llms.txtをサイトに置いたものの、AIクローラーが本当に来ているか不安になっているWeb担当者の方、いらっしゃいませんか。
私は2025年からLLMO(LLM Optimization)を回している側ですが、llms.txtは「サイトの目次」を提供するだけで、個別ページの中身をAIに渡す役割は別に必要だと最近気づきました。それが今回紹介するURL.mdパターンです。
本記事ではAstroでの実装を中心に、URL.mdパターンの設計思想・実装コード・AIクローラーの挙動まで整理します。
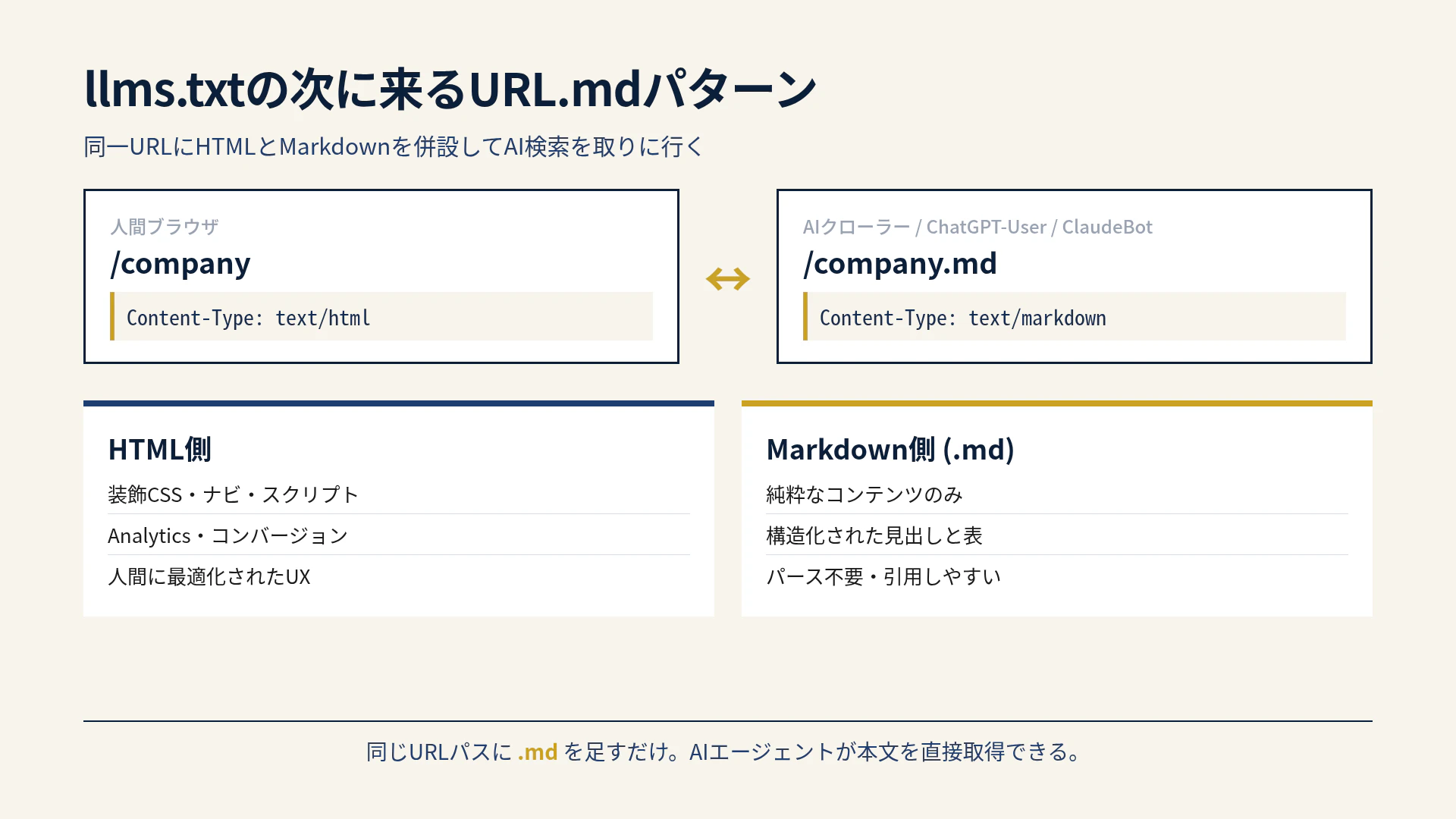
結論: 「/page」と「/page.md」を併設する
短く言うと、これだけです。
/company → HTML(人間用)
/company.md → Markdown(AI用)
AIエージェントがWeb上の情報を取得するとき、HTMLからナビ・装飾・スクリプトを除いて純コンテンツを抽出する処理は重く、そして失敗しやすい。最初からMarkdownで返せば、AIはパース不要でそのままコンテキストに使えます。
llms.txtがサイト全体の概要マップを提供するのに対し、URL.mdは各ページの中身を提供します。両者は補完関係です。
なぜURL.mdが必要か: llms.txtだけでは足りない理由
llms.txtはAnswer.AI共同創設者のJeremy Howard氏が2024年9月に提唱した仕様です。私もすぐ自社サイトに設置し、Qiitaにもllms.txtとrobots.txt 15分で設定する記事を書きました。
しかし1年運用して気づいたことがあります。
-
llms.txtは目次を提供する → どのページに何があるか分かる -
llms.txtは本文を提供しない → 結局AIがHTMLを取りに行く
そして問題はその先です。AIエージェントがHTMLを取りに行くと、Tailwindでガチガチに装飾されたページから本文を抽出するために1ページ数千トークンを消費します。重要な見出し構造が<div>の海に埋もれていれば、抽出精度も落ちます。
SERanking社の30万ドメイン調査(2025年11月)によると、llms.txtの有無はAI引用率に統計的に有意な差を生んでいません。「LLMが/llms.txtを真っ先に取りに来る」という前提は、実測値では成立していないようです。私もこのデータを見るまでは「設置した時点で半分勝ち」くらいの気持ちでいたので、ちょっと正座しました。
URL.mdパターンは「llms.txtを補完する」より「HTMLパースのコストを根本的に削る」アプローチです。
Astroでの実装
私が運用するサイトはAstroで動いているので、Astroの例で書きます。
Step 1: APIルートで.mdエンドポイントを作る
