AWS Deep Cutsは、AWS の中でも特に最新のサービスやニッチな機能など、多くの人が知らない「隠れた名曲 = Deep Cuts」を深くまで掘り下げる技術シリーズです。
このようなサービスは情報が少ないため、一部の有識者以外は触り方すら分からず、気軽にキャッチアップできないのが実情です。
そこでAWS Deep Cuts シリーズは「どんな人でも実際に触りながら理解できる」ことを目指し、できるだけ噛み砕いたサービス解説と簡単なハンズオンを提供します。
ハンズオン教材はGitHubでも公開しています。
https://github.com/Kenta-Matsuda/AWS-Deep-Cuts
🔰 はじめに
AWS Entity Resolution (AWS ER) はまだ日本語の記事が少なく、知らないエンジニアも多いかもしれません。この記事では、サービスの概要や特徴をわかりやすく解説し、実際に触ってみるハンズオンも紹介します。データマッチングの課題に直面している方や、Customer 360やデータクレンジングに興味がある方は必見です!
1️⃣ Entity Resolutionとは?
Entity Resolution (ER) とは、異なるデータセットに散在するレコードの中から同一人物や同一企業などを特定して統合する技術です。データは重複や表記ゆれを含むことが多く、手動の照合作業は大変な工数がかかります。ER を活用すると、データ統合・分析・パーソナライゼーションの精度が向上し、ビジネス上の意思決定を支援します1。
2️⃣ AWS Entity Resolutionとは?
AWS Entity Resolutionは、こうしたエンティティマッチングを完全マネージドで実行できるサービスです。特徴として、以下のような点が挙げられます。
-
プリセット済みアルゴリズムとインタラクティブな設定
AWSが用意したマッチングアルゴリズムを選択でき、GUI上でルールを細かく調整できます2。 -
ルールベース/機械学習ベース/外部データプロバイダー連携
メールアドレスや電話番号など特定フィールドに対する明示的なルール、AWSが提供する機械学習モデル、さらにLiveRampやUID2などのIDサービスと連携したマッチングを選べます3。 -
ファジーマッチング
レーベンシュタイン距離やCosine類似度、Soundex などのアルゴリズムを利用し、スペルミスや文字順の違いでも高精度にマッチさせます3。 -
ニアリアルタイム照合 API
GetMatchID API により受信したレコードをハッシュ化し、既存のマッチIDを即座に返せます3。リアルタイムなパーソナライズや不正検知に利用できます。 -
セキュリティと地域性
データはデフォルトでAWS管理のキーで暗号化され、必要に応じてKMSキーを指定できます。VPC内からPrivateLinkで安全に呼び出すことも可能です3。 -
料金
ルール/MLマッチングは1,000レコードあたり約0.25 USD、外部プロバイダー連携は0.10 USDから課金されます3。
このように、AWS ER はデータ統合に必要な複雑な処理をマネージド化してくれる頼もしいサービスです。実際の使い方を次章で見ていきましょう!
3️⃣ 主なユースケース
AWS ER はさまざまな業界や場面で利用されています4。
-
Customer 360 / マーケティング
CRMや購買履歴、Web行動など複数のチャネルで顧客情報を統合し、統一した顧客ビューを構築します。
Customer 360とは
企業が保有する顧客のあらゆるデータ(属性、購入履歴、問い合わせ状況、Web上の行動など)を統合し、1人の顧客の全体像を多角的(=360度)に把握する概念や仕組み
-
不正検知
金融機関では、複数口座にまたがる取引を結び付けて不審なパターンを検出します。 -
ヘルスケア
病院や診療所に分散している患者情報を統合し、治療の一貫性を確保します。 -
小売 / EC
購買履歴や閲覧行動をまとめ、レコメンドやターゲティング精度を高めます。 -
データクレンジング・重複排除
機械学習モデル作成やBI分析の前処理として、重複データを除去する。
4️⃣ ハンズオン:AWS Entity Resolutionを触ってみよう
ここでは、実際にAWS Entity Resolutionで「顧客データの名寄せ」をやってみましょう。
このハンズオンでは、2つのCSVに分かれている顧客データをAWS Entity Resolutionで照合し、同一顧客に同じMatch IDを付与することを行います。ただし今回は、ワークフローを1つだけ作るのではなく、同じ2つのCSVを使って、目的別に複数パターンのマッチングワークフローを試す構成にします。
具体的には、以下の5パターンを順番に試します。
Pattern 1: Raw Exact Matching
生データのまま、email / phone の完全一致だけで名寄せする
Pattern 2: Cleansed Exact Matching
クレンジング済みキー列を使い、確実な一致だけを拾う
Pattern 3: Conservative Fuzzy Matching
表記ゆれを少し許容するが、誤統合しそうなものは拾わない
Pattern 4: Review Candidate Matching
あえて緩い条件で「人手確認候補」まで拾う
Pattern 5: GetMatchId API
バッチ実行後、新規レコードをリアルタイム照合する
AWS Entity Resolutionは、AWS Glueのテーブルを入力として読み込み、マッチングワークフローでレコードを比較し、マッチしたレコード集合にMatch IDを割り当てます。AWS公式ドキュメントでも、入力データはAWS Glueから読み込まれ、スキーママッピングを定義したうえでマッチングワークフローに利用すると説明されています。5
AWS Entity Resolutionでは、Schema mappingを事前に作成し、AWS Glueテーブルと対応するSchema mappingを入力にしてMatching workflowを作成します。Simple rule typeでは最大15個のルール、Advanced rule typeでは最大25個のルールを作成できます。AdvancedではCosine、Levenshtein、Soundexなどのファジー関数を使えますが、ファジー関数はExact系の条件とANDで組み合わせる必要があります。([AWS ドキュメント][5])
今回作成する主な設定は以下に固定します。
リージョン: ap-northeast-1
マッチング方式: Rule-based matching
ルールタイプ: Simple(Pattern 1, 2) / Advanced(Pattern 3, 4)
処理方式: Manual
入力データ: S3上のCSV 2ファイル
Glueデータベース: 1個
Glueテーブル: 2個
Schema mapping: 2個
Matching workflow: 4個(Pattern 1〜4)
Simpleは完全一致ベースで、リアルタイムワークフローにも対応します。表記ゆれを許容するファジーマッチングを使いたい場合は、Advanced rule typeが必要です。本ハンズオンでは、両方を体験するためにSimpleとAdvancedの両方を使います。([AWS ドキュメント][2])
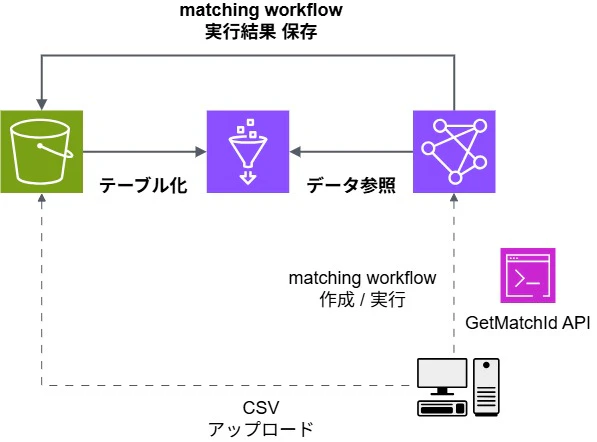
このハンズオンで作るもの
今回のハンズオンで作成するリソース一覧は以下の通りです。
S3 bucket x 1:
Glue テーブルを作成するための元データや、AWS Entity Resolution の実行結果を格納します
AWS Glue:
AWS Glue database x 1:
AWS Glue tables x 2:
データ統合に利用する2つのテーブルを作成します
AWS Entity Resolution:
AWS Entity Resolution schema mappings x 2:
AWS Entity Resolution matching workflow x 4:
各テーブルのスキーママッピングと、目的別の4つの突合結果を作成します
アーキテクチャ図にすると以下のようになります。
