概要
ネットワークの不正検知モデルでSoTA(多分今も?)のKitusneについて講義を受ける機会があったので、いいタイミングだと思い少しまとめてみることにしました。
Kitsune とは
Kitsune は、原論文 Kitsune: An Ensemble of Autoencoders for Online
Network Intrusion Detectionで2018年に発表された、ネットワーク侵入検知システム(Network Intrusion Detection System: NIDS)で(たぶん2019年12月現在も)SoTAのスコアを叩き出している異常検知の機械学習モデルになります。ネットワーク侵入検知とは、通常のネットワークトラフィックと、外部から侵入などを受けた異常トラフィックを区別し、検知することです。
コードもOSSとしてここにあります。
論文のアブストラクトやイントロのところにも書いてある通り、既存のNNを用いた異常検知モデルが非常に重く、ネットワーク検知のニーズ(ルーターとかにモデルをデプロイしたいため、軽いモデルが必要)に合わなかったり、教師あり学習のモデルが使われていることが多く、ネットワークエンジニアがラベリングをする手間だったりかかる費用が膨大になる、といったところを解決するのが、Kitsuneであるということです。
基本的なビルディングブロック
 入力ベクトルに対して**Auto Encoder** (AE)を用いて、出てきたものと入力の誤差を**MSE**でとって、それの**誤差と閾値によって異常を検知する**、といういたってスタンダードなアイディアにはなっていますが、先ほど出てきたネットワーク検知の**ニーズにより合った工夫**がいくつもなされているので紹介します。
入力ベクトルに対して**Auto Encoder** (AE)を用いて、出てきたものと入力の誤差を**MSE**でとって、それの**誤差と閾値によって異常を検知する**、といういたってスタンダードなアイディアにはなっていますが、先ほど出てきたネットワーク検知の**ニーズにより合った工夫**がいくつもなされているので紹介します。
入力の工夫
入力に入るべきものはネットワークのトラフィックデータです。ネットワーク検知に使われるマシンのスペックは、マシンの導入量が膨大であるなどの理由から安価な物で補えるだけのモデルの複雑さであればより好ましいです。したがって、メモリなども限られているので入ってくる全てのデータをログとして記憶するのではなく、データの統計量をトラッキングします。各統計量の詳しいところは原論文をお読みください。
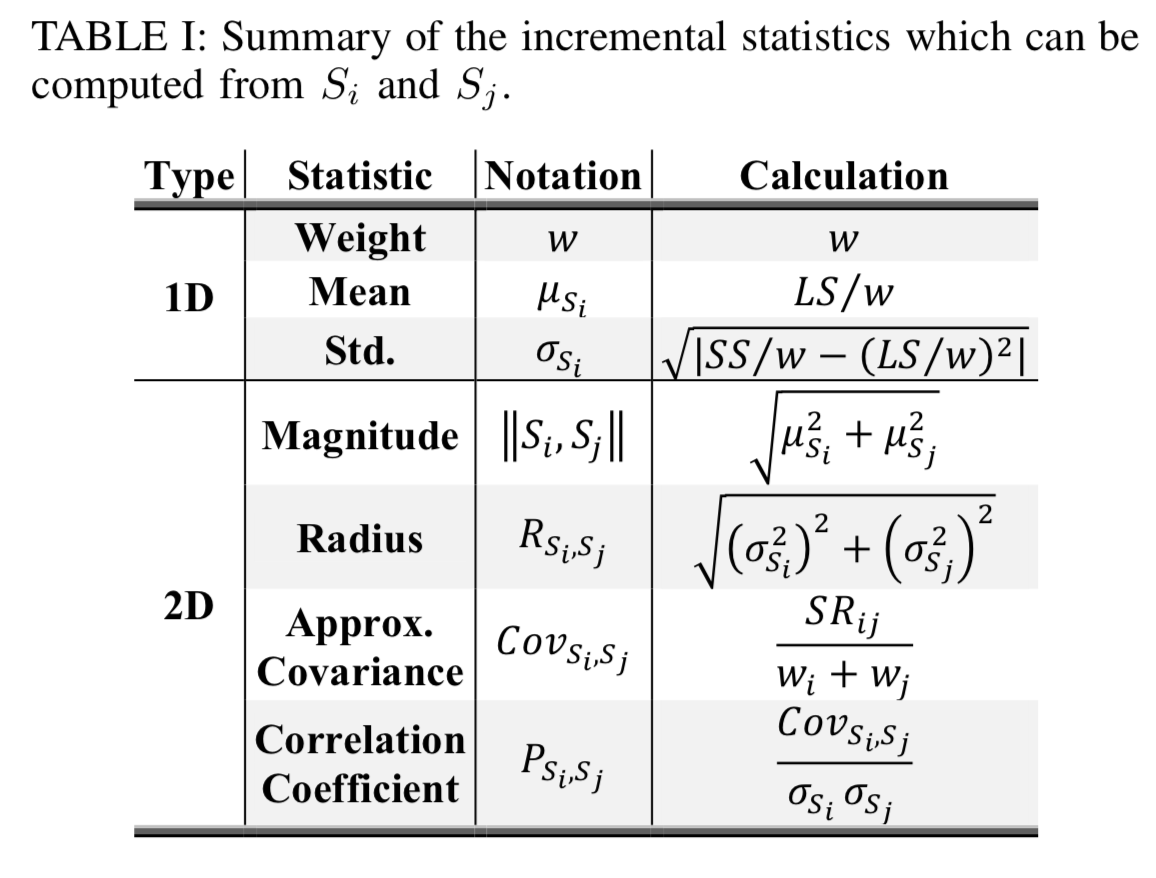
また、時間軸には
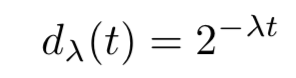
のように表現される簡単な時間で衰退するようなものを掛け合わせて、ある時間より古いものは入力データから完全に落としています。統計量は各時間ごとに更新され、古いものは消えるのでメモリにも優しいです。
