インフラ設計入門(前編) の続き。
前回の記事の最後に以下のようなことを書いている。
- アプリとサーバーが密結合
- アプリとロードバランサーが密結合
これらの課題を明らかにし、 コンテナ や コンテナオーケストレーター 、ついでに IaC の話につなげる。
サーバーにアプリを直接インストールして動かすことの課題
アプリケーションをサーバーで動かすことを考える。例えば AWS の EC2 やさくらの VPS サーバーを借りてるとする。
具体的にサーバーでアプリケーションをどのようにして動かすか?
最初に思いつく方法は、ローカルで動かしている方法をそのままサーバー上で実現することである。
例えば Python の場合
- 然るべき Python のバージョンをサーバーにインストール
- 然るべきライブラリを
pip install -r requirements.txtなどでインストール -
python main.pyなどを実行して動かす
といった作業を最低限行う必要がある。
実際はそれだけではない。アプリケーションにあわせてサーバーそのもののセッティングも変えなければならない。
- ログファイルにログを書き出し続けるとディスクが逼迫するので、ログローテートを正しくセットする
- リクエストを受けられるように、特定のポートを開く。サーバーに侵入されては困るのでそれ以外は閉じる
- リクエストを受けて正しく返せるようにルーティングを設定する
- ...
これで、一旦動かせる状態にはなる。
さて、ここには以下のような問題がある。
-
複雑なセットアップと管理:
- とにかくだるい。前の記事で説明した通り、上に示したセットアップが必要なサーバーは1台ではない。これを何度も繰り返すために 重厚な手順書 を必要とする。またステップ数が多いとそれだけ時間もかかるし、間違いも起きやすい。それを間違えず、迅速に黙々と行う専任の インフラ職人 を必要とする。もちろん揶揄している。
-
環境依存性と互換性の問題:
- いわゆる 「ローカルでは動いていたんですけどね」問題 。ローカルの開発環境では動いていたけど、本番環境だと途端に動かなくなる。理由は様々で、例えばローカルの Mac だと動くけど Debian ベースのサーバー環境だとインストールされる依存ライブラリに微妙に差異があって動かないとか、シンプルにデフォルトの文字コードがローカルと違うから、だとか。こういうしょーもない差異は結構ストレス。
-
バージョン管理とライブラリの依存関係:
- 一般にサーバーのスペックは高くて、メモリは 64 GB とか普通にある。したがって、 複数のアプリを一台のサーバーに同居させることも常。このとき、例えば2つの異なる Python のアプリケーションを同時に同じサーバーで動かそうとしたときに、一方のアプリはライブラリの version 1.0 を必要とするけど、もう一方のやつは同じライブラリの version 0.9 を必要とする、といったときに、明らかにめんどくさい。2つのアプリが、同じサーバーに動いているというだけで 密結合 になっている。
-
リソースの衝突と分離:
- 複数のアプリが同じサーバーで実行される場合、 CPU やメモリ、ディスクスペースなどのリソースの競合が発生する可能性がある。例えば一つのアプリにバグがあって、サーバーのメモリを全部使い果たす自体になれば、それが原因で同居している別のアプリケーションも動かない、という別の問題が発生する。これもアプリ同士が 密結合 になっている例だ。
こうした問題を解決する手段は、これまでもいくつか提供されてきた。いわゆる 仮想化 という技術。
Java を実行する環境として有名な JVM (Java Virtual Machine) や GraalVM は、仮想化技術の一つ。アプリケーションと OS の間に JVM を噛ませることで、 OS とアプリの密結合を防ぐ。
Python や Ruby も venv や rbenv など、論理的に環境を隔離させることで、ライブラリ管理などにおいてアプリを疎結合にすることを志向した仮想化技術の一つ。