1. 前提環境
- ローカルにAWS CLIが導入されていること
- 導入がまだの方は、公式ドキュメントから導入してください
- AWS CLIに認証情報が設定されていること
- 公式ドキュメントを参考にして、aws configureなどで設定してください
2. 使用する環境
以下をそのまま実行します。
export AWS_REGION=ap-northeast-1
export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
export RUN_ID=er$(date +%Y%m%d%H%M%S)
export BUCKET=aws-er-handson-${AWS_ACCOUNT_ID}-${RUN_ID}
export GLUE_DATABASE=aws_er_handson_${RUN_ID}
export SCHEMA_PRIMARY=customers_primary
export SCHEMA_SECONDARY=customers_secondary
export WORKFLOW_01=er-handson-01-raw-exact
export WORKFLOW_02=er-handson-02-cleansed-exact
export WORKFLOW_03=er-handson-03-conservative-fuzzy
export WORKFLOW_04=er-handson-04-review-candidates
echo "AWS_REGION=ap-northeast-1"
echo "AWS_ACCOUNT_ID=${AWS_ACCOUNT_ID}"
echo "RUN_ID=${RUN_ID}"
echo "BUCKET=${BUCKET}"
echo "GLUE_DATABASE=${GLUE_DATABASE}"
echo "SCHEMA_PRIMARY=${SCHEMA_PRIMARY}"
echo "SCHEMA_SECONDARY=${SCHEMA_SECONDARY}"
echo "WORKFLOW_01=${WORKFLOW_01}"
echo "WORKFLOW_02=${WORKFLOW_02}"
echo "WORKFLOW_03=${WORKFLOW_03}"
echo "WORKFLOW_04=${WORKFLOW_04}"
以降、コンソールで名前を入力する場面では、ここで表示された値をそのまま使います。
3. サンプルCSVを作成する
3.1 registration_data.csv を作成する
このCSVは、CRMや会員登録データを想定しています。
source_record_id,full_name,email,phone,address,city,email_key,phone_key,name_key,address_key,city_key
A001,Yamada Taro,taro.yamada@example.com,08011112222,1-1-1 Shibuya,Tokyo,taro.yamada@example.com,08011112222,yamada taro,1-1-1-shibuya,tokyo
A002,Sato Hanako,hanako.sato@example.com,09022223333,2-2-2 Umeda,Osaka,hanako.sato@example.com,09022223333,sato hanako,2-2-2-umeda,osaka
A003,Suzuki Ichiro,ichiro.suzuki@example.com,07033334444,3-3-3 Sakae,Nagoya,ichiro.suzuki@example.com,07033334444,suzuki ichiro,3-3-3-sakae,nagoya
A004,Tanaka Jiro,jiro.tanaka@example.com,08044445555,4-4-4 Tenjin,Fukuoka,jiro.tanaka@example.com,08044445555,tanaka jiro,4-4-4-tenjin,fukuoka
A005,YAMADA TARO,Taro.Yamada@Example.com,080-1111-2222,1-1-1 Shibuya,Tokyo,taro.yamada@example.com,08011112222,yamada taro,1-1-1-shibuya,tokyo
A006,Sato Hana,h.sato@example.com,,2-2-2 Umeda,Osaka,h.sato@example.com,,sato hana,2-2-2-umeda,osaka
A007,山田 太郎,taro_yamada@example.com,08011112222,1-1-1 渋谷,東京,taro_yamada@example.com,08011112222,yamada taro,1-1-1-shibuya,tokyo
A008,No Match A,no.match.a@example.com,08055556666,5-5-5 Susukino,Sapporo,no.match.a@example.com,08055556666,no match a,5-5-5-susukino,sapporo
3.2 lead_list.csv を作成する
このCSVは、マーケティングにおける見込み顧客のリストを想定しています。
source_record_id,full_name,email,phone,address,city,email_key,phone_key,name_key,address_key,city_key
B001,Taro Yamada,taro.yamada@example.com,08099990000,1-1-1 Shibuya,Tokyo,taro.yamada@example.com,08099990000,yamada taro,1-1-1-shibuya,tokyo
B002,Hanako Sato,h.sato@example.com,09022223333,2-2-2 Umeda,Osaka,h.sato@example.com,09022223333,sato hanako,2-2-2-umeda,osaka
B003,Ichiro Suzuki,ichiro.suzuki@example.com,07033334444,3-3-3 Sakae,Nagoya,ichiro.suzuki@example.com,07033334444,suzuki ichiro,3-3-3-sakae,nagoya
B004,Jiro Tanaka,j.tanaka@example.com,08044445555,4-4-4 Tenjin,Fukuoka,j.tanaka@example.com,08044445555,tanaka jiro,4-4-4-tenjin,fukuoka
B005,No Match B,no.match.b@example.com,08077778888,5-5-5 Gion,Kyoto,no.match.b@example.com,08077778888,no match b,5-5-5-gion,kyoto
B006,Taro Yamada,taro.yamada+promo@example.com,08011112222,1-1-1 Shibuya,Tokyo,taro.yamada@example.com,08011112222,yamada taro,1-1-1-shibuya,tokyo
B007,Sato Hanoko,hanako.sato@example.com,090-2222-3333,2-2-2 Umeda,Osaka,hanako.sato@example.com,09022223333,sato hanoko,2-2-2-umeda,osaka
B008,Yamada T.,taro@example.com,08011112223,1-1-1 Shibuya,Tokyo,taro@example.com,08011112223,yamada t,1-1-1-shibuya,tokyo
