はじめに
いきなりこのページに来られた方は、親ページから参照をお願いいたします。
記事構成

ここの目的
pycharmを使用して、python言語でAIをコーディングします。コードはコピペでOKです。
ソースコード内の意味が分からなくても実行できます。
開発環境の立ち上げ
-
Pythonプログラムを作成するためにpycharm(PyCharm Community Edition)を起動します。前回作ったPJが表示されるので「
mnist」をクリック
-
pycharm起動画面 (mnistプロジェクトが起動されました)
-
このサンプルのソースコードは、AIとは全く関係がないものなので全部消去します (サンプルのソースコードは、
CTL+AしてDELキーで簡単に消せます)
PythonによるAIプログラミング
- ソースコードは以下です。
# ------------------------------------------------------------------------------------------------------------
# CNN(Convolutional Neural Network)でMNISTを試す
# ------------------------------------------------------------------------------------------------------------
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from keras.datasets import mnist
from keras import backend as ke
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
# ------------------------------------------------------------------------------------------------------------
# ハイパーパラメータ
# ------------------------------------------------------------------------------------------------------------
# ハイパーパラメータ ⇒ バッチサイズ、エポック数
# 例えば、訓練データが60,000個で、batch_sizeを6,000とした場合、
# 学習データをすべて使うのに60,000個÷6,000=10回のパラメータ更新が行われる。
# これを1epochと言う。epochが10であれば、10×10=100回のパラメータ更新が行われることとなる。
# epoch数は損失関数(コスト関数)の値がほぼ収束するまでに設定する。
batch_size = 6000 # バッチサイズ
epochs = 5 # エポック数
# ------------------------------------------------------------------------------------------------------------
# 正誤表関数
# ------------------------------------------------------------------------------------------------------------
def show_prediction():
n_show = 100 # 全部は表示すると大変なので一部を表示
y = model.predict(X_test)
plt.figure(2, figsize=(10, 10))
plt.gray()
for i in range(n_show):
plt.subplot(10, 10, (i+1)) # subplot(行数, 列数, プロット番号)
x = X_test[i, :]
x = x.reshape(28, 28)
plt.pcolor(1 - x)
wk = y[i, :]
prediction = np.argmax(wk)
plt.text(22, 25.5, "%d" % prediction, fontsize=12)
if prediction != np.argmax(y_test[i, :]):
plt.plot([0, 27], [1, 1], color='red', linewidth=10)
plt.xlim(0, 27)
plt.ylim(27, 0)
plt.xticks([], "")
plt.yticks([], "")
# ------------------------------------------------------------------------------------------------------------
# keras backendの表示
# ------------------------------------------------------------------------------------------------------------
# print(ke.backend())
# print(ke.floatx())
# ------------------------------------------------------------------------------------------------------------
# MNISTデータの取得
# ------------------------------------------------------------------------------------------------------------
# 初回はダウンロードが発生するため時間がかかる
# 60,000枚の28x28ドットで表現される10個の数字の白黒画像と10,000枚のテスト用画像データセット
# ダウンロード場所:'~/.keras/datasets/'
# ※MNISTのデータダウンロードがNGとなる場合は、PROXYの設定を見直してください
#
# MNISTデータ
# ├ 教師データ (60,000個)
# │ ├ 画像データ
# │ └ ラベルデータ
# │
# └ 検証データ (10,000個)
# ├ 画像データ
# └ ラベルデータ
# ↓教師データ ↓検証データ
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# ↑画像 ↑ラベル ↑画像 ↑ラベル
# ------------------------------------------------------------------------------------------------------------
# 画像データ(教師データ、検証データ)のリシェイプ
# ------------------------------------------------------------------------------------------------------------
img_rows, img_cols = 28, 28
if ke.image_data_format() == 'channels_last':
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
else:
X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols)
X_test = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
# 配列の整形と、色の範囲を0~255 → 0~1に変換
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# ------------------------------------------------------------------------------------------------------------
# ラベルデータ(教師データ、検証データ)のベクトル化
# ------------------------------------------------------------------------------------------------------------
y_train = np_utils.to_categorical(y_train) # 教師ラベルのベクトル化
y_test = np_utils.to_categorical(y_test) # 検証ラベルのベクトル化
# ------------------------------------------------------------------------------------------------------------
# ネットワークの定義 (keras)
# ------------------------------------------------------------------------------------------------------------
print("")
print("●ネットワーク定義")
model = Sequential()
# 入力層 28×28×3
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu', input_shape=input_shape, padding='same')) # 01層:畳込み層16枚
model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) # 02層:畳込み層32枚
model.add(MaxPooling2D(pool_size=(2, 2))) # 03層:プーリング層
model.add(Dropout(0.25)) # 04層:ドロップアウト
model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) # 05層:畳込み層64枚
model.add(MaxPooling2D(pool_size=(2, 2))) # 06層:プーリング層
model.add(Flatten()) # 08層:次元変換
model.add(Dense(128, activation='relu')) # 09層:全結合出力128
model.add(Dense(10, activation='softmax')) # 10層:全結合出力10
# model表示
model.summary()
# コンパイル
# 損失関数 :categorical_crossentropy (クロスエントロピー)
# 最適化 :Adam
model.compile(loss='categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
print("")
print("●学習スタート")
f_verbose = 1 # 0:表示なし、1:詳細表示、2:表示
hist = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test),
verbose=f_verbose)
# ------------------------------------------------------------------------------------------------------------
# 損失値グラフ化
# ------------------------------------------------------------------------------------------------------------
# Accuracy (正解率)
plt.plot(range(epochs), hist.history['accuracy'], marker='.')
