スキル1.2.2
柔軟なアーキテクチャパターンを作成し、コードを変更せずに動的なモデル選択とプロバイダーの切り替えができるようにする (AWS Lambda、Amazon API Gateway、AWS AppConfigの使用など)。
GAABは“任意のモデルプロバイダー / ナレッジベース / メモリタイプ” を差し替え可能な設計となっており、「コード変更なしでプロバイダー切り替えできる柔軟性」を実現するサンプルとして適切。方針としてはDynamoDBにLLMのアクセス先情報を登録し、LLM呼び出しに際してDynameDBから情報を選択。
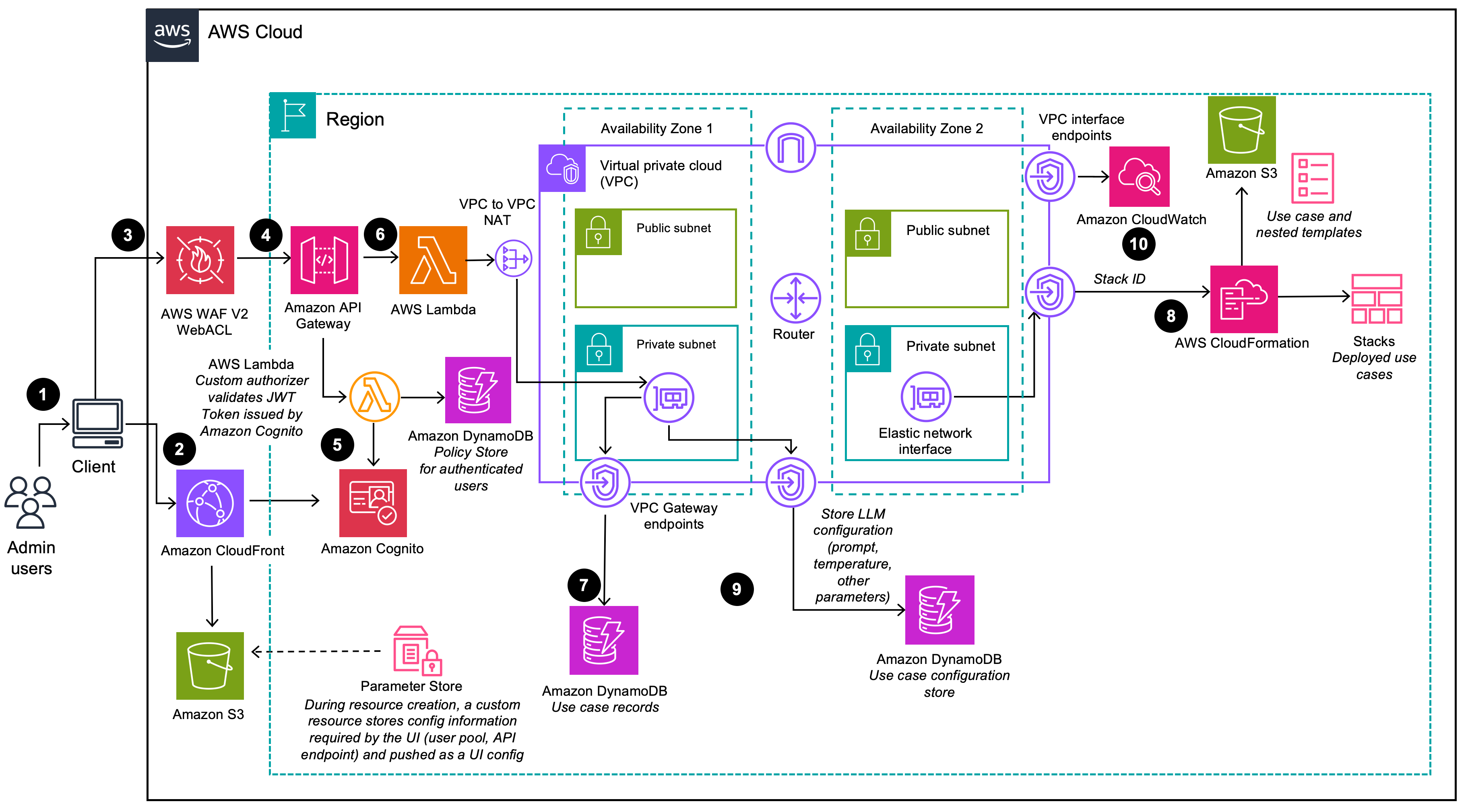
(9)にて、デプロイウィザードで管理者ユーザーが提供するすべての LLM 設定オプションは、DynamoDB に保存されます。デプロイでは、この DynamoDB テーブルを使用して、実行時に LLM を設定します。
具体的なユースケースは以下の通り。
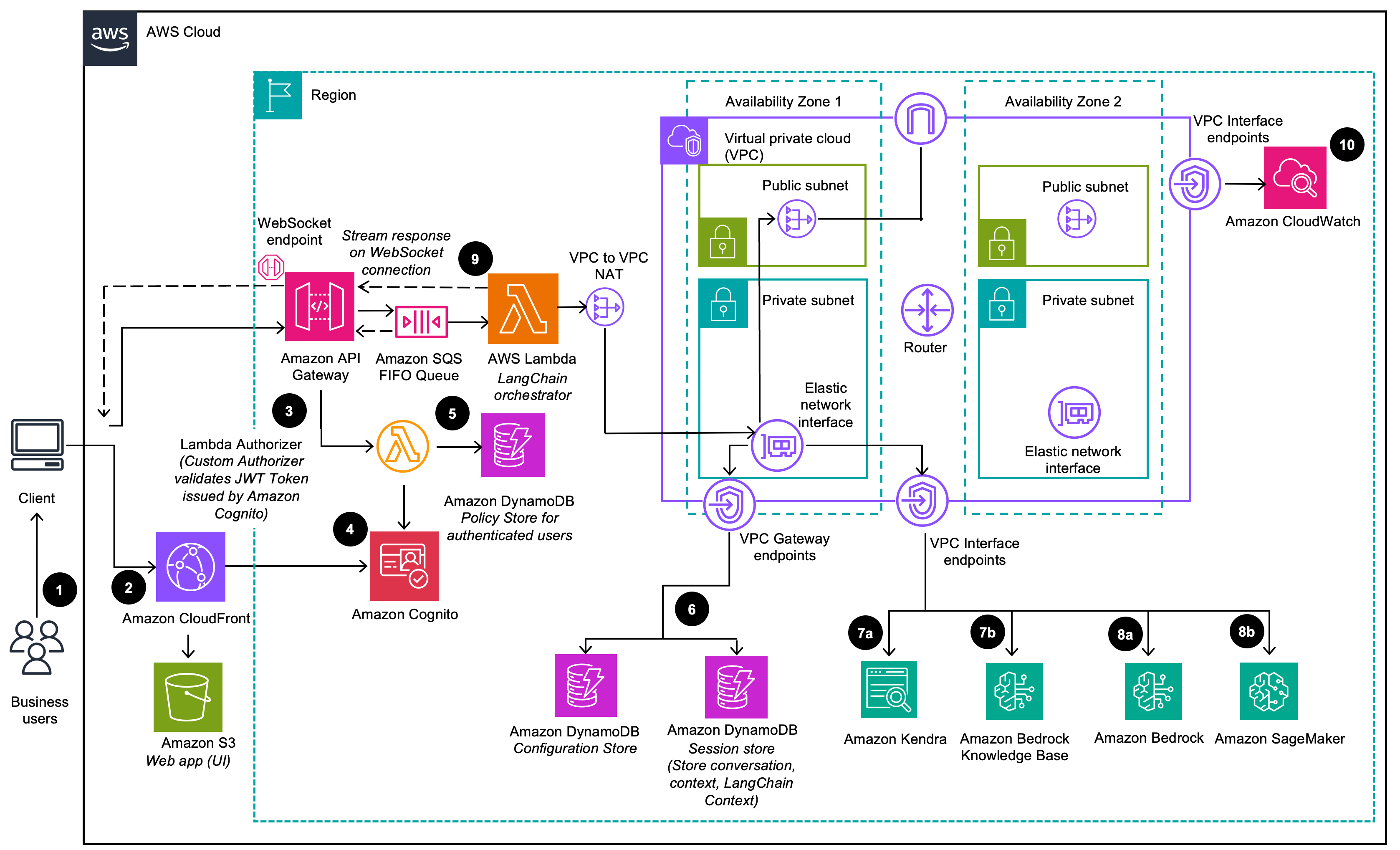