B009,山田太郎,taro-yamada@example.com,08011112222,1-1-1 渋谷,東京,taro-yamada@example.com,08011112222,yamada taro,1-1-1-shibuya,tokyo
B010,Suzuki Ichirou,ichiro.suzuki@example.com,07033334444,3-3-3 Sakae,Nagoya,ichiro.suzuki@example.com,07033334444,suzuki ichirou,3-3-3-sakae,nagoya
3.3 期待するマッチング結果
このデータでは、以下のマッチを期待します。
| 期待Match ID | レコードID | 顧客像 |
|---|---|---|
| M001 | A001, A005, A007, B001, B006, B009 | 山田太郎 / Taro Yamada |
| M002 | A002, A006, B002, B007 | 佐藤花子 / Hanako Sato |
| M003 | A003, B003, B010 | 鈴木一郎 / Ichiro Suzuki |
| M004 | A004, B004 | 田中次郎 / Jiro Tanaka |
| M005 | A008 | No Match A |
| M006 | B005 | No Match B |
| 要レビュー | B008 | 山田太郎の可能性はあるが自動統合しない |
4. S3バケットを作成してCSVをアップロードする
以降のコマンドでは、{}で囲まれた部分を自環境用に修正してください。
4.1 S3バケットを作成する
{YYYYMMDD}を変更してください。
# 東京リージョンに、「aws-deepcuts-er-ACCOUNT_ID-YYYYMMDD」というS3を作成
aws s3 mb s3://aws-deepcuts-er-$(aws sts get-caller-identity --query Account --output text)-{YYYYMMDD} --region ap-northeast-1
4.2 バケット暗号化を有効化する
{YYYYMMDD}を変更してください。
aws s3api put-bucket-encryption \
--bucket aws-deepcuts-er-$(aws sts get-caller-identity --query Account --output text)-{YYYYMMDD} \
--server-side-encryption-configuration '{
"Rules": [
{
"ApplyServerSideEncryptionByDefault": {
"SSEAlgorithm": "AES256"
}
}
]
}' \
--region ap-northeast-1
4.3 CSVをアップロードする
{YYYYMMDD}を変更してください。
aws s3 cp registration_data.csv s3://aws-deepcuts-er-$(aws sts get-caller-identity --query Account --output text)-{YYYYMMDD}/input/registration_data/registration_data.csv --region ap-northeast-1
aws s3 cp lead_list.csv s3://aws-deepcuts-er-$(aws sts get-caller-identity --query Account --output text)-{YYYYMMDD}/input/lead_list/lead_list.csv --region ap-northeast-1
4.4 アップロード結果を確認する
{YYYYMMDD}を変更してください。
aws s3 ls s3://aws-deepcuts-er-$(aws sts get-caller-identity --query Account --output text)-{YYYYMMDD}/input/ --region ap-northeast-1 --recursive
以下のように2ファイルが表示されれば成功です。
registration_data.csv
lead_list.csv
5. AWS Glueデータベースを作成する
5.1 db.json を作成する
まず、Glueデータベースの定義ファイルを db.json として作成します。
{
"Name": "aws-deepcuts-er-glue-db"
}
なお、db.json の内容は 5.2 Glue データベースを作成する でコマンドを実行する際に、直接引数として渡しても構いません。ただし実行環境によってJSONのエスケープ処理が異なるため、ここではファイル形式でコマンドに渡す方法を採用しています。
5.2 Glue データベースを作成する
以下のコマンドで Glue データベースを作成します。
aws glue create-database --database-input file://db.json --region ap-northeast-1
Glue データベースが作成できたことを確認します。
aws glue get-databases --region ap-northeast-1
以下のように、 aws-deepcuts-er-glue-db のエントリが表示されれば成功です。
{
"DatabaseList": [
{
"Name": "aws-deepcuts-er-glue-db",
"CreateTime": "2026-05-29T03:15:43+09:00",
"CreateTableDefaultPermissions": [
{
"Principal": {
"DataLakePrincipalIdentifier": "IAM_ALLOWED_PRINCIPALS"
},
"Permissions": [
"ALL"
]
}
],
"CatalogId": "663858476530"
}
]
}
6. AWS Glueテーブルを作成する
AWS Entity Resolutionは、S3上のファイルを直接指定するのではなく、AWS Glueテーブルを入力として使います。AWS公式ドキュメントでも、AWS Entity ResolutionはAWS Glueからデータを読み取り、各行をレコードとして処理すると説明されています。([AWS ドキュメント][1])
6.1 registration_data 用のGlueテーブル定義を作成する
以下の内容で registration_data_table.json を作成してください。ただし StorageDescriptor.Locationを変更してください。
{
"Name": "registration_data",
"TableType": "EXTERNAL_TABLE",
"Parameters": {
"classification": "csv",
"skip.header.line.count": "1"
},
"StorageDescriptor": {
"Location": "s3://aws-deepcuts-er-{ACCOUNT_ID}-{YYYYMMDD}/input/registration_data/",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"SerdeInfo": {
"SerializationLibrary": "org.apache.hadoop.hive.serde2.OpenCSVSerde",
"Parameters": {
"separatorChar": ",",
"quoteChar": "\""
}
},
"Columns": [
{ "Name": "source_record_id", "Type": "string" },
{ "Name": "full_name", "Type": "string" },
{ "Name": "email", "Type": "string" },
