@kenmaroです。
秘密計算、準同型暗号などの記事について投稿しています。
秘密計算に関連するまとめの記事に関しては以下をご覧ください。
概要
IDASHというデータプライバシー、セキュリティのワークショップについてご存知でしょうか?
おそらく知らない人の方が多いのではないでしょうか。
このIDASH2021にはコンペが用意されており (コンペ厨歓喜)、
データプライバシー、セキュリティに関連する技術のうち3種類(トラックと呼ばれる)がお題として用意されています。
参加者はその中からお題を選んで、出された課題にチャレンジすることができます。
参加費はなんと無料です。
しかし、現在のところ賞金や賞品なども設定されていません。(この辺は頑張って欲しい。)
今回は複数人でチームを組み、
このIDASH2021のトラック2にプレイヤーとして参加しました。
このコンテストの概要、
どのような方針や、データ解析などを経て提出まで漕ぎ着けたか、
チームとして開発しどのようなことを学べたか、
などについてまとめていければと思います。
提出レポジトリ
今回2つのモデルを1チームから提出しました。
提出の際は
- docker hub によるdocker image の共有、
- コードのOSSでの提出、
- ドキュメントをpdfでの提出
が求められました。
我々はgitのREADME.mdをpdf化し、ドキュメントとして提出しました。
もし興味のある方がいらっしゃいましたらぜひレポジトリをご覧ください。
アルゴリズムや使ったセキュリティパラメータなどはそちらにまとめています。
IDASHとは?
IDASHとは
スイス連邦工科大学(ETH) (とくに有名なのはローザンヌ校EPFL)
などがオーガナイズするデータプロテクションインヘルス(DPPH)(https://dpph.ch/)
などが主体となり、また、
- Department of Biomedical Informatics at UCSD,
- School of Biomedical Informatics at UTHealth,
- School of Informatics and Computing at Indiana University
これらの機関も協力し、
医学とりわけゲノム系のデータをプライバシーを保護した状態で解析するコンペティション及びそのワークショップ
を行っているイベントのことです。
IDASHの参加には2種類あり、
1種類目はIDASHがオーガナイズするデータ解析コンペに参加する2種類目はIDASHがオーガナイズするワークショップに参加する
と分かれています。
コンペティションについて
コンペティションはここhttp://www.humangenomeprivacy.org/2021/competition-tasks.html
でまとめられているように、今年は必要技術スタックとして3種類のトラックに分かれていました。
ブロックチェーン技術を生かしたヘルスデータの共有準同型暗号を利用したウイルスの変異株を暗号状態で予測コンフィデンシャルコンピューティングでのモデル学習(今回は実際はフェデレーテッドラーニングに限定)
となっていました。
詳しい内容に興味のある方はリンクから確認していただきたいですが、
実際のタスク内容はかなり実運用を考慮したものになっています。
コーディングをして実装したものを成果物にしなくてはならないので、
実現性が極めて低いシナリオは排除され、3ヶ月程度という実装期間で無理なく課題が完了できるような条件になっています。
今回我々はトラック2である、
準同型暗号を利用したウイルスの変異株を暗号状態で予測
にチャレンジしてみることにしました。
期間について
タイムラインはオフィシャルサイトからのチャートをお借りしました。
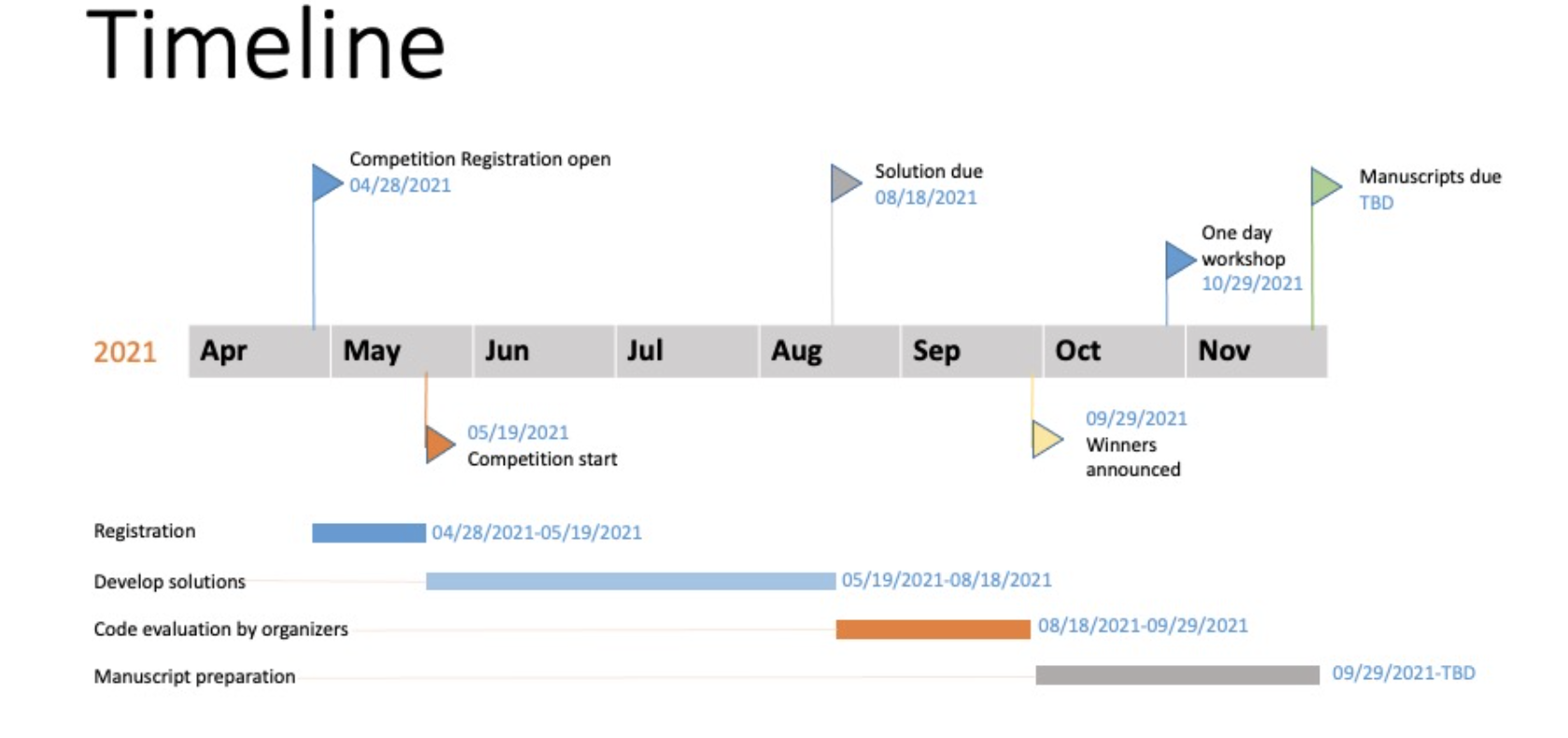
実際の開発期間はちょうど3ヶ月でした。