VirtualBox や VMware は、アプリだけではなく OS からごっそり仮想化する技術。これらは VM (仮想マシン) と呼ばれる。 Vagrant という、 VirtualBox や VMware に簡単に VM を導入できるツールがあるのだけど、そこでは このように VM イメージが誰でも使えるように公開されている。今で言えば Docker Hub のようなもの。
VM ならば、 Nginx や MySQL などのミドルウェアの仮想化も可能にしてくれる。つまり、 Nginx などを然るべき VM にしっかりセットアップして、その VM イメージを使い回すことによって、上の「とにかくセットアップだるい」問題は解消する。
ここで欲を出すと、 VM を使い回すときの問題点は、 VM イメージのサイズが めちゃくちゃ重い こと。数GB から数十 GB くらいある。これをいちいちダウンロードして立ち上げて、というのが、オーバーヘッドがかかりすぎる。
願わくば、 python main.py でアプリケーションが実行される手軽さで VM を立ち上げて実行できると嬉しい。
このあたりの願いを叶えてくれるのが コンテナ。
コンテナ
コンテナをわかりやすく比喩するならば 小さなVM というかんじ。 VM が持つ「環境を隔離させる」という性質を帯びた状態で、かつサイズが小さい。数百 MB から数 GB くらい。
小さな VM というのは比喩に過ぎないことを強調しておく。厳密には、 VM に見えるように OS などを擬似的に模倣しているイメージ。 VM に接続するときにターミナルを開くけれども、コンテナでどうようのことをする場合には 疑似ターミナル を開く。わざわざ "疑似" という言葉を付けたくなるくらいには、やはり模倣に過ぎない。
コンテナ技術として有名なものは Docker であろう。ここでコンテナ技術と呼んでいるのは、コンテナを作るのはもちろん、コンテナを動かす環境も同時に含んでいる。 Docker の他のコンテナ技術と言えば rkt や CRI-O, containerd など。ここでは Docker の話をする。
Docker でコンテナを作るとき、以下のような Dokcerfile を書く。以下はその例。
# 公式のPython 3.9イメージをベースイメージとして使用する
FROM python:3.9
# コンテナ内の作業ディレクトリを設定する
WORKDIR /app
# requirements.txtファイルを作業ディレクトリにコピーする
COPY requirements.txt .
# requirements.txtから依存関係をインストールする
RUN pip install --no-cache-dir -r requirements.txt
# main.pyファイルを作業ディレクトリにコピーする
COPY main.py .
# エントリーポイントをmain.pyファイルを実行するように設定する
CMD ["python", "main.py"]
Dockerfile はいわば VM の設計書 あるいは VM 構築の作業手順書 のようなものだ。しかも嬉しいことに、ここに定義したことが 自動的に実行される。「とにかくだるい」問題はここで卒業できる。
ここで、コンテナを使った運用について言及しておく。
例えば一度作ったコンテナイメージに対して、なんらか修正を加えたい場合を考える。このとき、コンテナの中に入って設定を書き換える、という方法も、手段としては存在する。
しかしながら、これをやり続けると、セットアップを手動で行うことによる「とにかくだるい」問題が再発する。
ではどうすればよいか。この場合、 コンテナイメージを壊して、 Dockerfile を書き換えて、コンテナイメージを作り直す ということ。このようにすることで、イメージの中身は Dockerfile と同期される。 "Dockerfile にかかれていない特別な手順" というものが存在しなくなる。それ故、上に述べた「とにかくだるい」問題も解消される。
これは「コンテナイメージを一度構築したら不変である(それ故、修正が必要ならば一度壊して作り直す)」という風に言い換えられる。このようなことをコンテナの イミュータビリティ (immutability) と表現することがある。イミュータビリティとは日本語で「不変性」と表現されるもの。コンテナの運用はイミュータビリティを意識する。
