_list = blob_container_client.list_blobs()
blob_info_list = []
#blob_listからデータを取得し、それぞれのpropatyも取得する
for blob in blob_list:
blob_client = blob_container_client.get_blob_client(blob.name)
properties = blob_client.get_blob_properties()
#日本時間になっていないので、日本時間に修正する
#プロパティから時間を取得
creation_time_az = properties.creation_time
last_modified_az = properties.last_modified
# JST タイムゾーンの定義(時差を治す)
jst_timezone = timezone(timedelta(hours=9))
#日本時間に修正する
creation_time_jp = creation_time_az.astimezone(jst_timezone) if creation_time_az else None
last_modified_jp = last_modified_az.astimezone(jst_timezone) if last_modified_az else None
#必要な情報だけ表示する
blob_info ={
"ファイル名":blob.name,
"サイズ(kB)":f"{blob.size / 1024:.1f}",
"作成日時":creation_time_jp.strftime("%Y-%m-%d %H:%M:%S") if creation_time_jp else "N/A",
"最終更新日時":last_modified_jp.strftime("%Y-%m-%d %H:%M:%S") if last_modified_jp else "N/A",
"metadata_storage_path":properties.metadata.get("metadata_storage_path","N/A"),
"sharepoint_url":properties.metadata.get("sharepoint_url","N/A")
}
blob_info_list.append(blob_info)
return blob_info_list
blob_info_list = get_blob_info_list()
if blob_info_list:
#DataFrameに変換
df = pd.DataFrame(blob_info_list)
#DataFrameを表示させる
st.dataframe(df, use_container_width=True)
# 削除機能の実装
st.subheader("ファイル削除")
delete_file = st.selectbox("削除するファイルを選択してください",df["ファイル名"].tolist())
if st.button("削除"):
#確認用ダイアログを表示させる
@st.dialog("削除の確認")
def delete_judge():
st.write(f"本当に{delete_file}を削除しますか?")
if st.button("はい"):
try:
#削除したいファイルの情報のみ取得する
blob_client = blob_container_client.get_blob_client(delete_file)
blob_client.delete_blob()
st.write(f"{delete_file}を削除しました")
except Exception as e:
st.write(f"{e}によってファイルを削除できませんでした")
#ダイアログを閉じる
st.rerun()
st.success(f"{delete_file} を削除しました。")
elif st.button("いいえ"):
st.write("ファイル削除を取り消しました。")
#ダイアログを閉じる
st.rerun()
# 確認ダイアログの関数を呼び出す
delete_judge()
else:
st.write("コンテナにファイルが存在しません")
elif page == "インデクシング":
st.title("実装予定")
それでは、各ブロックに分けて詳しく説明していきます!
事前準備
import streamlit as st
import pandas as pd
from azure.cosmos import CosmosClient
from io import BytesIO
from azure.storage.blob import BlobServiceClient
from datetime import timezone, timedelta
必要なもの
・Azure Cosmos Databaseのアカウント
・Azure Blob storageのアカウント
・Python 3.8以上
pip install azure-cosmos azure-storage-blob pandas xlsxwriter streamlit
・Pythonの基礎的な知識
以上があれば大丈夫です!
Azure Cosmos Databaseとの接続
エンドポイント・キー・データベース名・コンテナ名は各自が使用しているものを設定します。
取得したエンドポイントとキーを使用してclient(認証情報)を作成し、それに基づいてデータを取得します。
# Azure Cosmos DB 接続情報を入力する
cosmos_endpoint = "YOUR_COSMOSDB_ENDPOINT"
cosmos_key = "YOUR_COSMOSDB_KEY"
database_name = 'YOUR_DATABASE_NAME'
cosmos_container_name = 'YOUR_CONTAINER_NAME'
# クライアントの初期化
cosmos_client = CosmosClient(cosmos_endpoint,cosmos_key)
database = cosmos_client.get_database_client(database_name)
cosmos_container = database.get_container_client(cosmos_container_name)
Azure Blob storageとの接続
こちらも各自使用しているものを設定してください。
# Azure Blob Storageの接続情報
blob_endpoint = "YOUR_BLOB_ENDPOINT"
blob_container_name = "YOUR_BLOB_CONTAINER_NAME"
# BlobServiceClientの作成
blob_service_client = BlobServiceClient.from_connection_string(blob_endpoint)
blob_container_client = blob_service_client.get_container_client(blob_container_name)
データの取得
SQL構文を用いて、CosmosDBから取得したいデータを選択しています。
今回の場合はSELECT *で全件取得したものをc._ts DESCで時刻降順に表示するよう指示しています。
その後、取得したデータをリスト形式で格納しています。
※enable_cross_partition_query=Trueはデータ全体から必要な情報を持って来るようにしてるくらいの認識です。
query = "SELECT * FROM c ORDER BY c._ts DESC"
# それぞれをリストに格納し、items変数に格納する
items = list(cosmos_container.query_items(query, enable_cross_partition_query=True))
画面に必要なデータだけ表示させる
このままだと、Azureがデータ格納時設定したにuserにとって必要ないデータが表示されてしまうので、必要な情報だけ表示されるように処理をします。
必要なフィールドは定義した順番に左側から表示されるため、順番を入れ替えて欲しい情報が最初に来るようにしてください。
# 必要なフィールドのリストを定義
need_fields = ['current_time','user', 'input', 'response', 'title', 'chunk_id_1', 'chunk_id_2', 'chunk_id_3', 'id']
# フィールドを抽出した新しいリストを作成
filtered_items = [{key: item[key] for key in need_fields if key in item} for item in items]
こんな感じで表示される

