ここでは、いわゆる インフラ と呼ばれる領域について話をしたい。
ここで言うインフラとは、アプリケーションの中身ではなく 配置 にフォーカスしたレイヤー。「アプリケーションを動かすサーバーはどうするか」「ネットワーク構成はどうするか」「DBは何を使うか」といったところを考えることを指している。
ここもまた面白い領域で、なかなか奥が深い。その面白さを説明したい。
紙芝居テイストで説明する。網羅的な説明では決して無いけれども、ポイントや、その先の広がりを示すキーワードを押さえた説明を試みる。インフラについて考えることを 始められる 状態を目指す。
「良いインフラ」を評価するために
これからインフラ設計について話をするが、そのためにインフラの良し悪しをどのように評価するのか。ここではその 評価の観点 を紹介する。
インフラに満たしてほしい要件はよく 非機能要件 の中で語られることが多い。 Wikipedia にある項目を抜粋すると、以下のようなもの。
- 可用性
- 可用性、耐障害性、災害対策、回復性、成熟性
- 性能・拡張性
- 業務処理量、性能目標値、リソース拡張性、性能品質保証
- 運用・保守性
- 通常運用、保守運用、障害時運用、運用環境、運用・保守体制、運用管理方針
- 移行性
- 移行時期、移行方式、移行対象(機器)、移行対象(データ)、移行計画
- セキュリティ
- 前提条件・制約条件、セキュリティリスク対応、セキュリティ診断、セキュリティリスク管理、アクセス・利用制限、データの秘匿、不正追跡・監視、ネットワーク対策、マルウェア対策、Web対策
- 環境・エコロジー
- システム制約/前提条件、システム特性、適合規格、機材設置環境条件、環境マネージメント
上とオーバーラップするが、 RASIS もまた、評価の観点としてよく語られる。 RASIS は以下の観点の頭文字を繋げたもの。
- Reliability(信頼性)
- Availability(可用性)
- Serviceability(保守性)
- Integrity(完全性)
- Security(機密性)
ここでは例によって、上に挙げた項目それぞれの厳密な定義は置いといて、中でもとりわけ注目したいものを抜粋して乱暴に説明をする。
- 安定性・信頼性: 変化に対してロバストネスであるかどうか。例えば「アプリのデプロイの方法は適切か?」など。
- 耐障害性: 各種障害に対してどれくらいロバストネスであるか。例えば「サーバーが1台ぶっ壊れても、サービスとしては生き続ける状態になっているか?」など
- スケーラビリティ: 拡張性があるかどうか。例えば「ユーザー数が今の100倍になってアクセス数が増加したときに、ちゃんと手立てが存在するか?」など
