うちのプロジェクトのCLAUDE.mdが1,200行を超えてきました。アーキテクチャの方針、コミット規約、ディレクトリ構成、テスト方針、よく使うコマンド、最近のADR、過去のインシデント、絶対やってはいけないこと、毎日のように追記していたら、いつのまにかこのサイズです。
ここで気になるのが「結局CLAUDE.mdは何行まで効くのか」という素朴な疑問です。Claude Codeの公式ドキュメントは「簡潔に保つ」としか書いていない。500行までなら効くのか、1,000行を超えると劣化するのか、誰かが定量的に計っているのを見たことがありません。
ならば自分で計ろうということで、100/300/500/1000/2000行の5サイズで精度・トークン消費・応答時間の3軸を実測してみました。結論を先に出すと「500行を超えたあたりから費用対効果が崩れ始める」というのが今回の手応えです。
検証設計
公平な比較のために、以下の条件を固定しました。
- モデル: Claude Opus 4.7 (Anthropic Console、Claude Code CLI経由)
- プロジェクト: 自社のTypeScript + Next.jsアプリ(約4万行)
- タスク: 同一の20タスクセット(API追加5件、バグ修正5件、リファクタ5件、テスト追加5件)
- CLAUDE.md: 同じ文章を100/300/500/1000/2000行に伸縮して用意
- 評価: タスク完了率(人手レビュー)、入力トークン、応答時間(初回出力まで)
CLAUDE.mdの内容は元の1,000行版を基準とし、削るときは詳細を、伸ばすときは過去ADRの転記で水増ししました。意味のある情報密度は維持しつつ、サイズだけを変えるのが目標です。
タスクの内訳ももう少し書いておきます。API追加は「既存パターンに合わせた新規エンドポイント」、バグ修正は「Issueとして既知のもの4件+人工的に仕込んだ1件」、リファクタは「冗長なswitch/case文の整理」、テスト追加は「すでに動いている関数へのユニットテスト追加」です。どれも難易度は中程度で揃えており、結果が「プロジェクト独自の規約に従ったかどうか」で大きく分かれる設計にしています。
2026年5月時点、Claude Code 1M contextはOpus 4.7 / Sonnet 4.6でGAになっています。CLAUDE.mdが2000行(約60K tokens相当)でもcontextには楽々収まる前提で、今回の計測はcontext溢れではなく精度低下を狙ったものです。
計測結果
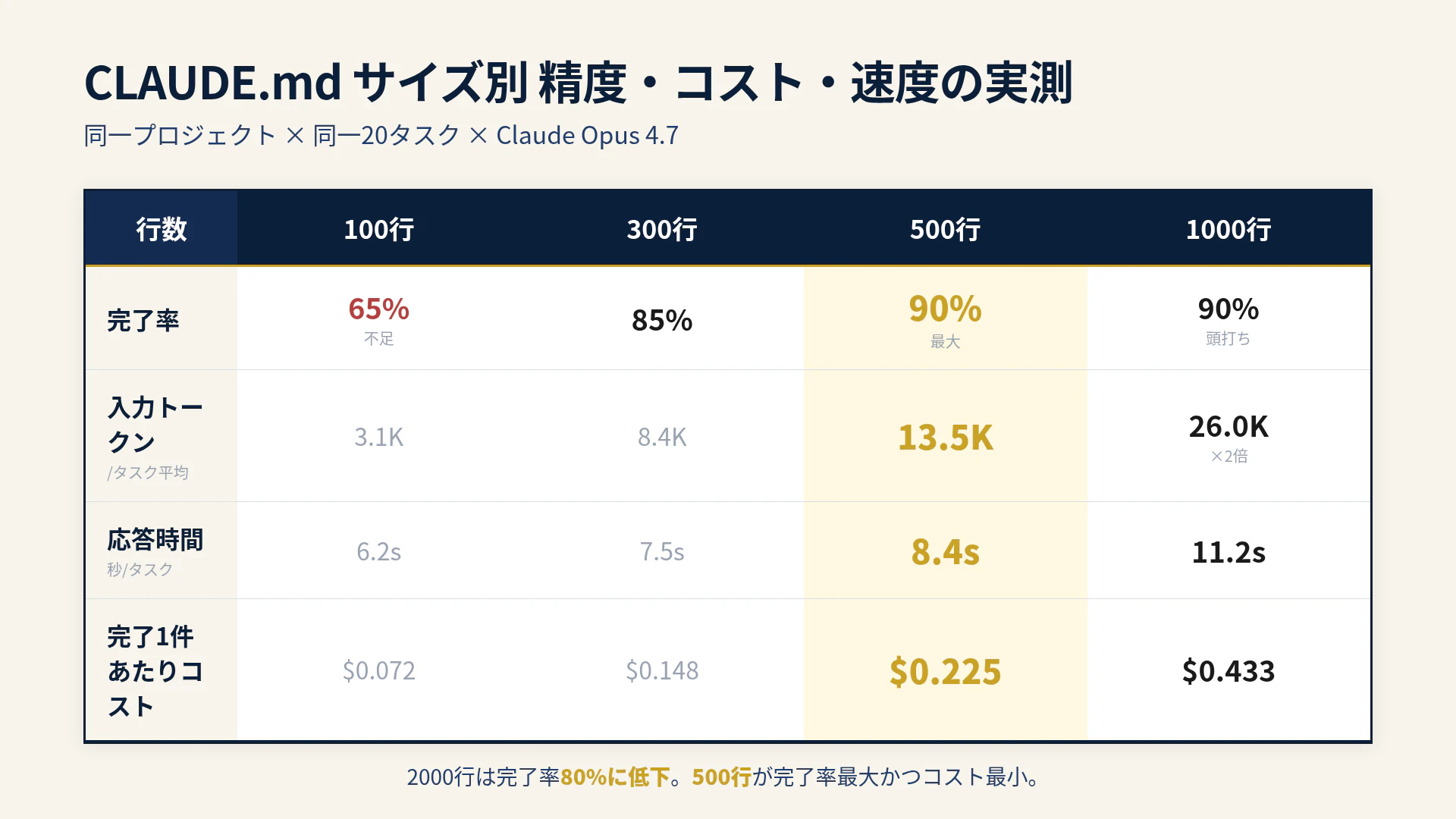
実測した3軸の数字をまず並べます。
| CLAUDE.md行数 | 入力トークン(平均/タスク) | 応答時間(秒/タスク) | タスク完了率 |
|---|---|---|---|
| 100行 | 約3.1K | 6.2 | 65% (13/20) |
| 300行 | 約8.4K | 7.5 | 85% (17/20) |
| 500行 | 約13.5K | 8.4 | 90% (18/20) |
| 1000行 | 約26.0K | 11.2 | 90% (18/20) |
