はじめに: あなたのサイト、AIに「見えて」いますか?
先日、自社サイトが ChatGPT や Perplexity の回答に引用されているか調べてみました。結果はゼロ。SEOでは上位に入っているページでも、AI検索からは完全に無視されていたのです。
原因を調べていくうちに、2つのファイルの存在に辿り着きました。robots.txt と llms.txt です。
robots.txt は知っている方が多いでしょう。でもAIクローラー向けの設定をしている人は、驚くほど少ない。そして llms.txt に至っては、存在すら知らないエンジニアがほとんどではないでしょうか。
この記事では、この2つのファイルを15分で設定する手順を、テンプレート付きで解説します。
llms.txt とは何か
llms.txt は、Answer.AI の Jeremy Howard 氏が2024年に提案した新しいウェブ標準です。
サイトのルート(yoursite.com/llms.txt)に置く Markdown ファイルで、LLM に「うちのサイトはこういう内容で、特にここが重要ですよ」と伝えるコンシェルジュのような役割を持ちます。
robots.txt との違い
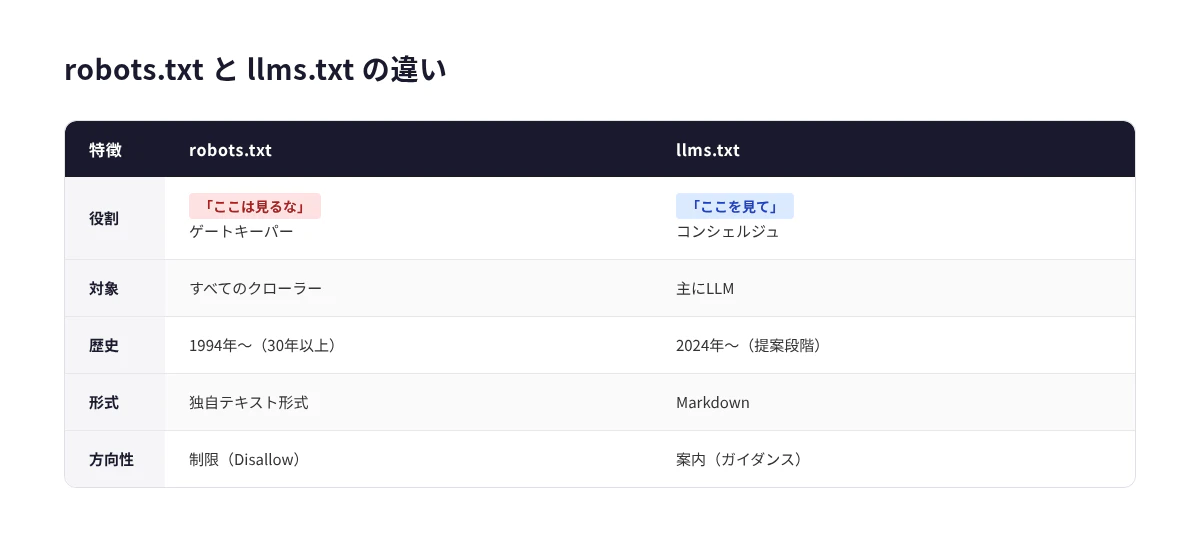
robots.txt が「入るな」と指示するゲートキーパーなら、llms.txt は「ここが重要です」と案内するコンシェルジュです。
sitemap.xml では代替できない
「sitemap.xml があれば十分では?」と思うかもしれません。しかし:
- sitemap.xml は全ページの一覧。LLM に有用なページは厳選が必要
- Markdown版URL(LLMが読みやすい形式)を含められない
- 大規模サイトでは巨大すぎてコンテキストウィンドウに収まらない
- ページの説明や関係性の情報がない
llms.txt は「AIにとって本当に重要なページだけ」を渡すための仕組みです。
llms.txt を5分で作る
ファイル仕様
| 項目 | 要件 |
|---|---|
| 配置場所 | yoursite.com/llms.txt |
| フォーマット | Markdown |
| エンコーディング | UTF-8 |
| 推奨サイズ | 10KB以下 |
テンプレート: 技術ブログ向け
# あなたのブログ名
> フルスタックエンジニアの技術ブログ。Next.js、TypeScript、
> AI/MLに関する実践的な記事を公開しています。
## 人気記事
- [記事タイトル](https://example.com/blog/article-1): 記事の簡潔な説明
- [記事タイトル](https://example.com/blog/article-2): 記事の簡潔な説明
## チュートリアル
- [ガイドタイトル](https://example.com/docs/guide-1): ガイドの簡潔な説明
## 著者について
- [プロフィール](https://example.com/about): 経歴、スキル、連絡先
## Optional
- [年間まとめ](https://example.com/blog/yearly-review): コンテキストに余裕がある場合に参照
必須要素は2つだけ:
-
# サイト名(H1タイトル、1つだけ) -
> サイトの説明(ブロッククオート、1〜2文)
テンプレート: SaaS/プロダクト向け
# ProductName
> クラウドベースのプロジェクト管理ツール。5,000社以上が利用。
## プロダクト
- [機能一覧](https://product.com/features): 主要機能の詳細
- [料金プラン](https://product.com/pricing): Free / Pro / Enterprise
- [API Documentation](https://product.com/docs/api): REST API仕様
## リソース
- [導入事例](https://product.com/cases): 業種別の導入効果
- [FAQ](https://product.com/faq): 導入・運用のQ&A
## Optional
- [ブログ](https://product.com/blog): 製品アップデートと業界動向
llms-full.txt との使い分け
llms.txt 仕様には llms-full.txt という拡張も提案されています。
- llms.txt: リンク集(10KB以下)。「ここが重要」と案内する
- llms-full.txt: コンテンツ全体をインラインで含む(サイズ制限なし)
まずは llms.txt を実装して、効果を確認してから llms-full.txt を検討してください。
robots.txt のAIクローラー設定を10分で見直す
主要AIクローラー一覧(2026年版)
| クローラー名 | 運営元 | User-Agent | 用途 |
|---|---|---|---|
| GPTBot | OpenAI | GPTBot |
ChatGPT学習データ・RAG |
| ChatGPT-User | OpenAI | ChatGPT-User |
ChatGPTのBrowse機能 |
| ClaudeBot | Anthropic | ClaudeBot |
Claude学習データ |
| Google-Extended | Google-Extended |
Gemini学習データ | |
| PerplexityBot | Perplexity | PerplexityBot |
Perplexity RAG |
| Applebot-Extended | Apple | Applebot-Extended |
Apple Intelligence |
| Bytespider | ByteDance | Bytespider |
TikTok AI |
あなたの robots.txt、AIをブロックしていませんか?
