こんにちは!株式会社GROWTH VERSEに所属しております川田剣士です。最近ロードバランサー周りを個人的に学習していまして、知見を整理し技術記事で体系的にまとめようと思いました。記事に対する質問・コメント大歓迎です!
OSI参照モデルから理解する L4 / L7
ロードバランサーの説明では必ず「L4」「L7」という言葉が出てきます。OSI参照モデルをよくわからない人もいると思うので、まずはこれらのレイヤーの理解をしてからロードバランサーやプロキシなどの説明を進めます。まずはロードバランサー理解に必要な範囲だけ、OSI参照モデルを整理します。
OSI参照モデルとは
OSI参照モデルは、ネットワーク通信を7層に分けて整理した概念モデルです。

| Layer | 名称 | 代表例 |
|---|---|---|
| L7 | アプリケーション層 | HTTP, gRPC |
| L6 | プレゼンテーション層 | TLS |
| L5 | セッション層 | セッション管理 |
| L4 | トランスポート層 | TCP, UDP |
| L3 | ネットワーク層 | IP |
| L2 | データリンク層 | Ethernet |
| L1 | 物理層 | ケーブル |
すべてを理解する必要はありません。ロードバランサーに関係するのは主にL4とL7です。
L4(トランスポート層)とは何か
L4はTCPやUDPを扱う層です。ここで扱われる情報は次のようなものです。
- 送信元IPアドレス
- 宛先IPアドレス
- ポート番号
- TCP/UDPプロトコル
重要なのは、L4は通信の中身を理解しないという点です。
IP: 10.0.0.1 → 10.0.0.10
Port: 443
