前編はこちら
http://qiita.com/kenmaz/items/4b60ea00b159b3e00100
機械学習やディープラーニングについては全く初心者のソフトウェアエンジニアが、畳込みニューラルネットワークを用いて「ももいろクローバーZ」のメンバーの顔識別を行うアプリを作った話の続きです。
deeplearning
前編ではクローラーが集めてきた画像から顔画像を取り出し、学習用データを生成するところまで説明しました。ここからようやく学習に入ります。
機械学習部分のコードは、Tensorflowに付属にしている Deep MNIST for Expertsと、CIFAR-10 Classificationあたりのコードをベースに実装をすすめました。
CSVの生成と読み込み
gen_testdata.py
https://github.com/kenmaz/momo_mind/blob/master/deeplearning/gen_testdata.py
まず訓練データをTensorflowに食わせる部分ですが、MNISTのサンプルコードと同様、CSVを生成し、そいつを読みこませることにしました。前編では学習用のももクロメンバー画像をそれぞれMacのFinder上でフォルダ分けしましたが、そのフォルダ/ファイルの構造を元に、
訓練用画像のファイルパス,メンバー名を0-4に対応させた数値
という形式のCSVを吐く小さいスクリプトを書きました。
ちなみにTensorflowでは訓練データをこんなような protocol bufferでシリアライズして、TFRecordsというファイル形式に書き出すのがオススメらしいです。ちょっと面倒だったので今回は見送りました。
学習データの入力
以下がCSVを読み込み後述のモデルの入力データとなるTensorを構築するスクリプトです。
mcz_input.py
https://github.com/kenmaz/momo_mind/blob/master/deeplearning/mcz_input.py
TensorFlowにはテキストファイルを読み込む tf.TextLineReaderや、読み込んだデータをcsvとしてデコードしてくれるtf.decode_csv関数など、便利なクラスや関数が予め用意されています。こいつらを使って入力データを読み込めば、そのままTensorFlowへの入力データ形式であるtf.Tensorを自動的に構築してくれます。
さらに機械学習のテクニックとして、訓練サンプル画像を左右反転したり、ちょっと回転させたりズームさせたり、コントラスをランダムに変えるなどすることによって、訓練サンプル画像を「水増し」するテクニック(「データ拡張」と呼ぶらしい)がありますが、それらの処理もほとんどTensorFlowが用意してくれています。
ランダムに左右反転させるtf.image.random_flip_up_down(), 明るさをランダムに変えるtf.image.random_brightness()、同じくコントラストを変える tf.image.random_contrastなど。
最初はこれらの関数の存在に気づかず、自分でopenCVを使ってがんばっていたのですが、素直にTensorFlowのものを使ったほうが良さそうですね。
バッチ入力
今回は訓練データとして、各メンバー150枚ずつ、計750枚の顔画像を用意してあります。これらからランダムに120枚の画像を取り出し、上記の通りデータ拡張を行いランダム化させた上で、学習モデルの入力としてまとめてぶち込みます。この作業を1ステップとし、1000ステップ〜30000ステップほどひたすら学習を繰り返します。
学習モデル
今回作ったコードの中でおそらくいちばん重要な、学習/推論のモデルを組み立てるスクリプトです。
mcz_model.py
https://github.com/kenmaz/momo_mind/blob/master/deeplearning/mcz_model.py
モデルの検討その1
まずは以下のような畳み込みニューラルネットワークのモデル定義してみました。
https://github.com/kenmaz/momo_mind/blob/master/deeplearning/mcz_model.py#L6
- 入力 (28x28 3chカラー)
- 畳み込み層1
- プーリング層1
- 畳み込み層2
- プーリング層2
- 全結合層1
- 全結合層2
これはほとんどCIFAR-10のサンプルそのままのやつです。このモデルだと、分類精度だいたい**65~70%**程度しか出ませんでした。
そもそも入力28x28なのはCIFAR-10のサンプルをそのまま持ってきたからですが、28x28といえば、例えばこれ、28x28の画像です。

うーん、誰でしょうね?(僕はわかりますけど)
この荒い画像から特徴を探しださなきゃいけない、ってことで人間がやってもいかにも大変そうです。もっと高解像度にしたい。
モデルの検討その2
ということでもうちょい精度を高めたいなと思い、入力画像の解像度を倍にして、さらに畳み込み&プーリング層をひとつづつ追加しました。
https://github.com/kenmaz/momo_mind/blob/master/deeplearning/mcz_model.py#L53
- 入力 (56x56 3chカラー)
- 畳み込み層1
- プーリング層1
- 畳み込み層2
- プーリング層2
- 畳み込み層3
- プーリング層3
- 全結合層1
- 全結合層2
という畳み込みニューラルネットワークのモデルを定義しました。
すると精度は最終的に**85%**程度まで上昇しました。
56x56の画像といえばこんな感じです。

今度は誰だかわかりましたよね?
このくらいの解像度になってようやくえくぼが認識できます。やっぱりこれくらいはほしいですよね。
さて、じゃあもっと解像度を上げて、層を増やせばもっと精度向上できるんだろうな、と思い、
実はさらに層を増やしたり、入力の解像度を高めたりしたバージョンも作っては見たのですが、なかなかクロスエントロピーが収束せず、うまく行きませんでした。原因はよくわかってません。すぎゃーん氏のブログによると112x112の入力で90-95%まで達成できたとのこと。どこで違いが出たのだろう。。
モデルのグラフ
TensorFlowには学習モデルをグラフで表示してくれる機能が付いているので、雑な説明つきで以下に貼っておきます。
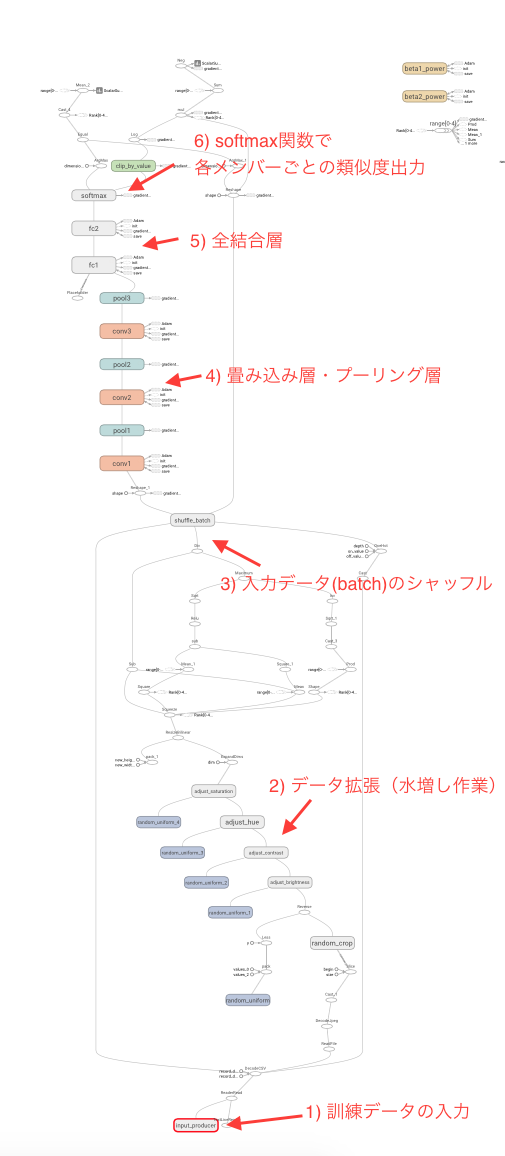
下から上に向けてデータが流れていくイメージです。
中編おわり
そろそろ眠くなってきたので、つづきはまた後日。