この記事はDeNA IPプラットフォーム事業部 Advent Calendar 2017のエントリです(2回目)。
こんにちは。@kenmazです(2回目)。
DeNAでマンガボックスというiOSアプリを開発しています(2回目)。
マンガボックスは最近4周年を迎えました。めでたいですねー(2回目)。
Turi Create とは
ここから本題です。
先日、AppleがTuri Createというライブラリを公開しました。
https://github.com/apple/turicreate

調べてみると2016年にAppleが買収したシアトルのTuriという企業が開発していたソフトウェアがベースになっているようです。
今思い出してみると、WWDC2017のCoreMLセッションにも「turi」出てきているんですよね。
https://developer.apple.com/videos/play/wwdc2017/703/
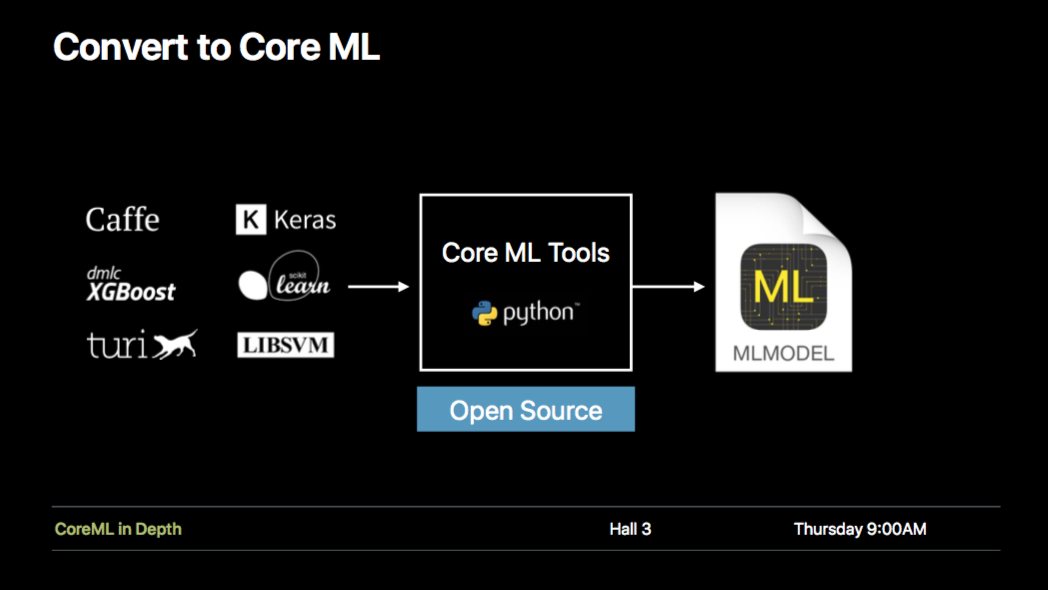
まあ確かにAppleとしても機械学習注力するぜといっても、CoreMLはメインはクライアント側・推論側なので、サーバー側・学習側を他社(Keras/Tensorflow=googleなど)に抑えられっぱなし、ってのもやりづらいでしょうからねぇ。
機械学習ライブラリというと、Tensorflow, Keras, Chainer, scikit-learn などすでに数多く存在しますが、それらとは何が違うのでしょう。サイトの説明によると以下のような特徴があるそうです。
- アルゴリズムではなくタスクにフォーカス
- 組み込みのデータ可視化ツール
- テキスト、画像、音声、ビデオ、センサーデータなどフレキシブルに扱える
- 大規模データに対しても単一のマシン上で動作する
- CoreMLにエクスポートしてiOS/macOS/watchOS/tvOSにデプロイ可能
実際に試してみましょう。
Disclaimer
機械学習自体については専門家ではないのでだいぶゆるい理解のところが多々ありますがご容赦下さい。
タスクベースのAPI
多くの機械学習ライブラリでは、さまざまなアルゴリズムの実装がAPIとして提供されており、それらを組み合わせて目的のタスクを実装する、というスタイルのものが多いかと思います。
たとえば画像のクラス分類タスクをKerasで実装すると以下のようなコードになるかと思います。
dataReader = csv.reader("train.csv", delimiter=' ')
for row in dataReader:
img = Image.open(row[0], 'r')
label = row[1]
...
Y_train = ...
X_train = ...
Y_test = ...
X_test = ...
...
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, Y_train,
batch_size=batch_size,
nb_epoch=nb_epoch,
validation_data=(X_test, Y_test),
shuffle=True,
callbacks=[csv_logger, cp_cb, stopping])
....
上記例では、訓練データのcsvや画像データを読み込んで、パース・整形し、訓練・交差検証用のデータに分けて、計算モデルの構築、損失関数や最適化手法を指定して、といったことをやっています。
一方同じようなことをturicreateを使って書くと、こんな感じになります。
data = tc.image_analysis.load_images('data/%s' % data_type, with_path=True)
data['label'] = data['path'].apply(lambda path: ...)
model = tc.image_classifier.create(data, target='label', max_iterations=100)
短い!