Protocol: TCP
ここまでしか見ません。
L7(アプリケーション層)とは何か
L7はアプリケーションレベルのプロトコルを扱う層です。
例:
- HTTP
- gRPC
- WebSocket
ここでは通信の中身を理解します。例えばHTTPなら、
GET /users/123 HTTP/1.1
Host: example.com
Authorization: Bearer xxx
のような情報を解析できます。つまり、L7はアプリケーションの意味を理解できる層です。
L4ロードバランサーとL7ロードバランサーの違い
このレイヤーの違いが、そのままロードバランサーの機能差になります。
L4ロードバランサー
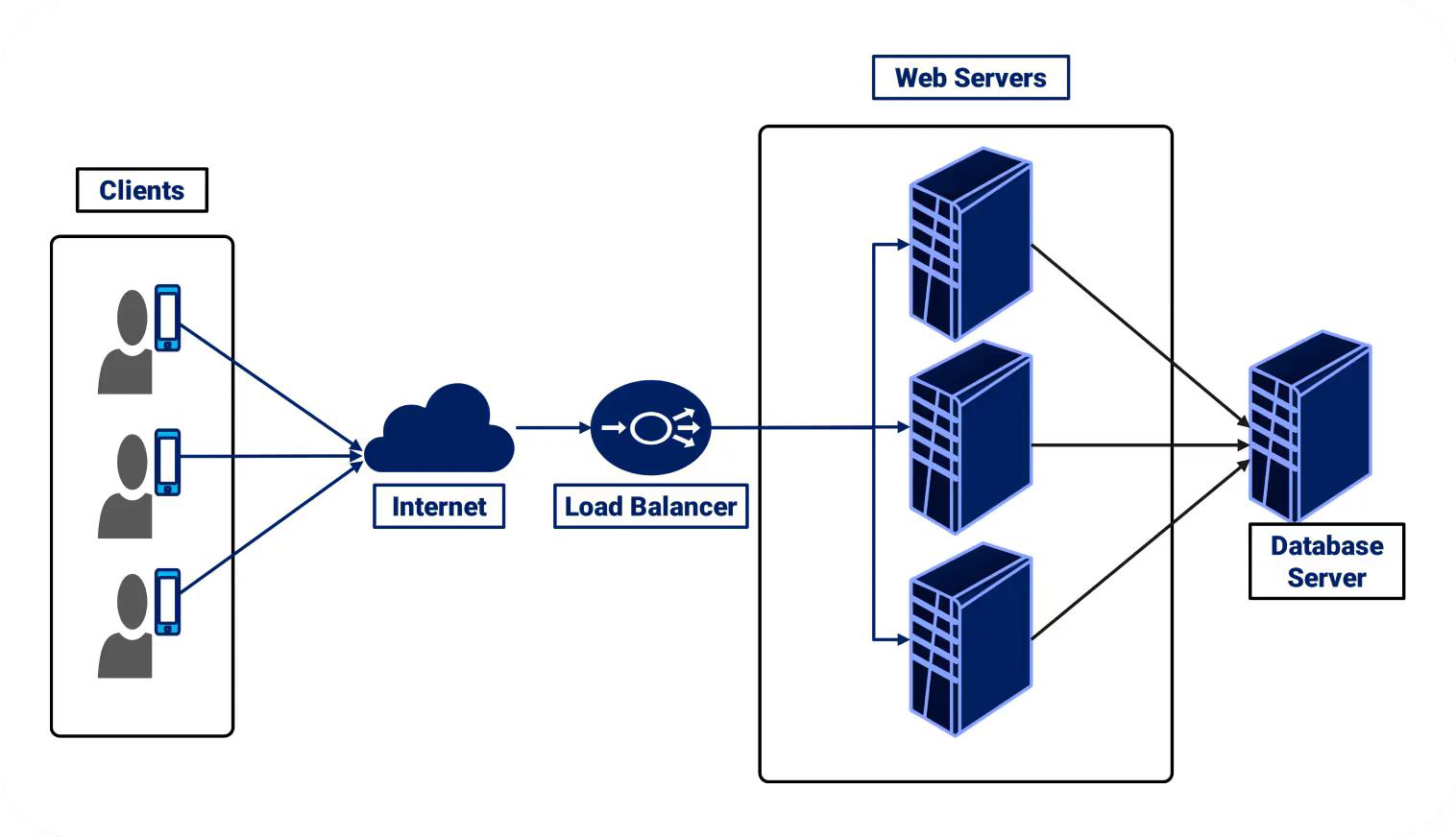
L4ロードバランサーは、
- IP
- ポート
- TCP/UDP
の情報だけを使って転送先を決定します。
特徴:
- 高速
- 処理が軽い
- プロトコル非依存(HTTP以外も可)
できないこと:
- パスベースルーティング
- HTTPヘッダ解析
- Cookie判定
アプリの中身は見ません。
L7ロードバランサー
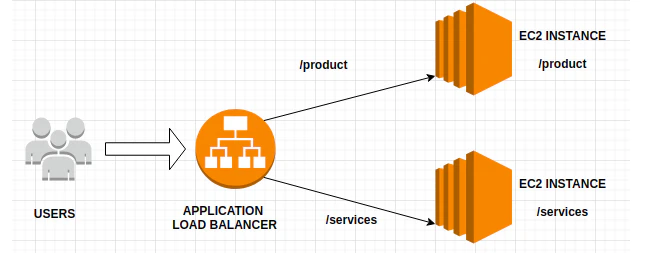
L7ロードバランサーは、HTTPレベルの情報を解析します。
例えば:
- /api/* はAPIサーバーへ
- /static/* は別サーバーへ
- 特定のヘッダがあれば別ルートへ
といった振り分けが可能です。
特徴:
- 柔軟なルーティング
- SSL終端(TLS終端)
- 認証連携
- WAF統合
ただし、パケット内容を解析する分、処理は重くなるというトレードオフがあります。