5月〜8月に開発し、成果物を提出。
提出された成果物は1ヶ月ほどかけて評価され、各トラックについて順位がつけられます。
順位が発表された後にワークショップが開催されます。
ワークショップではコンペに出場した人たちの発表であったり、意見交換などが執り行われます。
コンペの内容について
今回私たちが参加したのはトラック2なので、トラック2に絞ってお伝えします。
まず、参加のレジストレーションをすると、メールが届きコンペに使用するゲノムデータへのアクセス方法、
及びアクセスする時のパスワードなどが記載されています。
また、コンペ中に質問などを書き込むことのできる共有ドキュメントへのアクセス方法などもメールに記載されています。
それが完了すると、あとはとくにインストラクションなどなく、締め切りまで地道に実装を行うことになります。
提出する成果物には使用できるコンピュータリソースに対して制約が設定されていました。
前処理部分に対して使用できるメモリに制約があったり、推論に使える実行時間が最大30分程度、と定められていたりなどです。
それらにきちんと見合ったものを提出する必要があります。
提出が済むと評価期間に入ります。
この期間は基本的にやることはあまりないのですが、
時折提出したプログラムについての質問などが送られてくることがありますので、きちんと回答しましょう。
評価期間が終わると順位などが発表され、ワークショップなどの案内などがあり、コンペとしてはここで終了となります。
課題
課題に関してもオフィシャルサイトで確認できますが、
私たちが参加したトラック2の課題について簡単に説明します。
課題は、渡された学習データ(8000件のゲノム情報)から病気(今回はコロナウイルスがテーマでした。)の変異株4種類のうちどの株にそのゲノム情報が該当するかを診断する推論モデルを構築。
構築したモデルを使って、テストデータ(2000件)に対して推論を実行、この推論の際は準同型暗号をもちいてゲノム情報を暗号状態でモデルに投入します。
2000件のテストデータは渡されず、提出したプログラムに対しての入力として使用されるため、
提出するプログラムは、
- 入力テストデータを前処理するプログラム
- 前処理されたデータを暗号化し、暗号状態で変異株を推論するようなプログラム
の2段階に分かれます。
提出されたプログラムは、
- 2000件を推論するときに必要な実行時間(速度)
- その推論精度
によって順位付けされます。
このあたりの順位付けに関して明確な判断基準はないように感じました。
例えば1%精度が上がるのと実行時間が1分早くなるのはどちらがスコアが高くなるのか、など。
考えられる技術スタック
必要な技術スタックとして、
- 実際のデータを解析し、どのようなモデルを用いれば目的の変異種を正確に予測できるのか、というデータサイエンス的な側面
- そのアルゴリズムを既存の準同型暗号ライブラリ(もしくは自作したもの)にどう応用するのか、といった秘密計算に関連した側面
が必要でした。
提出するものにGUIなどは必要なく、実行可能ファイルとその使い方を記載したドキュメントのみ提出すればよいので、
フロント的な技術に関しては今回は必要ありませんでした。
開発メンバー
チームを三人でとりあえず結成しました。簡単に紹介すると、
- ベンチャーにて秘密計算に一応の経験がある筆者 kenmaro
- 大手のIT会社で研究開発をしているAIエンジニア1名 Ryohei くん
- 暗号理論専門のコンピュータサイエンス寄りの学生コーダー1名 Sくん
でした。
知識に多少差はあれど3人とも秘密計算、AIを含んだデータ解析には専門性と経験があり、
C++、Pythonに関して問題なく開発が可能なメンバーでした。
もしこれから参加を考える方へのアドバイスとしては、
- 3人程度でちょうど良いタスク量
- C++が書けないと厳しいかも