上記コードで実質的にやっていることは、訓練画像データの読み込みと、tc.image_classifier.create()の実行だけです。これだけで画像分類のモデルの訓練と交差検証が完了します。
どういうアルゴリズムを使うか、どういうモデルにするか、ハイパーパラメータはどうするか、と言ったことはturiが全て肩代わりします(もちろん明示的に指定することも可能です)。開発者がやることは、訓練データを用意して、目的のタスクにあったモジュールのメソッド呼び出すだけです。このあたりが最初の特徴として挙げた「アルゴリズムではなくタスクにフォーカス」が意味するところであり、turiの特徴となっている部分です(とはいえ、TensorflowでもEstimatorsのような同様のハイレベルAPIが整備されてきたので、単純にどちらが良いとは言えない部分もありますが)。
ではturicreateが提供する機能を使って簡単なコードを書いてみましょう。
リコメンド
turicreateにはリコメンド機械学習モデルを構築するためのturicreate.recommenderモジュールが提供されています。
これを使ってマンガボックスの閲読ログを訓練データとして与え、あなたにおすすめのマンガをリコメンドするようなシステムについて考えてみます。
まず訓練データセットとして、以下のような形式のcsvファイルを用意します。
head mangabox/manga_fav.csv
uid,manga_id
9c30da6cb90094adf0dd2abd77e008cd,57503
9c30da6cb90094adf0dd2abd77e008cd,57634
2fb5e069653b98bf28bb0c854b352c67,57763
2fb5e069653b98bf28bb0c854b352c67,197
2fb5e069653b98bf28bb0c854b352c67,23829
2fb5e069653b98bf28bb0c854b352c67,41363
2fb5e069653b98bf28bb0c854b352c67,30840
9c30da6cb90094adf0dd2abd77e008cd,55016
9c30da6cb90094adf0dd2abd77e008cd,55016
....
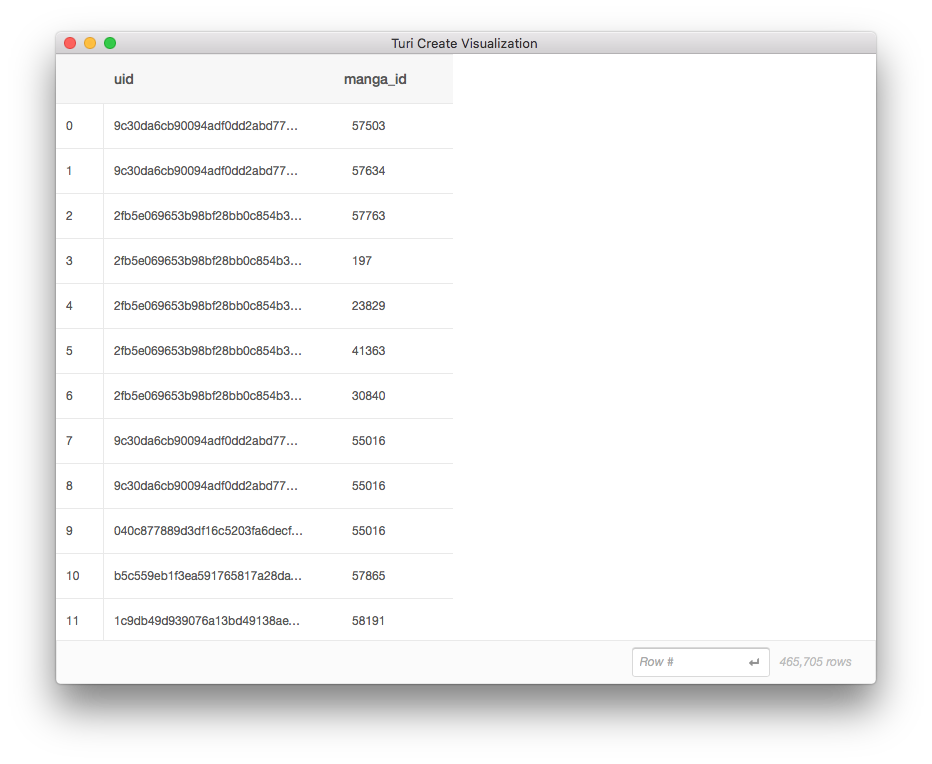
これはマンガボックスのお気に入り作品登録機能のログから抽出したデータです(一部改変しています)。uidがユーザごとの識別子、manga_idがマンガ作品ごとのIDです。各行は、どのユーザが、どの作品をお気に入り登録しているか、ということを表しています。
訓練データセットが用意できたら、次にこのcsvを読み込むコードを書きます。
import turicreate as tc
data = tc.SFrame.read_csv('mangabox/manga_fav.csv')
data.explore()
SFrameはラベル付き二次元の可変配列のデータ構造です。表形式でデータを扱いやすく、SQLのテーブルのように条件でレコードをフィルタ・ソートしたり、他のSFrameとjoinしたりできます(後述)。ちょうどpandasのDataFrameのようなものです。
SFrameには可視化の機能も備わっており、上記のコードを実行すると、以下のようなMacのウインドウが表示され、正しくデータが読み込まれていることを視覚的に確認できます。
続けて、こんなコードを書いて実行します。
train, test = tc.recommender.util.random_split_by_user(data, 'uid', 'manga_id')
model = tc.recommender.create(train, user_id='uid', item_id='manga_id')
1行目ではdataを訓練用のデータと検証用のデータにいい感じに分割しています。
そして重要なのは2行目です。なんとこの一行だけでモデルの訓練と交差検証が完了してしまいます。
たった1行のコードですが、実行してみると内部ではいろいろな処理が行われます。
なんとなくログから内部で行われていることを追ってみましょう。
$ python train.py
Finished parsing file /Users/kentaro.matsumae/Projects/turi/recommender/mangabox/manga_fav.csv
Parsing completed. Parsed 100 lines in 0.228304 secs.
