やりたいこと
- https://storage.googleapis.com/openimages/web/download.html からダウンロードできるデータセットの見方を知りたい。
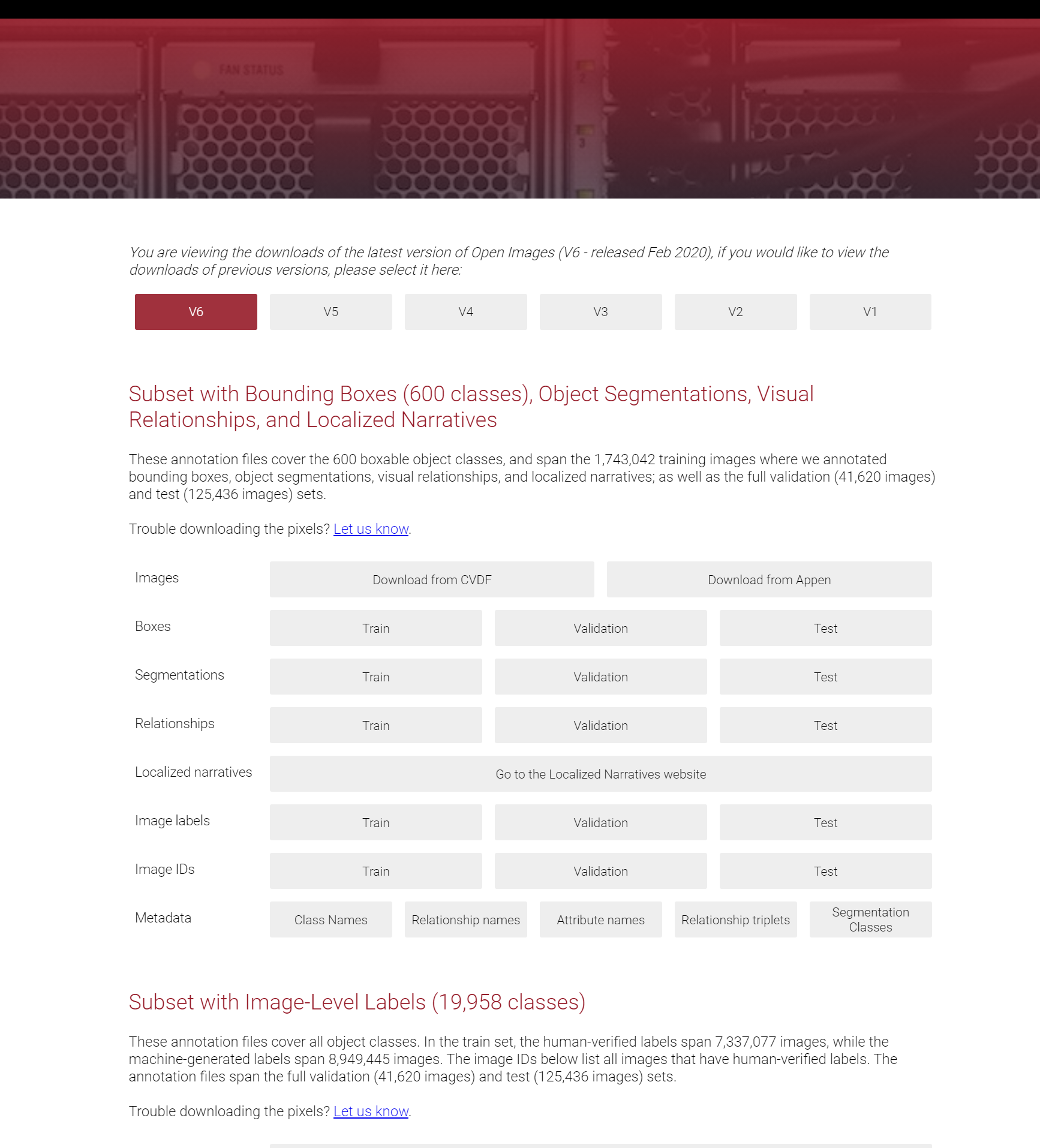
各データの概要
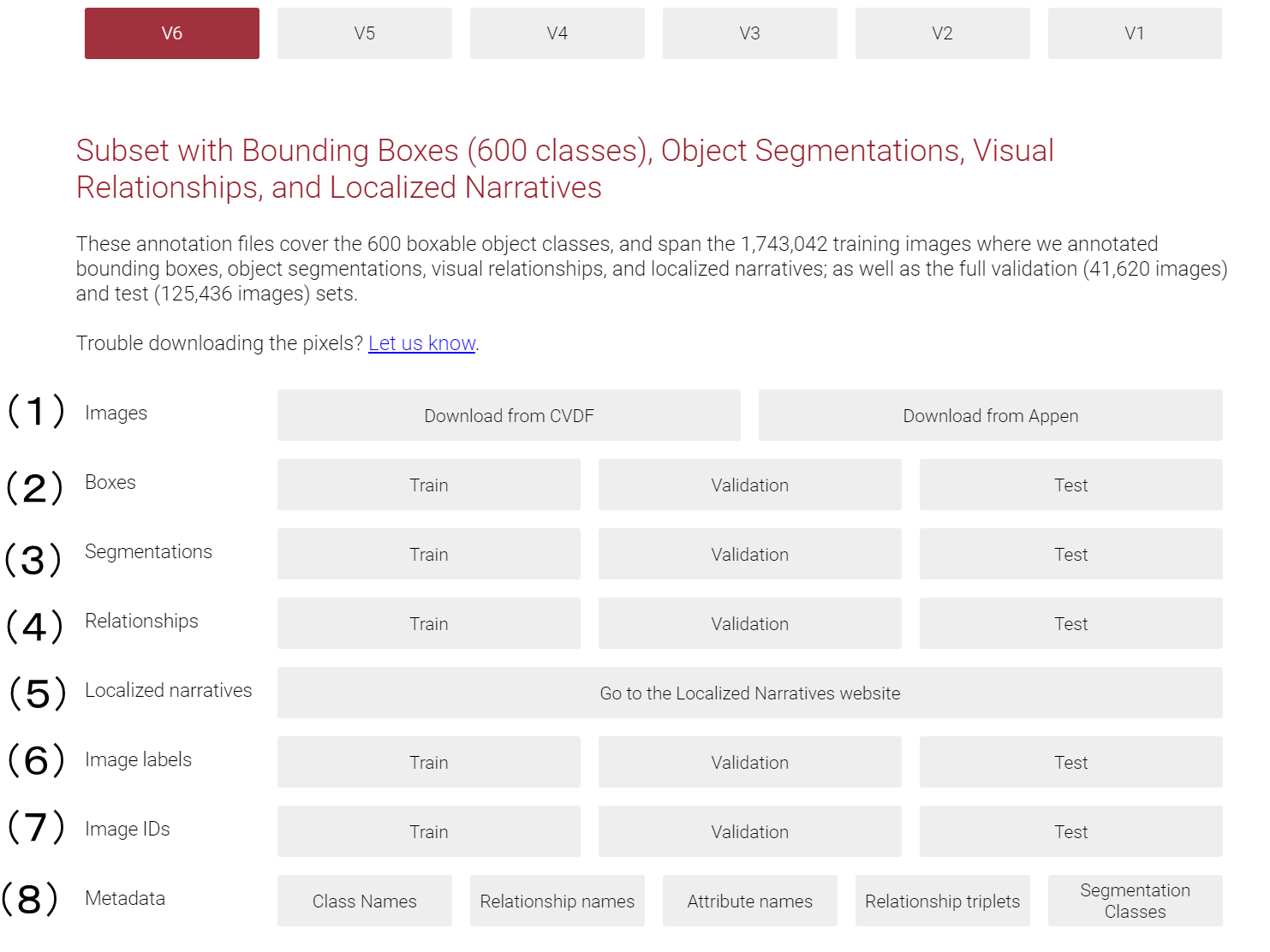
(1)Images
学習用データとして用いる画像ファイル(.jpg)の実体をダウンロードできる。