src/pages/company.md.tsを作ります(.ts拡張子+前段の.mdがAstroの動的ルート規約)。
import type { APIRoute } from 'astro';
export const GET: APIRoute = () => {
const content = `# 株式会社サンプルテック — 会社情報
## 基本情報
| 項目 | 内容 |
|------|------|
| 会社名 | 株式会社サンプルテック |
| 代表者 | 山田 太郎 |
| 設立 | 2025年4月 |
## ミッション
エンジニアの可処分時間を取り戻す。
`;
return new Response(content, {
headers: { 'Content-Type': 'text/markdown; charset=utf-8' },
});
};
ポイントは3つ。
- Content-Type: text/markdown — AIに「これはMarkdownだ」と明示
- charset=utf-8 — 日本語のページでは必須
- APIルート — ビルド時に静的ファイルとして書き出される(SSGでも動く)
Step 2: データソースを共有する
HTMLページとMarkdownエンドポイントで異なる内容を返すとAIが混乱します。src/data/company.jsonのような単一のデータソースから両方をレンダリングするのが基本です。
// src/data/company.json
{
"name": "株式会社サンプルテック",
"ceo": "山田 太郎",
"founded": "2025-04",
"mission": "エンジニアの可処分時間を取り戻す。"
}
// src/pages/company.md.ts
import companyData from '../data/company.json';
export const GET: APIRoute = () => {
const md = `# ${companyData.name} — 会社情報
## 基本情報
| 項目 | 内容 |
|------|------|
| 会社名 | ${companyData.name} |
| 代表者 | ${companyData.ceo} |
| 設立 | ${companyData.founded} |
## ミッション
${companyData.mission}
`;
return new Response(md, {
headers: { 'Content-Type': 'text/markdown; charset=utf-8' },
});
};
これでsrc/pages/company.astro(HTML)とsrc/pages/company.md.ts(MD)が同じcompany.jsonから派生し、一貫性が保たれます。