------------------------------------------------------
Inferred types from first 100 line(s) of file as
column_type_hints=[str,int]
If parsing fails due to incorrect types, you can correct
the inferred type list above and pass it to read_csv in
the column_type_hints argument
------------------------------------------------------
Finished parsing file /Users/kentaro.matsumae/Projects/turi/recommender/mangabox/manga_fav.csv
Parsing completed. Parsed 465705 lines in 0.308098 secs.
Materializing SFrame...
Done.
つづく>>
訓練データの読み込みが行われています。
明示的に入力データの型は指定していませんが、最初の100行を読んで、各カラムの型が[str,int]であるとよしなに判断してくれています。
>>つづき
#### train #####
Recsys training: model = item_similarity
Preparing data set.
Data has 465103 observations with 149077 users and 206 items.
Data prepared in: 0.448854s
Training model from provided data.
Gathering per-item and per-user statistics.
+--------------------------------+------------+
| Elapsed Time (Item Statistics) | % Complete |
+--------------------------------+------------+
| 1.637ms | 16.75 |
| 25.511ms | 100 |
+--------------------------------+------------+
Setting up lookup tables.
Processing data in one pass using dense lookup tables.
+-------------------------------------+------------------+-----------------+
| Elapsed Time (Constructing Lookups) | Total % Complete | Items Processed |
+-------------------------------------+------------------+-----------------+
| 28.313ms | 0 | 0 |
| 50.928ms | 100 | 206 |
+-------------------------------------+------------------+-----------------+
Finalizing lookup tables.
Generating candidate set for working with new users.
Finished training in 1.08462s
つづく>>
訓練データの形式をもとに、最適な訓練モデルが自動的に選択されます。turicreateには何種類かのリコメンド用のモデルが予め用意されており、訓練データの形式を元に自動的に選択してくれます。
今回選択されたのはitem_similarityというモデルです。
https://apple.github.io/turicreate/docs/api/generated/turicreate.recommender.item_similarity_recommender.ItemSimilarityRecommender.html#turicreate.recommender.item_similarity_recommender.ItemSimilarityRecommender
1秒程度で訓練が完了しています。
次に訓練したモデルの検証を行います。
res = m.evaluate(test)
pro = res['precision_recall_overall']
pro.print_rows(18,3)
以下実行結果。
WARNING:root:Model trained without a target. Skipping RMSE computation.
+--------+-----------------+-----------------+
| cutoff | precision | recall |
+--------+-----------------+-----------------+
| 1 | 0.108991825613 | 0.0585560745642 |
| 2 | 0.113079019074 | 0.133556074564 |
| 3 | 0.0953678474114 | 0.162257255309 |
| 4 | 0.0776566757493 | 0.173610570477 |
| 5 | 0.0675749318801 | 0.189051079106 |
| 6 | 0.0617620345141 | 0.202970243502 |
| 7 | 0.0603347606072 | 0.237158859911 |
| 8 | 0.0555177111717 | 0.249602093335 |
| 9 | 0.0511656070239 | 0.257435880801 |
| 10 | 0.0479564032698 | 0.269788287704 |
| 11 | 0.0453306911073 | 0.281141602872 |
| 16 | 0.04189373297 | 0.39082868388 |
| 21 | 0.0378876346179 | 0.475512521085 |
| 26 | 0.0333263466778 | 0.515226417542 |
| 31 | 0.0313790981805 | 0.583273863587 |
| 36 | 0.0290644868302 | 0.6269462826 |
| 41 | 0.0286435834386 | 0.691648285109 |
| 46 | 0.0279587726573 | 0.771113922408 |
+--------+-----------------+-----------------+
[18 rows x 3 columns]
Note: Only the head of the SFrame is printed.
You can use print_rows(num_rows=m, num_columns=n) to print more rows and columns.
Materializing X axis SArray...
Materializing Y axis SArray...
Done.
cutoffごとの適合率(precision)、再現率(recall)が表示されます。適合率と再現率は、以下のような感じでよく教科書に出てきます。
TP (True-Positive) = 高評価で推薦、実際に高評価だった (あたり)
FP (False-Positive) = 高評価で推薦、実際は低評価だった (はずれ)
FN (false-Negaitive) = 低評価で推薦、実際は高評価だった (はずれ)
TN (True-Negaitive) = 低評価で推薦、実際に低評価だった (あたり)
適合率(precision) = TP / (TP + FP)
面白くないやつはなるべく推薦しない確率
面白いやつを取りこぼすことはある
再現率(recall) = TP / (TP + FN)
とりこぼしなく高評価をおすすめできる確率
面白くないやつをおすすめすることはある
cutoffってなんだろう・・?