{ "Name": "phone", "Type": "string" },
{ "Name": "address", "Type": "string" },
{ "Name": "city", "Type": "string" },
{ "Name": "email_key", "Type": "string" },
{ "Name": "phone_key", "Type": "string" },
{ "Name": "name_key", "Type": "string" },
{ "Name": "address_key", "Type": "string" },
{ "Name": "city_key", "Type": "string" }
]
}
}
6.2 lead_list 用のGlueテーブル定義を作成する
以下の内容で lead_list_table.json を作成してください。ただし StorageDescriptor.Locationを変更してください。
{
"Name": "lead_list",
"TableType": "EXTERNAL_TABLE",
"Parameters": {
"classification": "csv",
"skip.header.line.count": "1"
},
"StorageDescriptor": {
"Location": "s3://aws-deepcuts-er-{ACCOUNT_ID}-{YYYYMMDD}/input/lead_list/",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"SerdeInfo": {
"SerializationLibrary": "org.apache.hadoop.hive.serde2.OpenCSVSerde",
"Parameters": {
"separatorChar": ",",
"quoteChar": "\""
}
},
"Columns": [
{ "Name": "source_record_id", "Type": "string" },
{ "Name": "full_name", "Type": "string" },
{ "Name": "email", "Type": "string" },
{ "Name": "phone", "Type": "string" },
{ "Name": "address", "Type": "string" },
{ "Name": "city", "Type": "string" },
{ "Name": "email_key", "Type": "string" },
{ "Name": "phone_key", "Type": "string" },
{ "Name": "name_key", "Type": "string" },
{ "Name": "address_key", "Type": "string" },
{ "Name": "city_key", "Type": "string" }
]
}
}
6.3 Glueテーブルを作成する
aws glue create-table --database-name aws-deepcuts-er-glue-db --table-input file://registration_data_table.json --region ap-northeast-1
aws glue create-table --database-name aws-deepcuts-er-glue-db --table-input file://lead_list_table.json --region ap-northeast-1
6.4 Glueテーブルを確認する
aws glue get-tables --database-name aws-deepcuts-er-glue-db --region ap-northeast-1 --query 'TableList[].Name' --output table
以下のように表示されれば成功です。
-----------------------
| GetTables |
+---------------------+
| lead_list |
| registration_data |
+---------------------+
7. Schema mappingを作成する
AWS Entity Resolutionでは、入力テーブルのどの列を「名前」「メールアドレス」「電話番号」などとして扱うかをSchema mappingで定義します。Schema mappingではUnique ID列が必須で、Unique IDは単一テーブル内で一意である必要があります。今回はsource_record_idをUnique IDにします。AWS公式ドキュメントでは、Unique IDが未指定、一意でない、または不適切な場合、マッチングワークフロー実行時にレコードが拒否されると説明されています。([AWS ドキュメント][3])
7.1 生データ列とクレンジング済みキー列
今回のCSVは、生データ列に加えて、事前にクレンジングした「キー列」を持っています。
| 元列 | クレンジング済み列 | 例 |
|---|---|---|
email |
email_key |
Taro.Yamada@Example.com → taro.yamada@example.com
|
phone |
phone_key |
080-1111-2222 → 08011112222
|
full_name |
name_key |
YAMADA TARO → yamada taro
|
address |
address_key |
1-1-1 渋谷 / 1-1-1 Shibuya → 1-1-1-shibuya
|
city |
city_key |
東京 / Tokyo → tokyo
|
email_key、phone_key、name_key、address_key、city_keyは、Glue ETLやPythonなどで事前に作ったクレンジング済み列を想定しています。AWS Entity Resolution自体にもNormalize dataがありますが、メールの+promo除去、漢字/ローマ字変換、住所表記の統一まで万能にやってくれる前提にはしないほうが安全です。実務では、AWS Entity Resolutionの前にGlueなどで照合用キーを作る設計にしておくと、期待結果が安定します。
7.2 AWS Entity Resolutionコンソールを開く
ブラウザで以下を開きます。
https://console.aws.amazon.com/entityresolution/
右上のリージョンが東京リージョン(ap-northeast-1)になっていることを確認します。
7.3 Schema mappingの共通設定
customers_primary(registration_data用)とcustomers_secondary(lead_list用)の2つを作成します。両方とも、Input fieldは以下のように設定します。
| Input field | Attribute type | Match key name | 用途 |
|---|---|---|---|
source_record_id |
Unique ID | - | レコード識別子 |
full_name |
Full name | name_raw |
生データ比較用 |
email |
Email address | email_raw |
生データ比較用 |
phone |
Phone number | phone_raw |
生データ比較用 |
email_key |
Email address | email_key |
クレンジング済みメール |
phone_key |
Phone number | phone_key |
クレンジング済み電話番号 |
name_key |
Full name | name_key |
クレンジング済み氏名 |
address_key |
Full address | address_key |
クレンジング済み住所 |
city_key |
City | city_key |