意外と多いのが、意図せずAIクローラーをブロックしているケースです。
# こうなっていませんか?
User-agent: *
Disallow: /
Allow: /public/
この設定だと Googlebot は明示的に許可していても、GPTBot や ClaudeBot は * に該当してブロックされます。
推奨設定: 全面許可(AI検索最適化重視)
# robots.txt
User-agent: Googlebot
Allow: /
User-agent: GPTBot
Allow: /
Disallow: /admin/
Disallow: /api/
User-agent: ChatGPT-User
Allow: /
Disallow: /admin/
Disallow: /api/
User-agent: ClaudeBot
Allow: /
Disallow: /admin/
Disallow: /api/
User-agent: Google-Extended
Allow: /
Disallow: /admin/
Disallow: /api/
User-agent: PerplexityBot
Allow: /
Disallow: /admin/
Disallow: /api/
User-agent: Applebot-Extended
Allow: /
Disallow: /admin/
Disallow: /api/
User-agent: *
Disallow: /admin/
Disallow: /api/
Sitemap: https://example.com/sitemap.xml
選択的許可(有料コンテンツ保護)
ブログは許可、プレミアム記事は保護する場合:
User-agent: GPTBot
Allow: /blog/
Allow: /docs/
Allow: /faq/
Disallow: /premium/
Disallow: /members-only/
全面ブロックはやめた方がいい
# ⚠️ これはおすすめしません
User-agent: GPTBot
Disallow: /
全面ブロックは、AI回答からあなたのサイトが完全に消えることを意味します。あなたがブロックしている間に、競合が引用ポジションを獲得します。
AIが読めないコンテンツに注意
設定が完璧でも、AIクローラーはJavaScriptを実行しないことが多いです。
<!-- ❌ AIに見えない -->
<div class="accordion" style="display: none;">
<p>重要な情報がここに...</p>
</div>
<!-- ✅ AIに見える -->
<div class="faq-answer">
<p>重要な情報がここに...</p>
</div>
タブ、アコーディオン、JavaScript で動的生成されるコンテンツは認識されない可能性があります。重要情報は必ずHTMLで直接提供してください。
効果の確認: サーバーログを見る
設定後は、実際にAIクローラーが来ているか確認しましょう。
# Nginxログからai関連クローラーのアクセスを抽出
grep -E "GPTBot|ClaudeBot|Google-Extended|PerplexityBot" \
/var/log/nginx/access.log | \
awk '{print $1, $4, $7, $14}' | head -20
# User-Agent別のアクセス数を集計
grep -oE "GPTBot|ClaudeBot|Google-Extended|PerplexityBot" \
/var/log/nginx/access.log | \
sort | uniq -c | sort -rn
まとめ: 15分の投資で、AI検索の土俵に立てる
| やること | 所要時間 | 効果 |
|---|---|---|
| llms.txt を作成・配置 | 5分 | AIに「重要ページ」を直接伝える |
| robots.txt のAIクローラー設定見直し | 10分 | AI検索からの排除を防ぐ |
この2つのファイルを設定するだけで、あなたのサイトはAI検索の「土俵」に立てます。設定しなければ、土俵にすら上がれません。
llms.txt はまだ提案段階ですが、実装コスト15分・デメリットゼロです。やらない理由がありません。
参考
- LLMO Framework -- LLMOの5つのコアコンポーネント(Knowledge Clarity / Structural Formatting / Retrieval Signals / Authority Signals / Citation Signals)を定義したフレームワーク
- llms.txt 提案仕様 -- Jeremy Howard氏によるllms.txtの公式仕様
本記事の内容をさらに深掘りした「AI検索で自社サイトを上位表示させる体系的な方法」については、拙著で詳しく解説しています。
📕 なぜあなたのサイトはChatGPTに無視されるのか -- LLMO実践ガイド(Amazon Kindle)
JSON-LD構造化データの実装、GEO論文に基づく引用率+115%の手法、Python測定スクリプトなど、本記事では扱いきれなかった実装テクニックを全12章で解説しています。