概要
タイトルのままですが、とりあえず軽く触ってどんなものなのか少しだけ勉強したのでまとめておきます。
余裕のある人は、
こちらをじっくりと読んでみてください。
おすすめなのは、この記事をまず読んでから、上をしっかりと読むことです💪
機能
主に2つあります。
- DB (SQL)をコラボレーターの間で使える(詳細は下)
- ML(どんなモデルが使えるかまだ未確認)を、コラボレーターの間で使える(詳細は下)
コラボレーターの設定とデータのアップロード
コラボレーターは、AWSアカウントのIDを打ち込み、名前を設定するだけで簡単に行えました。
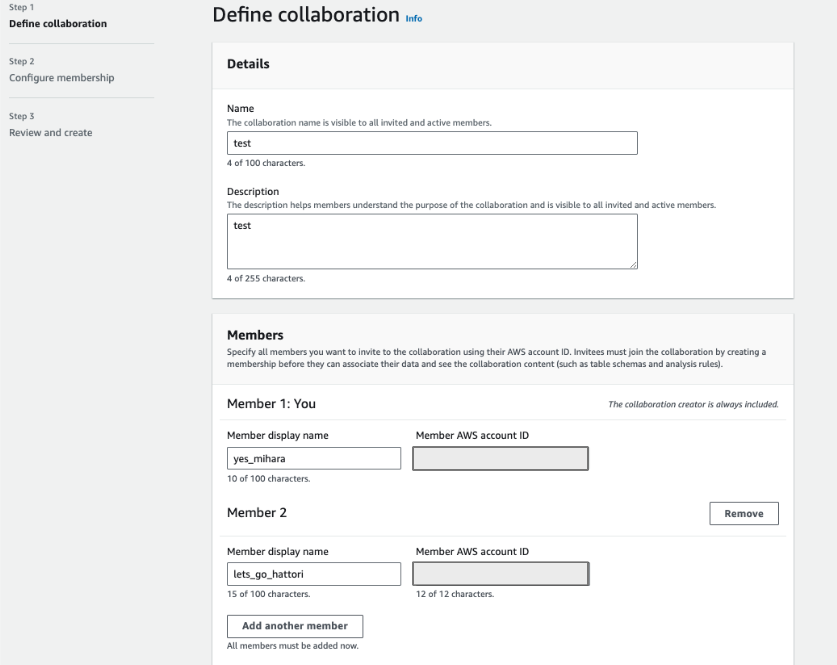
ここでは、コラボレーターを1人追加しています。
DB(SQL)について
コラボレーターの間で、
- どのようなデータ構造か(カラムとか、ジョインカラムとか設定)
- 誰がクエリを打てるか
- どんなクエリを打てるか
- 結果は誰が見えるか
- クエリにかかったお金は誰が払うか
- データの暗号化を詳細設定(暗号化を高度にすると、使用できるクエリに制限がかかる)
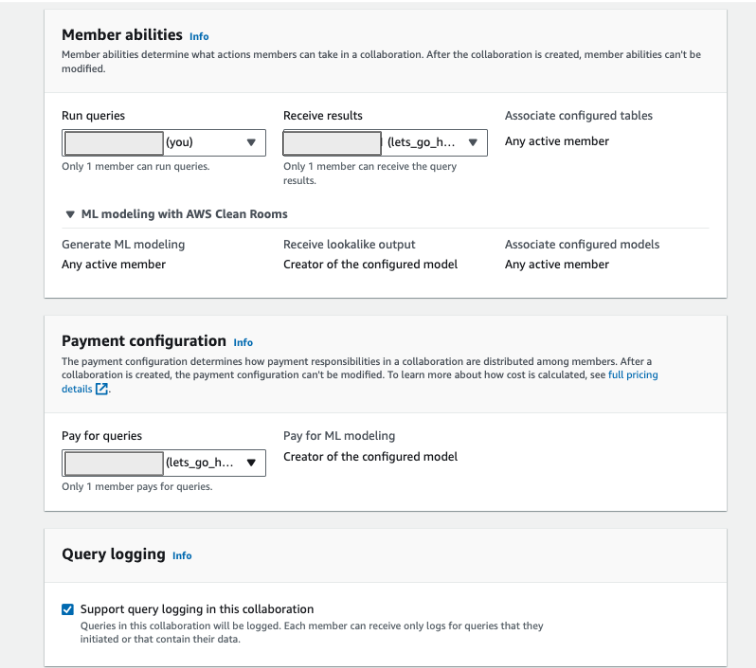
などが設定できます。
データの暗号化について
今までで触ったことはないのですが、C3Rと呼ばれるクライアント側のツールをダウンロードして、
CLIで自分用の鍵を生成し、データを暗号化してアップロードできるようです。
今度試そうと思います。
その際に、いくつかデータベースに格納するデータについて暗号の設定ができます。