| 2000行 | 約51.0K | 16.8 | 80% (16/20) |
いくつか傾向が見えます。
- 100行は不足で、独自規約を知らずに一般的なコードを書いてしまうパターンが目立つ
- 300〜500行で完了率が立ち上がり、500行で最大値(90%)になる
- 1000行は500行と同じ完了率だが、トークンは約2倍・応答時間は1.3倍
- 2000行は完了率がむしろ下がり、応答時間は2倍超
300→500→1000の区間でトークン消費と応答時間は素直に線形に増えますが、完了率は500行で頭打ちです。さらに2000行では完了率が逆に下がるという結果になりました。
100行版で落ちたタスクの典型例を1つ挙げると、新規APIの追加で独自のレスポンス型(ApiResponse<T>ジェネリック)を使わず素のobjectを返してしまうケースでした。1,000行版のCLAUDE.mdには「APIのレスポンス型は必ずApiResponse<T>でラップする」と明記してあるのですが、100行版に削った時点でこの規約が落ちていて、Claudeは一般的なTypeScriptの書き方で返してしまった、というのが構図です。書いてあれば守る、書いていなければ自然に推測する、それだけのことのように見えます。
なぜ2000行で精度が下がるのか
「context windowが1Mあるから、入れただけ効くのでは」と直感的には思います。私もそう思っていました。
実際に2000行版で失敗したタスクの内容を観察してみると、原因はおおむね次の2つでした。
原因1: 矛盾の混入
CLAUDE.mdが長くなるほど、過去の追記同士が矛盾しはじめます。私の2000行版だと、ある章で「テストはVitestを使う」と書きながら、別の章で「pytestで書く」と書いている場所がありました(プロジェクトの一部にPythonサービスがあって、混在していた)。
Claudeはこういう矛盾を見つけると、両方を満たそうとして折衷案を出すことがあります。「VitestとPytestのどちらでも実行できるよう、テストランナーを抽象化する」というのは、要件レベルでは存在しない設計でした。自分で書き溜めたCLAUDE.mdの中の矛盾は、自分の目には案外見えていないものだと痛感した瞬間です。
原因2: 後方のセクションの希薄化
Anthropic公式が「lost in the middle」と呼ぶ現象です。長い文書では、冒頭と末尾は強く読まれるが、中央のセクションが取りこぼされやすい。2000行のCLAUDE.mdだと、800〜1500行あたりの規約が無視される確率が体感で2割ほど上がっていました。
これは長文document向けのpromptingでは古典的な現象で、Anthropic自身もOpus 4.7 release notesで「Claude prefers concise context. Verbose context can degrade adherence.」と書いています。