- 秘密計算を少し知っているメンバー、AIなどの知見があるメンバーが少なくとも一人ずつ居ること
が大切かなと思いました。
メンバーに明確な人数制限などはないので、1人でももしかすると開発可能かもしれません。
しかしながら、やはりこのようなコンペティションやハッカソンの醍醐味はチーム開発にもあると考えていますので、
2、3人でのチャレンジが妥当かな、というのが参加してみた感想です。
開発フロー
8月18日が締め切りであったことから、
7月いっぱいくらいでコードを完成させることを目標に設定しました。
初めてのミーティングをオンラインで行った時は、
ゲノムデータの解析に関しては全く経験がない3人だったので、
どのようなアルゴリズムを用いればいいのか見当もつかない状態でした。
したがって、最初の1ヶ月でアルゴリズム、方針、前処理方法など決定
残りの1ヶ月で暗号のところを実装、テストまでする。
というおおまかな流れとすることにしました。
二週間に1回のペースで進捗ミーティングを行い、それぞれのタスクの進捗を確認することにしました。
最初の1ヶ月は個人プレーでアルゴリズムを複数試し、最初の二週間でアルゴリズムに当たりをつけ、
次の二週間でだいたいの精度を出してみる。
その精度を持ち寄って、一番良いと思われる2つ程度のアルゴリズムを選択し、
それを暗号状態で実行可能になるように暗号ライブラリと連携してコーディングしていく、
というような戦略になりました。
アルゴリズム選定期間はスピード感が大事で、いろいろな手法を試すトライアンドエラーの期間だったので、
基本的に早いプロトタイピングのできるPythonで開発を行いました。
暗号が絡んでくると多くはC++での開発となるため、必要な関数などを洗い出し、
分担することでチーム開発を行いました。
概ねパーツが揃ってきたところで最後に一人が全コードのマージ、結合テストなどを行い、
平文時の推論結果と暗号を用いた時の推論結果が一致することを試すようなテストも行いました。
以上が簡単な開発のフローとなります。
開発計画
6月頭にスタートした開発でしたが、以下のような進め方をバックログとして記載していました。
先述の通り、開発を大まかにアルゴリズム+前処理選定(1ヶ月)、暗号部分実装+結合テスト(1ヶ月)
とし、ミーティングを2週間に一回(最後らへんは1週間に一回)基本的に行いました。
1回のミーティングで全体の開発フローの確認と、
進捗管理、次のミーティングまでの2週間までのタスク確認、技術的な相談などを行いました。
簡単な流れは以下のように記録しています。
6月
6/15 はまずデータを触り、分析に当たりをつける作業、それに伴う意見交換
6/22 個人で仮にアルゴリズムをいくつか選定し、実際に推論スコアを算出してみる
6/29 結果の良いものを持ち寄り、チームとしてよかったものを選定する
7月
7/5 暗号の部分開発着手
7/14 暗号部分を加味したアルゴリズム選定、決定
7/21 前処理のところもC++で実装しなおす
7/28 並列処理などを実装に追加して効率化を詰めていく、前処理部分と暗号部分の結合テスト
8月
8/3 だいたいの成果物完成目安
8/10 成果物の機能テスト、デバッグ作業、提出の準備
8/17 提出完了
アルゴリズム選定、前処理選定フロー
生物学的なアプローチが可能か
筆者にとって ゲノム解析どっちが初めてだったので、
まずはゲノム解析の理論や生物学的な議論を用いて何か前処理を簡単にしたり、効率化するようなことができないかという事について調査しました。
数時間の調査結果、与えられたデータのラベルとして登場するCovidの変異株(米国株、イギリス株など)はウイルスの塩基配列のある特定の場所の塩基がある特定のタンパク質からある特定のタンパク質へと変異してしまっているということでした。
それぞれの変異株によって、変異箇所は異なるため、変異株によってどこで変異が起こるのかを仮にデータから特定できれば前処理がかなり効率化できるということでした。