このような運用が想定されていることから、コンテナのベースイメージによっては、 cd や cat のような、サーバーの作業に当然必要なコマンドすら入っていないことはよくある。そのような「人間が作業する」ということを徹底的に排除することで、コンテナに詰め込むのに必要なコマンドのバイナリなどを無くして、極限までイメージのサイズを小さくしようとする。
コンテナオーケストレーター
さて、次はコンテナをどのように動かすか、に注目する。
コンテナには一つのアプリケーションが詰め込まれているとしよう(高凝集である)。一つのプロダクトを動かすには、アプリケーションがたった一つあれば十分ということはほとんど無いだろう。フロントエンドとバックエンドが別れていることは常であるし、 DB や LoadBalancer といったアプリも必要である。しかも、これらは互いに 協調して動作しなければならない。
協調して動作するとはどういうことか。それは例えば、「LoadBalancer のコンテナがリクエストを受けたら、このアプリのコンテナに流さねばならない」「このアプリのコンテナは DB のコンテナと通信をする必要があるけれど、こっちのアプリのコンテナは DB に接続する必要がない」などということ。
つまり、 コンテナ間の関係性を管理する必要がある。
この管理をになってくれるものを コンテナオーケストレーター と呼ぶ。
コンテナオーケストレーターとしてすぐに思い浮かぶものは Docker Compose であろうか。以下のように、コンテナが互いにどのように動いてほしいかを記述して docker compose up とするだけで、そのように動いてくれる代物。以下は自分で作った Web アプリが MySQL にアクセスすうように書いた docker-compose.yaml のイメージ:
version: '3'
services:
webserver:
image: myimage
ports:
- 8080:8080
depends_on:
- mysql
mysql:
image: mysql
environment:
- MYSQL_ROOT_PASSWORD=secret
開発用途だとすごく便利。
では、本番用途だとどうか?これは問題がある。
というのも、 Docker Compose は 一台のサーバーの中で複数のコンテナを動かす というユースケースしか対応していない。本番用途だと、一方で、前回にお話した通り、複数のサーバーで複数の同じアプリを動かして、耐障害性やスケーラビリティを確保していた。すなわち Docker Compose だと、このあたりの本番環境で満たしてほしい要件を満たせない。
じゃあ各サーバーに入って、それぞれのサーバーで docker compose を実行するか?それもまた手段の一つではあるが、今度は、上の「docker-compose.yaml を書いて docker compsoe up するだけで全部動く」という利点を享受できなくなる。
ここで必要なものは docker-compose.yaml のようにコンテナの動き方を定義するだけで、複数のサーバーでよしなに動いてくれるツール の存在である。
こういうものはあるか?ある。それが Kubernetes や Amazon ECS といったもの。
Kubernetes も ECS も、複数のサーバーでコンテナを動かす仕組みを提供してくれるもの。以前は Docker Swarm とか Methos とかがあったけども、今はこのあたりが強い。 AWS の EKS(Elastic Kubernetes Service), Azure の AKS(Azure Kubernetes Service), GCP の GKE(Google Kubernetes Engine) はいずれも Kubernetes をラップして提供したサービス。
Kubernetes は Google 発祥の OSS 。古くは Borg と呼ばれていた。このあたりの経緯は以前に紹介した 誰も読んでない SRE 本 に詳しく書かれてある。
Kubernetes の使い方を簡単に説明する。
まず以下のような マニフェストファイル と呼ばれるものを書く。これは docker-compose.yaml の代わりになる、コンテナがどのように動いてほしいかを記述したものである。