WEB画面全体の処理
ここから、StreamlitをつかってWEB画面の設計に入っていきます。
デフォルトの状態だと、ページの中央部分にしかデータが表示されないため、st.set_page_configを使って、画面の横幅いっぱいに表示されるようにします。
st.sidebar.selectboxは画面左上にページ切り替えを表示させます。
#ページ全体の幅を広げる(これは一番初めに書く!書かないとエラーになる)
st.set_page_config(layout="wide")
# サイドバーにセレクトボックスを追加
page = st.sidebar.selectbox("ページを選択してください", ["評価一覧/検索", "ファイルアップロード","格納ファイル一覧表示","インデクシング"])
st.sidebar.selectboxを使うとこんなのが出てくる

評価一覧機能の実装
WEB上でCosmos DBに格納されたデータを確認するための処理を行う
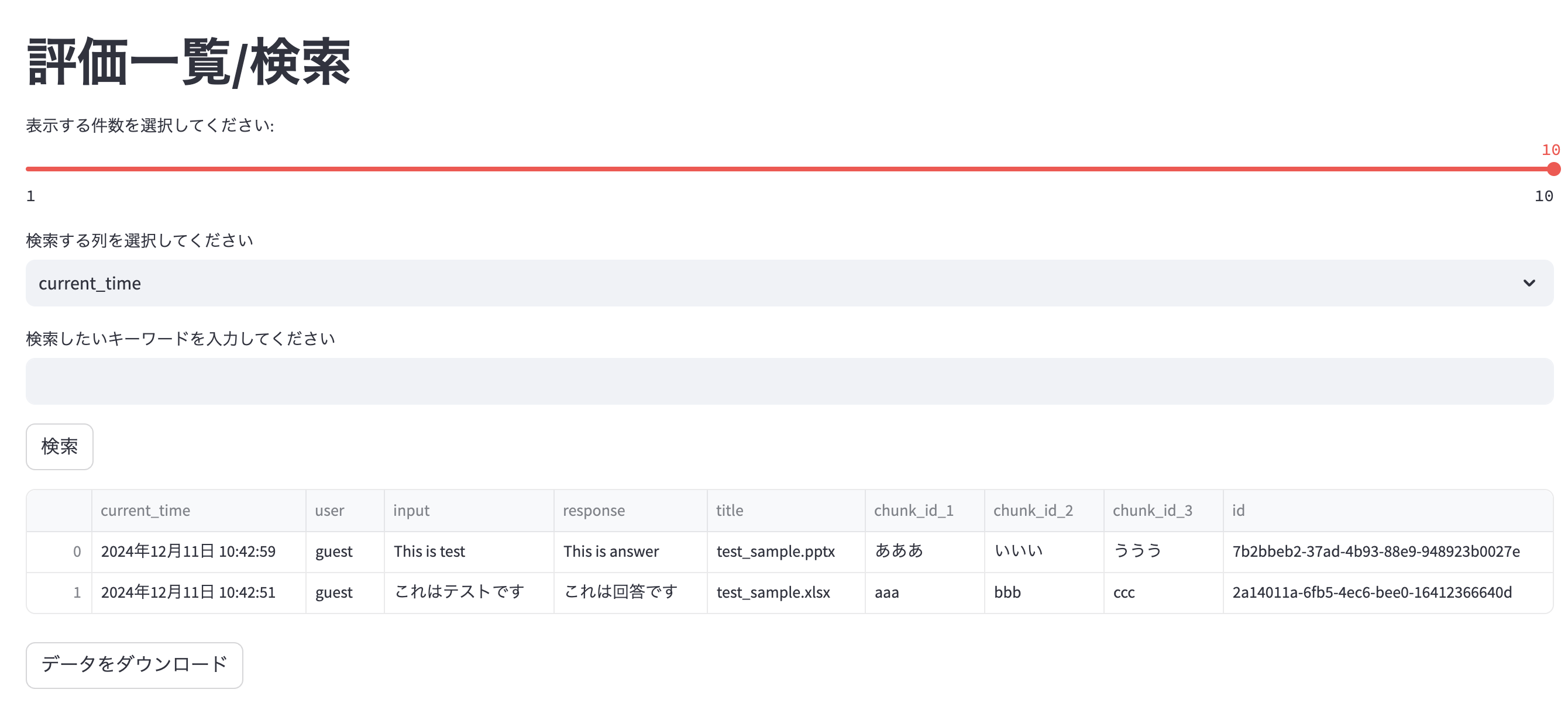
取得したデータをDataFrameに変換
先ほどのセレクトボックスで"評価一覧/検索"が設定された場合にこの処理に辿り着くようにします。
st.titleは名前の通り、画面のタイトルを設定します。
pd.DataFrameはpandasを使用して、取得したデータを表形式のフレームに変換しています。
pandasについてはこちらのサイトを見てください。
→https://aiacademy.jp/media/?p=152
if page == "評価一覧/検索":
st.title("評価一覧/検索")
# データをデータフレームに変換し、選択された件数分表示
dataframe = pd.DataFrame(filtered_items)
検索機能の実装(データ件数)
st.sliderを使用して、画面に表示される件数を選択することができます。
min_value=1で最小件数1
max_value=len(filtered_items)で読み込まれた件数を最大件数
value=10で画面作成時に読み込まれる件数を制限しています。