(6)にてDynamoDBからLLMオプションの情報を取得し、(8)でそのLLMにアクセスしています。
-
AWS AppConfigでフィーチャーフラグと自由形式の構成データを作成する
AWS AppConfigとは、AWS Systems Managerの機能の一つ。専用のLambda Extensionが提供されており、Lambdaを利用するとより簡単にAppConfigを活用できる。feature flagのローカルキャッシュなどの実装が省略できる。 -
AWS AppConfig にコンテキストに基づいてフラグ値を分けることができるマルチバリアントフラグが登場したので Lambda から使ってみた
ブログタイトルの通り。
スキル1.2.3
耐障害性の高い AIシステムを設計し、サービス中断中も継続的に運用できるようにする (AWS Step Functionsサーキットブレーカーパターン、リージョンの可用性が限られているモデルに対する Amazon Bedrockクロスリージョン推論、クロスリージョンモデルのデプロイ、グレースフルデグラデーション戦略の使用など)。
レジリエントなAIエージェント構築には以下の戦略が必要。
- 障害の隔離:各コンポーネントの境界で検証を行い、障害をシステム全体のワークフローから隔離する
- キャパシティプランニング:リクエスト毎分(RPM)とトークン毎分(TPM)を推定。

- SLOメトリクス設定:レイテンシを増大させない。不必要な推論ループを減らすようなプロンプトエンジニアリングやプロンプトキャッシングも有効。
- 決定論的オーケストレーション:ワークフローを明示的に定義しないと、LLMのミスやハルシネーションの影響を大きく受ける。
- 冗長性の確保:単一障害点を最小限に抑える
Graceful Degradationとは、「優美な劣化」と訳される設計思想で、システムが何らかの不具合や負荷によって機能が制限された場合に、完全に停止するのではなく、最低限の機能を維持し続けることです。障害が発生した場合も、致命的な障害を防ぎ、サービス全体の停止を避けることを目指します。
- Amazon Bedrock でクロスリージョン推論のサポートを開始
- クロスリージョン推論によるスループットの向上
-
Amazon Bedrockでのクロスリージョン推論の始め方