SSL終端(TLS終端とは)
TLS終端(TLS Termination)とは、ロードバランサーやプロキシサーバーなどのネットワーク機器が、クライアント(ブラウザ)からの暗号化されたHTTPS通信を受信・復号し、その中身を読み取れる状態でバックエンドサーバーに転送する技術です。HTTPSのままだと中身が見えませんが、プロキシサーバーを置いてTLS終端をさせることで、
- URLパス
- ヘッダー
- Cookie
が見えるようになります。これにより、
- パスベースルーティング
- WAF適用
- リクエスト内容ベースのレート制限
などが可能になります。
WAF(Web Application Firewall)とは
WAF(Web Application Firewall)は、Webアプリケーションへの通信(HTTP/HTTPS)をリアルタイムに監視・解析し、SQLインジェクションやクロスサイトスクリプティング(XSS)などの攻撃を検知・遮断するセキュリティ対策です。通常のFWはIP・ポートレベル(L3/L4)ですが、WAFはHTTPの中身を見ます。多くの場合、リバースプロキシに統合されています。
アプリ側・インフラ側それぞれの視点
アプリ側の視点
L7ロードバランサーを使うと、
- マイクロサービス単位のルーティング
- API Gateway的振る舞い(直接サーバーにリクエストするのではなく仲介役となっているという点でAPI Gateway的振る舞いと呼んでいる。)
- 認証の集約
が可能になります。つまり、アプリケーションの境界設計と密接に関わる存在になります。
インフラ側の視点
L4ロードバランサーは、
- 高スループット
- 低レイテンシ
- 単純で堅牢
