今回弊社で開催した勉強会で発表された、検索可能暗号へのアタック手法のまとめ。
勉強会での結論
- 検索可能暗号はその使い勝手の良さの反面、最も安全とされる暗号よりも機密性を担保できない。
- それらをついた、複数の攻撃手法がある。
- ユーザの扱うデータの性質によっては、これらの攻撃がハマることがある。
- ユーザ、暗号データベース提供者の両者がこれらの攻撃手法とそのリスクに対して理解し、最適な暗号化を提供することが大切。
また、これらのレポートは
Naveed, M., Kamara, S., & Wright, C. V. (2015, October). Inference attacks on property-preserving encrypted databases. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security(pp. 644-655). ACM
を参考にしている。

検索可能暗号って?
- 暗号化したまま検索可能な暗号化手法のこと
- 様々な検索可能暗号へのアプローチがある
- ORAM(Oblivious RAM)
- PIR(multi-server Private Information Retrieval)
-
SSE(Searchable Symmetric Encryption)
今回はSSEに焦点を当てて、SSEへの推論攻撃(つまり検索暗号をクラックしようとする攻撃)にはどのようなものがあるかまとめる。
- ここで使われる推論攻撃は、具体的には、暗号文と補助データ(公に公開されているオープンデータ)の組み合わせにより平文を解読しようとする攻撃方法である。
なぜSSEを使うのか?
- データベースなどに検索暗号を適用しやすい(既存のデータベースを検索可能暗号化したデータで置き換えたりする例が挙げられる)
- 実装が比較的簡単である(暗号形態は比較的標準のもので、難しいものは使っていない)
- 既存のデータベースを使用する際と使用感がほとんど変わらないため、移行が簡単である
- 暗号形式が比較的知られた従来の暗号である
- AES暗号(米国標準規格として採用されている共通鍵暗号であり、検索可能性を担保するためにはランダム性のないもの =決定的AES を採用する)
- OPE/ORE(Order Preserved Encryption: 順序保存暗号と呼ばれる、平文の大小関係を保持したまま、平文の持つ情報を暗号化させる暗号スキームのこと)