クロスリージョン推論を使用することで、オンデマンドモードを使用する Bedrock のお客様は、より高いスループット制限 (割り当てられたリージョン内のクォータの最大 2 倍) を得ることができ、需要のピーク時にレジリエンスを強化できます。
顧客は、事前に定義された一連のリージョンから選択することで推論データのフローを制御でき、適用されるデータレジデンシー要件と主権法に準拠できるようになります。
クロスリージョン推論を使用しても追加のルーティングコストは発生せず、リクエストを行ったリージョン (ソースリージョン) に基づいて請求されます。
スキル1.2.4
FMカスタマイズデプロイとライフサイクル管理を実装する [Amazon SageMaker AIを使用したドメイン固有のファインチューニングされたモデルのデプロイ、モデルデプロイのための低ランク適応 (LoRA) やアダプターなどパラメータ効率の高い適応手法、SageMaker Model Registryを使用したバージョニングとカスタマイズ済みモデルのデプロイ、自動デプロイパイプラインを使用したモデルの更新、デプロイが失敗した場合のロールバック戦略、モデルの廃止と交換のためのライフサイクル管理の使用など]。
- Llama2とAmazon SageMakerを使用したLoRAファインチューニングモデルのモデル管理
- SageMakerの効率的なマルチアダプター推論を使用して、数百のLoRAアダプターを簡単に展開および管理できます。
- Amazon SageMaker AIにおける高度なファインチューニング手法
- 無料のノートブックサービス SageMaker Studio Lab で 日本語 LLM を Fine-Tuning する
PEFTアプローチの例)
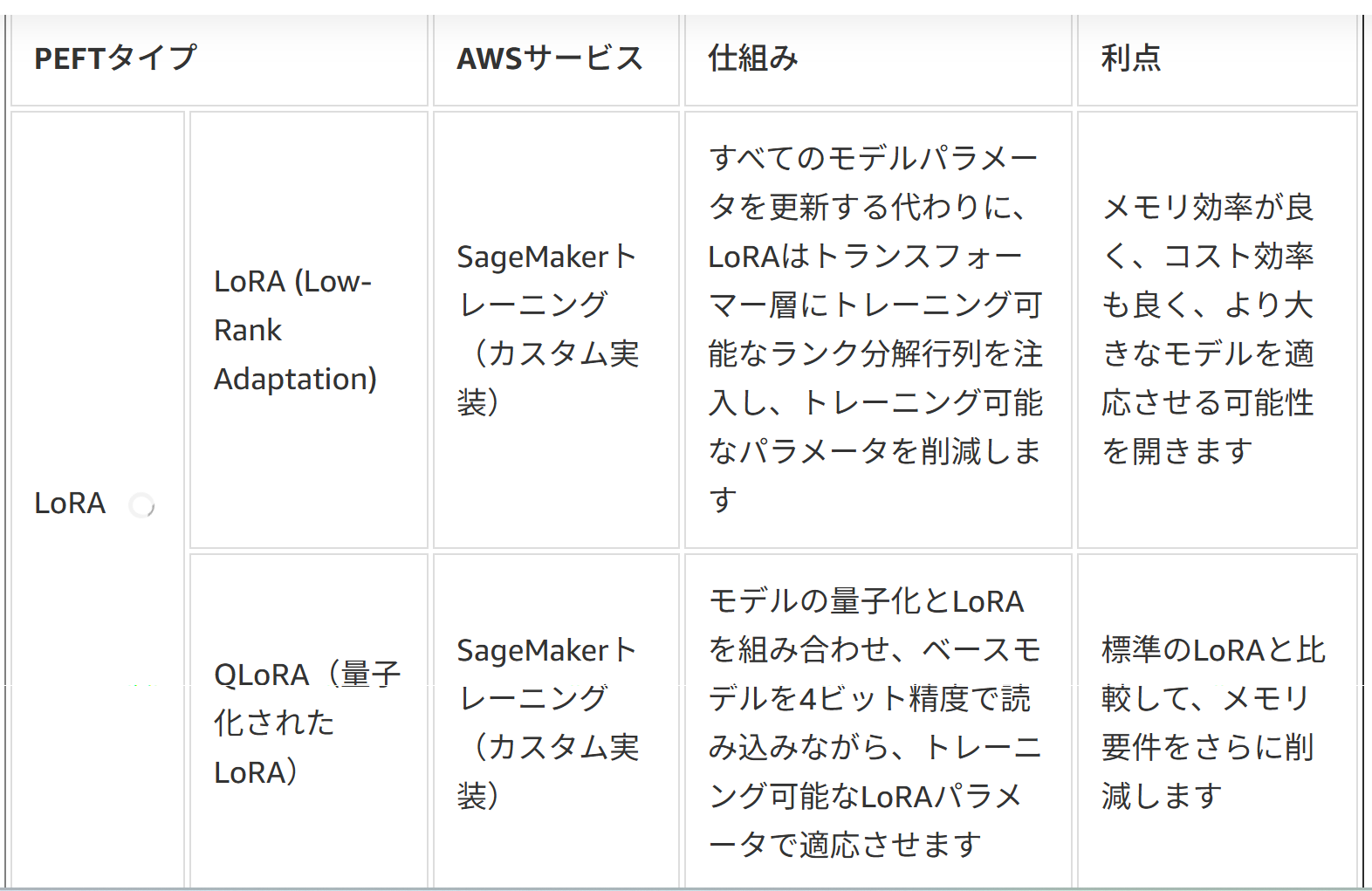
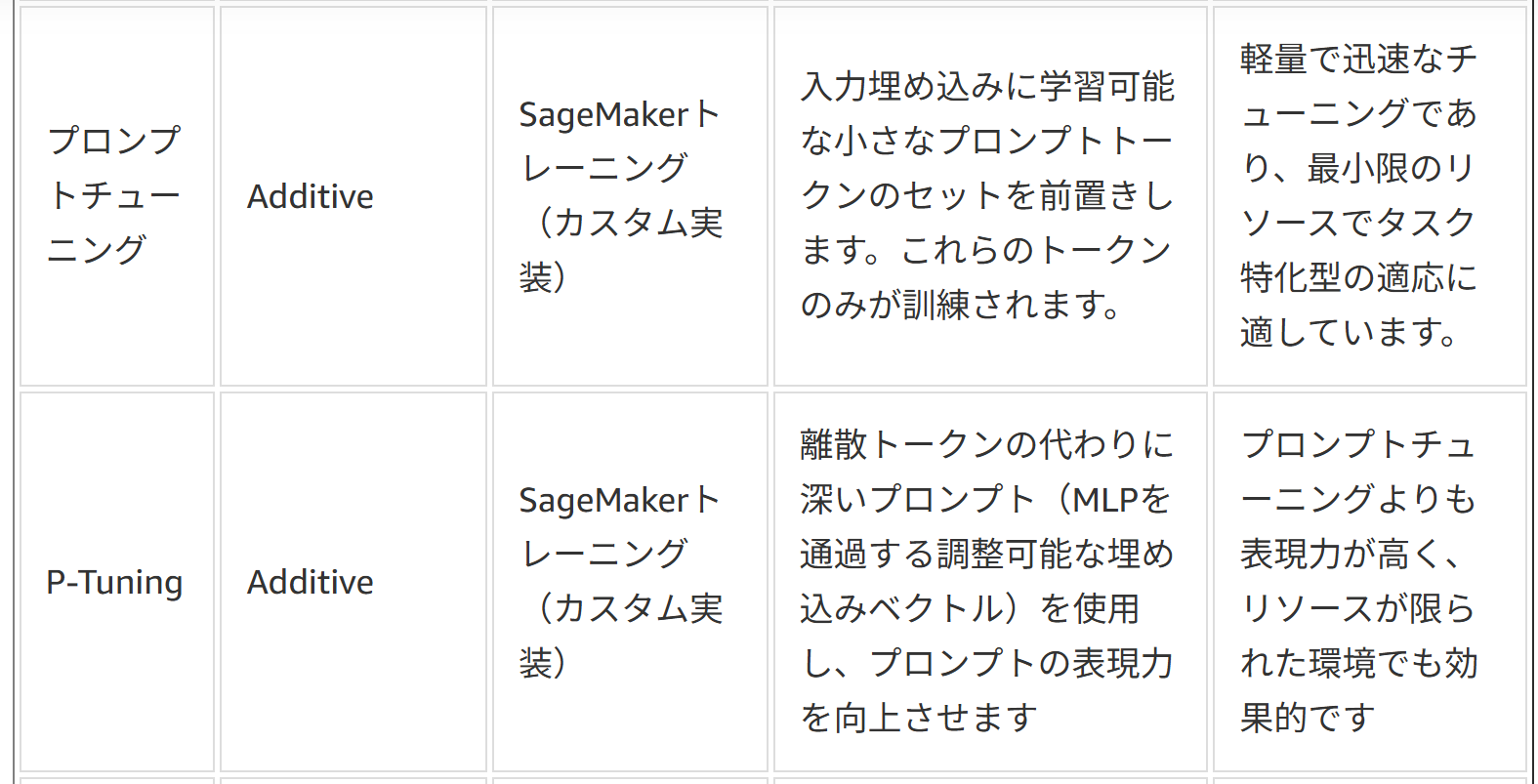

LoRAは多言語適応やドメイン適用、プロンプトチューニングはSaaSのテナント分離、P-tuningは複雑または小規模なモデルに、それぞれ効果的である。
プレフィックスチューニングはtransformerの各アテンション層で学習可能なベクトル(プレフィックス)を追加する。