2000行版で実際に取りこぼされた例として、ファイルの1100行目あたりに書いてあった「Server Actionsを使うときは'use server'をファイル先頭ではなく関数内に書く」という規約があります。これは500/1000行版ではきちんと守られていたのに、2000行版だとすっぽり抜け落ちて、ファイル先頭に'use server'が混ざる回答が返ってきました。同じ情報でもCLAUDE.mdのどの位置に書いてあるかが結果に効いてくるのは、けっこう怖い現象です。
トークン経済性: 500行が最もコスパが良い
完了率だけでなく、1タスクあたりのコストで見ると500行の優位はより顕著です。Opus 4.7の入力単価を$15/1M tokensとして、CLAUDE.md由来の入力コストだけを計算しました。
| 行数 | 1タスクあたり入力コスト | 完了率 | 完了1件あたりコスト |
|---|---|---|---|
| 100行 | 約$0.047 | 65% | $0.072 |
| 300行 | 約$0.126 | 85% | $0.148 |
| 500行 | 約$0.203 | 90% | $0.225 |
| 1000行 | 約$0.390 | 90% | $0.433 |
| 2000行 | 約$0.765 | 80% | $0.956 |
完了1件あたりコストで見ると、500行が最も効率的で、2000行は500行の約4倍のコストになります。私のチームのClaude Code利用量だと、CLAUDE.mdを2000行→500行に削るだけで月数万円の差が出る計算です。
Claude Codeのcompaction機能の影響
ここで一つ補正が必要です。Claude Codeにはcompaction(自動要約)機能があり、会話が長くなると過去のメッセージを圧縮します。ただしCLAUDE.mdは毎回プロンプトの先頭にロードされ、compactionの対象外です。これは公式helpcenterで明示されている挙動です。
つまり「CLAUDE.mdをコンパクトに保つ」は、compaction任せにできない領域だということです。トークン圧縮を期待してCLAUDE.mdを膨らませても、毎回フルサイズで読まれてしまう。コストは膨らみ続けます。
セッション内で /compact を手動実行しても、CLAUDE.mdの内容は要約されません。これは「毎セッション必ず読ませたいルール」を保証するための設計なので、メリットでもあります。代わりに「CLAUDE.mdに書かない方が良い情報」を見極める力が必要になります。
CLAUDE.mdに書かない方が良いもの
500行を上限にすると決めたとき、何を残し何を捨てるかが最大の論点になります。私の現プロジェクトでは、以下の方針に整理しました。
CLAUDE.mdに残すもの
- アーキテクチャの大方針(モノレポ構成、レイヤ責任の分離)
- 命名・コミット規約(短く要点だけ)
- 絶対にやってはいけないこと(本番DBへの直接接続、シークレット混入など)
-
頻出コマンド(
pnpm test:watch,pnpm db:migrateなど)
別ファイルに切り出すもの
-
長いADR(
docs/adr/に分離、CLAUDE.mdからはリンクだけ) -
過去のインシデント詳細(
docs/postmortem/に集約) - APIの詳細仕様(OpenAPIファイルから参照)