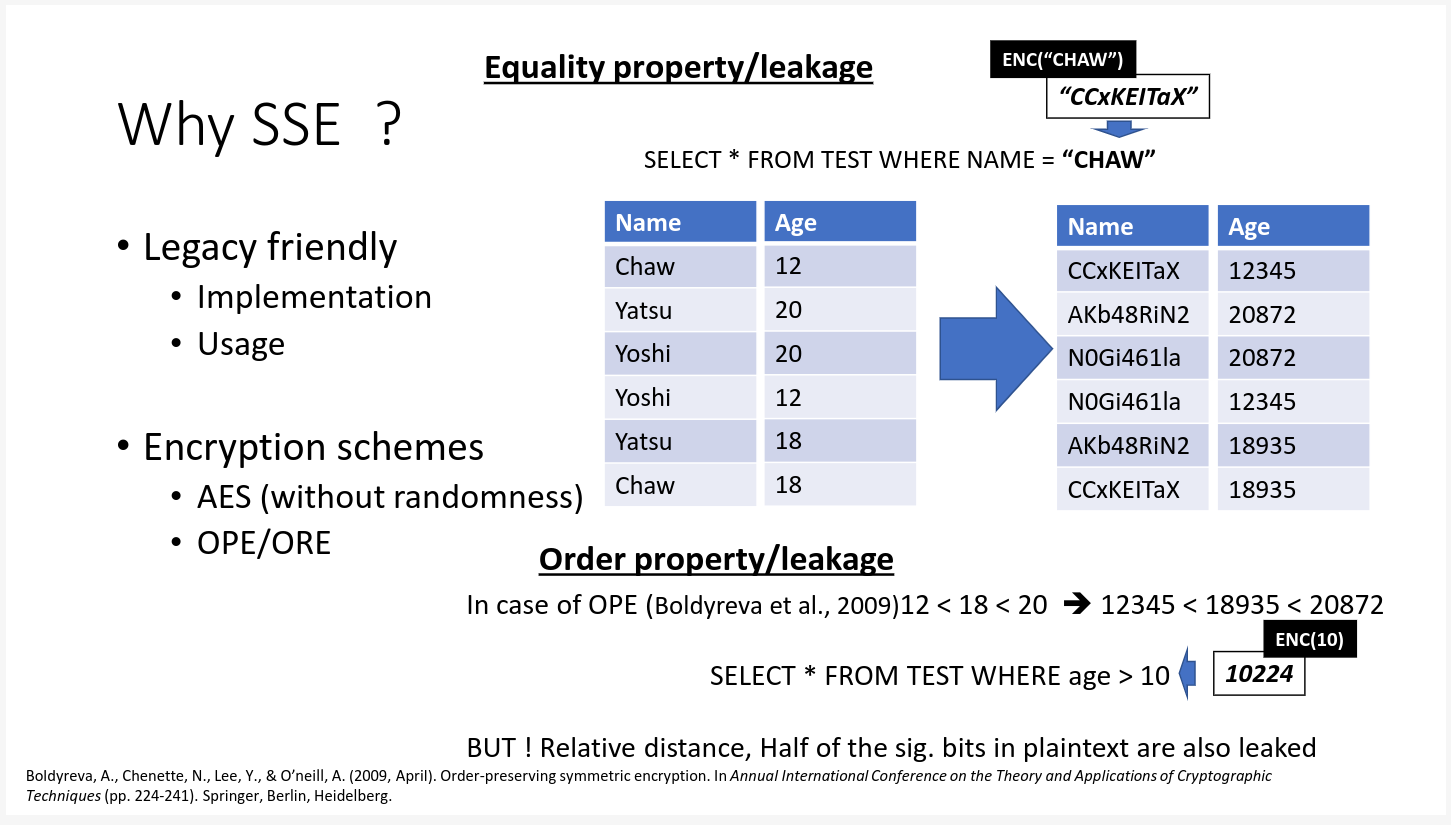
例えば、上のテーブルの例だと、平文のデータベース(左テーブル)を検索可能暗号によって暗号化し、暗号化されたテーブル(右テーブル)を生成する。
その際、
- Nameカラムー>Stringなので、AES暗号で暗号化
-
Ageカラムー>Intなので、OPEで暗号化
したとする。
もしユーザが一般的なSQL文**"SELECT * FROM TEST WHERE NAME = ”CHAW”"**
を実行すると、実際には**AES_Enc("CHAW")="CCxKEITaX"**となり
**"SELECT * FROM TEST WHERE NAME = ”CCxKEITaX”"**が実行されることに成る。
また、OPE暗号は平文の数字の大小関係を保存するので、
"SELECT * FROM TEST WHERE age > 10" というようなクエリも
OPE_Enc(10) = 10224 により
"SELECT * FROM TEST WHERE age > 10224"
というクエリが実際には実行される。
以上が検索可能暗号のざっくりとした流れである。
暗号化データと補助データ(パブリックデータ)による攻撃種類
頻度分析攻撃

簡単な手法であるが効果は高い
例えば、暗号化されたテーブル情報にアクセスできるとき(右テーブル)、
- 出てきた暗号文の頻度をチェックする(中テーブル)。
- 決定的AESは入力となる平文が同じ場合、出力の暗号文も同じになるため、平文そのものはわからなくても平文がどのような偏りをもった情報なのか(ヒストグラム情報)がわかる。
- 補助データ(パブリックデータ)に対してもヒストグラム情報を計算する。
- 似たようなヒストグラム情報を持つ暗号カラムを目的カラムだと断定する。
- 断定された目的カラムと補助データの対応するデータを照らし合わせ、暗号文と補助データ内の平文を対応付ける。
仮にこのヒストグラム情報が機密性の高いものである場合、頻度分析攻撃はかなり効果的である。
ただし、暗号化されたカラムの数が多いとき、仮にヒストグラム情報がわかったとしても上記4の目的カラムを断定することが困難である。
次の手法はその困難性にフォーカスしたもの。
Ip最適化攻撃

頻度分析攻撃よりも比較的高度な攻撃手法
- 暗号化テーブルと、補助データの頻出度データ(ヒストグラム)を計算するところまでは同じ。