(2)Boxes
oidv6-train-annotations-bbox.csv がダウンロードできる。ImageIDをキーとして、そのイメージに移りこんだ対象物のラベル名および、その対象物の位置を示す矩形領域(相対位置)が書かれている。

(3)Segmentations
train-masks-0.zip などをダウンロードできる。これは「Imagesでダウンロードしたjpg写真」に重ねることで「対象物以外をマスキングする」ことができる画像である。

たとえば、ImageIDが0000c4f95a9d5a54の場合。
0000c4f95a9d5a54.jpg

ここで、train-masks-0 フォルダに含まれる 0000c4f95a9d5a54_m01226z_6491f7bc.png は、サッカーボール以外の領域をマスクする画像である。
0000c4f95a9d5a54_m01226z_6491f7bc.png

重ね合わせると下記。

(4)Relationships
oidv6-train-annotations-vrd.csv をダウンロードできる。

ImageIDをキーとして、
ImageID,LabelName1,LabelName2,XMin1,XMax1,YMin1,YMax1,XMin2,XMax2,YMin2,YMax2,RelationshipLabel
000506542b3a9dd7,/m/03bt1vf,/m/019nj4,0.159326,0.407383,0.182617,0.999023,0.159326,0.407383,0.182617,0.999023,is
000506542b3a9dd7,/m/03bt1vf,/m/019nj4,0.709845,0.999352,0.234375,0.999023,0.709845,0.999352,0.234375,0.999023,is
000506542b3a9dd7,/m/03bt1vf,/m/02wzbmj,0.000000,0.150907,0.108398,0.999023,0.000000,0.150907,0.108398,0.999023,is
000506542b3a9dd7,/m/03bt1vf,/m/02wzbmj,0.159326,0.407383,0.182617,0.999023,0.159326,0.407383,0.182617,0.999023,is
000506542b3a9dd7,/m/03bt1vf,/m/02wzbmj,0.709845,0.999352,0.234375,0.999023,0.709845,0.999352,0.234375,0.999023,is
00083be471c81e1b,/m/03bt1vf,/m/083mg,0.149565,0.646087,0.075625,0.979375,0.149565,0.646087,0.075625,0.979375,is
00083be471c81e1b,/m/03bt1vf,/m/083mg,0.424348,0.847826,0.087500,0.923750,0.424348,0.847826,0.087500,0.923750,is
000ac95750ac7399,/m/04yx4,/m/019nj4,0.049375,0.560625,0.084270,0.999064,0.049375,0.560625,0.084270,0.999064,is
000ac95750ac7399,/m/04yx4,/m/019nj4,0.485625,0.658750,0.496255,0.999064,0.485625,0.658750,0.496255,0.999064,is
000ac95750ac7399,/m/04yx4,/m/02wzbmj,0.049375,0.560625,0.084270,0.999064,0.049375,0.560625,0.084270,0.999064,is
000ac95750ac7399,/m/04yx4,/m/02wzbmj,0.485625,0.658750,0.496255,0.999064,0.485625,0.658750,0.496255,0.999064,is
000d1d89a1939a18,/m/01bl7v,/m/015c4z,0.337500,0.417500,0.482109,0.838983,0.337500,0.417500,0.482109,0.838983,is
000d1d89a1939a18,/m/01bl7v,/m/019nj4,0.484375,0.591250,0.044256,0.387947,0.484375,0.591250,0.044256,0.387947,is
のようなデータが確認できる。
(5)Localized narratives
へリンクする。利用方法は未調査のため不明。
(6)Image labels
train-annotations-human-imagelabels-boxable.csv がダウンロードできる。

下記のようなデータが格納されている。
ImageID,Source,LabelName,Confidence
000002b66c9c498e,verification,/m/014j1m,0
000002b66c9c498e,verification,/m/014sv8,1
000002b66c9c498e,verification,/m/01599,0
たとえば、
000fe11025f2e246.jpg
の場合。
ImageID: 000fe11025f2e246

この写真に対する各ラベルの名称と信頼性
ImageID Source LabelName Name Confidence
000fe11025f2e246 crowdsource-verification /m/0199g Bicycle 1
000fe11025f2e246 crowdsource-verification /m/07jdr Train 0
000fe11025f2e246 verification /m/015qff Traffic light 0
000fe11025f2e246 verification /m/018p4k Cart 0
000fe11025f2e246 verification /m/01bjv Bus 0
000fe11025f2e246 verification /m/01g317 Person 1
000fe11025f2e246 verification /m/01knjb Billboard 0
000fe11025f2e246 verification /m/01mqdt Traffic sign 0
000fe11025f2e246 verification /m/01prls Land vehicle 1
000fe11025f2e246 verification /m/04_sv Motorcycle 1
000fe11025f2e246 verification /m/07j7r Tree 1
000fe11025f2e246 verification /m/07yv9 Vehicle 1
000fe11025f2e246 verification /m/083wq Wheel 1
000fe11025f2e246 verification /m/0cgh4 Building 0
000fe11025f2e246 verification /m/0k4j Car 1
000fe11025f2e246 verification /m/0pcr Alpaca 0
000fe11025f2e246 verification /m/0pg52 Taxi 0
000fe11025f2e246 verification /m/0zvk5 Helmet 0
Confidenceが1なのは
- Bicycle
- Person
など。
Confidenceが0なのは
- Alpaca
- Taxi
など。
すなわち
「この写真には、自転車や人が写っていることは信頼できるが、アルパカやタクシーが写っていることは信頼できない」となる。
(7)Image IDs

train-images-boxable-with-rotation.csv をダウンロードできる。
ImageIDをキーとして
ImageID,Subset,OriginalURL,OriginalLandingURL,License,AuthorProfileURL,Author,Title,OriginalSize,OriginalMD5,Thumbnail300KURL,Rotation
といったデータが保存されているが、用途の詳細は未調査のため不明。
(8)Metadata