クレンジング済み都市 |
address |
Pass through | - | 結果確認用 |
city |
Pass through | - | 結果確認用 |
Advanced rule type(Pattern 3, 4)でも使えるよう、各入力フィールドには一意のMatch key nameを割り当てます。Advanced rule typeでは、グループ化したフィールドを除き、同じMatch keyを複数フィールドで使えないためです。([AWS ドキュメント][7])
7.4 customers_primary(registration_data)を作成する
左メニューで Data preparation > Schema mappings を選び、右上の Create schema mapping を押します。
Step 1: Specify schema details で以下を入力します。
| 項目 | 入力値 |
|---|---|
| Schema mapping name | customers_primary |
| Description | Schema mapping for registration_data |
| Creation method | Import from AWS Glue |
| AWS Region | ap-northeast-1 |
| AWS Glue database | aws-deepcuts-er-glue-db |
| AWS Glue table | registration_data |
| Unique ID | source_record_id |
Input fields で、Matching fieldsとして full_name / email / phone / email_key / phone_key / name_key / address_key / city_key を選びます。Add columns for pass through をチェックし、Pass throughとして address / city を追加します。
Next を押し、Step 2: Map input fields で前掲の「Schema mappingの共通設定」表のとおりにAttribute typeとMatch key nameを設定します。Hashedはすべてチェックしません。
Step 3: Group data では何も変更せず Next、Step 4: Review and create で内容を確認して Create schema mapping を押します。
7.5 customers_secondary(lead_list)を作成する
再び Create schema mapping を押し、Step 1 で以下を入力します。
| 項目 | 入力値 |
|---|---|
| Schema mapping name | customers_secondary |
| Description | Schema mapping for lead_list |
| Creation method | Import from AWS Glue |
| AWS Region | ap-northeast-1 |
| AWS Glue database | aws-deepcuts-er-glue-db |
| AWS Glue table | lead_list |
| Unique ID | source_record_id |
以降のInput fields / Map input fields / Group dataの設定は、customers_primaryと同じです。Step 4 まで進めて Create schema mapping を押します。
8. 統合したい顧客(期待結果)を整理する
各パターンの結果を比較できるよう、最終的な業務上の期待結果を整理しておきます。
| 期待グループ | レコード | 顧客像 |
|---|---|---|
| M001 | A001, A005, A007, B001, B006, B009 | 山田太郎 / Taro Yamada |
| M002 | A002, A006, B002, B007 | 佐藤花子 / Hanako Sato |
| M003 | A003, B003, B010 | 鈴木一郎 / Ichiro Suzuki |
| M004 | A004, B004 | 田中次郎 / Jiro Tanaka |
| M005 | A008 | 単独顧客 |
| M006 | B005 | 単独顧客 |
| Review | B008 | 山田太郎っぽいが、自動統合は危険 |
B008はこのハンズオンの重要な教材です。
B008,Yamada T.,taro@example.com,08011112223,1-1-1 Shibuya,Tokyo
住所と都市は山田太郎系に近いですが、メールは弱く、電話番号も1桁違います。そのため、自動統合ではなくレビュー候補として扱うのが安全です。各パターンでこのB008がどう扱われるかに注目してください。
9. Pattern 1: Raw Exact Matching
9.1 目的
まずは、何もクレンジングしないとどこまでマッチするかを見るパターンです。「AWS Entity Resolutionを使えば何でも自動で名寄せできる」という誤解を防ぐための実験です。
9.2 ワークフロー設定
AWS Entity Resolutionコンソールの左メニューで Workflows > Matching を選び、Create matching workflow を押します。Step 1 のData inputには、registration_data(customers_primary)とlead_list(customers_secondary)の2つを設定します。以降の主な設定値は以下です。
| 項目 | 設定値 |
|---|---|
| Workflow name | er-handson-01-raw-exact |
| Matching method | Rule-based matching |
| Rule type | Simple |
| Processing cadence | Manual |
| Normalize data |
Off(推奨) |
| Output | s3://<BUCKET>/output/01-raw-exact/ |
Simple rule typeでは、Matching rulesでRule nameとMatch keysを設定します。([AWS ドキュメント][5])
9.3 Matching rules
| 優先度 | Rule name | Match keys | Comparison type |
|---|---|---|---|
| 1 | raw_exact_email |
email_raw |
Single input field |
| 2 | raw_exact_phone |
phone_raw |
Single input field |
設定後、Create and run でワークフローを作成・実行します。
9.4 期待結果
| グループ | レコード | 理由 |
|---|---|---|
| R001 | A001, B001, B006, A007, B009 | A001-B001はemail一致。A001/A007/B006/B009はphone一致 |
| R002 | A002, A006, B002, B007 | A002-B002はphone一致。A006-B002はemail一致。A002-B007はemail一致 |
| R003 | A003, B003, B010 | email/phone一致 |
| R004 | A004, B004 | phone一致 |
| R005 | A005 | 単独。email大小文字、phoneハイフンにより漏れる想定 |
| R006 | A008 | 単独 |
| R007 | B005 | 単独 |
| R008 | B008 | 単独 |
このパターンで見せたいのは、表記ゆれやクレンジング不足があると、本来同一人物でも漏れるということです。特にA005は山田太郎ですが、以下のように表記が違うためRaw Exactでは漏れます。