特に、valueは読み込まれるデータが多い場合だと、処理がうまくされないことがあるため、設定しておく必要があります。
# 表示件数の選択(今回の場合だとページが読み込まれた際に10件表示される)
display_count = st.slider('表示する件数を選択してください:', min_value=1, max_value=len(filtered_items), value=10)
実装するとこんな感じ

検索機能の実装(文字列検索)
st.selectboxとst.text_inputを使用して、検索したい列に検索したいキーワードが存在する場合、一致するものだけを表示させる処理を設定。
st.buttonで作成した検索ボタンを押した際に、一致するものがある場合はそのデータを、ない場合はリスト全体を返す。
astype(str).str.containsで入力されたキーワードを文字列(str型)に変換し、na=Falseで大文字小文字の区別を削除している。
#検索フィールドを作成
search_low = st.selectbox("検索する列を選択してください", dataframe.columns)
search_query = st.text_input("検索したいキーワードを入力してください")
#検索キーワードと一致するデータをフィルタリング処理
if st.button("検索"):
if search_query:
filtered_df = dataframe[dataframe[search_low].astype(str).str.contains(search_query, case=False, na=False)]
else:
filtered_df = dataframe
else:
filtered_df = dataframe
# フィルタリング結果を表示
st.dataframe(filtered_df.head(display_count), use_container_width=True)
検索前
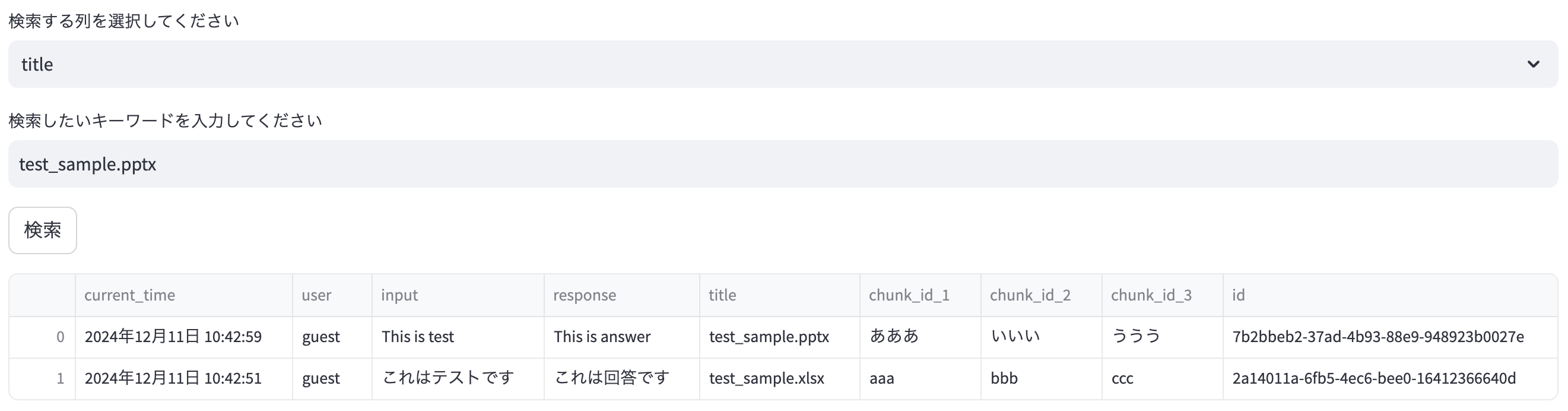
検索後