Class Names
class-descriptions-boxable.csv がダウンロードできる。
/m/011k07,Tortoise
/m/011q46kg,Container
/m/012074,Magpie
.....以下省略
Relationship names
oidv6-relationships-description.csv がダウンロードできる。
at,at
holds,holds
wears,wears
surf,surf
.....以下省略
Attribute names
oidv6-attributes-description.csv がダウンロードできる。
/m/02gy9n,Transparent
/m/05z87,Plastic
/m/0dnr7,(made of)Textile
/m/04lbp,(made of)Leather
/m/083vt,Wooden
/m/02wzbmj,Stand
/m/083mg,Walk
/m/06h7j,Run
/m/0by3w,Jump
/m/015c4z,Sit
/m/051_dmw,Lay
/m/019nj4,Smile
/m/0463cq4,Cry
/m/015lz1,Sing
/m/01lhf,Talk
Relationship triplets
oidv6-relationship-triplets.csv がダウンロードできる。
LabelName1,LabelName2,RelationshipLabel
/m/03bt1vf,/m/02wzbmj,is
/m/01y9k5,/m/083vt,is
/m/04yx4,/m/0jyfg,wears
/m/02p5f1q,/m/02vqfm,contain
.....以下省略
Segmentation Classes
https://storage.googleapis.com/openimages/v5/classes-segmentation.txt へのリンク。
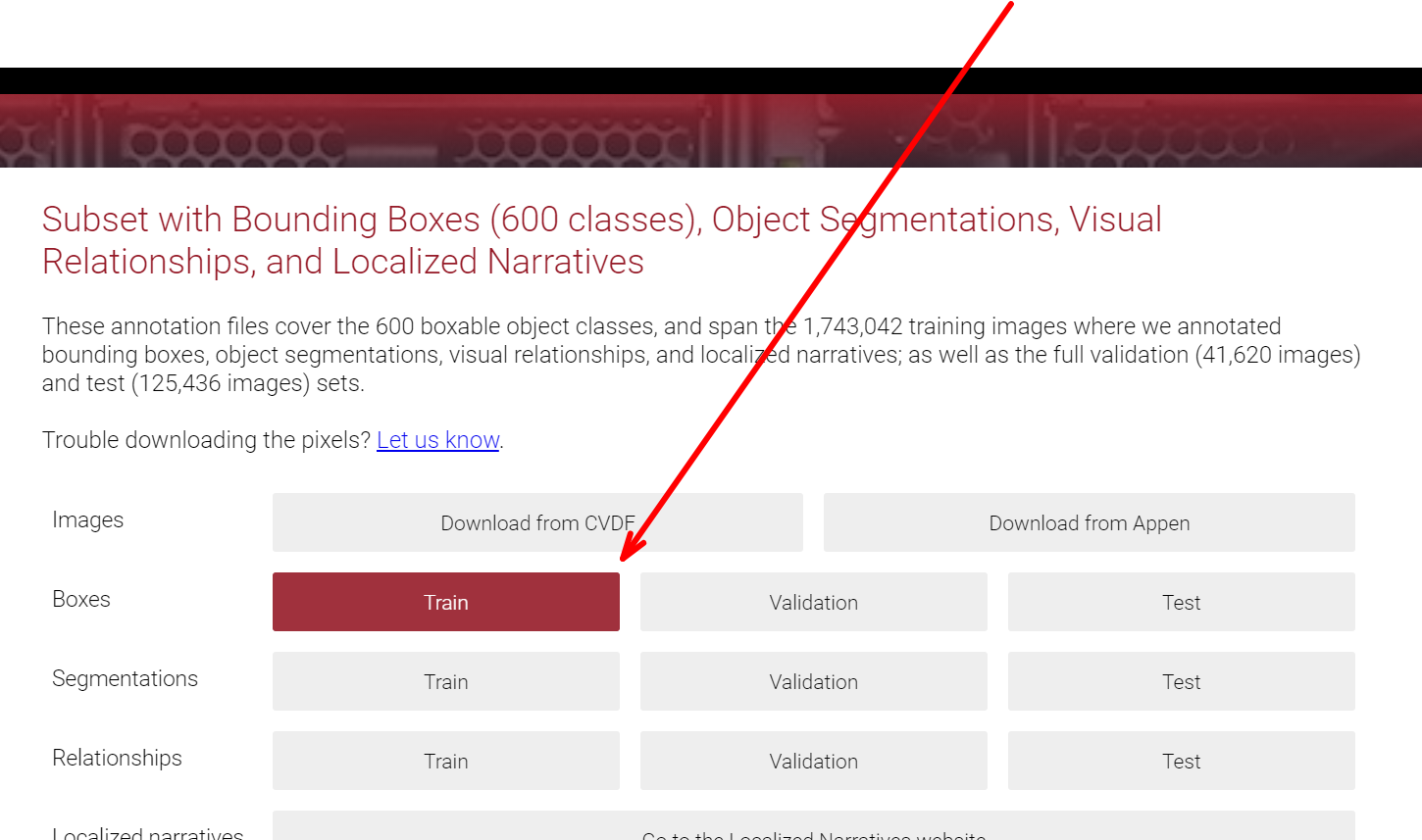
画像データをダウンロードする
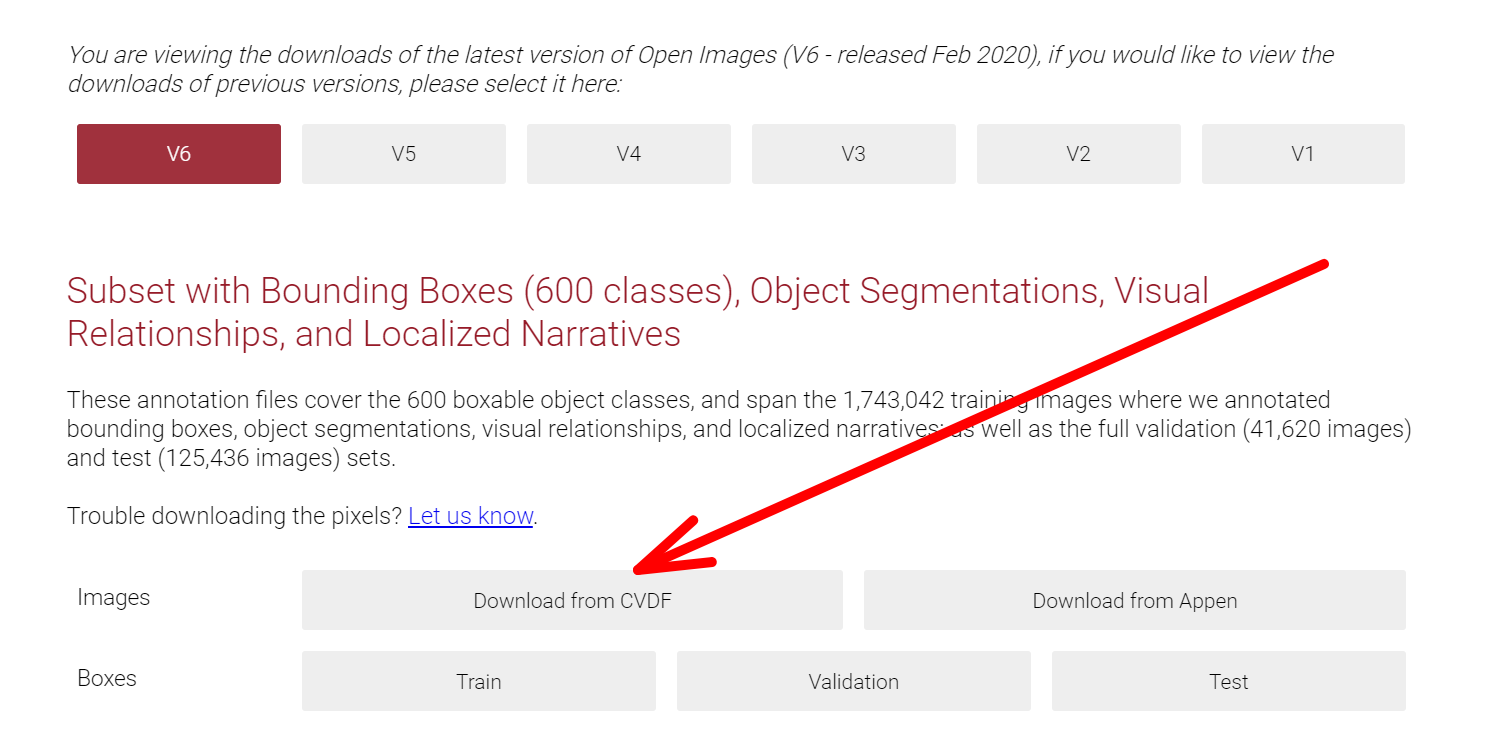
下記に記載のとおり、AWSのCLIにてダウンロードできる。
