2群の差の推定
はじめに
ベイズモデリングの練習第1弾
いろいろあって時間がなかったが、やっとベイズモデリングに関する練習ができた。
第1回はベイズ統計の2群の差について
参考図書は
「初めての統計データ分析」(https://www.asakura.co.jp/books/isbn/978-4-254-12214-5/)
です。
使用したデータは有名な「iris」
さらにその中でも「pedal.length」(ガクの長さ?)を用いました。
ベイズモデリングするためのソフトにはstan + python (pystan)を使ってます。
ベイズ統計を用いた2群の差について
頻度主義の統計として有名なt検定、それをベイズモデリングで行うのが今回の目的です。
観測データをx1、x2とすると、これらは
x1 ~ normal(mu1, sigma1)
x2 ~ normal(mu2, sigma2)
というふうに生成される。
観測値(x1, x2)から推定された母平均、mu1, mu2を比較することで、
それらに差が存在する確率を議論することが可能になる。
実験
まず、元データについて、ヒストグラムと推定したmuとsigmaで正規分布を書いたplotが下の図
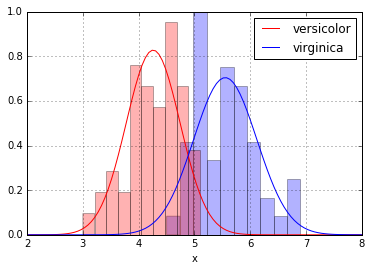
versicolor種とvirginica種についてそれぞれ50データずつ、
確かにplotしただけで、それぞれに差がありそうだとわかる。
次に推定したmu_versicolor, mu_virginicaのプロット
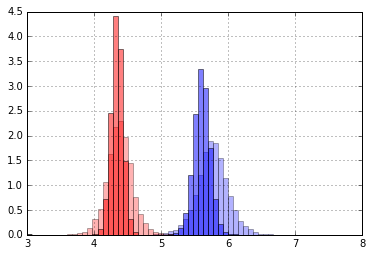
濃い色と薄色があるのは、10サンプルからの推定(薄い方)と30サンプルからの推定(濃い方)の2種類を行ったから。
薄い方が広く分布していることからも、観測数が多い方が、精度の高い推定ができることがわかる。
最後にmu_versicolor - mu_viginicaの10サンプル版、30サンプル版のプロット
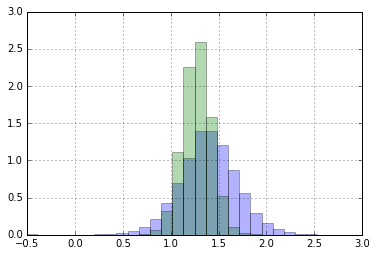
青が10サンプル、緑が30サンプル
このヒストグラムを要約することで(EAPを求める)
ガクの大きさが〜〜cm以上大きい確率を評価することができる。
やはりサンプル数が多い方が、尖度の高いヒストグラムが得られている。
30サンプルの場合、ほとんどの確率で1.0~1.5の差があると評価できる。
結論
今回はベイズ統計を用いた2値の差を評価したが、なかなか使えそう。
p値だけでなく、どれだけ離れてる確率が~~%と出せるところが良い。
また、データの少なさに対する信頼度の低さも同時に評価できていいですね。
自身の修論にも使いたいな〜〜〜