ちなみに SRE という言葉がある。 Google 発祥の言葉で Site Reliability Engineering の略。ここで説明したような、信頼性を保ちつつ低コストでサービスを運用することをミッションに帯びたエンジニアリングの領域を指す。ここには 『SRE サイトリライアビリティエンジニアリング』 という有名な(かつ誰も読んでない言われる)本がある。 SRE としてエンジニア採用しているところもとても多いし、関連する本やコミュニティもたくさんある。今回の話も SRE に関する本を多分に参照している。
よくある Web サービスから考える
ここからは、上で話をした観点に基づいて、 Web サービスのインフラを考えていきたい。
「自己紹介を書いた文章をインターネットで公開する」といった、簡単な Web サービスを考える。
今回はわかりやすくこの例を用いるけれど、例えばアプリと DB の関係でもこれと似たような考え方をしたりするので、これを理解できればいくらか応用が効くはず。
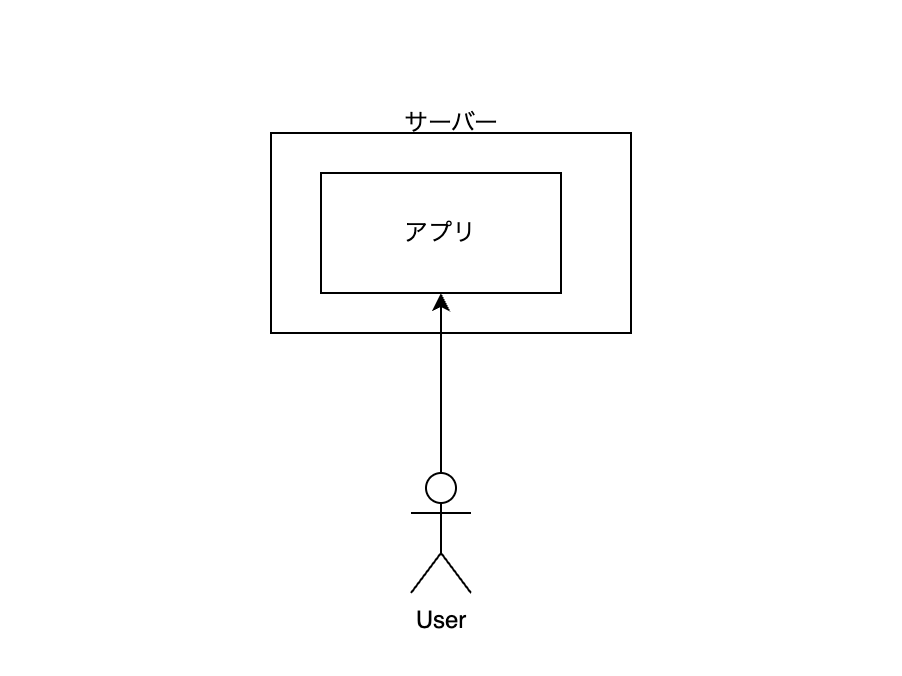
サーバーを自分で準備して、その上で文章を表示する Web アプリケーションを動かしている様子を描いている。
このサーバーは、例えば AWS で EC2 などをイメージしてもらえばよい。要するに、このアプリを動かすために、どこかのクラウドの仮想サーバーを借りて、そこに ssh などでログインして、ターミナルから色々とセッティングしたイメージ。
ポイントは、ユーザーが直接アプリケーションにアクセスしていること。
実際、これで「自己紹介を書いた文章をインターネットで公開する」という要件は満たせる。
しかしながら、以下の点についてはよくない。
まずは耐障害性について。アプリが動いているサーバーが壊れたら、このサービスは機能しなくなる。「サーバーってそんな壊れるの?」と思うかもしれないが、壊れる。古来からあるやつだと、ログファイルの log rotate が間に合わずにサーバーのストレージがパンパンになって、 ssh でのログインもできなくなる、とか。またあるいは、大量にユーザーからリクエストが来て CPU やメモリが逼迫して、そのまま制御を何も受け付けなくなってしまう、とか。こういうサーバーを再起動したりしたくなるとき。
「サーバーが壊れるものなのはわかった。ということは、それは避けられない事故のようなものなのだから、そこでアプリが動かなくなるのもまた仕方のないことで、対処もなにもないのでは?」と思うかもしれない。実はそうでもない。例えば、 Spotify では US と Asia に配置していた何千台のサーバーを誤って削除してしまったけど、サービスは正常に動き続け、ユーザーからの障害報告は一つもなかった 、という話がある。 SRE を極めればここまでできるのか、というかんじ。