https://github.com/cvdfoundation/open-images-dataset#download-images-with-bounding-boxes-annotations
事前にawscliをインストールしておく。
awscliのインストール手順
CentOSの場合: https://qiita.com/kenichiro-yamato/items/039ba9a9867e177e67f0
Windowsの場合: https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2-windows.html
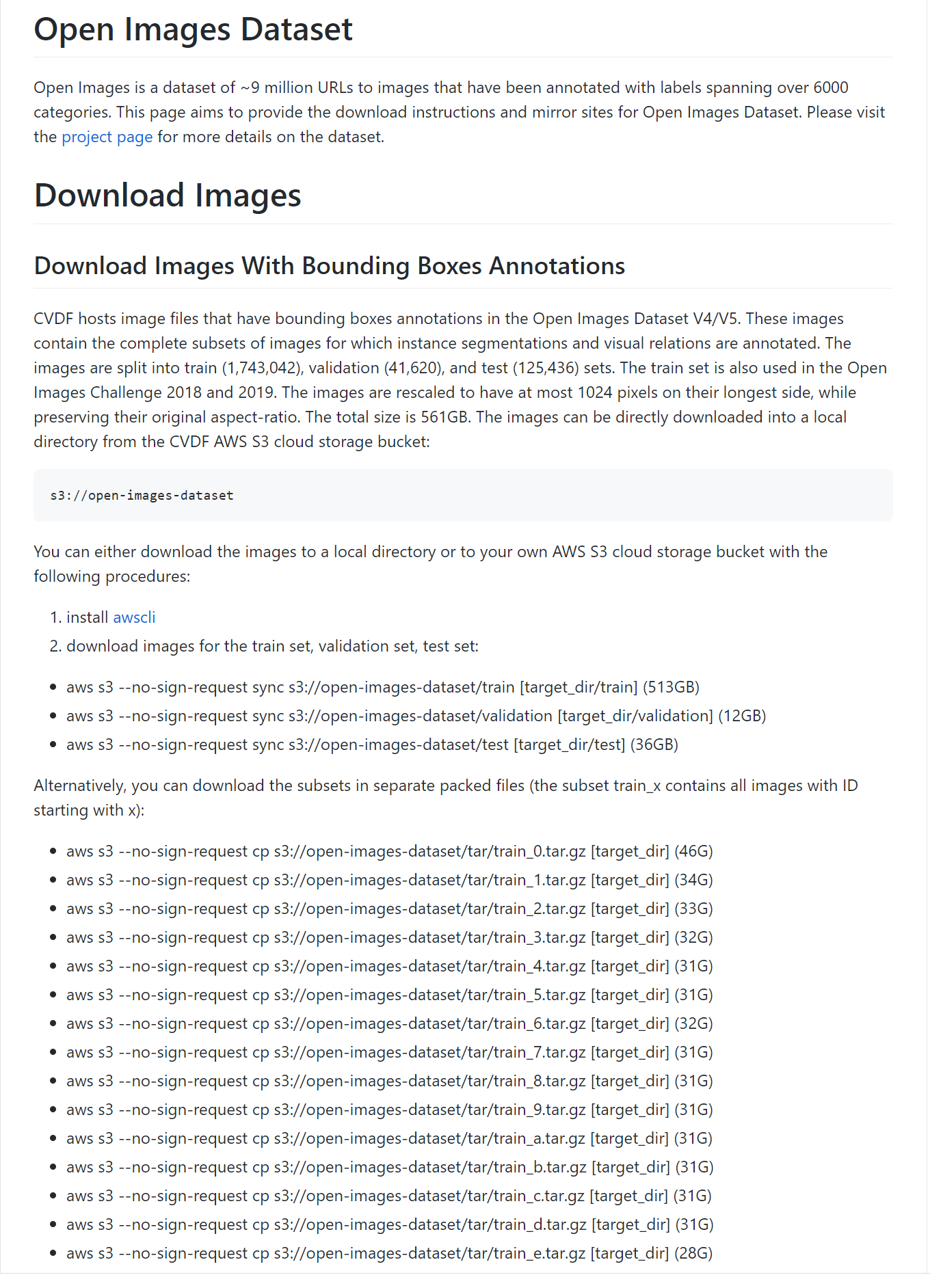
まずは下記コマンドにて、train_0.tar.gz をダウンロードする。
aws s3 --no-sign-request cp s3://open-images-dataset/tar/train_0.tar.gz .
画像データの構成
ダウンロードしたアーカイブを解凍すると、フォルダ内にjpgファイルが保存されている。