A001: taro.yamada@example.com, 08011112222
A005: Taro.Yamada@Example.com, 080-1111-2222
10. Pattern 2: Cleansed Exact Matching
10.1 目的
次に、クレンジング済みキー列を使うと、確実な一致を安定して拾えることを確認します。実務で最も使いやすい基本形です。
10.2 ワークフロー設定
| 項目 | 設定値 |
|---|---|
| Workflow name | er-handson-02-cleansed-exact |
| Matching method | Rule-based matching |
| Rule type | Simple |
| Processing cadence | Manual |
| Normalize data |
OffまたはOn(キー列を使うためどちらでもよい) |
| Output | s3://<BUCKET>/output/02-cleansed-exact/ |
10.3 Matching rules
| 優先度 | Rule name | Match keys | Comparison type |
|---|---|---|---|
| 1 | cleansed_exact_email |
email_key |
Single input field |
| 2 | cleansed_exact_phone |
phone_key |
Single input field |
10.4 期待結果
| グループ | レコード | 理由 |
|---|---|---|
| M001 | A001, A005, A007, B001, B006, B009 |
email_keyまたはphone_keyが一致 |
| M002 | A002, A006, B002, B007 | email/phoneのクレンジング済みキーを介して一致 |
| M003 | A003, B003, B010 | email/phone一致 |
| M004 | A004, B004 | phone一致 |
| M005 | A008 | 単独 |
| M006 | B005 | 単独 |
| M007 | B008 | 単独 |
この結果が、本ハンズオンの基本的な正解です。B008はまだ単独で、これは意図通りです。
B008:
name_key = yamada t
email_key = taro@example.com
phone_key = 08011112223
address_key = 1-1-1-shibuya
city_key = tokyo
住所と都市は近いですが、email/phoneが確定的に一致しないため、自動統合しません。
11. Pattern 3: Conservative Fuzzy Matching
11.1 目的
名前や住所の表記ゆれを少し許容します。ただし、誤統合を避けるため、ファジー条件だけではマッチさせません。AWS Entity ResolutionのAdvanced rule typeでは、Levenshtein、Cosine、Soundexなどの関数を使えますが、ファジー関数はExactまたはExactManyToManyとANDで組み合わせる必要があります。([AWS ドキュメント][7])
11.2 ワークフロー設定
| 項目 | 設定値 |
|---|---|
| Workflow name | er-handson-03-conservative-fuzzy |
| Matching method | Rule-based matching |
| Rule type | Advanced |
| Processing cadence | Manual |
| Normalize data |
OffまたはOn
|
| Output | s3://<BUCKET>/output/03-conservative-fuzzy/ |
11.3 Matching rules
| 優先度 | Rule name | Rule condition | 狙い |
|---|---|---|---|
| 1 | exact_email_key |
Exact(email_key, EmptyValues=Ignore) |
メール完全一致 |
| 2 | exact_phone_city |
Exact(phone_key, EmptyValues=Ignore) AND Exact(city_key, EmptyValues=Ignore) |
電話番号一致+都市一致 |
| 3 | same_address_similar_name |
Exact(address_key, EmptyValues=Ignore) AND Exact(city_key, EmptyValues=Ignore) AND Levenshtein(name_key, 2) |
同一住所・同一都市で名前が少し違う |
| 4 | same_phone_similar_name |
Exact(phone_key, EmptyValues=Ignore) AND Levenshtein(name_key, 2) |
電話番号一致で名前のtypoを許容 |
11.4 期待結果
| グループ | レコード | 理由 |
|---|---|---|
| M001 | A001, A005, A007, B001, B006, B009 | email/phone一致。名前・住所の揺れも補助 |
| M002 | A002, A006, B002, B007 | email/phone一致に加え、Hanako/Hana/Hanokoの揺れを吸収 |
| M003 | A003, B003, B010 | Ichiro/Ichirouの表記ゆれを吸収 |
| M004 | A004, B004 | phone一致 |
| M005 | A008 | 単独 |
| M006 | B005 | 単独 |
| M007 | B008 | 単独 |
Pattern 3でも、B008は単独にします。Yamada T.とYamada Taroは近いものの、メール不一致・電話番号1桁違いです。住所一致だけで自動統合すると危険だからです。つまりPattern 3は、顧客360の本番統合に近い、保守的な自動マッチングです。
12. Pattern 4: Review Candidate Matching
12.1 目的
このパターンでは、あえて条件を少し緩めて、自動統合してはいけないが、人間が確認すべき候補を拾います。本番運用では、このワークフローの結果をそのまま顧客マスタに反映しません。MatchRule = review_*のレコードだけを抽出して、レビュー用キューに回します。GetMatchId APIのレスポンスにはmatchIdだけでなく、どのルールにマッチしたかを示すmatchRuleも含まれます。ルール名を設計しておくと、後続処理で「自動統合」と「レビュー候補」を分けやすくなります。([AWS ドキュメント][6])
12.2 ワークフロー設定
| 項目 | 設定値 |
|---|---|
| Workflow name | er-handson-04-review-candidates |
| Matching method | Rule-based matching |
| Rule type | Advanced |
| Processing cadence | Manual |
| Normalize data |
OffまたはOn
|
| Output | s3://<BUCKET>/output/04-review-candidates/ |
12.3 Matching rules
| 優先度 | Rule name | Rule condition | 扱い |
|---|---|---|---|
| 1 | auto_exact_email_key |
Exact(email_key, EmptyValues=Ignore) |
自動統合OK |
| 2 | auto_exact_phone_city |