調べてみたところ、recommend()メソッドに対する引数kそのもののようです。
kは、リコメンド結果としてtop何件までアイテムを提示するかを制御する変数です。あるユーザになんらかのマンガをリコメンドしたときに、例えばk=10ならTOP10件の作品がリコメンドされて、そのユーザが実際にお気に入り登録する可能性のあるマンガが(すべて?)含まれている可能性が、26.9%の確率である、ということのようです。すべて、なのか一部、なのかはよくわからず。要調査です。
とりあえずデータセットやリコメンドのロジックを変更したときは、この値を見て性能が向上したかどうかを確認していくと良さそうです。
推論させてみる
まあ、ともかく実際にリコメンドさせてみましょう。
以下のようなコードを実行します。
例として、「骨が腐るまで」「皆様の玩具です」「屍領域」をお気に入り登録しているユーザに対してリコメンドしてみます。
import turicreate as tc
m = tc.load_model('recommend.model')
manga = tc.SFrame.read_csv('mangabox/manga_id-title.csv')
print("==== input ====")
data = tc.SFrame({
'uid': ["xxxxxx","xxxxxx","xxxxxx"],
'manga_id': [56124,58191,40184]
})
print(data.join(manga, on='manga_id'))
print("==== recommend ====")
res = m.recommend(['xxxxxx'], new_observation_data=data)
print(res.join(manga, on='manga_id').sort('rank'))
ところでここでさらっとjoinとかsortが出てきましたが、これがSFrameの強力なところです(pandasのDataFrameと同様?)。
リコメンド結果をIDではなく作品名で表示したかったので、IDとタイトルをcsvにエクスポートしたものをSFrameとして取り込み、リコメンド結果のSFrameとjoin/sortしています。まるでSQLを扱うかのように、メモリ上のデータを扱えるので非常に楽ですね。
さて結果です。
==== input ====
+----------+--------+----------------+
| manga_id | uid | title |
+----------+--------+----------------+
| 40184 | xxxxxx | 骨が腐るまで |
| 56124 | xxxxxx | 皆様の玩具です |
| 58191 | xxxxxx | 屍領域 |
+----------+--------+----------------+
[3 rows x 3 columns]
==== recommend ====
+--------+----------+----------------+------+-----------------------------------+
| uid | manga_id | score | rank | title |
+--------+----------+----------------+------+-----------------------------------+
| xxxxxx | 54275 | 0.229193170865 | 1 | 異常者の愛 |
| xxxxxx | 58443 | 0.167914152145 | 2 | 人間工場 |
| xxxxxx | 61167 | 0.148039698601 | 3 | 蝕人孤蟲 |
| xxxxxx | 59579 | 0.142513533433 | 4 | 元風俗嬢が金持ち妻になりました... |
| xxxxxx | 57822 | 0.141827464104 | 5 | 少女ペット2nd season |
| xxxxxx | 58229 | 0.127714614073 | 6 | 死因とあそぼ! |
| xxxxxx | 48298 | 0.126432379087 | 7 | 少女ペット |
| xxxxxx | 203 | 0.117491046588 | 8 | 恋と嘘 |
| xxxxxx | 58232 | 0.114524205526 | 9 | LIFE GAME |
| xxxxxx | 30840 | 0.113866349061 | 10 | リアルアカウント |
+--------+----------+----------------+------+-----------------------------------+
[10 rows x 5 columns]
同じホーラー・バイオレンス系の「異常者の愛」「人間工場」「蝕人孤蟲」あたりがリコメンドされました。なんとなく良さそうな気がします
今度は作品間の類似度を確認してみましょう。id= 47415「りぶねす」という作品の類似作品TOP10を出してみます。
sim_src = tc.SFrame({'manga_id': [47415]})
print(sim_src.join(manga, on='manga_id'))
print(m.get_similar_items(sim_src['manga_id']).join(manga, on={'similar':'manga_id'}).sort('score', ascending = False))
結果です。
==== similar ====
+----------+----------+