- 全てのカラムに対して暗号化を強制するか(暗号化したカラムについては、原則Whereは使えない)
- 決定的暗号を使うか(使うと、頻度攻撃などが可能になりますが、NoにするとそのカラムはJoinカラムには使えなくなります。)
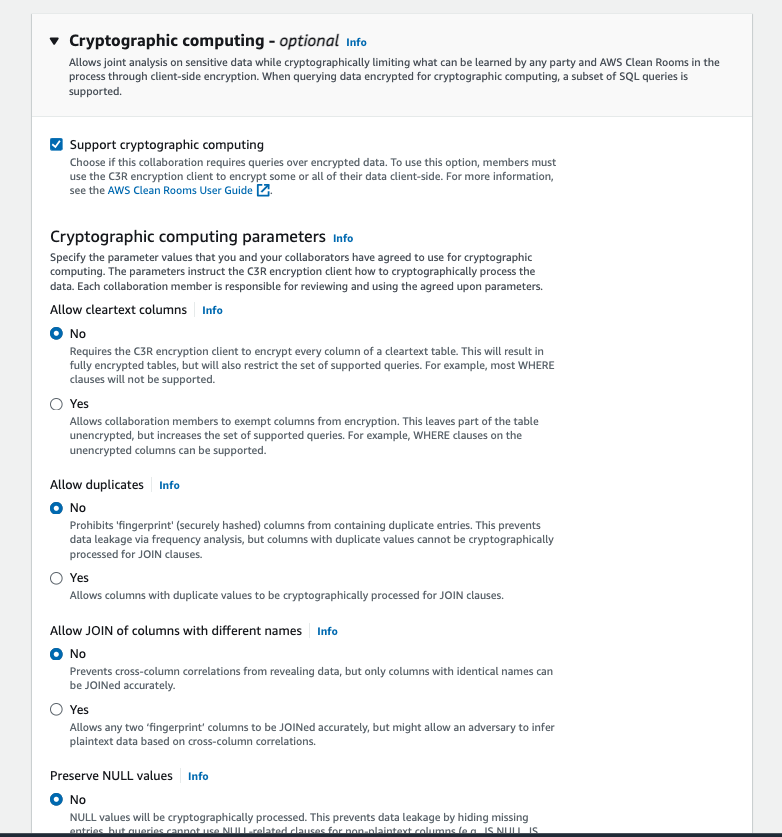
ダッシュボード
SQL
さて、コラボレーションを作成するとダッシュボードに遷移します。
テーブルデータの管理は以下のようなダッシュボードで行います。
だれがどのデータに対してどんなクエリを打てるか、そして結果は誰が見えるか、
それに対して誰がお金を払うか
などを設定し、コラボレーションをスタートします。
セキュアなクエリや、クエリの実行、閲覧などの細かな設定が可能
また、クエリについては差分プライバシーを使い、個人を特定することがないように細かな設定ができるようです。
また、SUMやAVGをクエリできるカラムについて制限したり、その統計を計算する際に最小の数のマッチなどを設定できます。
こうすることで、非常に小さな数のレコードに対して統計値が計算されることを防ぐことができます。
AWS Glueでのデータのカタログ化が必須
AWS Glueというサービスをまだ私は使ったことがないのですが、
自分のアップロードしたデータに対してカタログIDを付与し、コラボレート可能にするようです。
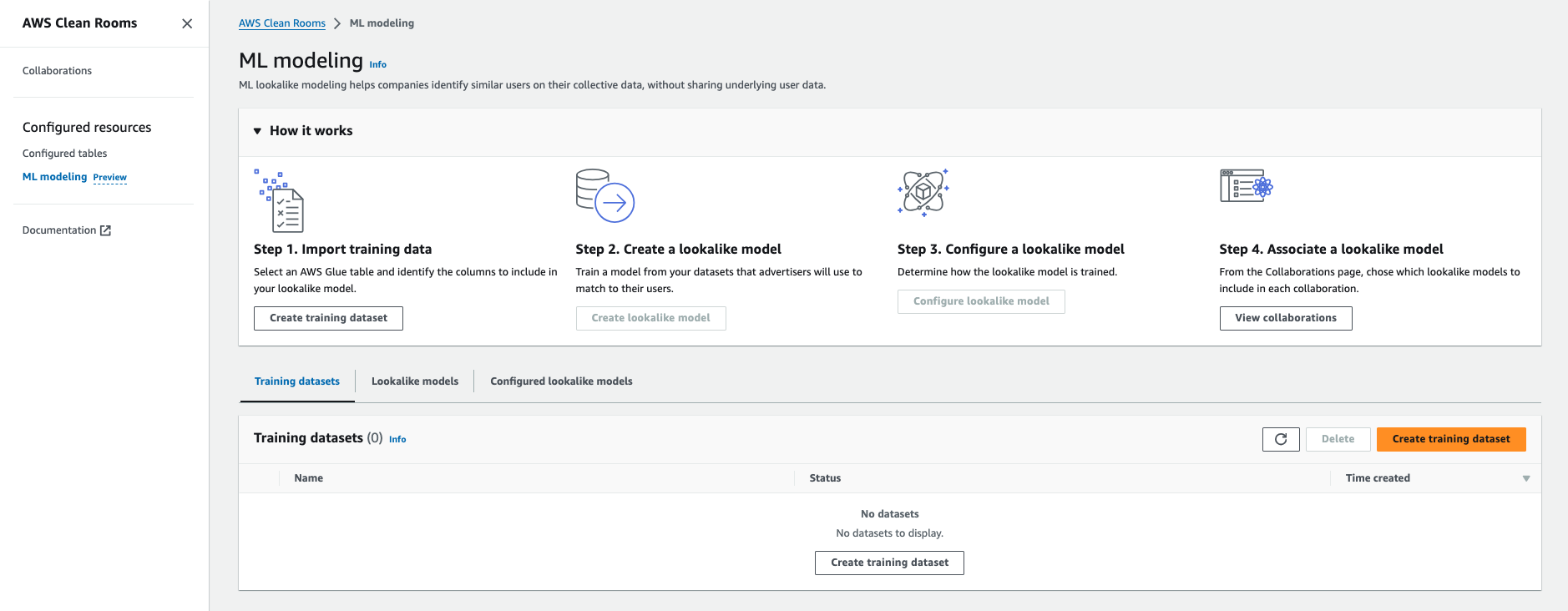
ML
MLについては仕様が面白いです。