したがって最初のアプローチして前処理を簡単にするためにある特定の部位だけに注目して進めることができないかと考えました。
これはもしうまくいけば2万以上あったタンパク質の配列もある程度圧縮できることで非常に効率的だと思ったのですが
結局20,000シーケンスのどこに着目すれば良いのかが判断ができず、生物学的なアプローチとは一旦断念しました。
MASHアルゴリズムについての調査
次にオフィシャルサイトから提案されていたMASHと言う手法について調査しました。
MASHはシーケンスを一定の区間で区切るその変数を変数kとして定義します。
例えばk=6であれば6ずつのタンパク質を区切ってそれぞれハッシュ化します。
ハッシュ化することでその部分シーケンス位が一位の整数として表現され、
MASHでは各シーケンスに対して、登場したハッシュの最小値(もしくは最小からいくつかの値)をそのシーケンスの代表値としてテーブル化します。
推論するときは入力シーケンスに同じ計算をし、ハッシュ値の最小値が一致するような他のシーケンスを集めてクラスタリングを行います。これにより高確率で同じような塩基配列を持ったシーケンスたちを束ねることができる手法でした。
MASHではハッシュ関数をひたすらコールすることになるため、まずはPythonの標準ライブラリで実装されているハッシュ関数をいくつか用い、1番高速なものは何かを調査しました。
その後高速のハッシュ関数を使いMASHをいくつかの変数kを用いて実装してみたました。
結果は60%から65%程度しか出らず、求めていた精度からは大きく離れる結果なってしまいました。
したがって最終的にはMASHアルゴリズムからは撤退しました。
塩基配列のエンコーディング方法の調査
与えられたシーケンスは20,000以上の長さを持つシーケンスだったので、
初めに各タンパク質のストリングで表記されているデータをベクトルなどの数値データにエンコードする必要がありました。
エンコード仕事して以下の2つを実験しました。
- ラベルエンコーディング
- ワンホットエンコーディング
ラベルエンコーディング、ワンホットエンコーディングは先述のマッシュのようにシーケンスごとに区切りそれらをそれらの組み合わせをセットとして保存するところまでは共通しています。
ラベルエンコーディングでは部分シーケンスごとにラベルを付与し、ワンホットエンコーディングでは部分シーケンスに対してワンホットとなったベクトルを付与するところが違いになります。
次元削減、次元抽出
これによって数値ベクトルとして表現されたシーケンスをエンコードされた数値データとして、
次の次元削減、次元抽出の入力としました。
まずは次元削減、次元抽出などを目標とし、ScikitLearnに実装されているPCA,Truncated SVD, tSNEなどをつかって次元の削減を行いました。
###分類器の調査
また抽出された特徴量用い、それを
- 簡単なニューラルネットの分類器
- セントロイドによるクラスタリング
- KNNによる分類器
へのインプットとしてどこまで精度が上がるか、次元をどこまで下げることができるか実験しました。
結果として、以下のことがわかりました。
- エンコーディング手法としてワンホットエンコーディングの方が推論精度が少しだけ高くなる。(しかしエンコードされた出力としての次元数はラベルエンコードの時より大きい。)
- 次元抽出は100〜200次元程度までの圧縮がよく、さらに小さくすることも可能。
- PCAよりtSNEを用いた方が推論精度が少しだけ良くなる。
- tSNEは状態を保存できない(つまりfit関数は存在せず、fittransformしか存在しないため、今回のシナリオには向かない。)
- KNNだと96%程度、NNだと98%程度の推論精度、セントロイドを用いたクラスタリングは65%程度までしか上がらない。
初めの1ヶ月の結論