評価一覧で表示されたファイルをエクセルファイルとして保存
この関数を作成したのは、ExcelファイルをStreamlitの機能を使用して、そのままダウンロードすると文字化けを起こしたためです。
対処法として、一度メモリ内にExcelファイルとして書き出し、そのファイルをそのままダウンロードする形をとったところ解決しました。
このコードでは、pandasのExcelWriterというExcelファイルに最適な形で書き出してくれるツールを使用しています。
#Excel形式で出力する際に使用する変数(既存のダウンロードだと文字化けしたため)
def to_excel(dataframe):
#メモリ内にバッファを作成し、書き出したり書き込んだりを行う
output = BytesIO()
with pd.ExcelWriter(output, engine='xlsxwriter') as writer:
dataframe.to_excel(writer, index=False, sheet_name='Sheet1')
return output.getvalue()
excel_data = to_excel(filtered_df)
Excelファイルをダウンロード
st.download_buttonでファイルをダウンロードするボタンを設定できる。
st.download_button(
label="データをダウンロード",
data=excel_data,
file_name='cosmosdb_data.xlsx',
mime='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'
)
ダウンロードボタンが設定される

ファイルアップロード機能の実装
WEB画面で選択したファイルをAzure Blob Storageに直接格納できるように処理を行う。

フォームとしてファイルアップロードボタンを設定する
アップロードボタンをフォームにしたのは、ファイルをアップロード時に自動で入力した値が空になって欲しかったからです。
st.formでformを作成し、引数のclear_on_submit=Trueでファイルがアップロードされた場合に値を空にするよう設定しています。
st.file_uploaderはファイルをアップロードするシステムを設定します。type=で提出可能な拡張子を制限することが可能です。

今回は metadataに最初から値が入っていて欲しかったので、default_keys=["metadata_storage_path","sharepoint_url"]と設定しています。
このように既にmetadataに値が入っています。

