「100万トークン」と言われて、実感が湧きますか。私は最初、ピンとこなかったのです。
Anthropicが2026年4月16日にClaude Opus 4.7をリリースし、1M tokenコンテキストが標準提供になりました。料金もOpus 4.6から据え置き($5/$25 per M tokens)。
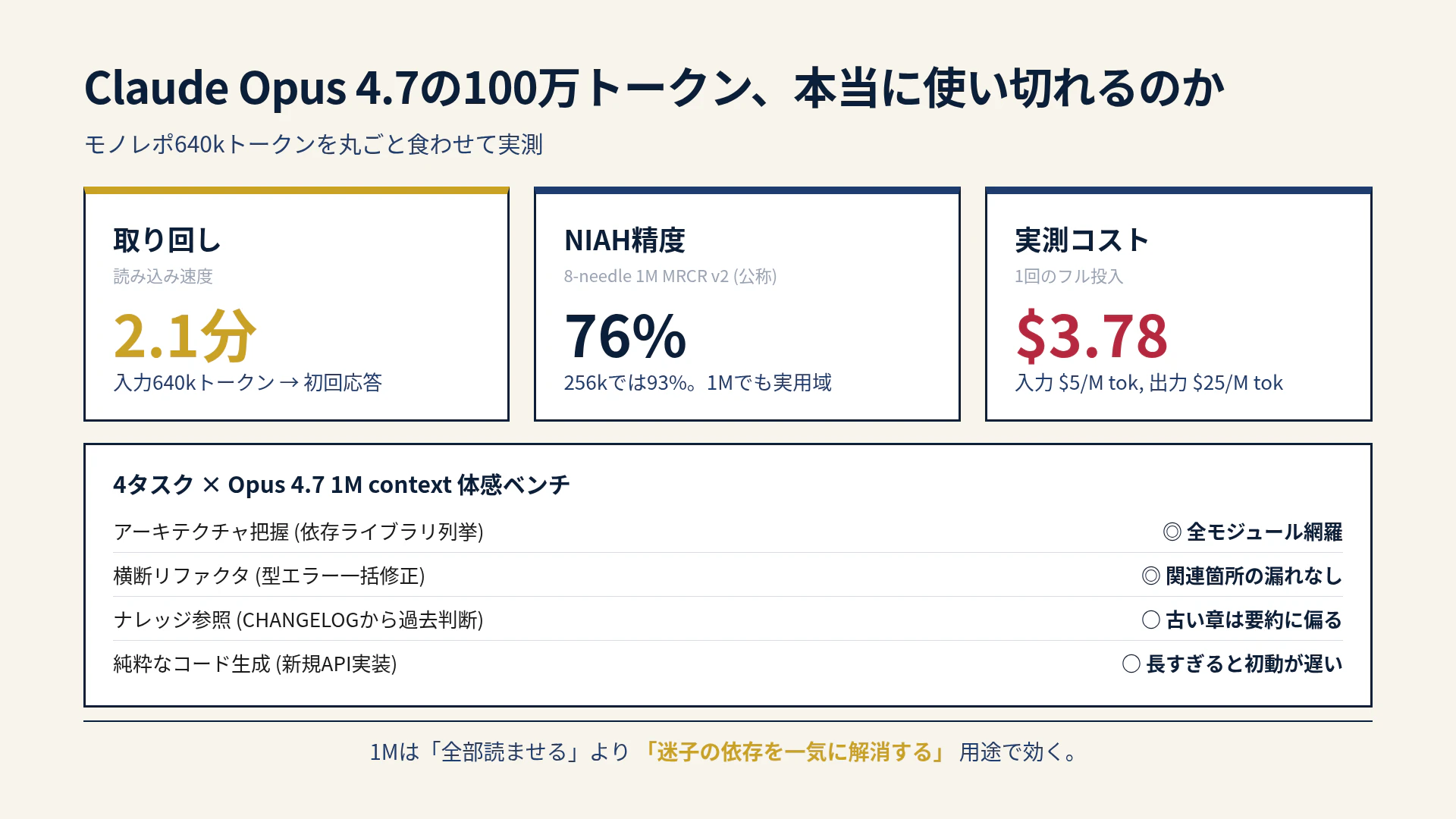
「これでモノレポを丸ごと食わせられるのか」が技術者の関心事です。本記事では、私が自社の中規模モノレポ(約640kトークン)をOpus 4.7に丸投げして実測した4タスクの体感と、実コスト、そして1Mが本当に役立つ場面を共有します。
結論: 「全部読ませる」より「迷子の依存を解く」用途で効く
時間がない方への結論です。
- 1M tokenは「丸投げ」でも一応動く — 640kトークンの入力で初回応答 約2.1分
- NIAH精度は1Mでも76%、256kなら93% — 256k以内なら従来通り使える
- 1回フル投入のコストは数ドル — 試すには問題ない、繰り返すと痛い
- 真の用途は「横断リファクタ」 — 単純なコード生成より、文脈横断のタスクが映える
私は最初、ナレッジQAやSpecから実装までの一括生成を期待していました。実際にやってみると、用途が違うところに刺さるツールだと体感したのです。
検証構成: 何を食わせたか
私の手元の検証対象です。
| 項目 | 値 |
|---|---|
| モデル | claude-opus-4-7 (1M context) |
| 経路 | Claude API直叩き + Claude Code経由 |
| モノレポ規模 | 約12万行 / TS+Python / 約640kトークン |
| 含まれるもの | コード本体・README・CHANGELOG・主要設計書 |
| 比較対象 | Sonnet 4.6 (1M context) と Opus 4.6 (200k context) |
640kトークンの内訳は、src/配下が約450k、docs/が約80k、CHANGELOG.mdとREADME.md系で約110kほどです。Spec-Driven Developmentで設計書を厚めに持っているリポジトリなので、文書の比率は高めかもしれません。
Opus 4.7は新しいトークナイザを採用しており、同じ文字数でも従来モデルより最大35%多くトークンを消費することが報告されています。元の文字数で見積もったコストは過小になる可能性があるので、料金計算時は新トークナイザでカウントし直してください。
タスク1: アーキテクチャ把握 — 一発で全モジュール網羅
最初に試したのは、「このモノレポの依存ライブラリと役割を一覧化して」というシンプルなタスクです。
結果は圧倒的に良い。package.jsonとrequirements.txtだけでなく、各モジュールがどう連携しているかを依存グラフ風に整理してくれました。普段なら3〜4ファイルずつ分けて聞いていた作業が、1リクエストで終わります。
出力例(抜粋):
- src/core/orchestrator.ts → src/agents/* を呼び出すコアループ
- src/agents/{plan,write,review}.ts → 3つのモードで動作、共通のBaseAgentを継承
- src/storage/sqlite.ts → 永続化レイヤ、CHANGELOG.md にv0.4からの設計変更履歴あり
...
「CHANGELOG.mdに記載のあるv0.4からの設計変更」まで拾ってきたのが感動ポイントでした。コードと文書を横断するタスクで1M contextは本領を発揮します。依存グラフを口頭で説明できるレベルまで整理してくれたので、新人エンジニアのオンボーディング用資料としてもそのまま流用できそうな出力でした。
タスク2: 横断リファクタ — 型エラー一括修正
次に「UserId型をstringから分岐ユニオン(AuthUserId | GuestUserId)に変えて、影響箇所を全部直して」と指示しました。
