この記事は,ドコモSI部 アドベントカレンダー10日目の記事になります。
今回の記事では今年の夏に出張したKDD2018について,特に強化学習ハンズオンとKDD Cupを中心に書いていきたいと思います。
※下記リンクから飛べば記事のつまみ食いができます🍔
概要
KDDは今年で24回目を数える,データマイニング関連の学術会議です。今年は8/19〜8/23の期間で,イギリスのロンドンで開催されました。
参加者,採択論文数ともに過去最大となり,一層の盛り上がりを見せています。

会議は特定の分野の基本事項から最先端研究までを概観するチュートリアル,各分野の最先端な研究発表が行われる本会議,参加者が手を動かしながら基本事項を学ぶハンズオンから構成されています。またイベントとして,特に深層学習分野での各種基調講演が行われるDeep Learning Dayや,与えられたお題に対して長期間に渡ってモデル作成を行いその精度を競い合うKDD Cupなどが催されています。
ドコモSI部では例年,KDD本会議と併催されるKDD Cupに参加しています。また解法やデータサイエンスに関わる最先端手法の調査を行うために現地出張も行っており,私は初日のチュートリアルから本会議最終日まで全ての日程に参加させて頂きました。
この記事では冒頭にも書いた通り,この中でも特に強化学習ハンズオンとKDD Cupを中心に紹介していきたいと思います。
強化学習ハンズオン:Reinforcement learning with Ray
私が参加した強化学習ハンズオン, Reinforcement learning with Rayは,講義と演習形式で強化学習の基礎を学び,最後に分散処理を行うためのライブラリであるRayを学ぶハンズオンでした。以下では簡単にハンズオンの内容+αで強化学習の紹介を行ったあと,rayのチュートリアルを行いたいと思います。ちなみに当日のハンズオンで利用されたスライドやコードは,全て下記のGithubにあがっています。
強化学習とは?
強化学習はある環境内にいる行動の主体(エージェント)が現在の状態を観測し,どのような行動をとれば得られる報酬を最大化できるか決定していく機械学習の枠組みです。最近では深層学習の流れの中で古典的に扱われていたQ学習などが発展した深層強化学習が研究され,工場機械や自動運転車,さらにはマーケティング分野でも応用されはじめています。
強化学習では一般に,マルコフ決定過程(Markov Dicision Process; MDP)に従い状態が遷移していきます。例えばいま$S$を状態,$A$を行動,$t$を時間ステップとして,状態$s$のときに行動$a$をとることで状態$s'$へ遷移する確率$P_{ss'}^a$を
$$P_{ss'}^a= {\rm P}[S_{t+1} | S_t = s, A_t = a]$$
とし,また行動$a$をとったときに得られる報酬$R_s^a$を
$$R_s^a = E[R_{t+1} | S_t = s, A_t = a]$$
とします。これらと報酬に対する割引率$\gamma$の組$<S,A,P,R,\gamma>$をもってマルコフ決定過程を定めます。また,ある状態$s$に対してどのような行動をとるかは方策$\pi$によって定められ
$$\pi(a|s) = {\rm P}[A_t = a | S_t = s]$$
で記述されます。以上を基本事項として,強化学習ではエージェントが環境の状態を観測して行動を起こし,その結果として報酬を受け取りながら状態遷移をしていくことになります。
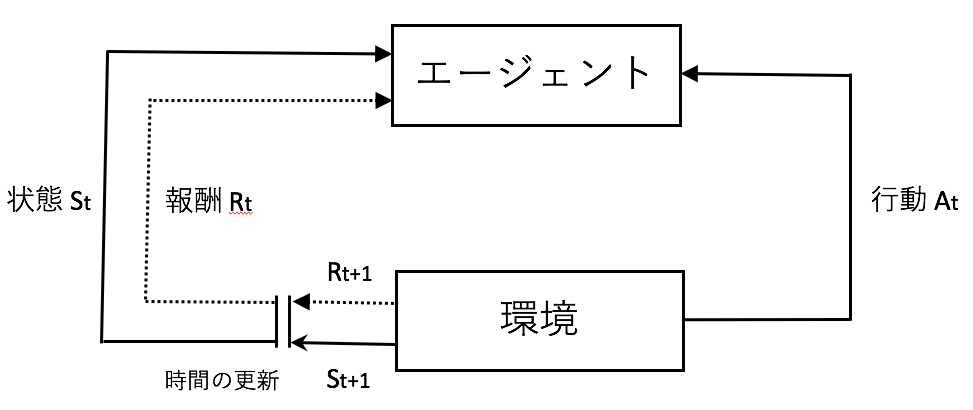
ここで強化学習の学習の仕方には,大きく3つ存在しています。ひとつが方策ベースな手法,ひとつが価値ベースな手法,最後がモデルベースな手法です。ここでは特に価値ベースな手法である価値反復法について紹介します。
価値反復法(Q-learning)
価値反復法はある状態sのときに$s$ある行動$a$をとり,方策$\pi$に従って時間発展したときに期待される割引報酬和$Q_{\pi}(s,a)$を最大化するように方策を探し出す方法です。すなわち,
$$