st.form_submit_buttonを設定することで、form内の情報をアップロードすることができます。
elif page == "ファイルアップロード":
st.title("ファイルアップロード")
# フォームの作成(フォームにすることで、入力が終了した後に、自動で値を空にできる)
with st.form(key='upload_form', clear_on_submit=True):
# ファイルアップローダーを作成
uploaded_file = st.file_uploader("ファイルを選択してください", type=["csv", "xlsx", "txt", "pdf"])
#空のmetadataを設定
metadata ={}
# メタデータ入力フィールド(デフォルトで名前が入っているようにする。)
default_keys = ["metadata_storage_path","sharepoint_url"]
default_values = ["",""]
#metadataを2つ設定させる
for i in range(2):
key = st.text_input(f"メタデータ キー{i+1}", value=default_keys[i], key=f"key_{i}")
value = st.text_input(f"メタデータ 値{i+1}", value=default_values[i], key=f"value_{i}")
if key and value:
metadata[key]=value
# フォームの送信ボタン
submit_button = st.form_submit_button(label='アップロード')
アップロードするファイルにメタデータを紐付ける
ボタンが押された時に、ファイルが体とエラーを返しますが、metadataがからでもエラーは返さないようにしています。(metadataがファイルの可能性もあるため)
metadata=metadataで先ほど設定したmetadataをファイルのmetadataとして扱います。
overwrite=Trueは同じファイルが既に存在していた場合、新しいファイルが上書きすることを許可しています。
metadataの値に日本語は設定できません。アルファベットか数字を入力するようにしましょう。
# アップロードボタン
if submit_button:
try:
if uploaded_file is not None:
# BlobClient の作成
blob_client = blob_service_client.get_blob_client(container=blob_container_name, blob=uploaded_file.name)
# ファイルをアップロードし、メタデータを設定
blob_client.upload_blob(uploaded_file, metadata=metadata, overwrite=True)
st.success(f"{uploaded_file.name} をアップロードしました。")
else:
st.error("ファイルを選択してください。")
except:
st.error("metadataの値に日本語は使用できません。")
Blob storageに格納されているファイルをWEB画面で確認
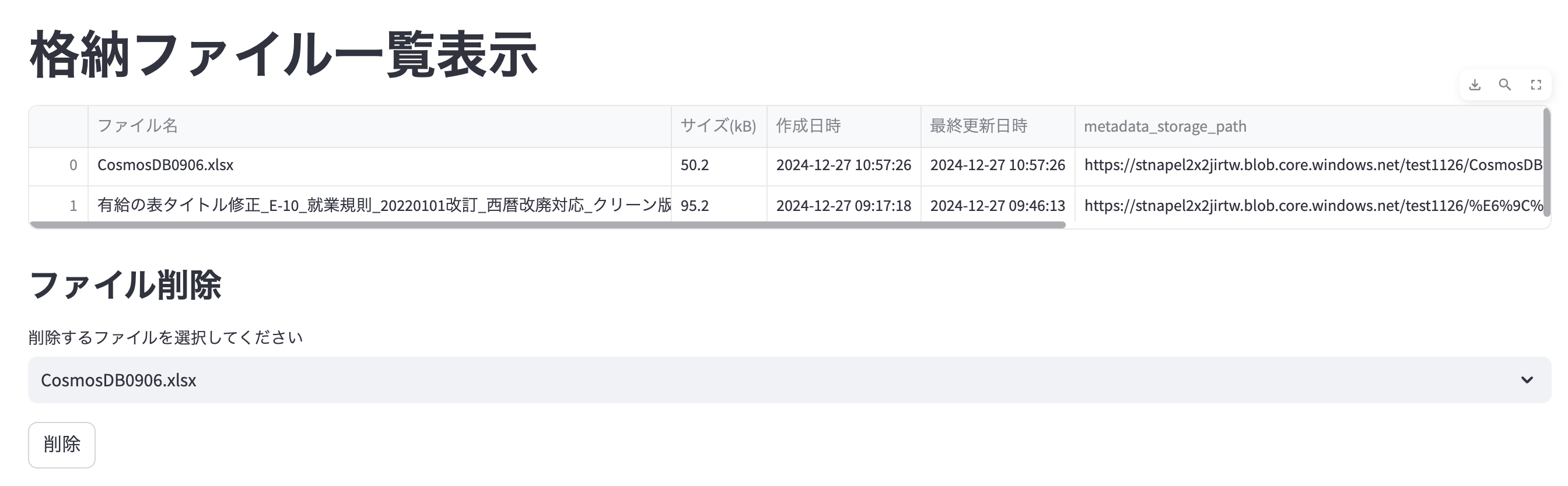
BlobStorageと接続する
get_blob_client(blob.name)で格納されているファイル名を取得
properties = blob_client.get_blob_properties()でファイルに紐づけられている詳細情報(投稿日時やサイズ)を取得
elif page=="格納ファイル一覧表示":
st.title("格納ファイル一覧表示")
def get_blob_info_list():
#blob_listにblobstorage内のデータを格納
blob_list = blob_container_client.list_blobs()
blob_info_list = []
#blob_listからデータを取得し、それぞれのpropatyも取得する
for blob in blob_list:
blob_client = blob_container_client.get_blob_client(blob.name)
properties = blob_client.get_blob_properties()
登録された時刻を日本時間に設定
Azureの設定時刻がイギリスの標準時時刻になっているため、日本時刻に直す必要がある。
今回はpropatyで作成日時と最終更新日時を取得したものに9時間足すことで日本の時刻に合わせている。
#日本時間になっていないので、日本時間に修正する
#プロパティから時間を取得
creation_time_az = properties.creation_time
last_modified_az = properties.last_modified
# JST タイムゾーンの定義(時差を治す)
jst_timezone = timezone(timedelta(hours=9))
#日本時間に修正する
creation_time_jp = creation_time_az.astimezone(jst_timezone) if creation_time_az else None
last_modified_jp = last_modified_az.astimezone(jst_timezone) if last_modified_az else None
取得したPropertyから必要な情報のみを取得する
propertyを全て表示すると必要のない情報も含まれるため、必要なものを抜き出す。
f"{blob.size / 1024:.1f}"Azureの格納データがByte単位で格納されているため、kBで表示するために1024で割っている。
.1fで小数点第一までを表示させている。
strftime("%Y-%m-%d %H:%M:%S")は日付・時刻を◯月◯日◯◯時◯◯分の形で表示させるために使用
properties.metadata.getにすることで、metadataから指定したmetadataの値を取得することができる。
metadataをそのまま持ってくると、リスト形式で表示される
#必要な情報だけ表示する
blob_info ={
"ファイル名":blob.name,
"サイズ(kB)":f"{blob.size / 1024:.1f}",
"作成日時":creation_time_jp.strftime("%Y-%m-%d %H:%M:%S") if creation_time_jp else "N/A",
"最終更新日時":last_modified_jp.strftime("%Y-%m-%d %H:%M:%S") if last_modified_jp else "N/A",
"metadata_storage_path":properties.metadata.get("metadata_storage_path","N/A"),
"sharepoint_url":properties.metadata.get("sharepoint_url","N/A")
}
blob_info_list.append(blob_info)
return blob_info_list
blob_info_list = get_blob_info_list()
こんな感じで表示される
(metadataは設定していないのでN/Aとなっている)