次にスケーラビリティについて。ユーザーが増えて大量にアクセスが増えたときの対処がとても限定されてしまう。
スケールの方法は大きく2種類ある: スケールアップ と スケールアウト。それぞれざっくり説明するならば、スケールアップは、サーバーの CPU やメモリなどのスペックを上げることで拡張すること。スケールアウトは、サーバーそのものの台数を増やすことで拡張させること。
基本的な戦略として、スケールアップではなく、スケールアウトができるようにすることを考える。なぜなら、スケールアップは頭打ちだから。一台のサーバーに増設できるメモリにも限界がある。スケールアップ戦略をとると、その限界がサービスの限界となる。一方スケールアウトの戦略ならば、サーバースペックにおける限界はまず問題にしなくてもよくなる。
これらを気にして、次のような構成を考える。
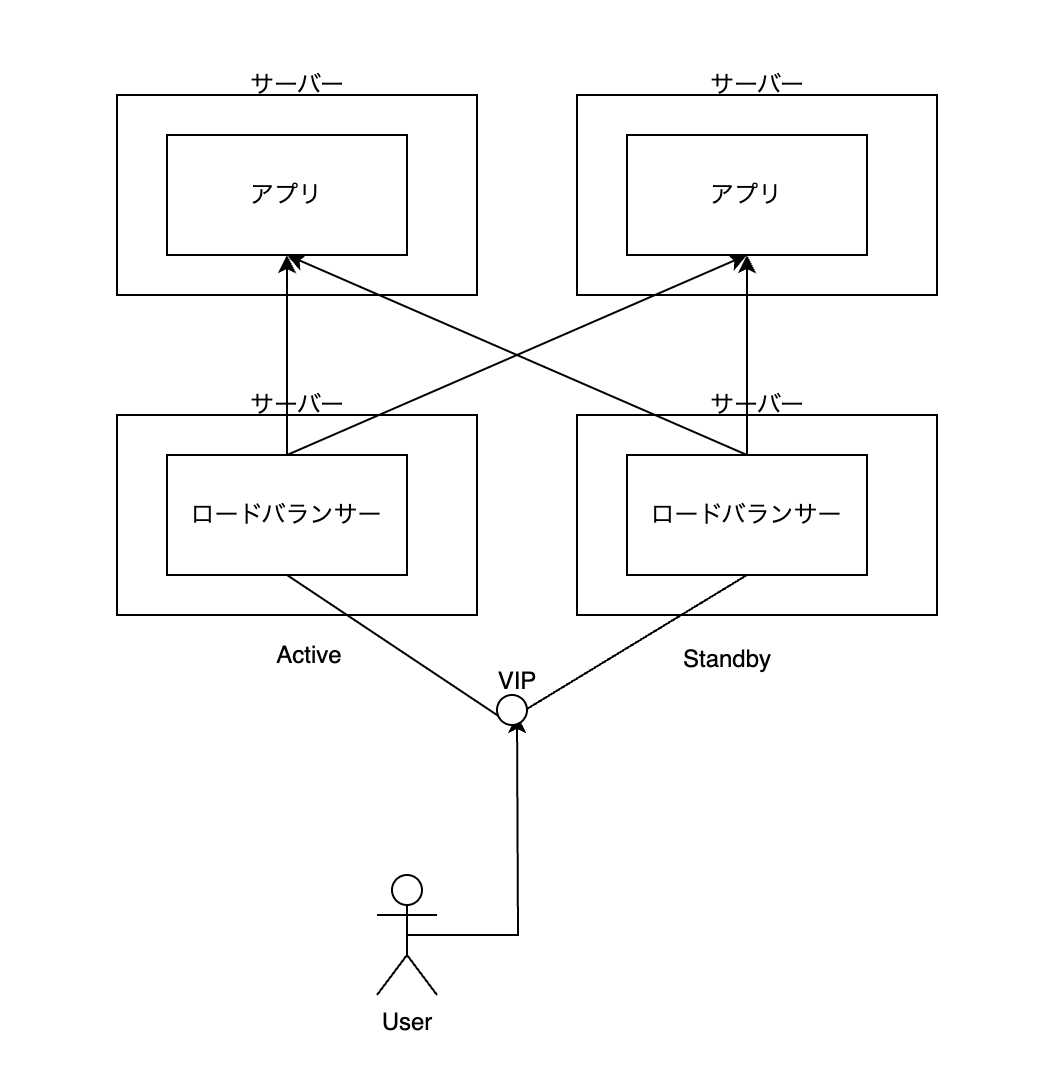
まずサーバーを1台から4台に増やす。全く同じアプリを、2つの異なるサーバーで動かす。さらに、 ロードバランサー というアプリをその前段に2台配置する。
ロードバランサーとは、そのまま 負荷分散 という意味で、ユーザーから受けたリクエストを、複数のアプリの負荷が按分するように上手にトラフィックを流してくれるアプリ。例えば、これは ラウンドロビン と呼ばれるものだけれど、最初のユーザーからのリクエストは左のサーバーに、次に来たリクエストは右のサーバーに、その次に来たリクエストはまた左のサーバーに、... といったことをやる。有名なもので Nginx や Apache HTTPD といったソフトウェアがある。
Nginx や Apache など、これらソフトウェアは リバースプロキシ(リバプロ) とも呼ばれる。リバプロは負荷分散だけ機能に持つわけではない。例えば静的コンテンツをある程度キャッシュして、アプリに答えてもらうまでもないことはリバプロが代わりに答えたりする(プロキシ機能)。また、アプリに一定間隔でアクセスして、もしアプリが死んでいたら、そのアプリにリクエストを流さない、といった賢さも持っている。
リバプロを配置することによって、前の構成の課題が低減される。アプリを横にどんどん並べていけば、ロードバランサーがうまく按分してくれる限り、サービス全体でさばけるリクエストはどんどん大きくできる(スケーラビリティ)。また、そのうちのアプリが一つ死んだ場合は、リバプロの機能によって勝手にそこ以外のアプリにリクエストが流れるので、死んだ瞬間にサービスが止まるということはない(耐障害性)。ちなみに、このようなアプリを複数あらかじめ配置しておいて耐障害性を増すことを 冗長化 と言ったりする。