という特徴があり、大量トラフィックに向いています。設計はシンプルですが、アプリ制御はできません。どちらが優れているとかではなく、セキュリティ要件や実施したいルーティングのレベルによって使用するべきロードバランサーが分かれるというのを認識していただければ良いかなと思います。
プロキシとは何か
プロキシ(Proxy)とは、インターネット上でユーザーの代わりにWebサイトへのアクセス・通信を行う「代理」サーバーのことです。直接通信せずにプロキシを挟むことで、IPアドレスを隠して匿名性を保つ、社内LANから外部へのアクセスを制限する、キャッシュ機能で高速に表示するなどのセキュリティと効率向上の役割を果たします。 プロキシは大きく分けてフォワードプロキシとリバースプロキシの2種類があります。
フォワードプロキシ
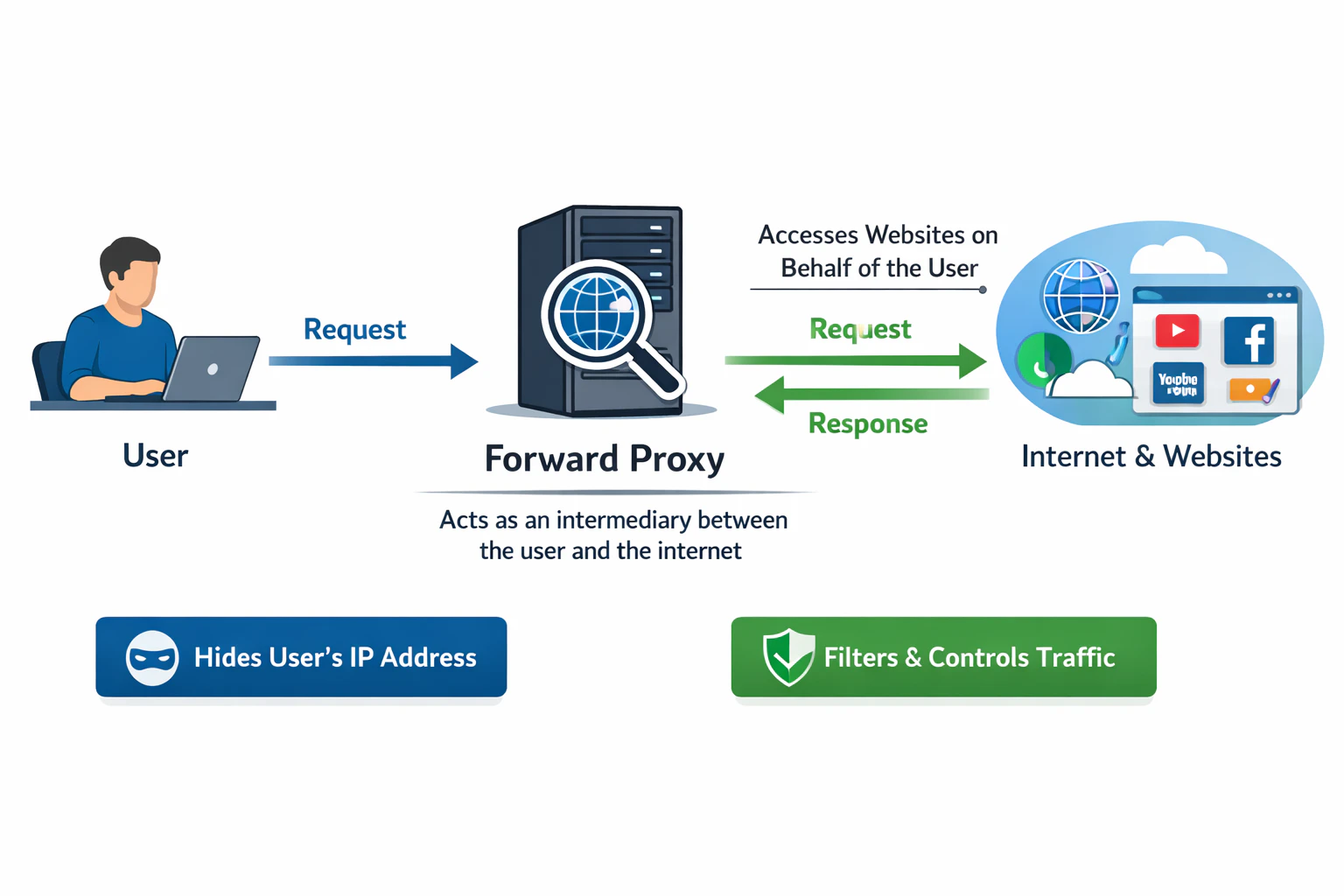
フォワードプロキシは、企業内LANなどの内部ネットワークとインターネットの間に設置され、ユーザー(クライアント)の代わりにWEBサーバーへアクセスするプロキシサーバーです。サーバーから見ると、通信元はプロキシに見えます。主な用途は、
- 企業ネットワークの外部アクセス制御
- キャッシュ
- アクセスログ管理
- フィルタリング
ポイントは、プロキシはクライアントの代理人であるという点です。
リバースプロキシ
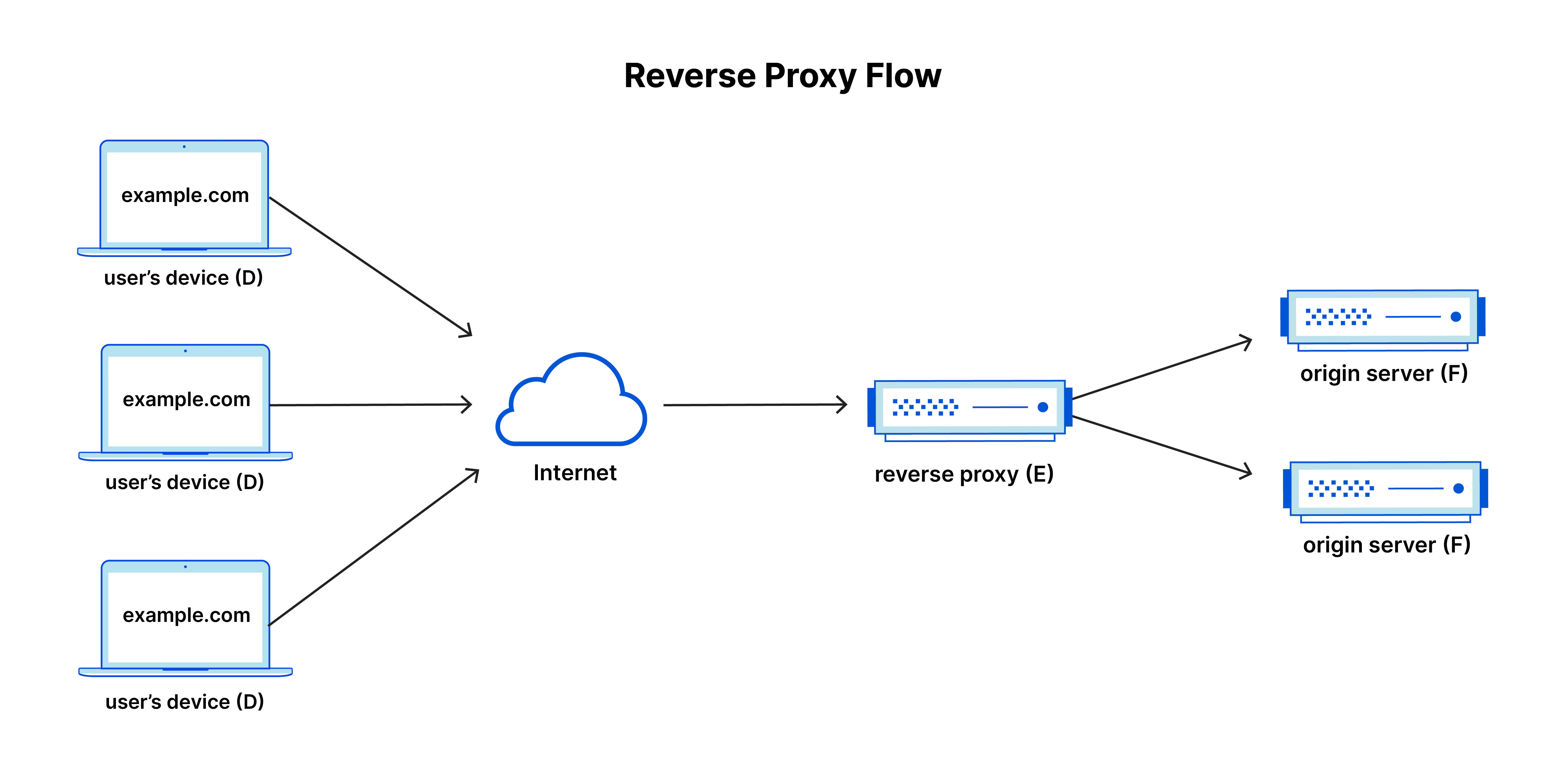
リバースプロキシは、Webサーバー(配信元)の前に配置され、ユーザー(クライアント)からのリクエストを代行して受取・転送する仕組みです。主にサーバーの負荷分散、高速化(キャッシュ)、セキュリティ向上を目的とし、直接のWebサーバーへのアクセスを防ぐことで安全な運用を可能にします。 主な用途は、