| manga_id | title |
+----------+----------+
| 47415 | りぶねす |
+----------+----------+
[1 rows x 2 columns]
+----------+---------+-----------------+------+--------------------------------------------------------+
| manga_id | similar | score | rank | title |
+----------+---------+-----------------+------+--------------------------------------------------------+
| 47415 | 24268 | 0.0524193644524 | 1 | もももも百田さん |
| 47415 | 47383 | 0.0364963412285 | 2 | 育てち魔おう! |
| 47415 | 51749 | 0.0282486081123 | 3 | 私がモテないのはどう考えてもお前らが悪い!... |
| 47415 | 54784 | 0.0258620977402 | 4 | 地獄恋 LOVE in the HELL |
| 47415 | 35348 | 0.0233722925186 | 5 | 男子バド部に女子が紛れてる -シークレットバドミント... |
| 47415 | 319 | 0.0214477181435 | 6 | 女なのでしょうがない |
| 47415 | 51703 | 0.0211764574051 | 7 | 漂流ネットカフェ |
| 47415 | 335 | 0.0202702879906 | 8 | 虹浜ラブストーリー |
| 47415 | 46651 | 0.0176870822906 | 9 | 穴殺人 復刻掲載 |
| 47415 | 58762 | 0.0169491767883 | 10 | 君といる夏ーハツコイー... |
+----------+---------+-----------------+------+--------------------------------------------------------+
[10 rows x 5 columns]
ほんわか・ゆるい系の作品が並んでます。
今度はid=54275「異常者の愛」で試してみます。
==== similar ====
+----------+------------+
| manga_id | title |
+----------+------------+
| 54275 | 異常者の愛 |
+----------+------------+
[1 rows x 2 columns]
+----------+---------+----------------+------+-----------------------------------+
| manga_id | similar | score | rank | title |
+----------+---------+----------------+------+-----------------------------------+
| 54275 | 56124 | 0.294033110142 | 1 | 皆様の玩具です |
| 54275 | 58191 | 0.203336715698 | 2 | 屍領域 |
| 54275 | 40184 | 0.190209686756 | 3 | 骨が腐るまで |
| 54275 | 58443 | 0.181938648224 | 4 | 人間工場 |
| 54275 | 61167 | 0.161069750786 | 5 | 蝕人孤蟲 |
| 54275 | 57822 | 0.158378362656 | 6 | 少女ペット2nd season |
| 54275 | 59579 | 0.158158302307 | 7 | 元風俗嬢が金持ち妻になりました... |
| 54275 | 48298 | 0.136510550976 | 8 | 少女ペット |
| 54275 | 58229 | 0.11179536581 | 9 | 死因とあそぼ! |
| 54275 | 47418 | 0.110164403915 | 10 | イジメの時間 |
+----------+---------+----------------+------+-----------------------------------+
期待通り、バイオレンス・ホラー系が上位に来ました。
とまあ、精度についてはあれでしたが、とりあえず最小のコードでなんとなく、っぽいリコメンドシステムを作ることができました。
画像分類
機械学習といえば、CNNで画像分類がメジャーな問題なので、turiでも実装してみましょう。
ちょうどたまたま過去に「ももクロ顔画像分類器」なるものをKerasやTensorflowで作ったことがあったので、そのデータを流用して遊んでみようと思います。
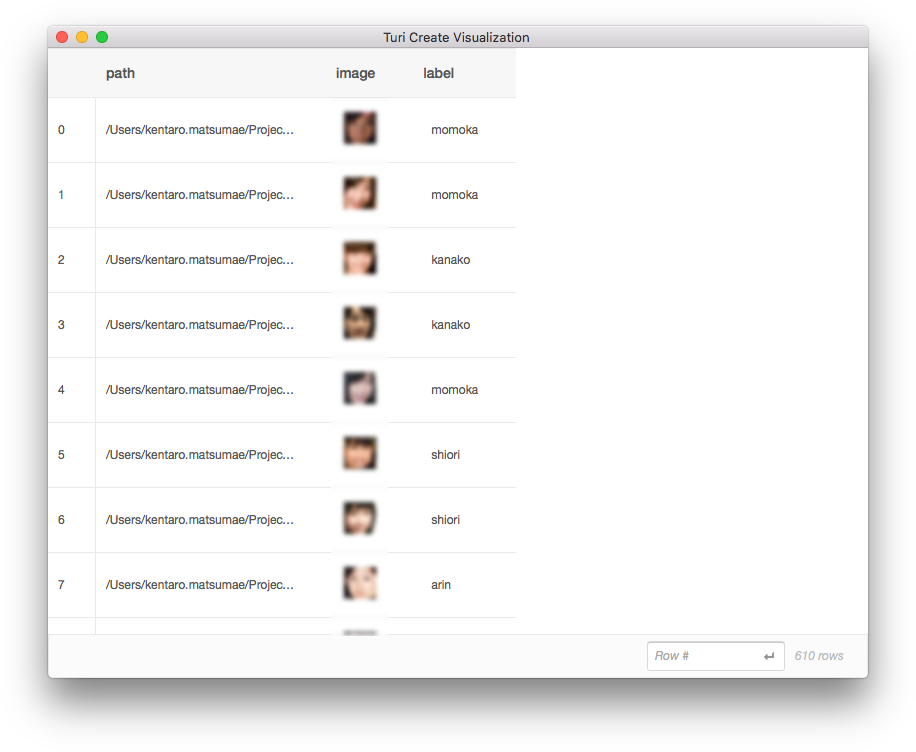
まずは訓練データを準備します。訓練用の画像は112x112のJPG画像で、以下のようなフォルダに分けて保存されています。
data/
train/
reni/
xxxx.jpg
xxxx.jpg
...
kanako/
xxxx.jpg
xxxx.jpg
...
shiori/
xxxx.jpg
xxxx.jpg
...
arin/
xxxx.jpg
xxxx.jpg
...
momoka/
xxxx.jpg
xxxx.jpg
...