次に、ロードバランサーそのもの耐障害性をみてみる。
ロードバランサーは Active/Standby 構成にしている。これは2台あるサーバーに Active と Standby とそれぞれ名前をつけて、 Active 側を常に動かしつづけ、 Standby 側は一方で何もせず待機させる、という構成。なにか障害が起きるとしたら Active 側なので、 Active 側に不具合が起きたらすぐに Standby 側が Active に素早く切り替わって、代わりにリクエストを受ける、という仕組み(フェイルオーバー)。
ロードバランサーの前に VIP というものがある。これは Virtual IP Address 、すなわち 仮想IPアドレス の略。 VIP は常に Active 側に引っ付いている。フェイルオーバーが起きたら、 VIP がかつて Standby 側だった方に素早くかつ自動的に付け直される、というかんじ。
ユーザーには VIP にアクセスしてもらうようにする。そうすることによって、 Active 側に障害が起きて Standby に切り替わっても、ユーザーはそれを悟ることなく、 VIP に変わらずアクセスし続けることができる。これがロードバランサーの耐障害性である。
では、ロードバランサーそのもののスケーラビリティはどうか?
この構成だと不十分である。ロードバランサーが載ったサーバーがリクエストをさばききれないとき、これだとスケールアップの手段しかとれない。
これを考慮した構成が以下。
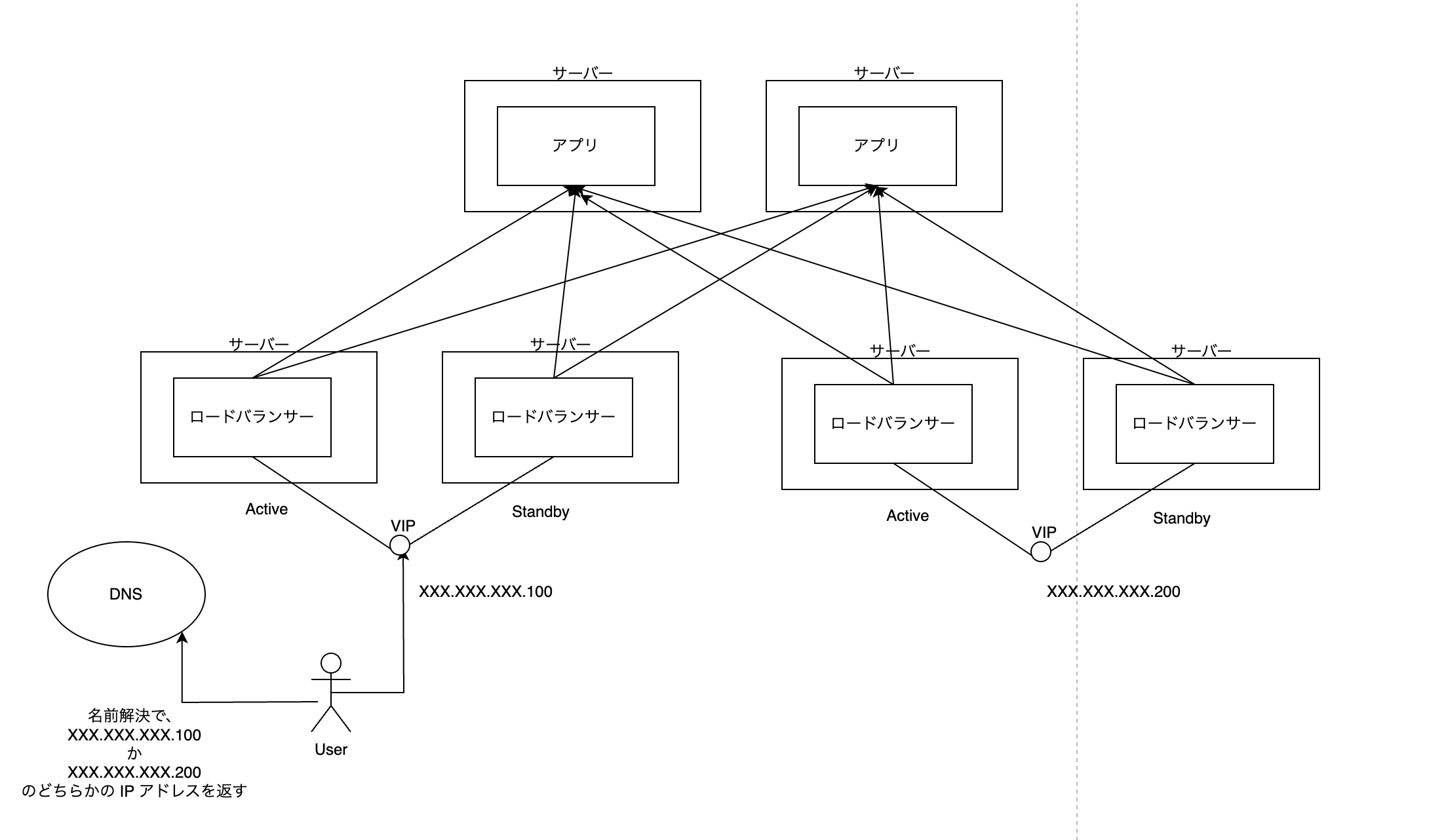
ユーザーには、 IP アドレスで直接アクセスさせるのではなく 名前(FQDN) でアクセスしてもらう。ここでいう名前とは、例えば www.google.com のようなもの。
名前は DNS と呼ばれるサーバーに問い合わせることで、 IP アドレスに変換される。みなさんが例えば Chrome で google.com というサイトにアクセスするとき、裏側では勝手に DNS サーバーと通信をして、 google.com に対応する IP アドレスを取得している。これを 名前解決 と呼ぶ。
この名前解決の仕組みを工夫することで、ロードバランサーそのもののスケーラビリティを確保できる。どういうことか。
一つの名前に対して、実は 複数の IP アドレスを対応づけることができる。例えば、現時点の yahoo.com の名前には以下のように 6 つの IP アドレスが対応している。
yahoo.com. 1465 IN A 74.6.231.21
yahoo.com. 1465 IN A 74.6.143.26