Exact(phone_key, EmptyValues=Ignore) AND Exact(city_key, EmptyValues=Ignore) |
自動統合OK |
| 3 | review_same_address_similar_name |
Exact(address_key, EmptyValues=Ignore) AND Exact(city_key, EmptyValues=Ignore) AND Cosine(name_key, 0.65, EmptyValues=Ignore) |
要レビュー |
| 4 | review_same_city_soundex_name |
Exact(city_key, EmptyValues=Ignore) AND Soundex(name_key, EmptyValues=Ignore) |
要レビュー |
12.4 期待結果
| グループ | レコード | 扱い |
|---|---|---|
| M001 | A001, A005, A007, B001, B006, B009 | 自動統合OK |
| M001候補 | B008 | 要レビュー |
| M002 | A002, A006, B002, B007 | 自動統合OK |
| M003 | A003, B003, B010 | 自動統合OK |
| M004 | A004, B004 | 自動統合OK |
| M005 | A008 | 単独 |
| M006 | B005 | 単独 |
Pattern 4では、B008が山田太郎グループの候補として拾われる可能性があります。ただし、記事では必ず次のように説明するのが安全です。
B008は「同一人物の可能性がある」だけであり、
自動でM001に統合すべきではない。
理由は以下です。
| 項目 | B008 | M001系 | 評価 |
|---|---|---|---|
| 名前 | Yamada T. | Yamada Taro / 山田太郎 | 近い |
| taro@example.com | taro.yamada@example.com 等 | 弱い | |
| phone | 08011112223 | 08011112222 | 1桁違い |
| address | 1-1-1 Shibuya | 1-1-1 Shibuya | 一致 |
| city | Tokyo | Tokyo | 一致 |
このようなレコードは、CRM統合や顧客360では非常に現実的です。緩いルールは「マッチ確定」ではなく「レビュー候補抽出」に使う、という設計が重要です。
13. Pattern 5: GetMatchId APIによるリアルタイム照合
13.1 目的
バッチでMatching workflowを実行したあと、新しく入ってきた顧客レコードが既存のどのMatch IDに属するかを同期的に確認します。GetMatchId APIは、ルールベースMatching workflowで処理済みのレコードに対して、対応するMatch IDを返します。リクエストではworkflowNameとrecordを渡し、レスポンスにはmatchIdとmatchRuleが含まれます。([AWS ドキュメント][6])
13.2 対象ワークフロー
まずはer-handson-02-cleansed-exactを使います。各ワークフローの Last job metrics の Status が Completed になってから実行してください。
13.3 API実行例1: 山田太郎系に一致
aws entityresolution get-match-id \
--workflow-name er-handson-02-cleansed-exact \
--apply-normalization \
--record '{
"email_key": "taro.yamada@example.com",
"phone_key": "08011112222",
"name_key": "taro yamada",
"city_key": "tokyo"
}' \
--region ap-northeast-1
期待結果です。
{
"matchId": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"matchRule": "cleansed_exact_email"
}
13.4 API実行例2: 佐藤花子系に一致
aws entityresolution get-match-id \
--workflow-name er-handson-02-cleansed-exact \
--apply-normalization \
--record '{
"email_key": "h.sato@example.com",
"phone_key": "09022223333",
"name_key": "hanako sato",
"city_key": "osaka"
}' \
--region ap-northeast-1
期待結果です。
{
"matchId": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"matchRule": "cleansed_exact_email"
}
13.5 API実行例3: B008相当の曖昧レコード
aws entityresolution get-match-id \
--workflow-name er-handson-02-cleansed-exact \
--apply-normalization \
--record '{
"email_key": "taro@example.com",
"phone_key": "08011112223",
"name_key": "yamada t",
"address_key": "1-1-1-shibuya",
"city_key": "tokyo"
}' \
--region ap-northeast-1
Pattern 2(er-handson-02-cleansed-exact)に対しては、期待結果は「既存Match IDなし」です。一方、Pattern 4のレビュー候補ワークフロー(er-handson-04-review-candidates)に対して実行した場合は、以下のような結果になる可能性があります。
{
"matchId": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"matchRule": "review_same_address_similar_name"
}
このmatchRuleを見て、後続処理で以下のように分岐します。
auto_* ルール:
自動統合してよい
review_* ルール:
顧客マスタには反映せず、人手レビューに回す
14. 全パターンの結果まとめ
| Pattern | Workflow | 目的 | M001 山田太郎 | M002 佐藤花子 | M003 鈴木一郎 | M004 田中次郎 | B008 |
|---|---|---|---|---|---|---|---|
| 1 | 01-raw-exact |
生データ完全一致の限界を見る | A005が漏れる | 統合される | 統合される | 統合される | 単独 |
| 2 | 02-cleansed-exact |
本番基本形。確実な一致だけ拾う | 統合される | 統合される | 統合される | 統合される | 単独 |
| 3 | 03-conservative-fuzzy |
表記ゆれを少し吸収する | 統合される | 統合される | 統合される | 統合される | 単独 |
| 4 | 04-review-candidates |
人手確認候補も拾う | 統合される | 統合される | 統合される | 統合される | M001候補 |
| 5 | GetMatchId |
新規レコードをリアルタイム照合 | 既存Match IDを返す | 既存Match IDを返す | 既存Match IDを返す | 既存Match IDを返す | ワークフロー次第 |
15. 記事での説明方針
この流れにすると腹落ちしやすいです。
1. Raw Exactでやる
→ 思ったより漏れる。クレンジングが必要だと分かる。