まずはこれらの画像と正解ラベルをまとめてSFrameとしてまとめ、データセットとして準備しておきます。
import turicreate as tc
def path2label(path):
if "reni" in path:
return "reni"
elif "kanako" in path:
return "kanako"
elif "shiori" in path:
return "shiori"
elif "arin" in path:
return "arin"
elif "momoka" in path:
return "momoka"
else:
return "unknown"
def gen_sframe(data_type):
data = tc.image_analysis.load_images('data/%s' % data_type, with_path=True)
data['label'] = data['path'].apply(path2label)
data.save('data/%s.sframe' % data_type)
data.explore()
gen_sframe('data/train')
これで'data/train.sframe'フォルダを読み込めば、いつでもデータセットがSFrameとして取り出せるようになります。
save後にdata.explore()をしているので、以下のように正しくデータがSFrameにまとめらていることを確認できます。
次に画像分類タスクの中心処理を書きます。
import turicreate as tc
data = tc.SFrame('data/train.sframe')
train_data, test_data = data.random_split(0.8)
model = tc.image_classifier.create(train_data, target='label', max_iterations=100)
metrics = model.evaluate(test_data)
print(metrics['accuracy'])
model.save('data/mcz.model')
これまた短いコードです。リコメンドのときと同じように、createメソッドでモデルの訓練を行い、evaluateメソッドで精度の検証を行っています。最後に訓練結果をmcz.modelというファイルに保存しています。
実行してみましょう。
$ python train.py
Downloading https://docs-assets.developer.apple.com/turicreate/models/resnet-50-symbol.json
Download completed: /var/tmp/model_cache/resnet-50-symbol.json
Downloading https://docs-assets.developer.apple.com/turicreate/models/resnet-50-0000.params
Download completed: /var/tmp/model_cache/resnet-50-0000.params
[00:47:19] src/nnvm/legacy_json_util.cc:190: Loading symbol saved by previous version v0.8.0. Attempting to upgrade...
[00:47:19] src/nnvm/legacy_json_util.cc:198: Symbol successfully upgraded!
Resizing images...
Performing feature extraction on resized images...
Completed 512/592
Completed 592/592
PROGRESS: Creating a validation set from 5 percent of training data. This may take a while.
You can set ``validation_set=None`` to disable validation tracking.
WARNING: The number of feature dimensions in this problem is very large in comparison with the number of examples. Unless an appropriate regularization value is set, this model may not provide accurate predictions for a validation/test set.
WARNING: Detected extremely low variance for feature(s) '__image_features__' because all entries are nearly the same.
Proceeding with model training using all features. If the model does not provide results of adequate quality, exclude the above mentioned feature(s) from the input dataset.
Logistic regression:
--------------------------------------------------------
Number of examples : 568
Number of classes : 5
Number of feature columns : 1
Number of unpacked features : 2048
Number of coefficients : 8196
Starting L-BFGS
--------------------------------------------------------
+-----------+----------+-----------+--------------+-------------------+---------------------+
| Iteration | Passes | Step size | Elapsed Time | Training-accuracy | Validation-accuracy |
+-----------+----------+-----------+--------------+-------------------+---------------------+
| 1 | 6 | 0.000101 | 1.156186 | 0.279930 | 0.291667 |
| 2 | 8 | 1.000000 | 1.251055 | 0.473592 | 0.416667 |
| 3 | 9 | 1.000000 | 1.308617 | 0.547535 | 0.416667 |
| 4 | 10 | 1.000000 | 1.374899 | 0.570423 | 0.375000 |
| 5 | 11 | 1.000000 | 1.438285 | 0.637324 | 0.458333 |
| 6 | 12 | 1.000000 | 1.503571 | 0.653169 | 0.541667 |
| 11 | 17 | 1.000000 | 1.792186 | 0.755282 | 0.625000 |
| 25 | 31 | 1.000000 | 2.576023 | 0.950704 | 0.708333 |
| 50 | 63 | 1.000000 | 4.211884 | 1.000000 | 0.666667 |
| 51 | 64 | 1.000000 | 4.271336 | 1.000000 | 0.625000 |
| 75 | 101 | 1.000000 | 5.957015 | 1.000000 | 0.708333 |
| 100 | 139 | 0.250000 | 7.682708 | 1.000000 | 0.750000 |
+-----------+----------+-----------+--------------+-------------------+---------------------+
TERMINATED: Iteration limit reached.
This model may not be optimal. To improve it, consider increasing `max_iterations`.
0.683544303797
いきなり気になるログが出ています。
Downloading https://docs-assets.developer.apple.com/turicreate/models/resnet-50-symbol.json
turiの画像分類タスクではいわゆる転移学習が行われており、デフォルトではResNet50の学習済みモデルを使い、最終層だけを差し替えて学習を行っているようです。
今回はCPUマシンで、訓練画像750枚、100イテレーションで、数10秒で学習が完了してるので、おそらく最終層の重みのみ更新されているのでしょう。
また以下のような警告が出ています。
WARNING: The number of feature dimensions in this problem is very large in comparison with the number of examples. Unless an appropriate regularization value is set, this model may not provide accurate predictions for a validation/test set.
WARNING: Detected extremely low variance for feature(s) '__image_features__' because all entries are nearly the same.
Proceeding with model training using all features. If the model does not provide results of adequate quality, exclude the above mentioned feature(s) from the input dataset.