yahoo.com. 1465 IN A 74.6.143.25
yahoo.com. 1465 IN A 98.137.11.164
yahoo.com. 1465 IN A 98.137.11.163
yahoo.com. 1465 IN A 74.6.231.20
上の画像を見直してみる。ここには前と違って VIP が2つある。 XXX.XXX.XXX.100 と XXX.XXX.XXX.200 である。
DNS にこの2つの IP アドレスをある名前に対応させたものとして登録しておく。そうしたら、
そして、名前解決のときに 登録した 2 つの IP アドレスのうち 1 つを返してもらう。そのとき、名前解決の度に 異なる IP アドレスを返すようにする。これを DNS ラウンドロビン と呼ぶ。
DNS ラウンドロビンによって、ユーザーのリクエストは勝手に2つの VIP それぞれに按分されることになる。
ちなみに、名前でアクセスすることはセキュリティ上も必要。例えば TSL を使った暗号通信、要するに https:// という HTTP アクセスを可能にするにはサーバー証明書などを発行することになるけれども、そのときには名前を定義しておく必要がある。
またちなみに、 DNS ラウンドロビンはこれ以外にも考えられる用途がある。後で話をするマルチリージョン、マルチクラウドの実装にも使える。またこれは要するに「環境まるごと入れ替え」みたいな要件に対応できるので、 Blue/Green デプロイメント や カナリヤリリース を実現する具体的な手段の一つとしても注目したいところ。
さらに
これで一件落着、ではない。もっとこだわることができる。
例えば、全部のサーバーを同じ発電所から電源を引っ張っている場合、その発電所が落ちたらサービスが終わる。故に、サーバーのハードに2以上の異なる発電所から電源をとれるようにケアすることもできる(電源の冗長化)。データセンターで管理されているサーバーは、これをデフォルトで行っている。(ソースを忘れてしまったのだけど、)例えばマイクロソフトは、一つのデータセンターがまるごと潰れても、他のデータセンターでまるごと動かす準備をしてたりする。
さらに例えば、大地震が起きたことによって、これらサーバーを配置しているデータセンターそのものが終わるかもしれない。そのときは、 データセンターをまたがってサーバーを配置する ということを考える。これはクラウドサービスだとリージョンという概念で別れてたりする。
またさらに例えば、 AWS を使っていたら AWS 全体の障害に苛まれることがある。こういうものに影響を受けたくないならば、 Azure や GCP といった、別のクラウドベンダーも同時に利用して、どこかのクラウドで大規模障害が起きても勝手にスイッチしてサービスを継続させる工夫をする必要がある。こういった工夫のことを マルチクラウド と言ったりする。