apiVersion: apps/v1
kind: Deployment
metadata:
name: mywebapp-deployment
spec:
replicas: 2
selector:
matchLabels:
app: mywebapp
template:
metadata:
labels:
app: mywebapp
spec:
containers:
- name: mywebapp
image: mywebapp:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: mywebapp-service
spec:
type: LoadBalancer
selector:
app: mywebapp
ports:
- protocol: TCP
port: 80
targetPort: 80
このファイルを作って kubectl apply というコマンドを実行するだけで、なんと以前の記事で紹介した以下の構成ができあがる。驚異的。
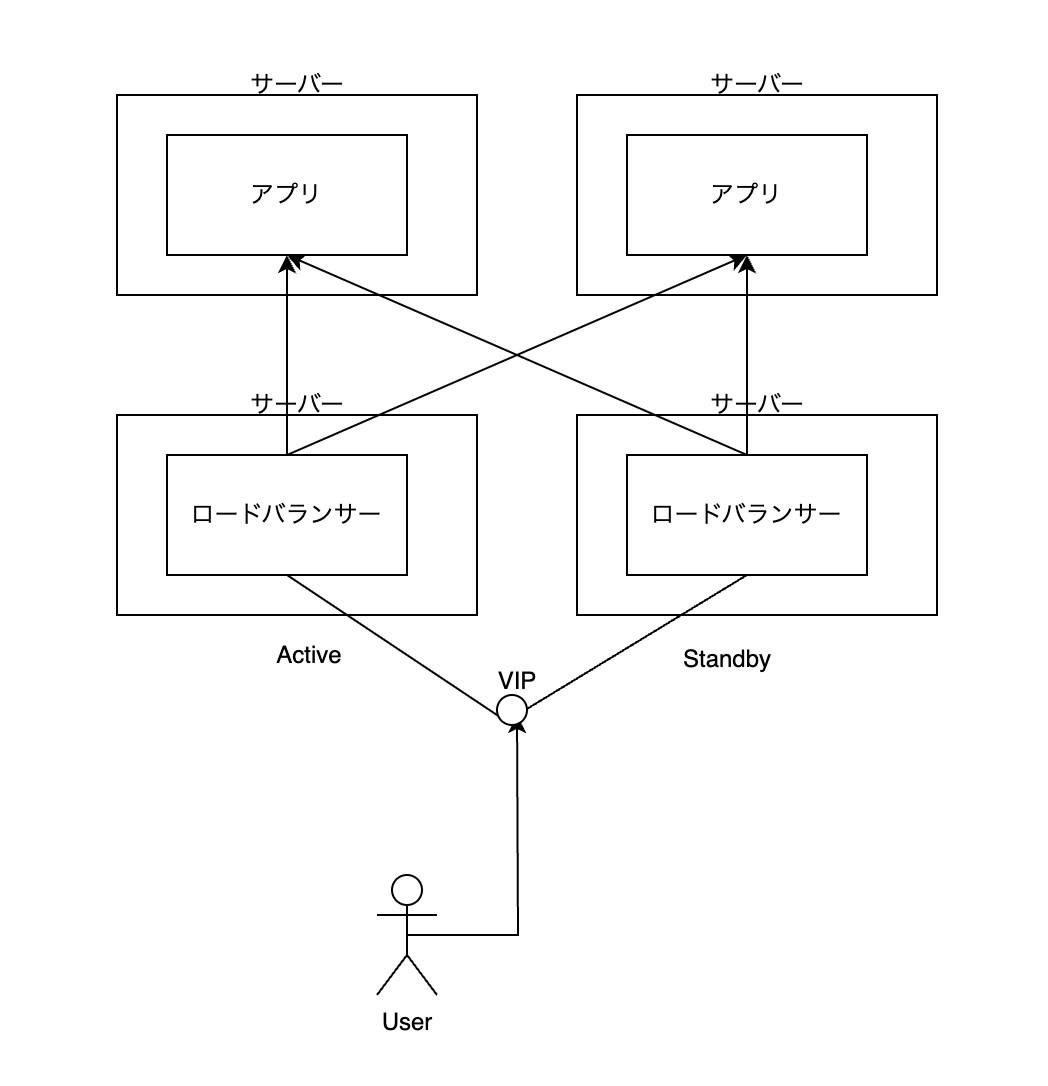
ちなみに ECS と EKS(AWS の提供する Kubernetes サービス)の違いも述べておく。
ECS もまた上のような定義ファイルを記載することで、記載した通りのインフラが出来上がる、という面では Kubernetes と同じ。 ECS は Kubernetes とは違う技術でこれを実現している。利用面での一番の違いは サーバー管理を誰がするか というところ。
ECS は利用者はサーバー管理をしなくても良い。 ECS でどのような構成でコンテナを動かしたいかだけを意識すればよい。
一方、 EKS はそうではない。 Kubernetes クラスターそのものの管理をしなければならない。例えば、 Kubernetes はだいたい4ヶ月に一度クラスターをアップデートしなきゃいけない。この作業、結構だるい。
ここまでして EKS を使う理由はなにか。それは Kubernetes のカスタマイズ性にある。 Kubernetes は例えば Custome Resource や オペレーターパターン などを駆使すれば、自分で kubectl のコマンドを簡単に作ることもできるし、振る舞いをかなりカスタマイズできる。ある程度規模が大きい会社で、複数プロダクトを Kubernetes を使って動かすような取り決めをしているならば、このようなことをしたくもなるだろう。
ちなみに、ローカルで Kubernetes は動かせるか?できる。例えば Docker Desktop には Kubernetes モードがある。 Kubernetes のマニフェストファイルを許容してそれをローカルで再現することができる。
オンプレで Kubernetes を管理するのは、かなり体力が必要。考えてみてほしい。 Kubernetes があればアプリは楽なのだけど、 Kubernetes そのものを構築するのはサーバーへ直接作業が必要になる。ここを便利にするツールも多くあるけれど、まあ大変なことが予想できる。実際、 LINE や Yahoo などは専任の Kubernetes を面倒を見るチームがある。この管理を代わりにクラウドベンダーにやってもらって、その対価としてお金を支払う、というのも選択肢として考えよう。
宣言的設定と IaC
これはインフラの話によらない話で、 宣言的設定(Declaretive Configuration) なんていう言葉がある。似たようなモチベーションの 宣言的プログラミング という言葉もある。
これらは設定やプログラミングの記法の一種で、「どのように 理想的な状態にするか」という手続きに注目するのではなく、「最終的に実現したい状態は なにか」に注目した書き方。
例えば最適化理論の定式化などは、いわゆる宣言的設定のニュアンスが強い。
\begin{align}
\min_{\vec{x}} \ & f(\vec{x}) \\
\text{s.t.} \ & g_1(\vec{x}) \leq 0, \\
& g_2(\vec{x}) \leq 0, \\
& \vdots \\
& g_M(\vec{x})\leq 0 .