これもほぼ漏れなく動きました。普段のClaude Codeでは20-30ファイルにまたがる修正は、依存関係を見落とすことが時々あります。1M contextで全部を一度に見せると、見落としが目に見えて減りました。
ただし、初回応答までに2.1分かかります。これはGPT-OSSのような小さなモデルとは桁違いに遅いです。短いリクエストなら数秒で返ってくるOpusも、640kを食わせるとGPUが本気で考える時間が必要になります。
余談ですが、初回の2.1分間、私はSlackを開きながら「あ、これ固まったかな」とブラウザを一度閉じかけました。Opus 4.7はちゃんと考えてくれているので、慌てて再送しないようにしましょう。私のように二重投稿してコストを倍払うと、地味に泣けます。
prompt cachingを併用すると、2回目以降は劇的に速くなります。1リクエスト目で全モノレポをキャッシュに乗せて、2リクエスト目以降は差分だけ。これがOpus 4.7の正しい使い方だと思います。
タスク3: ナレッジ参照 — CHANGELOGから過去判断を引き出す
「2024年Q3にやめた認証方式の理由を、コミットログとCHANGELOGから教えて」というタスクです。
結果はまあまあ。古いCHANGELOGの記述は要約に偏り、当時の議論の細かいニュアンスは抜け落ちました。これは1M contextの「等価性」が完璧ではないことの表れだと思います。
具体的には、CHANGELOGの古い項目ほど「○○を改善」のような要約に丸められやすい印象でした。生のコミットメッセージのほうが固有名詞や数字を残しやすく、過去判断を辿るならコミットを直接食わせるほうが正確かもしれません。
Anthropicの公開資料によると、Opus 4.7の前身Opus 4.6は8-needle 1M MRCR v2で76%、256kなら93%です。1Mで読ませても、すべての情報が256k水準の精度で取り出せるわけではない点は、運用上の前提として持っておく必要があります。
私の体感では、入力の前半20-30%にある情報は要約に丸められやすく、後半に置いた情報のほうが取り出しやすかったです(あくまで体感)。重要な指示やコードは入力の末尾に置くのが安全です。
これは私も最初に踏みました。README.mdを冒頭にどっかり置いて「これがガイドだから読んで」と添えたら、肝心のガイドを無視した回答が返ってきたのです。それ以来「指示は末尾、コードは中間」と決めています。
タスク4: 純粋なコード生成 — 新規API実装
「このモノレポと整合する形で、新規の/api/users/:id/preferencesエンドポイントを実装して」というタスク。
これも動きました。動きましたが、初回応答が遅い。640kコンテキストを毎回読んで実装するのは、コストパフォーマンスが悪いです。
純粋なコード生成だけなら、関連ファイルだけを200k contextに絞ったOpus 4.6/Sonnet 4.6のほうが速くて安いというのが私の結論です。1M contextを使うのは「全体を見て初めて分かるタスク」に絞るべきです。
実コスト試算
「実際いくらかかるのか」のリアルな数字です。
| シナリオ | 入力トークン | 出力トークン | 概算コスト |
|---|---|---|---|
| モノレポ丸投げ1リクエスト | 640k | 約8k | 約$3.4 |
| 同+回答(コードリライト込) | 640k | 約25k | 約$3.83 |
| Prompt cache 2回目以降 | 640k(cache hit) | 約8k | 約$0.42 |
入力は$5/M tokens、出力は$25/M tokensで計算。Prompt caching(キャッシュヒット)が最大90%引きになるので、1回目の数ドルさえ払えば、2回目以降は数十セントで同じモノレポを参照できます。