こういう大惨事対応に関連するワードとして BCP(Business Continuity Plan) というものがある。ざっくり言えば、地震やテロといった緊急事態でも事業が継続できるような準備をあらかじめしておきましょう、ということ。サービスが大きくなっていくほど会社も大きくなっていって、それ故万が一でもサービスが死んでしまうと、そこにいる数千の従業員の務める会社が死ぬことになってしまうから、死活問題になっていく。このような BCP 対策の一つとして、ここで話をしたマルチリージョン、マルチクラウド、みたいな話が出てくる。
トレードオフ
例よって、ここにはトレードオフがある。
例えばサーバーの数を増やすことは、シンプルにお金がかかる。冗長化とお金のバランスは考える必要がある。
マルチリージョン、マルチクラウドなんかは、まず実装がとても面倒。ちゃんとスイッチするかのテストも必要だし、結構お金も時間もかかる。
データセンターのある場所によっては、その国の法律を気にする必要がある。例えば、ヨーロッパのデータセンターにデータをストアすることになるなら GDPR を気にする必要がある。これに沿わないと多大な罰金を支払うはめになる。
まだ続きがある
DNSラウンドロビンまで考えた構成で、おおよそ耐障害性などは賄えたであろう。
しかしながら、この構成は以下の点でいけてない:
まず、サーバーに直接アプリをインストールしていること。例えばアプリを動かしている言語のバージョンを上げたり、ライブラリを追加するときなどにも、アプリ以外にもサーバーの設定をいじる必要がある。「アプリだけを気にしたいのに、サーバーのことまで気にしなければならない」という意味では、 アプリとサーバーが密結合 にある。
また、スケールアウトさせるためにアプリを2つから3つに増やすときに、まずサーバーにアプリを新たに動かすセッティングが必要。これもアプリとサーバーの密結合性によるめんどくささがあるけれども、実は アプリとロードバランサーの関係も密結合 である。なぜなら、アプリが載ったサーバーが一つ増えると、その新たに増えた IP アドレスをロードバランサーに覚えさせる必要があるため。
こうした問題に対して、諦めなくてもよい。 実は解消できる。それを説明する手段が以下のようなもの。
- マイクロサービスアーキテクチャ、イベントドリブンアーキテクチャといった、アーキテクチャのパターンを適用させる
- Docker や Kubernetes のようなコンテナの利用
- クラウドサービスの利用
これはまた別記事で説明する。
おわり。