Step 3: llms.txtからリンクを張る
llms.txtの「詳細情報」セクションで、各.mdエンドポイントを案内します。
# Sample Tech Inc.
## サマリ
エンジニアの可処分時間を取り戻すスタートアップ。
## 詳細情報
- AI向け会社情報: https://example.com/company.md
- AI向け事業情報: https://example.com/products.md
- AI向けFAQ: https://example.com/faq.md
AIエージェントはllms.txtを起点に、必要な.mdエンドポイントへ自律的に辿り着けるようになります。
Next.js / Nuxt / SvelteKitでの実装
他のフレームワークでも同じことができます。
Next.js (App Router)
// app/company.md/route.ts
export async function GET() {
return new Response(`# 株式会社サンプルテック...`, {
headers: { 'Content-Type': 'text/markdown; charset=utf-8' },
});
}
Nuxt
// server/api/company.md.get.ts
export default defineEventHandler((event) => {
setHeader(event, 'Content-Type', 'text/markdown; charset=utf-8');
return `# 株式会社サンプルテック...`;
});
SvelteKit
// src/routes/company.md/+server.ts
export const GET = () => {
return new Response(`# 株式会社サンプルテック...`, {
headers: { 'Content-Type': 'text/markdown; charset=utf-8' },
});
};
どのフレームワークでも数十行のコードで実装可能です。public/に直接.mdを置く手もありますが、Content-Typeをホスティング側がどう返すか不確定になるので、私はAPIルート派です。
AIクローラーは本当に.mdを読むのか
実装しても「で、AIクローラーって本当に.mdを取りに来るの」が次の疑問です。
私のサイトのアクセスログから抜粋すると、主要AIユーザーエージェントは次の通り出てきます。
| User-Agent | 主体 | 何のために来るか |
|---|---|---|
ChatGPT-User/1.0 |
OpenAI | ChatGPTセッション中のリアルタイム取得 |
OAI-SearchBot/1.0 |
OpenAI | ChatGPT Search用インデックス |
GPTBot/1.0 |
OpenAI | 学習データ収集 |
ClaudeBot/1.0 |
Anthropic | 学習データ収集 |
Claude-User/1.0 |
Anthropic | Claudeセッション中の取得 |
Claude-SearchBot/1.0 |
Anthropic | Claude検索用 |
PerplexityBot/1.0 |
Perplexity | Perplexity Web検索 |
Claude-SearchBotはClaudeBotと独立して制御できる仕様になっていて、「学習データ収集はブロック、検索のための取得は許可」のような細かい運用が可能になっています(2026年5月時点)。
私のサイトでは.mdエンドポイントへのアクセスログを別途取っていて、上記のBotから.mdを直接fetchしている形跡があります。割合は全アクセスの数%ですが、ゼロではないことが確認できています。
robots.txtとの組み合わせ
URL.mdを置くならrobots.txtも整理しておくべきです。
# robots.txt
User-Agent: GPTBot
Disallow: /
User-Agent: ClaudeBot
Disallow: /
User-Agent: ChatGPT-User
Allow: /
User-Agent: Claude-User
Allow: /
User-Agent: Claude-SearchBot
Allow: /
User-Agent: OAI-SearchBot
Allow: /
「学習データ収集はNG / リアルタイム引用とAI検索は許可」というよくある方針はこれで実現できます。Disallow:は厳密遵守ではない(無視するBotもいる)ので、本当にブロックしたいトラフィックはエッジでブロックすべきですが、規約上の意思表示としては有効です。
実装フレームワークのllmoframework.comが、こうしたUser-Agent×ポリシーのパターンを公開しているので、設計の起点に使うと早いです。
計測のしどころ
URL.mdを置いたら、効果を測りたくなるはずです。私は次のメトリクスを見ています。
# nginxのアクセスログから1日のAIクローラー流入を集計
grep -E "ChatGPT-User|ClaudeBot|PerplexityBot|GPTBot" access.log \
| awk '{print $7}' \
| sort | uniq -c | sort -rn | head -20
-
.mdエンドポイント別ヒット数 — どのページがAIに読まれているか - User-Agent別の割合 — ChatGPT vs Claude vs Perplexityのシェア
- HTMLとMDのfetch比 — AIが.mdを優先しているか
私のサイトでは2026年Q1で「ChatGPT-User系 41% / Claude系 28% / Perplexity 15% / その他 16%」でした。サイトの内容で割合は大きく変わるので、自分で測ることをお勧めします。
まとめ
- URL.mdパターンは「llms.txtの次のステップ」 — サイト目次から個別ページ本文へ
- 同じデータソースから生成する — HTMLと中身がズレるとAIが混乱
- Content-Type: text/markdownが命 — text/plainでは構造を活かせない
- AIクローラーは確実に来ている — ログで実測すべき
- llms.txt / robots.txt / URL.md を3点セットで — それぞれ違う役割
URL.mdパターンを含む実装パターンを体系化したZenn Book「LLMO Webサイトビルダー」(全10章)で、Astro実装の完全コードとPlaywrightでの検証手順まで載せています。
LLMO Website Builder (Kenimoto)
あなたのサイトはURL.md対応していますか。AIクローラー(ChatGPT-User / ClaudeBot等)のアクセス数の変化を計測した方のデータ、ぜひコメントで募集します。私もまだ「.mdを置いたら本当に引用が増えたか」を半年スパンで測っている途中で、対照データが集まると判断材料になります。