ここでは例として
0000e8b36676338b.jpg
に着目する。
ImageID: 0000e8b36676338b
ImageIDは、画像を一意に識別できるIDである。
ファイル名がImageIDになっている。
縦横ピクセル width: 1024px height: 685px

何の写真なのか?を調べる
Metadata の ClassNames からダウンロードできるファイル
class-descriptions-boxable.csv
を参照すると、
/m/01prls,Land vehicle
という記載がある。つまり「Land vehicle」(陸上車両)の写真である。
ここで、
/m/01prls
は、LabelName(ラベルネーム)と呼ばれる識別子である。
ImageIDに紐づくLabelName(ラベルネーム)を求める方法
ImageIDとLabelNameの対応は、
oidv6-train-annotations-bbox.csv
に記載されている。
BoxesのTrainからダウンロードできる。
このCSVをImageIDで検索すれば、LabelNameが求まる。

つまり
ImageID:0000e8b36676338b は LabelName:/m/01prls なので Land vehicle
となる。
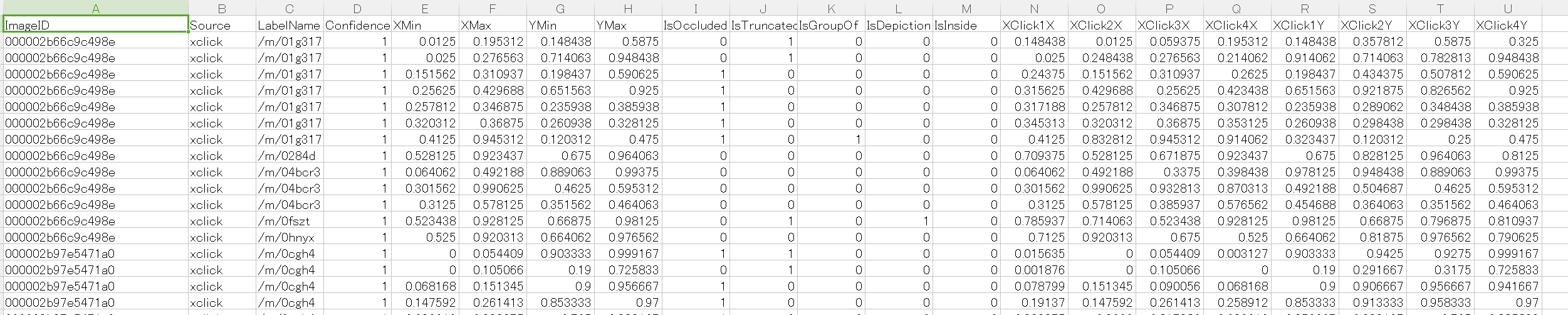
oidv6-train-annotations-bbox.csv の詳細
さらに詳細を見ていくと、下記の記載がある。
ImageID: 0000e8b36676338b
Source: xclick
LabelName: /m/01prls
Confidence: 1
XMin: 0.07
XMax: 0.89375
YMin: 0.139122
YMax: 0.835668
IsOccluded: 0
IsTruncated: 0
IsGroupOf: 0
IsDepiction: 0
IsInside: 0
XClick1X: 0.431875
XClick2X: 0.07
XClick3X: 0.36875
XClick4X: 0.89375
XClick1Y: 0.139122
XClick2Y: 0.641457
XClick3Y: 0.835668
XClick4Y: 0.449113
各数値からピクセル位置を計算する。
W:1024
H:685
column rate w, h px
--------------------------------
XMin 0.07 1024 72
XMax 0.89375 1024 915
YMin 0.139122 685 95
YMax 0.835668 685 572
XClick1X 0.431875 1024 442
XClick2X 0.07 1024 72
XClick3X 0.36875 1024 378
XClick4X 0.89375 1024 915
XClick1Y 0.139122 685 95
XClick2Y 0.641457 685 439
XClick3Y 0.835668 685 572
XClick4Y 0.449113 685 308
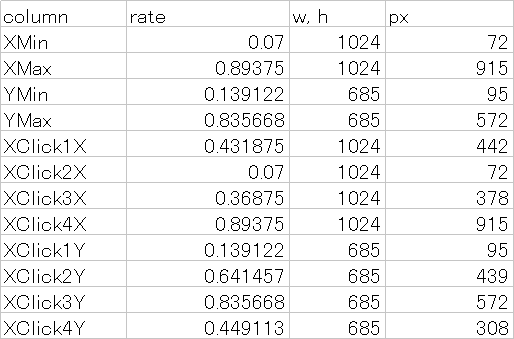
算出したピクセル位置を画像にプロットすると下記のようになる。