特徴の次元がとても大きい割には訓練画像少なすぎ!と怒られています。また、どの画像もほとんど同じなんでバリアンス低すぎ、精度でない場合はデータセットから似すぎてるやつ除外せよ、的な感じでアドバイスしてくれています。親切ですね(今回は精度はもとめてないので無視)。
100イテレーションで、訓練精度100%、交差検証の制度75%、テスト用のデータだと68%、ってことで、まあ精度は高くはないですが、分類自体はなんとなくできているようです。
CoreMLへのエクスポート
turiで学習したモデルは以下のコードでmlmodelに変換できます。
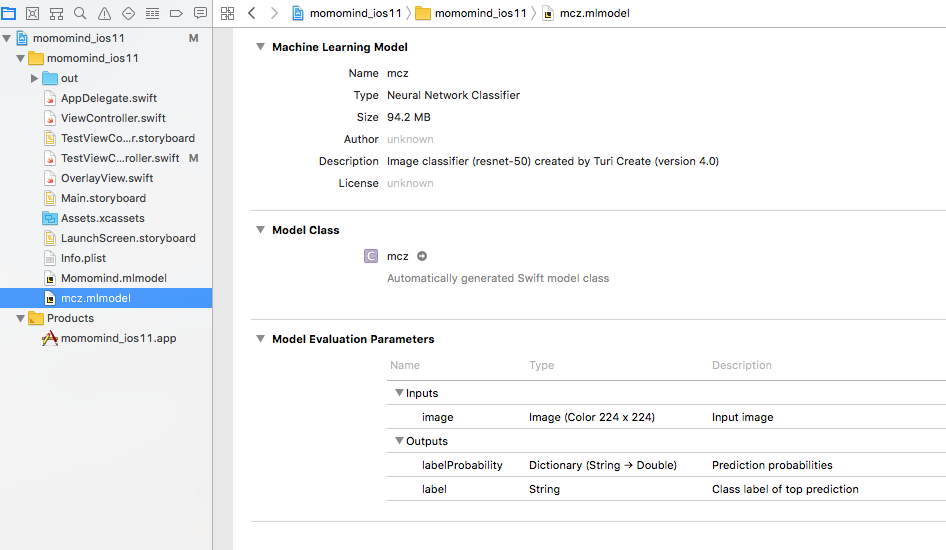
model.export_coreml('MCZClassifier.mlmodel')
以前作った「CoreMLによるももクロ顔画像識別iOSアプリ」のmlmodelを、turiで生成したものに差し替えてみます。mcz.mlmodelをXcodeにドラッグアンドドロップするだけです。
(命名が適当ですが)mczという名前のクラスが使えるようになりました。
あとはこいつをSwiftのコードから読んでCVImageオブジェクトを投げ込んでやればOKです。
実行結果は以下の通り。
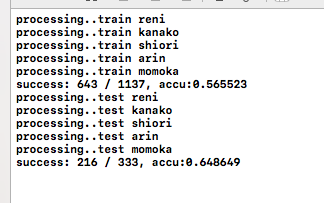
動いてるね。次行ってみよう。
GPUマシンでの学習
大量の画像データを使って学習させたい場合は、やはりGPUマシンで学習させたくなってきます。もちろんturiもGPUマシン上で学習させることができます。
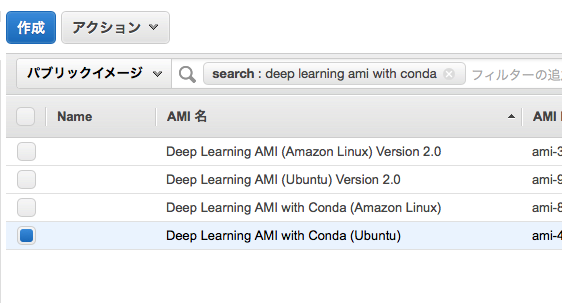
今回はAWSのp2.xlargeのGPUマシンを使います。AMIは「Amazon Deep Learing AMIs」を使います。GPUドライバやPythonの環境など予めセットアップされているので、楽です。
またお金もケチりたいのでスポットインスタンスで頑張ります。
Public AMIを検索して Deep Learning AMI with Conda (Ubuntu) を選択して・・・
スポットリクエストする。
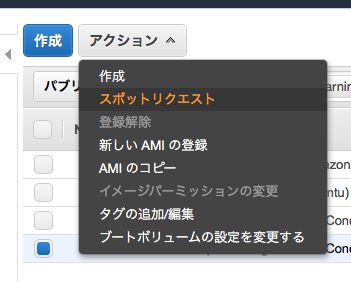
p2.xlargeがオススメ。$0.5~0.9/h くらいです。
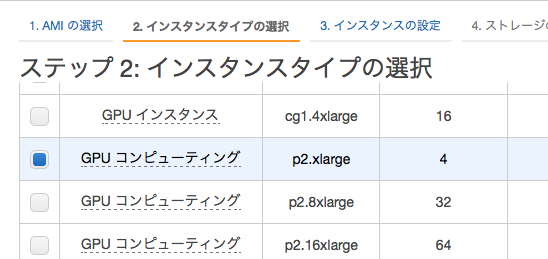
ステータスがReadyになったら・・
おもむろに ssh します。
$ ssh -A ubuntu@ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com
...