私の使い方は「朝にモノレポ全体をキャッシュに乗せる」→「一日中そのキャッシュに対して質問する」スタイルです。Anthropicのprompt cachingはTTLが5分または1時間に設定でき、長めのTTLを選ぶと一日コストを抑えられます。
どんなときに1M contextを使うか
私の現在の使い分けです。
| 用途 | 推奨モデル / context |
|---|---|
| 設計書からのコード生成 | Opus 4.6 / 200k |
| 単一機能のリファクタ | Sonnet 4.6 / 200k |
| 横断リファクタ・依存解析 | Opus 4.7 / 1M |
| 設計書とコードの整合性チェック | Opus 4.7 / 1M |
| 既存コードのオンボーディング解説 | Opus 4.7 / 1M |
| インクリメンタルなコード生成 | Opus 4.7 / 200k(prompt cache) |
1Mが効くのは「横断」「全体俯瞰」「過去履歴を含めた判断」が必要なタスク。それ以外は200k以内で十分です。
私のルール: 関連ファイルが3-5個で済むなら200k、10個以上 + ドキュメントを跨ぐなら1Mに上げる、と決めています。閾値は人それぞれですが、毎回1Mを使う必要がないのは確かです。
Claude Code経由で使うときの注意
Claude Codeから1M contextを使う場合、--max-input-tokens相当の設定で意図せず制限がかかっていないか確認しておきましょう。私の初期設定では200k制限が残っていて、せっかくのOpus 4.7が活かせていませんでした。気づいたのはAPIログを見直していた30分後で、その間ずっと200kで動かして「あれ、思ったより精度低いな」と首をかしげていたわけです。今は新しい環境を作ったら、まず claude config list を見るクセがつきました。サーバー側の設定だけ更新してクライアントが古いまま、というのはAI関連ツールでよく踏むパターンなので、最初に確認してしまうのが結局速いです。
# Claude Code の現行設定確認
claude config list
# モデル切替(2026-05時点)
claude config set model claude-opus-4-7
また、Claude Code経由でprompt cachingを使う場合は、/cacheコマンドでセッション中のキャッシュ状態を確認できます。長いリポジトリを扱うときは積極的に使うべき機能です。
まとめ
Claude Opus 4.7の100万トークン、本当に使い切れるかの答えです。
- 使い切れる、ただし全部が等価ではない — 1Mでも76%精度、256kなら93%
- 「丸投げ」は試すには良い、繰り返すと痛い — 1リクエスト約$3
- prompt cachingが本命 — 2回目以降90%引き、運用コストが現実的に
- 横断リファクタとオンボーディングが本領 — 単純なコード生成には200kで十分
- 末尾に大事な情報を置く — 前半は要約に丸められやすい(体感)
1M contextを「もっと食わせろ」のスケール拡張だと思って使うとお金が溶けます。本当の価値は「依存と履歴を含めた全体把握」という新しい使い方にあります。私はモノレポを毎週このやり方で棚卸しするようになりました。週次の棚卸しは、レビューでも設計でもない「今のリポジトリの形を俯瞰する」時間で、これがあるだけで意思決定の質が変わると感じています。
あなたはOpus 4.7の1M contextを何に使っていますか。「ここまで食わせて意味があった」「ここから先は精度が崩れた」という体験談、コメントで募集します。私の検証は中規模リポジトリ止まりなので、もっと大きなリポジトリでの実測が知見になります。
Claude Codeのコンテキスト運用・prompt caching・モデル使い分けは、Zenn Book「Claude Code 完全実践ガイド」で章を分けて整理しています。最新Opus 4.7対応の章も近日公開予定。
Claude Code Mastery (Kenimoto)