- バックエンドの抽象化
- SSL終端
- 認証
- キャッシュ
- ロギング
- ルーティング
- 負荷分散(実装による)
ポイントは、リバースプロキシはサーバーの代理であるということです。
フォワードプロキシとリバースプロキシをレストランの例で理解する
ここから、理解を補強するためにレストランの例を使います。登場コンポーネントの対応関係は以下の内容です。
| ネットワーク | レストラン |
|---|---|
| クライアント | お客さん |
| サーバー | レストラン |
| IPアドレス | 店内のテーブル |
| フォワードプロキシ | 予約仲介者 |
| リバースプロキシ | 入口の案内スタッフ |
フォワードプロキシの場合
人気店に入りたいとします。しかし直接レストランへ行くのではなく、仲介者に予約を依頼します。
お客さん → 仲介者 → レストラン
- レストランから見ると依頼元は「仲介者」
- 本当のお客さんは直接見えない
これがフォワードプロキシです。
リバースプロキシの場合
今度は直接レストランへ行きます。入口には案内スタッフがいます。
お客さん → 案内スタッフ → テーブル
- お客さんはどのテーブルが空いているか知らない
- 案内スタッフが適切な席へ誘導する
- 店内構造は抽象化されている
これがリバースプロキシです。ここで以下の疑問が出ます。
案内スタッフが空いている席へ均等に案内するなら、それはロードバランサーでは?
その通りです。ロードバランサーは、負荷分散に特化したリバースプロキシの一種であることが多いです。
- リバースプロキシは「代理・抽象化」が本質。