Q_{\pi}(s, a) =E_{\pi}\bigr[\sum_{\begin{array}{c}0\leq j \leq N\end{array}}\gamma^tR_{t+1}\bigl|s, a]
$$
を最大化します。ここでこの割引報酬和を一般に行動価値関数と呼びます。ここで我々の目標は,全ての$(s,a)$の組のもとで最適な方策$\pi^$をとったときの割引報酬和の期待値を求めることになります。このときの行動価値関数を最適行動価値関数と呼び$Q^(s,a)$と書きます。価値反復法ではこの最適行動価値関数を,次のような式に従って更新しながら近似的に求めていきます。
$$Q(s,a) \gets Q(s,a)+Q(s,a)+\alpha (r+\gamma {\rm max_{a'}Q(s', a')-Q(s,a)})$$
以上の枠組みは特にQ-learningと呼ばれ,強化学習では古典的に扱われてきた手法になります。
DQN
Q-learningでは全ての$(s,a)$の組に対して割引報酬和の期待値を求めることでしたが,状態$s$の数が高次元になるとすぐにこの組数(状態数)は爆発してしまいます。例えば強化学習でよく扱われるAtariのようなゲームでは,ゲームの画面の各マスが1つの状態に対応します。このとき1辺が10マス,各マスで取れる行動が境界を無視した上下左右の4つとして状態数は$2^{200}$となり非常に膨大となります。この膨大な状態数の下で最適行動価値関数を関数近似により求める際に深層学習を使ったものがDeep Q-Networkになります。
ray:AIのための分散システム
rayはpythonで利用可能な分散処理を行うためのライブラリです。特にその中のRLlibは,先ほどのDQNの他にもPPO, A2Cなどの強化学習アルゴリズムが実装されています。更にそれらの学習を分散処理させながら実行できます。ライブラリはpipによるインストール可能です。
pip install ray
また強化学習では学習の過程でシミュレーションを行うための環境を必要とします。ここではよく使われるopenAIのGymを利用します。こちらもpipでインストール可能です。
pip install gym
Gymのチュートリアルでも特に有名なものにCartPole問題があります。この問題では台車(cart)の上に棒(pole)が立っており,これが倒れないように台車を右または左に動かして倒れないようにする問題です。棒が直立している時間のタイムステップごとに報酬が1ずつ加算されるようになっていて,それを最大化することが目的になります。
非常に簡単ですが,これをrayで実装されているDQNを使って取り組んでみます。
import gym
import ray
from ray.rllib.agents.dqn import DQNAgent, DEFAULT_CONFIG
config = DEFAULT_CONFIG.copy()
config['num_workers'] = 5
ray.init()
agent = DQNAgent(config, 'CartPole-v0')
result = agent.train()
print(result)
rayのモジュールであるdqnからDQNAgentとDEFAULT_CONFIGを呼び出しています。前者はDQNアルゴリズムにおけるエージェント,configの中でワーカーの数を表すnum_workersを5として,CartPole問題をエージェントに学習させます。このコードを実行すると,下記のようなアウトプットがjson形式で得られます(長いので前半のみ記載)。
{'episode_reward_max': 69.0, 'episode_reward_min': 8.0, 'episode_reward_mean': 22.55, 'episode_len_mean': 22.55, 'episodes_this_iter': 40, 'policy_reward_mean': {}, 'custom_metrics': {}, 'num_metric_batches_dropped': 0, 'timesteps_this_iter': 1000, 'info': ...