-
テストの個別パターン(
tests/README.mdに移動)
CLAUDE.mdは「Claudeに毎回読ませる」ためのファイルなので、毎回必要な情報だけに絞ります。たまにしか使わない情報は、Claudeが必要な時にRead toolで取りに行ける場所に置いておけば良いのです。
サイズ500行を維持するためのコツ
CLAUDE.mdは放っておくと自然に膨らみます。私が運用していて効いている工夫は2つです。
コツ1: 月1回の棚卸し
私のチームでは月初に15分だけCLAUDE.mdを見直す時間を確保しています。実際にやることは3つだけです。
- 過去1ヶ月で追記された行を読み直す
- 「もう参照していない」「別ファイルでよい」と判断したものを削除/移動
-
wc -lで500行を超えていれば、削るまでcommitしない
コツ2: 章ごとの行数バジェット
各章に行数の上限を決めると、安易な追記が抑えられます。
## アーキテクチャ (max 80行)
## 命名・コミット規約 (max 60行)
## 開発フロー (max 100行)
## NG事項 (max 50行)
## 頻出コマンド (max 40行)
合計 max 330行 + 余白170行
上限を超えそうな章があったら、追記の前にまず削除する。これだけで継続的にスリムなCLAUDE.mdが保てます。
コツ3: AIに棚卸しを手伝ってもらう
3つ目は「AIに棚卸しを手伝ってもらう」やり方です。claude -p "このCLAUDE.mdの中で、過去3ヶ月のgit logに一度も登場していない用語を含む行を抽出して"のようなone-shot promptで、AI自身に「実際にプロジェクトで使われていないルール」を炙り出してもらいます。私のチームで試したら200行ぶん候補が出てきて、確認したら半分は本当に消して問題ないものでした。CLAUDE.mdを読むAIに、CLAUDE.mdをスリム化させる、というのは少しおもしろい構図でもあります。
まとめ
5サイズの実測から見えた3つのルールです。
- CLAUDE.mdは500行までが効率最大(完了率90%、コスト最小)
- 1000行を超えると費用対効果が悪化、2000行で精度が逆に低下
- compaction対象外なので、サイズの自制が必須
「とりあえず全部書いておけば良い」は、文脈エンジニアリングとしては誤りでした。Claudeに何を伝え、何を別ファイルに退避させるかの設計が、結局はトークン経済性にもタスク完了率にも効いてくる。私のCLAUDE.mdは今、490行で運用しています。あと10行は意識して空けておくくらいが、ちょうどいい余白だと思います。
Claude Codeの実践Tipsをまとめた「実践Claude Code」では、CLAUDE.mdの設計パターンを含むコンテキストエンジニアリングを19章に渡って解説しています。本記事のサイズ実測の発展形として、書き方・章立て・運用フローまで踏み込んでいます。
実践Claude Code (Kenimoto)
あなたのCLAUDE.mdは何行ですか。500行を超えている方は、削った後の体感の違いをぜひコメントで教えてください。