- ロードバランサーは「分散」が主目的。
現代の実装ではこの2つが統合されているため、混同されやすいのです。
ロードバランシングアルゴリズム
これまで、
- プロキシは「代理」
- ロードバランサーは「負荷分散に特化したリバースプロキシの一形態」
という整理を行いました。では次に重要になるのが、どのようにして振り分けるのか?という点です。リバースプロキシが「入口の案内スタッフ」だとすると、ロードバランサーは「どの席に案内するかを決めるロジック」を持っています。このロジックがロードバランシングアルゴリズム です。
前提:負荷分散 ≠ 均等分配
まず押さえるべき重要な点があります。
負荷分散は「均等に配ること」とは限らない
例えば、
- サーバーAは高性能
- サーバーBは低性能
- あるリクエストは非常に重い
- WebSocketのように長時間接続するケース
など、現実のシステムは均一ではありません。そのため、複数のアルゴリズムが存在します。
Round Robin
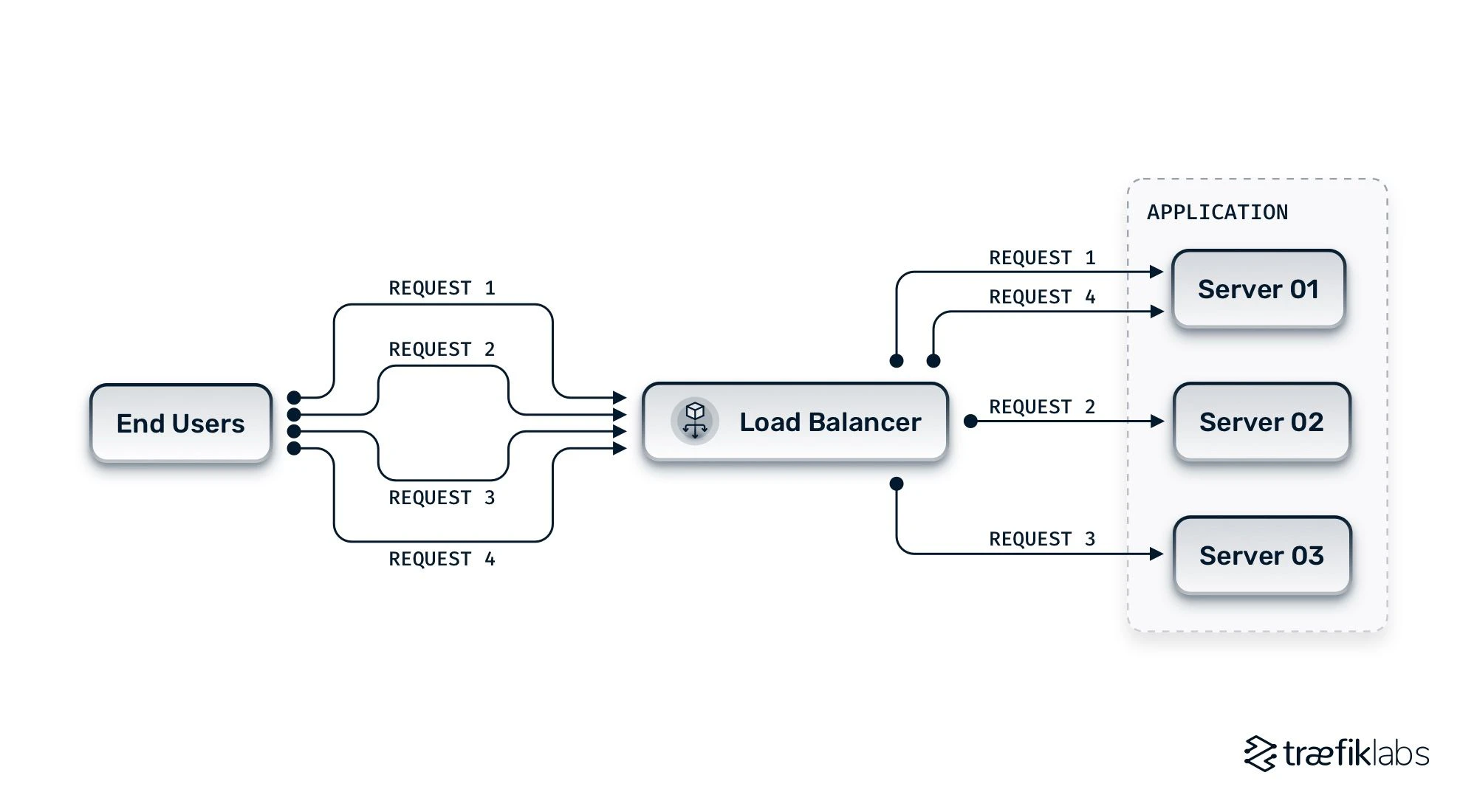
最も基本的な方式です。
Request1 → A
Request2 → B
Request3 → C
Request4 → A
順番に回していきます。特徴は、
- 実装がシンプル
- サーバー性能が均一なら効果的
- ステートレスなリクエストに向いている
注意点として、
- 処理時間の違いは考慮しない
- 長時間接続には弱い
Weighted Round Robin
サーバーごとに重みを設定します。例えば、
- サーバーA(weight=3)
- サーバーB(weight=1)
この時
A → A → A → B → A → A → A → B ...