AEの工夫
入力ベクトルを大きなAEに入れ込むのではなく、入力ベクトルを類似度計算し、その類似度が高いものから順に樹形図でクラスタリングします。
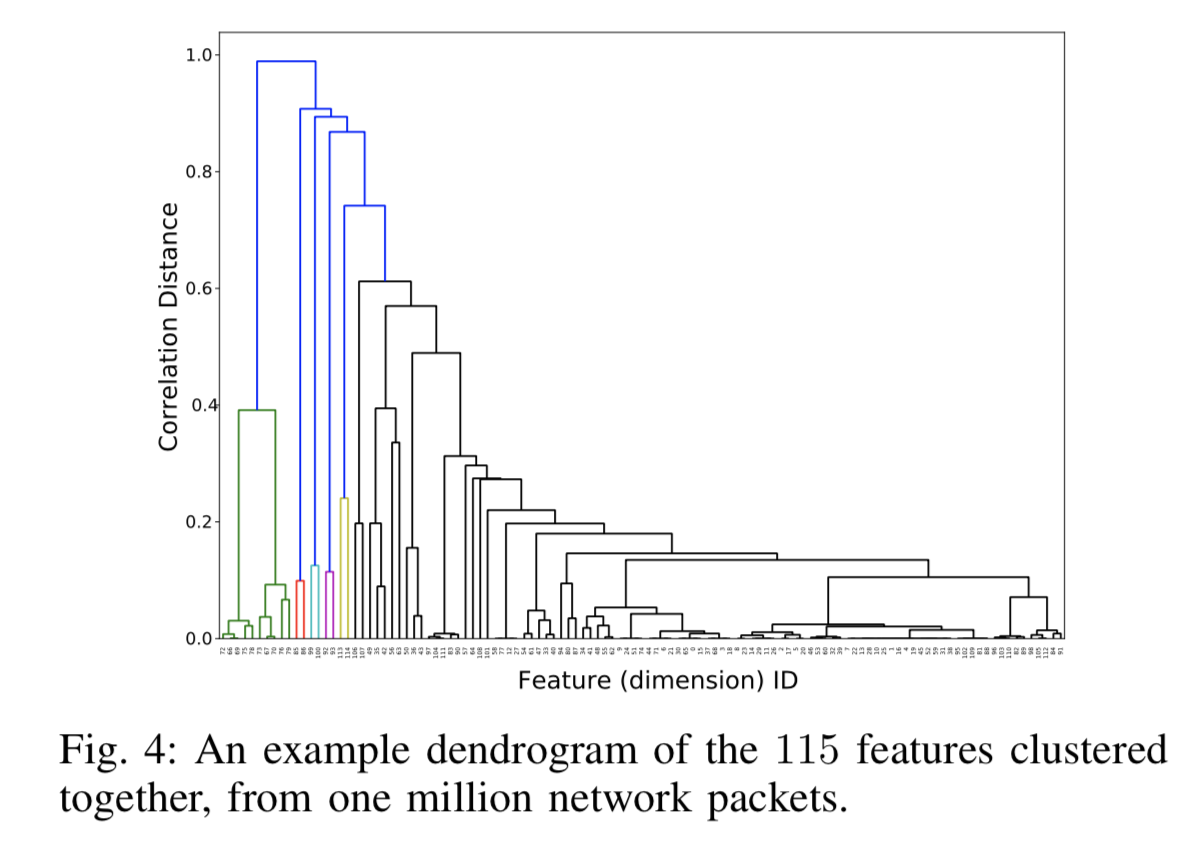
そのクラスタリングされたグループをそれぞれ別のAEに入れ、全体ではなくそのグループたちをAEで自己生成させます。こうする理由はパラメータ削減です。このように1つの大きなAEではなく複数の小さなAEを用いることから、AEアンサンブルというような題名がついているわけです。
アウトプット層の工夫
先述のいくつかのAEで作られた類似度の高いグループの自己生成されたものは、そのあとに大きなAEに入力され、その結果が異常スコアに使われることになっています。異常スコアは閾値によって決定され、指標としては単純に元の入力とのMSEが使われています。
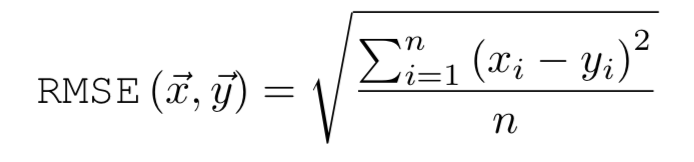
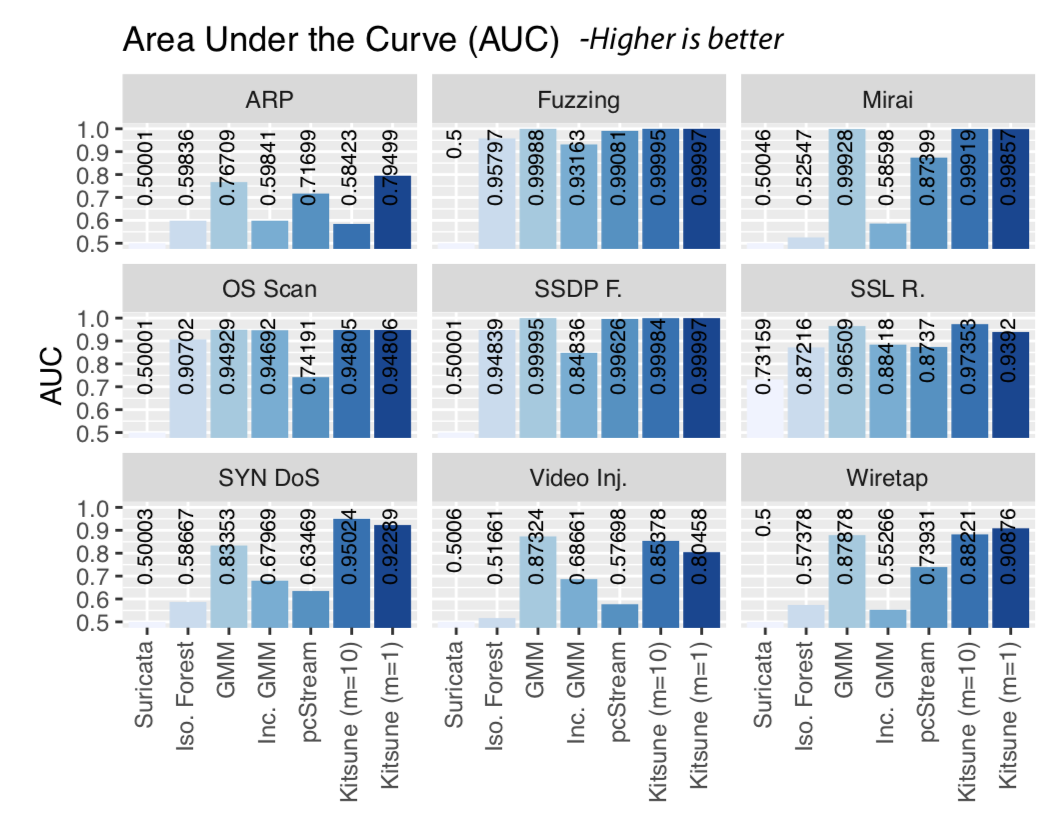
以上のような工夫を用いて、軽量でも以下のような素晴らしい結果を出しており、注目されているようです。
終わりに
めちゃくちゃ真新しいことが組まれているわけではないですが、マシンスペックのニーズに応じた制約の中で最大のアキュラシーを出すような工夫が詰まっている素晴らしいモデルだと感じました。興味のある人は原論文およびOSSになっているコードをぜひ見てみてください。今回はこの辺で。
おわり。