ファイルを表形式で表示
先ほど評価画面の一覧表示でも使用したDataFrameを使用して格納されたファイルを確認する。
if blob_info_list:
#DataFrameに変換
df = pd.DataFrame(blob_info_list)
#DataFrameを表示させる
st.dataframe(df, use_container_width=True)
格納ファイルを削除する
ファイルを画面上で削除できるように処理を追加
# 削除機能の実装
st.subheader("ファイル削除")
delete_file = st.selectbox("削除するファイルを選択してください",df["ファイル名"].tolist())
削除したいファイルを選択できる。

削除確認ボタンの実装(削除)
@st.dialogで画面上部に削除確認ダイアログを実装(誤操作を防ぐ)
delete_blob()を使用して、選択したファイルをBlob storageから削除
エラーが発生した場合はエラーコードと実行できなかった旨を伝える
if st.button("削除"):
#確認用ダイアログを表示させる
@st.dialog("削除の確認")
def delete_judge():
st.write(f"本当に{delete_file}を削除しますか?")
if st.button("はい"):
try:
#削除したいファイルの情報のみ取得する
blob_client = blob_container_client.get_blob_client(delete_file)
blob_client.delete_blob()
st.write(f"{delete_file}を削除しました")
except Exception as e:
st.write(f"{e}によってファイルを削除できませんでした")
#ダイアログを閉じる
st.rerun()
st.success(f"{delete_file} を削除しました。")
削除の際に本当に削除していいのか確認がでるように

削除確認ボタンの実装(削除取り消し)
削除をやめたい時にいいえを選択すると削除を取り消す。
st.rerun()で、画面全体を更新することで、
削除した場合はリストから該当ファイルが削除された一覧が表示され
取り消した場合はそのまま一覧が表示される
elif st.button("いいえ"):
st.write("ファイル削除を取り消しました。")
#ダイアログを閉じる
st.rerun()
# 確認ダイアログの関数を呼び出す
delete_judge()
else:
st.write("コンテナにファイルが存在しません")
今後実装予定の機能
Web画面上でインデクシングを自動で行うボタンを設定して、好きなタイミングでインデクシングができる機能を実装予定です。(時期は未定)
elif page == "インデクシング":
st.title("実装予定")
まとめ
この記事では、Streamlitを使用して、Azureの各種機能をWeb画面上で実行できる管理者画面を作成してきました。
同じような機能を作る予定の方やStreamlitってどんなことができるのか知りたい方にとって有益な記事となれば幸いです。