学習の過程で報酬の最大最小や平均が格納されているのが分かります。
今回の計算はCPU上で動いていますが,htopコマンドで分散処理されていることが確認できました。
<実行前>
<実行中>
KDD cup Workshop
KDD Cupは例年KDDの本会議と併催されるコンペティションです。今回のKDD Cupのお題は北京とロンドンの大気汚染を1ヶ月間予測するというもので,まだ誰も知らない結果を予測し,日々スコアが更新されていくようなコンペティションでした。今年は中国のコンペサイト,biendataにて開催されました。
| 項目 | 内容 |
|---|---|
| 予測ターゲット | PM2.5, PM10, O3 |
| 予測対象期間 | 毎日翌日以降48時間 |
| 予測地点 | 北京35地点,ロンドン13地点 |
| 評価 | 毎日算出されるSMAPEのうちベスト25日分の平均値 |
| 提供されるデータ | 天候データ,大気汚染観測データ |
| 外部データの利用 | 利用可能。ただし,本評価期間開始前にフォーラムに投稿しなければならない。 |
スコアの評価はSMAPEと呼ばれる指標で行われました。SMAPEは$t$を時刻,$A_t$を時刻$t$での正解値,$F_t$を時刻$t$での予測値として,下記の数式で表されるもので,外れ値に対して頑健な評価指標になります。
$$SMAPE = \frac{1}{n}\sum^{n}_{t = 1}\frac{F_t - A_t}{(F_t+A_t)/2}$$
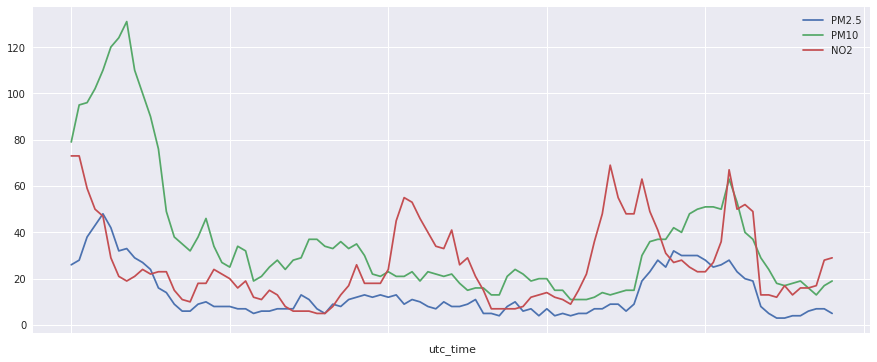
また時系列の実際のダイナミクスは下記のグラフのようになります。2018-02-01 00:00:00から2018-02-05 00:00:00までを横軸にとって,縦軸に各汚染物質の濃度をとってプロットしています。非周期性が強いことがわかります。
今回ドコモからは2チームが参加していました。私が所属していたチームはあまり上位には行けませんでしたが,今回のコンペを通して多くの知見が得られたように思います。チームメンバーの方々が提案して下さったアプローチ手法をいくつか紹介します。
- t-SNEを用いた天候情報の圧縮:t-SNEは高次元の情報を低次元(特に2次元)の空間に圧縮する手法です。私たちのチームでは,この手法を天候に関するグローバルな場の情報を特徴量化するための手法として利用しました。具体的にはある時刻での各観測地点での天候情報をカラム方向に保持した上でMulticoreTSNEというライブラリを用い2次元に圧縮して特徴量として用いました。
- 外部データの予測値サイト活用:今回外部データが利用可能だったのですが,「コンペのお題と同じように,PM2.5などの汚染の予測をしているサイトの情報を活用してみては?」というアイディアから,私たちのチームでは予測値サイトをスクレイピングし活用するということをしました。ただし,具体的な値ではなく汚染度がヒートマップ表示されるようなサイトであったため,beautifulsoupでカラーコードを取得し,汚染値を相対的な値として取得しました。
- ドメイン知識を意識した特徴量作成:一般的な話ですが,風向情報などはそのまま特徴量として放り込んだとしても数値情報でなく適切にワークしてくれません。私たちのチームではこれをsin, cos化した上で特徴量として利用し,機械学習の中でワークするように工夫しました。
ちなみに私が所属していたチームは,毎日手でサブミットを行なっていました。
#リアルタイム手サブは正直苦行だった。
上位陣のアプローチ
ここからは上位陣の手法を見ていきます。今回のコンペ上位の面々は次の通りでした。

特に上位3チームについて,発表内容をベースに手法を見ていきたいと思います。
1位 First Floor To Eat Latiao(Beijing University of Posts and Telecommunications)
1位は北京都電大学によるチーム,First Floor To Eat Latiaoでした。
彼らは今回の発表では空間,時間,ドメイン知識の3カテゴリからなる特徴量を大量に作成したことに特に重きをおいていました。
例えば時間に着目した特徴量としては天候の予測に関する特徴量を作成し,空間に着目した特徴量としては方向依存性のない特徴量(気温,湿度など)と方向依存性のある特徴量(風向や風速など)を意識して作成したということです。またドメイン知識を用いた特徴量としては日照時間に関する特徴量などを作成しています。