このように概ね前処理のアプローチと、その後の判別器のアルゴリズムを絞りました。
- エンコーディングとしてはワンホットを採用
- 次元抽出、削減にはPCAを採用し、200次元まで落とす
- 入力ベクトルに対してKNNもしくはNNで判別器を暗号実行する
暗号ライブラリとの結合
戦略
上で決定した前処理のアルゴリズム、
また特徴抽出削減のアルゴリズムに関しては平文状態での実行となります。
それらの入力を暗号化した後判別器のアルゴリズムには暗号ライブラリが暗号化されたものを入力します。
したがって2つのアルゴリズムに対して暗号状態でどちらが効率的に実行できるのか、
ということに関して実際にコーディングを行い暗号に適したアルゴリズムの選定を行いました。
使用格子暗号ライブラリ
使用するライブラリは、ベクトルや実数値を扱うことから、
マイクロソフトのリサーチチームが開発、運用しているSEALライブラリを用いることにしました。
SEALライブラリに関しては今までたくさん使ってきたことがあったので、
高速化のアイディアなども想起しやすく、これでとりあえず2つのアルゴリズムを
実験してみて、どちらのアルゴリズムを実際に選択するか判断することにしました。
###暗号状態での計算効率を加味
CKKS形式の強みであるSIMD計算を活用
KNNに関しては入力ベクトルに対して、学習データ(8000件)それぞれとの距離を準同型暗号の性質を用いて計算する必要がありました。
従って、8192次元の格子暗号を使ったと仮定しても、200次元の入力ベクトルに対して40シーケンス分のデータしか暗号文に格納できないため、(実際は使えるスロットは8192/2 = 4096なのでその半分)、
少なくとも20個の暗号文をテーブルとして保持し、それぞれとの距離を計算する必要がありました。
したがって、ある程度予想はしていましたがKNNはあまり高速に実装できにくいアルゴリズムでした。
これに対してNNは、1層のみのロジスティック回帰的なアルゴリズムを採用することで、一回の線形変換を準同型的に評価することで推論可能です。
この時の線形変換に使う重みは学習済みであれば一定であり、200X4の重み行列となるので、
1つの暗号文に対して20の入力を一括して入れることが可能でした。
したがって、ニューラルネットによる推論が比較的CKKS形式の恩恵を受けて高速化しやすいという判断になりました。
簡易な計測結果
実際に推論のところを簡単にコーディングして1CPUで(並列化処理なしで)速度測定したところ、
テスト評価時の2000件を
- KNNではPCAで2次元まで落として推論したとしても250秒かかる
- 回帰モデルだとPCAで200次元保持したままでも8秒程度で推論完了
という結果となりました。
したがって、PCAで200次元まで落とした特徴量を回帰モデルで推論する
モデルで一旦固定し、前処理部分と暗号部分を結合するコーディングに移りました。
C++ での前処理の実行
実際に速度が測定される際は、前処理も含めての測定となるため、前処理の部分もC++で実装することにしました。
ワンホットエンコーディングはまず学習データに対してPythonのPandasを用いて行い、
結果をC++側に出力。出力されたデータに従って推論用データもワンホットエンコーディングするような仕様にしました。
PCA行列などは学習データに対してPythonを用いて学習をさせ、
学習された行列をC++側でロードしておいて、推論時にPCA変換をおこないました。
この際、線形変換のライブラリにはEigenを用いました。
結局C++とPythonどちらも前処理プログラムを実装
ワンホットエンコードにおいては、
Pythonのpandasライブラリによるget_dummies 関数が非常に強力で、
C++でナイーブに実装するよりも高速であること、
Eigenでの計算も高速だがnumpyでも遜色なく線形計算を行えることなどを理由に、