これらの数値は「写真全体における、陸上車両が占める相対位置(領域)」を示す。
陸上車両を学習させるためのデータとして利用するには、背景の芝生や樹木と車両を区別する必要があるため。
画像領域識別プログラムの実装例
例として「ある画像データと共に、4点の座標をピクセル値で与えた場合に、その領域をマークする(あるいは切り抜く)」というプログラムの実装を考える。
その場合、関数に与えるべき4点の座標は下記の値になる。

つまり、下記の4つの値
top: 95px
left: 72px
bottom: 572px
right: 915px
を渡すことで、画像内の特定矩形領域を認識できる。
ブラウザ上で表現する場合の実装(HTML, CSS, JavaScript)は、たとえば下記のようになる。
変数boxに各値が入っているならば、
$('#' + id).css('top', box.top);
$('#' + id).css('left', box.left);
$('#' + id).css('width', box.width);
$('#' + id).css('height', box.height);
ここで、
$('#' + id)
は、
position: absolute;
などで重ねる「領域特定用のdivタグ」などを示す。
width = right - left;
height = bottom - top;
で求める。
この実装にて、元画像のimgタグに対して、div領域を重ねることで、
「写真全体において、陸上車両の部分のみを囲む(陸上車両の部分にのみdivを重ねてborderをつける)」
などの処理を実現できる。
一枚の写真に複数の車両が存在する場合
つぎに、
ImageID:000c10e0af86b52d
に着目する。
width: 1024px
height: 768px

この写真のように、複数の車両が写っている画像において、
各車両を識別する矩形データがどのように格納されているかを見る。
下記ファイルから該当データを抽出する。
oidv6-train-annotations-bbox.csv
class-descriptions-boxable.csv
ClassNamesは下記。
/m/01g317,Person
/m/04_sv,Motorcycle
/m/083wq,Wheel
/m/0h9mv,Tire
Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
000c10e0af86b52d /m/01g317 Person
Motorcycle
000c10e0af86b52d /m/04_sv Motorcycle
000c10e0af86b52d /m/04_sv Motorcycle
Wheel
000c10e0af86b52d /m/083wq Wheel
000c10e0af86b52d /m/083wq Wheel
000c10e0af86b52d /m/083wq Wheel
000c10e0af86b52d /m/083wq Wheel
000c10e0af86b52d /m/083wq Wheel
Tire
000c10e0af86b52d /m/0h9mv Tire
000c10e0af86b52d /m/0h9mv Tire
000c10e0af86b52d /m/0h9mv Tire
000c10e0af86b52d /m/0h9mv Tire
000c10e0af86b52d /m/0h9mv Tire
今回は
Motorcycle
に着目し
2台の位置を特定できているか?
を確かめる。
1台目
column rate w, h px
-------------------------------
XMin 0.2375 1024 243
XMax 0.486875 1024 499
YMin 0.445 768 342
YMax 0.639167 768 491