2. Cleansed Exactでやる
→ 顧客360の基本グループがきれいに作れる。
3. Conservative Fuzzyでやる
→ typoや表記ゆれにも少し強くなる。
4. Review Candidateでやる
→ B008のような「似ているが危険」な候補を拾える。
5. GetMatchIdでやる
→ バッチ統合済みの顧客360に対して、新規流入レコードを即時照合できる。
最終的なメッセージは、こうです。
AWS Entity Resolutionは「全部いい感じに自動統合する魔法」ではない。
むしろ、確実な一致・曖昧な一致・人手確認候補を、
ワークフローとルールで分離できるところに価値がある。
16. 後片付け
検証後は課金や不要リソースを避けるため、以下を実行します。
16.1 AWS Entity Resolutionリソースを削除する
for wf in ${WORKFLOW_01} ${WORKFLOW_02} ${WORKFLOW_03} ${WORKFLOW_04}; do
aws entityresolution delete-matching-workflow \
--workflow-name ${wf} \
--region ap-northeast-1
done
aws entityresolution delete-schema-mapping \
--schema-name ${SCHEMA_PRIMARY} \
--region ap-northeast-1
aws entityresolution delete-schema-mapping \
--schema-name ${SCHEMA_SECONDARY} \
--region ap-northeast-1
16.2 GlueテーブルとGlueデータベースを削除する
aws glue delete-table \
--database-name aws-deepcuts-er-glue-db \
--name registration_data \
--region ap-northeast-1
aws glue delete-table \
--database-name aws-deepcuts-er-glue-db \
--name lead_list \
--region ap-northeast-1
aws glue delete-database \
--name aws-deepcuts-er-glue-db \
--region ap-northeast-1
16.3 S3バケットを空にして削除する
{YYYYMMDD} を変更してください。
aws s3 rm s3://aws-deepcuts-er-$(aws sts get-caller-identity --query Account --output text)-{YYYYMMDD} --recursive --region ap-northeast-1
aws s3 rb s3://aws-deepcuts-er-$(aws sts get-caller-identity --query Account --output text)-{YYYYMMDD} --region ap-northeast-1
16.4 ローカルファイルを削除する
rm -f registration_data.csv lead_list.csv db.json registration_data_table.json lead_list_table.json
これでハンズオン用リソースの削除は完了です。
✅ ベストプラクティス
- 前処理の徹底 – データを揃え、欠損値を補完することでマッチ精度が向上します。
- コスト管理 – 課金は処理レコード数に比例するため、不要なレコードを含めないようにフィルタリングしましょう3。
- プライバシー保護 – 個人情報は可能な限りハッシュ化・暗号化し、アクセス制御やKMSキーの運用を徹底します3。
まとめ
AWS Entity Resolutionは、データの重複や表記ゆれに悩む企業にとって強力なソリューションです。プリセット済みのアルゴリズムと柔軟なルール設定により、データ統合の手間を大幅に削減し、Customer 360や不正検知など多様なユースケースに活用できます3。日本語情報が少ない今こそ、ぜひこのサービスを試して記事や事例をシェアしてみてください。この記事がその第一歩になれば幸いです。
-
AWS Entity Resolution | AWS re:Post
https://repost.aws/questions/QUoNOxleL_Q3eFejpdnGBL6Q/aws-entity-resolution ↩ -
The Power of Entity Resolution
https://www.bigdatatheory.com/2024/06/the-power-of-entity-resolution.html ↩ -
AWS Entity Resolution
https://tutorialsdojo.com/aws-entity-resolution/ ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 -
AWS Entity Resolution: Streamlining Data Matching and Linking Across Systems
https://www.linkedin.com/pulse/aws-entity-resolution-streamlining-data-matching-joseph-sibychen--t8llc ↩ -
https://docs.aws.amazon.com/entityresolution/latest/userguide/what-is-service.html "What is AWS Entity Resolution? - AWS Entity Resolution"
[2]: https://docs.aws.amazon.com/entityresolution/latest/userguide/creating-matching-workflow-rule-based.html "Creating a rule-based matching workflow - AWS Entity Resolution"
[3]: https://docs.aws.amazon.com/entityresolution/latest/userguide/create-schema-mapping.html "Creating a schema mapping - AWS Entity Resolution"
[4]: https://docs.aws.amazon.com/entityresolution/latest/userguide/create-matching-workflow.html "Match input data using a matching workflow - AWS Entity Resolution"
[5]: https://docs.aws.amazon.com/entityresolution/latest/userguide/rule-based-mw-simple.html "Creating a rule-based matching workflow with the Simple rule type - AWS Entity Resolution"
[6]: https://docs.aws.amazon.com/entityresolution/latest/apireference/API_GetMatchId.html "GetMatchId - AWS Entity Resolution"
[7]: https://docs.aws.amazon.com/entityresolution/latest/userguide/rule-based-mw-advanced.html "Creating a rule-based matching workflow with the Advanced rule type - AWS Entity Resolution" ↩