のようにして捌かれます。用途としては、
- スペック差がある環境
- スケール移行期間中
などです。
Least Connections

現在接続数が最も少ないサーバーへ振り分けます。特徴は、
- 長時間接続に強い
- WebSocketやgRPCに有効
- 動的負荷をある程度考慮できる
注意点は、
- 接続数 ≠ 実際のCPU負荷
- I/O待ちなどは考慮できない
IP Hash
クライアントIPをハッシュ化して転送先を決定します。
hash(client_ip) % server_count
特徴
- 同一クライアントは同じサーバーへ
- セッション維持に有効
注意点
- サーバー台数変更時にデータ再配置が発生
- 大規模環境では偏りが出る可能性
Consistent Hash
IP Hashの改良版です。
特徴
- ノード追加・削除時の再配置を最小化
- 分散KVSとの親和性が高い
これは単なる負荷分散というより、データ配置戦略に近いアルゴリズムです。Consistent Hashに関しては、以前技術記事を執筆したため、ぜひこちらも読んでいただければと思います。mod分割と一貫ハッシュ法の違いから学ぶ、分散DBのシャーディング設計
レストランの例で整理
- Round Robin → 順番に席へ案内
- Weighted → 広いテーブルを多めに使う
- Least Connections → 空席が多いエリアへ案内
- IP Hash → 常連客はいつも同じ席へ
- アルゴリズムによって、案内方針が異なります。
静的ロードバランシングと動的ロードバランシング
ロードバランシングアルゴリズムは大きく分けると、
- 静的(Static)
- 動的(Dynamic)
の2種類に分類できます。この分類は、振り分け判断に「リアルタイム状態」を使うかどうかで決まります。
静的ロードバランシング(Static)
定義
事前に決められたルールに従って振り分ける方式
サーバーの現在状態は考慮しない
代表例
- Round Robin
- Weighted Round Robin
- IP Hash
特徴
- 実装がシンプル
- オーバーヘッドが小さい
- 予測しやすい挙動
- 安定しやすい
デメリット
- 実際の負荷を見ない
- サーバーの処理時間差を吸収できない
- 偏りが発生する可能性
レストランの例
- Round Robin → 「順番に席へ案内」
- Weighted → 「大きいテーブルを多めに使う」
- IP Hash → 「常連は毎回同じ席」
店内の混雑状況は考慮しません。
動的ロードバランシング(Dynamic)
定義
サーバーの現在状態を見て振り分けを決定する方式
代表例
- Least Connections
- Least Response Time
- CPU使用率ベース
- レスポンスタイムベース
特徴
- 実際の負荷に応じて分散
- 長時間接続に強い
- 不均一な環境で有効
デメリット
- 状態監視コストがかかる
- 実装が複雑
- 振る舞いが読みにくい
レストランの例
- 空席が一番多いエリアへ案内
- 料理提供が遅いテーブルは避ける
- 回転率を見て判断する
リアルタイムに状況を見ています。
どちらを選ぶべきか?
ここが設計のポイントです。
静的が向いているケース
- 各サーバーの性能が均一
- ステートレスなAPI
- リクエスト処理時間が安定
例:
- 単純なREST API
- 静的コンテンツ配信
動的が向いているケース
- 処理時間にばらつきがある
- WebSocket / gRPCなど長時間接続
- バッチ混在環境
- ノード性能が不均一
例:
- リアルタイム通信
- 大量データ処理API
実務で重要な視点
重要なのは、ロードバランサーアルゴリズム単体で解決しようとしないことです。現代のシステムでは、
- Auto Scaling
- ヘルスチェック
- メトリクス監視
などと組み合わせて設計します。
例えば:
- 静的アルゴリズム + Auto Scaling
- Round Robinは負荷の実態を見ないため、リクエストが急増しても各サーバーのCPUが100%でも均等に回すだけです。そこでAuto Scalingを組み合わせます。負荷上昇 → ノード追加 → 自然に分散。つまり、分散ロジックはシンプルに保ち、キャパシティで吸収するという設計思想)
- 動的アルゴリズム + スロースタート
- 動的アルゴリズム(Least Connectionsなど)は、「今一番空いているノード」に集中しやすいという特性があります。問題になるのは、Auto Scalingで新規ノードが追加された瞬間に一気にトラフィック集中するコールドスタート集中問題です。この問題を解決するために、新規ノードに対して、最初は少量だけ流して徐々に割合を増やすという制御を行います。これにより、新規ノードへの急激な集中を防ぐことができます。
など、複合的に設計するのが一般的です。ロードバランサーアルゴリズムは、トラフィックの「分配方法」を決めるものであって、システムの「安定性」を保証するものではないです。安定性は、
- Auto Scaling
- ヘルスチェック
- メトリクス監視
- スロースタート
- キャッシュ設計
といった周辺設計と組み合わせて初めて実現されます。
アプリ側視点での理解
アプリケーションエンジニアとして重要なのは、
- 自分のAPIはステートレスか?
- 長時間接続はあるか?
- 処理時間は均一か?
- セッション維持は必要か?
これらによって、適切なロードバランシング戦略が変わります。ロードバランサーはインフラの話に見えますが、実はアプリ設計と密接に関係しているというのが本質です。
終わりに
最後まで読んでいただきありがとうございました!