ちなみに,彼らは学習器としては基本LightGBMしか利用していませんでした(ポスターではSeq2Seq系アルゴリズムに関しての言及もありましたが,オーラルの発表時にはLightGBMによる学習しか言及していなかった)。相変わらずXGBoostなりLightGBMなりの構造化されたデータのコンペでの強さは圧倒的ですね💪
2位 getmax(Peking University)
2位となったのは北京大学のGetmaxチームです。今回のコンペでは予測困難な日の汚染をあてたり,最後の10日間で評価したときに良い成績を残したりしたチームには特別賞が与えられたのですが,彼らはそういった賞を総なめで1位をとり,First Floor To Eat Latiao よりも高額の賞金を手にする結果となっていました。実際彼らのチームとしての実績は輝かしく,KDD Cup2017で1位,KaggleのOutbrain Click Predictionでも1位,……と様々な大会でトップの座についてきた経歴があります。
彼らのモデリングでは,GBDTとしてはLightGBMを用い,ニューラルネットの手法としてはembedding層やdense層を重ねたDNNとGRUからなるRNNを用いていました。ちなみに前者のネットワークにおける活性化関数としては,swishの亜種であるb-swish $x\cdot {\rm sigmoid}(bx)$を用いたらしいです。これら3つのモデルをスタッキングし,高スコアを叩き出していました。
3位 ReadyPlayerOne (Cortexlabs)
3位はCortexlabsのReadyPlayerOneでした。今回のコンペでは大なり小なりの欠損期間が存在していましたが,彼らは欠損量の過多によって線形補完を行うかXGBoostを用いた穴埋めをするかを切り分けていて,前処理が丁寧に感じられました。
モデルとしてはXGBoostとExtratreeRegression,LightGBMを用い,これらのモデルをアンサンブルしたものをsubmitしていました。
※ ちなみにチーム名のready Player Oneは環境汚染などで荒廃した世界を描いたスピルバーグ監督によるSF作品ですが,コンペのテーマと掛け合わせたのですかね。
まとめ
今回のKDD Cupでは全体的に,うまく外部データ等を用いてデータをクリーニングできたチームや,ドメイン知識を活用して特徴量作成できたチームが上位に食い込んでいたように思います。とはいえ,データの構造としては時系列データなので,Seq2Seq系の深層学習手法が上位の手法として用いられていたのも頷けて,これから構造化データ扱ったコンペであっても,深層学習を適用することが主流になっていく気がします。
全体のまとめ
今回は様々なトピックがある中で,学術系で無い方々にも興味を持って頂けそうなハンズオンとコンペティションについて中心に書きました。会議全体を通しては今回中心的に取り上げた内容以外にも,GraphやEmbeddingの話が盛り上がっていました。特にGraph関連の研究はKDDでは伝統的に盛んなようですが,今回は深層学習と絡めた研究が目立っていたように思います。これからもデータマイニング領域の研究開発が盛り上がっていくといいですね👍
付録
最後にプログラミングと関係ないですが,KDD2018のよもやま話を少し書きます📃
ご飯事情
今回の会場は市街地から少し離れたExCeL Londonという場所で行われました。施設内にはもちろん飲食店はありましたが,主催者側がKDD Lunchと称してお昼ご飯を準備してくれることも多かったです。菜食主義者の方に配慮してか,お肉を抜いた料理がいくつか提供されました。
一方で全体的に冷たい料理が多かったので,主催者が来年以降は温かい料理を出すとClosing Sessionで名言していました。期待🙌

登録事情
参加者は参加証を受け取るために初参加日に登録を行うのですが,初日に会場に着くと長蛇の列!スタッフに聞くと「GDPRの許諾のために時間がかかっている」ということでした。EU一般データ規則,通称GDPRは欧州経済領域から個人データの移転を本人の同意なくしては禁止するというものですが,これがボトルネックとなって登録に時間がかかるとは…… 来年はもっとスムーズに登録が進むと良いですね🤓