擬似データの自動作成
まずユーザは自身のデータをアップロードすると、
クリーンルーム内で自分のデータに似た擬似データのようなものが生成されるようです。
モデルの自動学習
また、自身のデータに対していろんなAIモデルを生成することができます。
擬似データによる類似データの検索
擬似データは自動生成され、クリーンルームの中で似たようなデータを持っているコラボレーターとマッチングされます。(類似性の高いデータが検索される)
また、この検索については、暗号化されたデータ同士の類似度を計算する、PSI(Private set intersection) をサポートしているようです。
コラボレーター同士のモデルの共有、活用
データにはモデルが紐ついており、類似性の高いデータが持つモデルについて、
ユーザはコラボレータのモデルをベースに推論ができます。
ユーザは類似度の高いデータから生成されたモデルに対して、それらを活用できます。
モデルは常にアップデートされ、自分に有用なモデルが取り揃えられたモデルマートのような感じでしょうか、
コラボレーターはそれらのモデルを、自分や相手のデータを見せ合うことなく利用することができるようです。
まとめ
今回はPreviewとなったAWS Clean Rooms ML を少しだけ記事にしてみました。
解説というほどのことはできなかったので、またAWS Glueを使い実際にデータをアップロードし、
モデルの作成などにチャレンジしてみようかなと思います。
皆さんも時間があったら触ってみてください。
今回はこの辺で。