=============================================================================
__| __|_ )
_| ( / Deep Learning AMI (Ubuntu)
___|\___|___|
=============================================================================
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-1039-aws x86_64v)
Please use one of the following commands to start the required environment with the framework of your choice:
for MXNet(+Keras1) with Python3 (CUDA 9) _____________________ source activate mxnet_p36
for MXNet(+Keras1) with Python2 (CUDA 9) _____________________ source activate mxnet_p27
for TensorFlow(+Keras2) with Python3 (CUDA 8) ________________ source activate tensorflow_p36
for TensorFlow(+Keras2) with Python2 (CUDA 8) ________________ source activate tensorflow_p27
for Theano(+Keras2) with Python3 (CUDA 9) ____________________ source activate theano_p36
for Theano(+Keras2) with Python2 (CUDA 9) ____________________ source activate theano_p27
for PyTorch with Python3 (CUDA 8) ____________________________ source activate pytorch_p36
for PyTorch with Python2 (CUDA 8) ____________________________ source activate pytorch_p27
for CNTK(+Keras2) with Python3 (CUDA 8) ______________________ source activate cntk_p36
for CNTK(+Keras2) with Python2 (CUDA 8) ______________________ source activate cntk_p27
for Caffe2 with Python2 (CUDA 9) _____________________________ source activate caffe2_p27
for base Python2 (CUDA 9) ____________________________________ source activate python2
for base Python3 (CUDA 9) ____________________________________ source activate python3
Python2 + CUDA9 の環境を選んだら、あとはpip install turicreateしたり訓練画像をs3からcopyするなどして・・・
$ source activate python2
$ python --version
Python 2.7.14 :: Anaconda, Inc.
$ git clone ...
$ pip install turicreate
$ aws s3 cp s3://path/to/imgs .
いざ訓練実行!
$ python train.py
[15:44:37] src/nnvm/legacy_json_util.cc:190: Loading symbol saved by previous version v0.8.0. Attempting to upgrade...
[15:44:37] src/nnvm/legacy_json_util.cc:198: Symbol successfully upgraded!
Resizing images...
[15:44:47] src/operator/././cudnn_algoreg-inl.h:112: Running performance tests to find the best convolution algorithm, this can take a while... (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
Performing feature extraction on resized images...
Completed 512/593
Completed 593/593
PROGRESS: Creating a validation set from 5 percent of training data. This may take a while.
You can set ``validation_set=None`` to disable validation tracking.
WARNING: The number of feature dimensions in this problem is very large in comparison with the number of examples. Unless an appropriate regularization value is set, this model may not provide accurate predictions for a validation/test set.
WARNING: Detected extremely low variance for feature(s) '__image_features__' because all entries are nearly the same.
Proceeding with model training using all features. If the model does not provide results of adequate quality, exclude the above mentioned feature(s) from the input dataset.
Logistic regression:
--------------------------------------------------------
Number of examples : 562
Number of classes : 5
Number of feature columns : 1
Number of unpacked features : 2048
Number of coefficients : 8196
Starting L-BFGS
--------------------------------------------------------
+-----------+----------+-----------+--------------+-------------------+---------------------+
| Iteration | Passes | Step size | Elapsed Time | Training-accuracy | Validation-accuracy |
+-----------+----------+-----------+--------------+-------------------+---------------------+
| 1 | 6 | 0.000041 | 1.205040 | 0.213523 | 0.032258 |
| 2 | 9 | 5.000000 | 1.336359 | 0.485765 | 0.354839 |
| 3 | 10 | 5.000000 | 1.400936 | 0.501779 | 0.387097 |
| 4 | 12 | 1.000000 | 1.499793 | 0.615658 | 0.451613 |
| 5 | 13 | 1.000000 | 1.563241 | 0.628114 | 0.451613 |
| 6 | 14 | 1.000000 | 1.632276 | 0.672598 | 0.548387 |
| 11 | 19 | 1.000000 | 1.954712 | 0.756228 | 0.516129 |
| 25 | 34 | 1.000000 | 2.885302 | 0.960854 | 0.709677 |
| 50 | 64 | 0.250000 | 4.638458 | 1.000000 | 0.774194 |
| 51 | 65 | 0.250000 | 4.703591 | 1.000000 | 0.774194 |
| 75 | 98 | 1.000000 | 6.535380 | 1.000000 | 0.741935 |
| 100 | 131 | 1.000000 | 8.423931 | 1.000000 | 0.709677 |
+-----------+----------+-----------+--------------+-------------------+---------------------+
TERMINATED: Iteration limit reached.
This model may not be optimal. To improve it, consider increasing `max_iterations`.
accuracy
0.707006369427
やったねお父さん
その他のタスク
turiは他にも以下のようなタスクベースのモジュールを提供しています。
- 類似画像検出
- 画像物体認識
- Activity Classifier(センサデータから活動状況推論するやつ)
- テキスト分類
また古典的な機械学習アルゴリズムのモジュールも提供してるらしいっす。
- クラス分類
- クラスタリング(kmeans)
- グラフ分析
- 最近傍法
- 回帰
- テキスト分析(トピックモデル)
参考文献
実践機械学習システム
https://www.oreilly.co.jp/books/9784873116983/
推薦システムのアルゴリズム
http://www.kamishima.net/archive/recsysdoc.pdf
コード
今回遊んだコードは以下においてあります。訓練データは各自用意してください。
https://github.com/kenmaz/turi-create-sandbox
まとめ
まだturi自体よくわからない部分が多々あり、そもそも機械学習全般について圧倒的知識不足の私ですが、こんな私でもturiの提供するモジュールをちょこちょこっといじれば、なんとなくそれっぽい機械学習モデルが動いたりするturiはなかなか今後に期待できそうです。今後もキャッチアップしていきたいと思います。
(アドベントカレンダー最終日)
IPPFのみなさんお疲れ様でしたー!