Pythonでの前処理プログラムも用意はしていました。
結合、性能テスト
以上のC++での実装が7月最終週に概ね終了しました。
与えられているデータセットに対して
- 平文で推論を行った時
- 実際に提出するプログラムを使って暗号状態で推論を行ったときの性能
の差について実際に比較し精度が落ちていないことを確かめるようなテストを8月の第1週で行うことができました。
Dockerfileの準備
Pythonを使うときやSEALのバージョンなどに依存関係があるプログラムを提出することになったため、
念の為Dockerfileを用意し、評価者が依存関係などを簡単に構築、速度テストなどを行えるようにしました。
また、
- Dockerを用いて環境構築する際の簡単なコマンド
- -テスト実行時の引数の渡し方
などを簡単にまとめたドキュメントを整備し、それとともに提出準備を行いました。
提出
これにより提出の準備が済み、8月の19日から約2週間ほど余裕を持った状態でプログラムの実装完了することができました。
本来であればあと1,2週間早くすべてのコーディングを 完了しておきたかったですが、
現実的に考えて1週間程度のバッファーをとっていたのは最初の計画のときにやっていてよかったなと思っています。
その後CPUが複数の場合の並列処理なども組み込むところまで完了し、
8/15 に無事成果物をIDASHオフィシャルの方に提出完了することができました。
評価結果待ち
1ヵ月後の9月に結果が発表されますが、
チームとしてきちんと成果物が目標通り達成され、楽しく開発できたので気楽に待ちたいと思います。
個人的感想
やはり、コンペやハッカソンは学びが多くとても面白かったです。
今まで、プレイヤーとして個人的にハッカソンに出たことはエプソン主催のハッカソンに1回のみで、
今回は2回目の対外的コンペ参加、という感じでした。
あとは主催者側として秘密計算のハッカソンを主催したことが1回、
Yahoo Japan 主催のHackDay2021に協賛(技術提供)、審査員としての参加が1回でした。
やはり、主催者側も楽しいですが、プレイヤーとしてチームで開発することの醍醐味を感じるという意味で
とても楽しく、やりがいを感じることができました。
また機会があればいろいろなハッカソンに出てみたいと思っています。
秘密計算を用いたコンペティションはあまり行われていませんし、出場しようと思っていても周りに興味のある人を見つけにくい分野かもしれません。
しかしながら今回のタスクに関しては時間も潤沢にありましたし、
課題もそこまで難易度が高くなかったため、割と参加しやすかったのかなあと思っています。
ただしなにも賞品などが用意されていないのは魅力的でないですよね、、
まとめ
今回はIDASHについて参加してみたレポートとしてまとめてみました。
IDASHは国際コンペで誰でも参加できます。
日本からの参加は今のところあまり多くないみたいですので、
もし興味がある人はぜひ参加してみてはいかがでしょうか。
(賞金とか賞品がないところはあまりモチベーションにはならないかもしれないですが、、)
研究室で秘密計算について研究している学生などにとってはいい機会になると思います。
個人的には他のトラックの例えばブロックチェーン技術を使ったトラック1などもにも参加できるような技術スタックを身につけられたら良いなと思っています。
ハッカソンで短期集中して成果物を作る経験はほんとうに良い経験になりますし、
チーム開発も学べますので、マネジメント経験にもなります。
毎回同じチームで開発して最強のチームへとビルドアップしていくのも楽しいですし、
毎回メンバーを変えて、違う技術スタックをもつメンバーからいろんなことを学んだりするのも楽しいですね、
あなたはどのようなハッカソンチームをビルドしてみたいですか??
ハッカソン的なイベントへの参加、オススメです!
今回はこの辺で。
kenmaro