\end{align}
$\text{s.t.}$ のところに制約条件が表現されているわけだけども、ここには「どのようにこの制約条件を満たすか」については言及していない。最適化のソルバーなどは、この目的関数と制約条件を上のような雰囲気で設定するだけでよい、といったインターフェースを準備してくれてたりする。
宣言的設定の対義語は 命令的設定(Imperative Configuration) 。「どのように達成するか」を記述するもの。ほとんどのプログララミング言語はこちら。
なぜ宣言的設定に言及したか。それはまさに上のマニフェストファイルがそれを意味しているから。
サーバー管理を手動でやる場合、 手順書 といったものが必要。ステップごとにやることが記載されていて、それを順番どおりにやっていけば達成できる、という「どのように達成するか」にフォーカスした存在。
この命令的設定だと、結構煩雑になる。例えば「冗長化のために、アプリが4つ動いていなければならない」という理想的な状態があるとする。それを実現するには、 今アプリがいくつ動いているか を知って、それに応じて オペレーションを変更しなければならない。例えば今アプリが一つも動いていないとしよう。その場合は 4 つのアプリを起動する必要がある。あるいはもともと 6 つのアプリが動いていて、それのスケールダウンを考えているとしよう。その場合は 2 つのアプリを停止させる必要がある。といった具合。
ここでマニフェストファイルを見る。ここでは
...
spec:
replicas: 2
...
というふうに、「とにかく 2 つ動いてほしい」と宣言しているだけ。 Kubernetes や ECS は賢くて、 どんなことが起きてもアプリが 2 つ動いている状態を実現してくれる。 Kubernetes は今コンテナがいくつ動いているかを常に監視していて、もしも障害などでアプリが 1 つしか動いていない状態が数秒あったら、 自動的に 2 つ目のコンテナをどこかのサーバーで動かしてくれる。この replicas の値を例えば 5 にして、 kubectl apply をしたら、自動的に 3 つのコンテナをどこかのサーバーで起動してくれる。
これは耐障害性があることを示している。たとえばサーバーが一つ落ちた場合、その上で動いているコンテナがごっそり消える。 Kubernetes は勝手にそれを検知して、どこか空いてるサーバーを自分で探して、ごっそり消えたコンテナを全部起動しなおしてくれる。
この仕組みを応用して面白い提供の仕方をしているのが、 Google の GCP。 Kubernetes のサーバーを選択するときに プリエンプティブル VM というものを選ぶことができる。これは、24時間くらいで自動的にシャットダウンしてしまうサーバー。その分安い。そんなの困る!と思うかもしれないが、 Kubernetes のこの性質を使えばそれがさほど問題にならないのも理解できると思う。
ここから IaC (Infrastructure as Code) という言葉を導入したい。これは宣言的設定と密接に関わりがある。
IaC とは、インフラの状態を コードとして管理する インフラ管理のアプローチの一つ。コードというか、上のマニフェストファイルのような テキストファイル としてインフラを設定する、ということ。
これができると何がいいかというと、 Git のようなバージョン管理の仕組みをインフラにも持ち込めること。 GitHub で PR ベースでレビューもできたりと、アプリのコードの開発フローと同じやり方が、インフラにおいてもできる。
この IaC と宣言的設定の相性の良さは感じられるだろう。「理想的なインフラの状態」をテキストで表現し、それをバージョン管理していく、ということ。
代表的な IaC ツールには、 Terraform、 Ansible、 Chef、 Puppet などがある。
おわりに
インフラ入門と銘打ったが、力尽きた。この近接領域のキーワードだけ示しておきたい。
- インフラのアーキテクチャ
- インフラのアーキテクチャにはいくつか重要なアーキテクチャパターンがある。 モノリシックアーキテクチャ、 マイクロサービスアーキテクチャ、 イベント駆動アーキテクチャ など。
- DB の話
- DBはでっかい話題がある。 RDB もそうだけど NoSQL みたいなものも含めて。
- ネットワークの話
- サーキットブレーカーや Istio のようなサービスメッシュの考え方
- DevOps, DevSecOps, MLOps
- CI/CD とか。 Chaos Engineering とか。
おわり