以上のとおり、白いMotorcycleの領域を特定できている。
2台目
column rate w, h px
-----------------------------------
XMin 0.456875 1024 468
XMax 0.83875 1024 859
YMin 0.445 768 342
YMax 0.789167 768 606
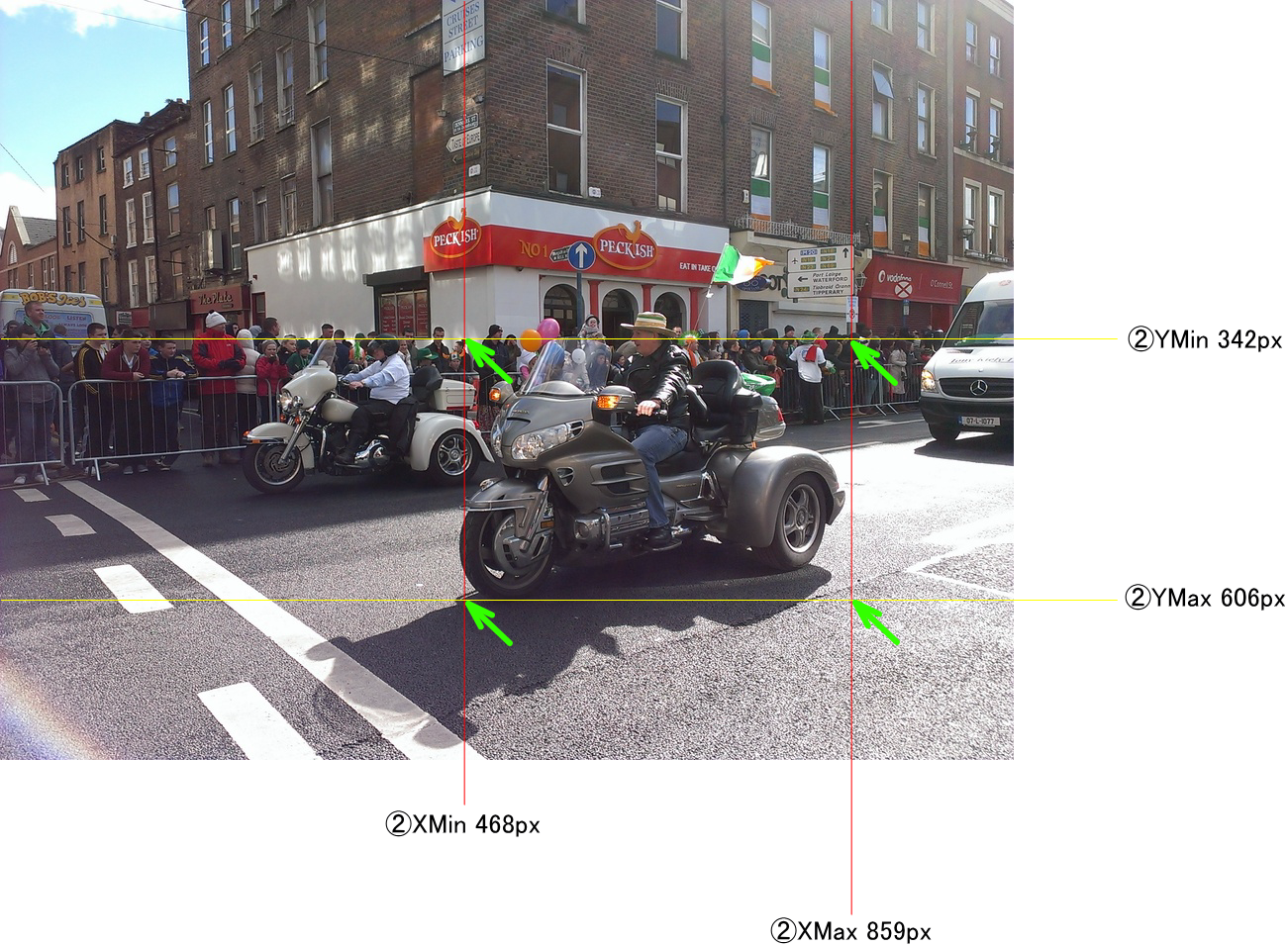
以上のとおり、灰色のMotorcycleの領域を特定できている。
まとめ
グーグルは
Open Images Dataset V6
https://storage.googleapis.com/openimages/web/index.html
にてデータセットを公開している(2020年11月時点)。
今後も公開データは増えて内容も充実していくだろう。
しかし、それを使いこなすためのノウハウ、すなわち
「そのデータをダウンロードして、具体的に、どのように使うのか? 何に役立つのか?」
については、各人での試行錯誤が必要となる。
特に、LAMPでのWebサービス実装をメインとしている(私のような)サーバサイドエンジニアは、
「機械学習の世界で前提とされている知識」が乏しいため、
教師データを構成する各値が「何を表すのか?」が分からなかった。
今回、各値を手作業で調べながら関連性を確かめていくことで、その全容が少しずつ見えてきた。
今後はダウンロードしたデータをDBに突っ込んで(それはサーバサイドエンジニアがもっとも得意とする領域)、
CSVやTSVをRDBにすることでより扱いやすくしたり、Web画面を実装してAPIでデータを呼び出せるようにしたり、
などの作業を進めながら、本来の目的である「機械学習モデルの実装(python, Tensorflow, Keras)にも着手していく予定。