- 上記2つの頻出度に対してL2距離を計算し、その総和を取る。
- 総和が一番小さくなるような並び替えを総当りで計算する。
- 目的カラムの候補カラムに対し、最小化されたL2距離の総和をそれぞれ求める。
- 距離情報にもとづいて、目的カラムを断定する。
- 断定された目的カラムと補助データの対応するデータを照らし合わせ、暗号文と補助データ内の平文を対応付ける。
この手法では、L2距離を暗号化カラムと補助データの間で求め、最小となる並び替えをすることにより、頻度分析攻撃よりも目的カラムに到達しやすくなっている。
頻度分析手法、Ip最適化攻撃はAES暗号であってもOPE暗号であっても適用ができるが、
OPE暗号に対しては更に効果的な攻撃が可能である。
OPEカラムに対する順序攻撃
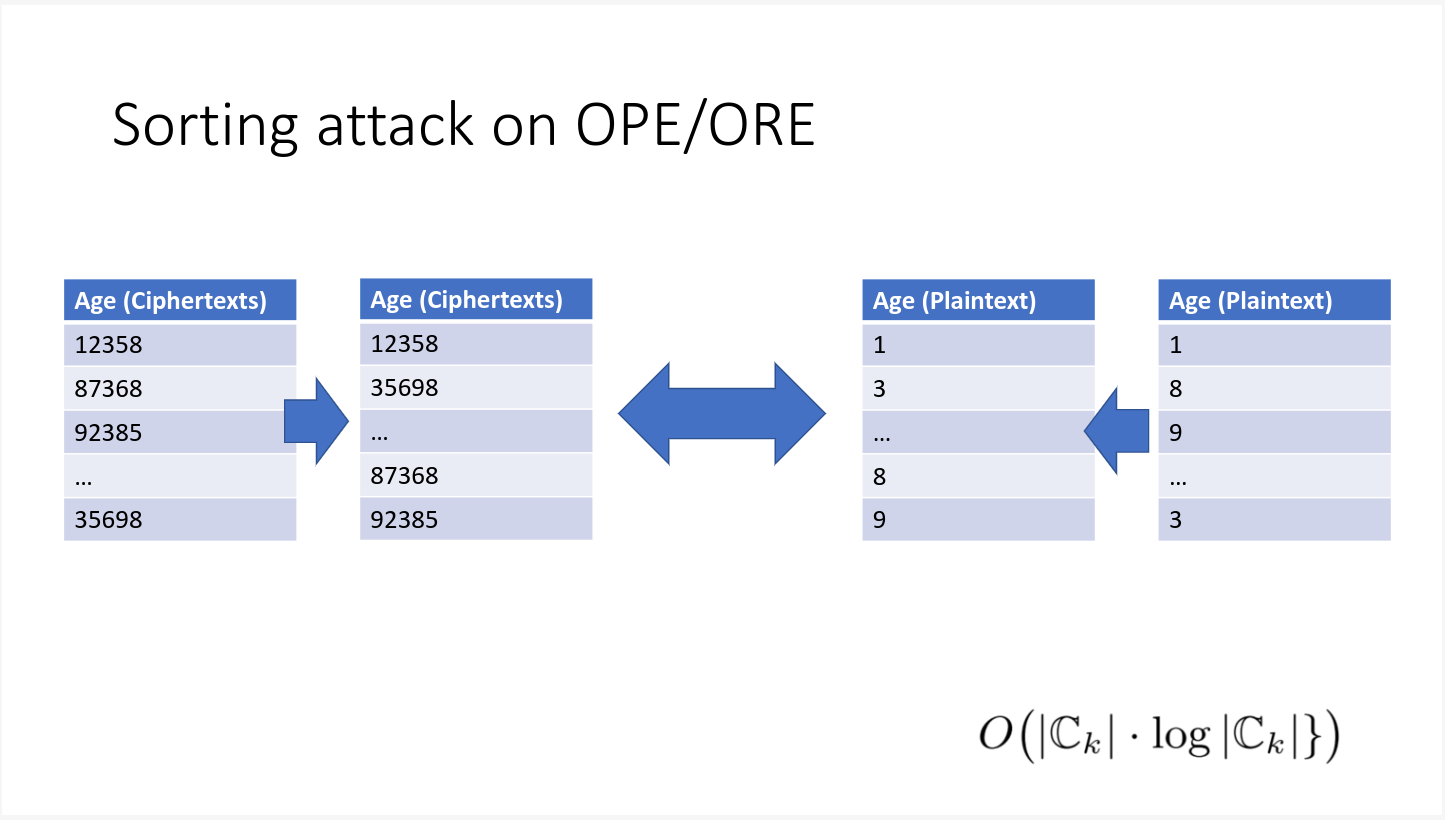
上2つの頻出度を、暗号化されたカラム、補助データに対して行うのに加えて、
OPE暗号を行ったカラムは、平文の順序も保存している。そのため、目的カラム、および目的カラム内のデータを断定するのに更に一つ情報が増えている。
したがって、OPE暗号は決定的AESよりもさらに1レベルパブリックデータによる攻撃耐性が低いと考えられる。
この事実を利用した攻撃が以下である。
累積分布関数を用いた攻撃手法

上で出てきたIp最適化攻撃に加えて、OPE暗号が平文の順序を保存するという事実を用いる。
一つの暗号文に対して、以下を仮定として考える。
その暗号文が、すべての暗号化されたデータ総数のx%よりも小さいとする(一番小さいものからカウントした、暗号文xの累積分布関数)。
その時、補助データにおいてもおそらく同じことが成り立っているはず。(対応する平文yも、近い累積分布関数をもっているはず)
このとき、Ip最適化攻撃に加えて累積分布関数(テーブル内のCDFカラム)も、目的カラム、及びカラム内のデータの断定に役立てることができる。
まとめ
これらの手法は大前提として、ユーザの持つデータセットがパブリックなオープンデータと類似した統計に基づいていることを利用している。
この場合、検索可能暗号を用いて暗号化されたデータにおいて
- OPEで暗号化されたデータの取扱い
- 決定的AESで暗号化されたデータの取扱
には最善の注意が必要である。対策としては、
- 暗号化されたデータにアクセスさせないようなシステムアーキテクチャ
-
それらのデータを更に非決定的AES暗号で再暗号化(2重の暗号化)
などが挙げられる。