plt.plot(range(epochs), hist.history['val_accuracy'], marker='.')
plt.title('Accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='lower right')
plt.show()
# loss (損失関数)
plt.plot(range(epochs), hist.history['loss'], marker='.')
plt.plot(range(epochs), hist.history['val_loss'], marker='.')
plt.title('loss Function')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right')
plt.show()
# ------------------------------------------------------------------------------------------------------------
# テストデータ検証
# ------------------------------------------------------------------------------------------------------------
print("")
print("●検証結果")
t_verbose = 1 # 0:表示なし、1:詳細表示、2:表示
score = model.evaluate(X_test, y_test, verbose=t_verbose)
print("")
print("batch_size = ", batch_size)
print("epochs = ", epochs)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
print("")
print("●混同行列(コンフュージョンマトリックス) 横:識別結果、縦:正解データ")
predict_classes = np.argmax(model.predict(X_test[1:10000, ], batch_size=batch_size), axis=-1)
true_classes = np.argmax(y_test[1:10000], 1)
print(confusion_matrix(true_classes, predict_classes))
# ------------------------------------------------------------------------------------------------------------
# 正誤表表示
# ------------------------------------------------------------------------------------------------------------
show_prediction()
plt.show()
-
このソースコードを先程のフィールド(赤枠内)に
コピペしてください。
-
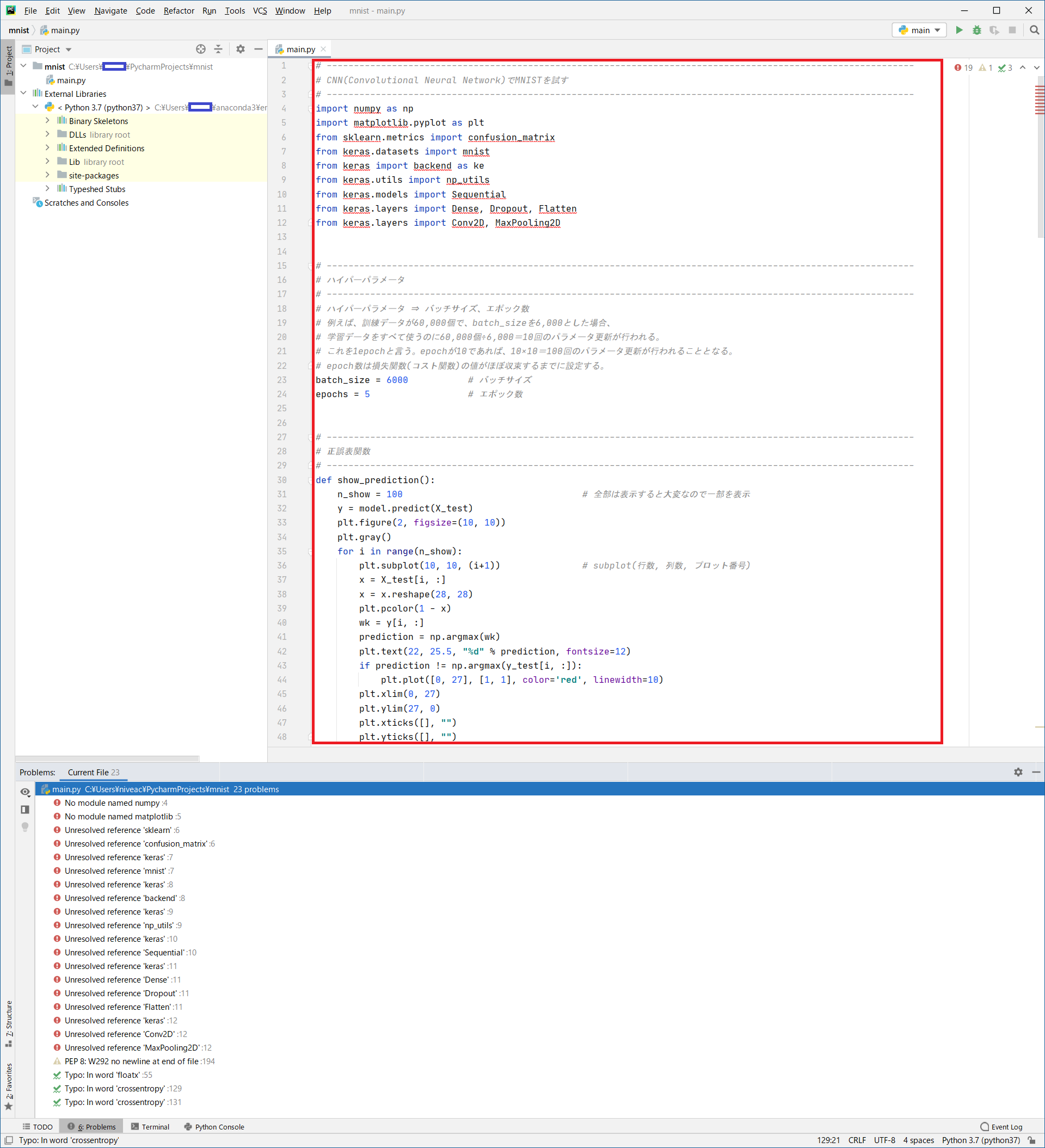
下ペインのタブで[
Probrems]をクリックして、内容を確認します。
下記の様に赤線枠内に!赤丸の箇所がある場合は、ライブラリが足りずエラーとなっています。

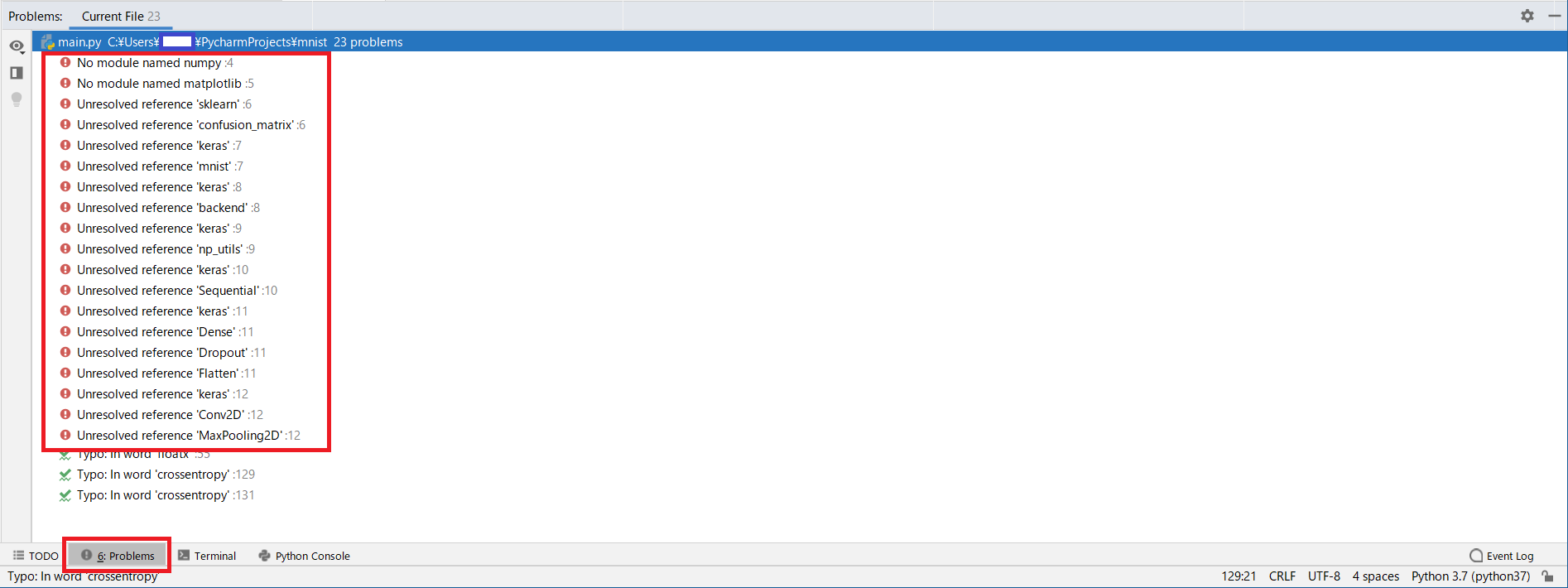
-
足りていないライブラリは、ソースコード内でも確認できます。
ソースコード内にライブラリが無い箇所に赤色で下線が付いています。
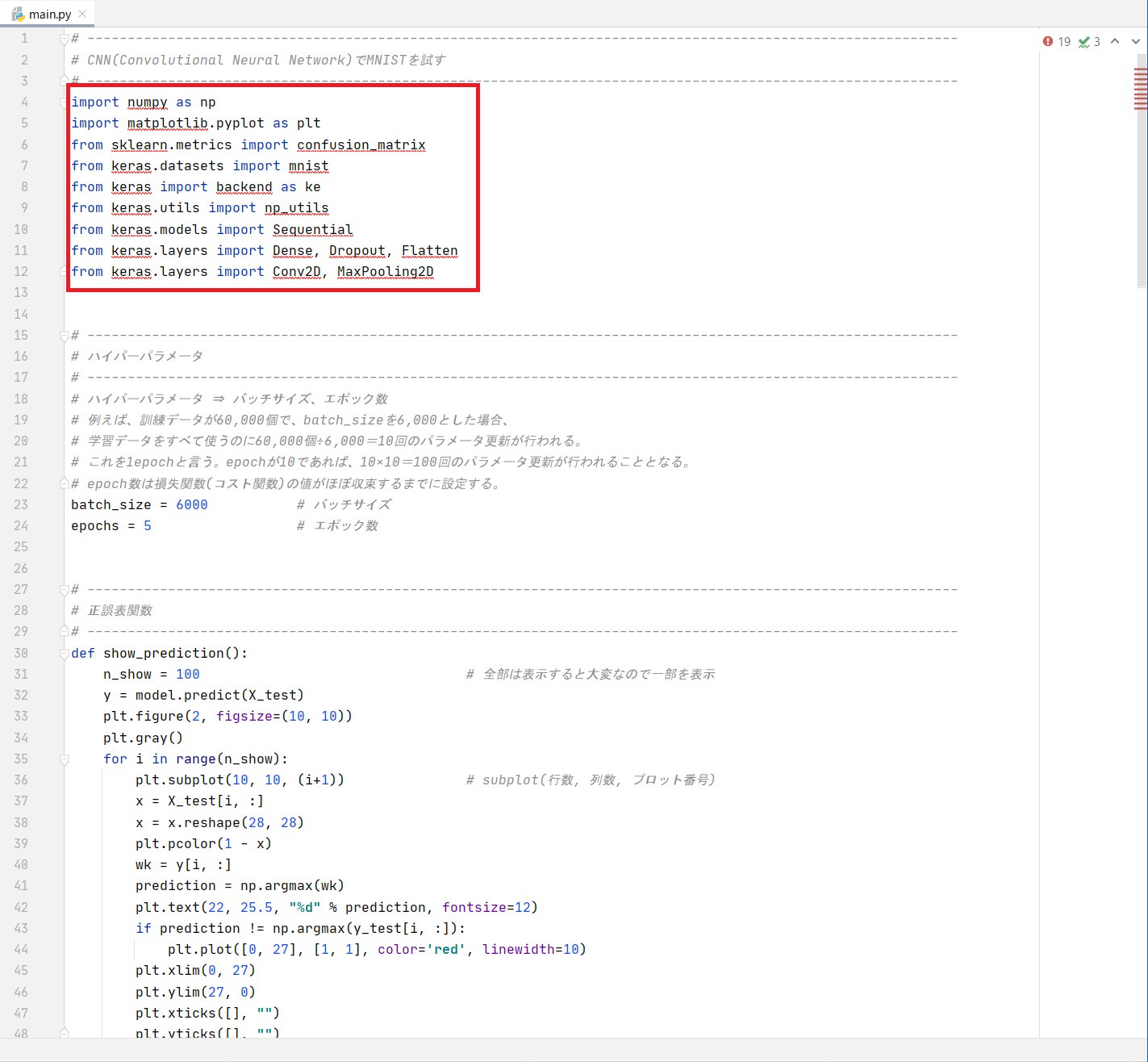
-
足りないライブラリを以下にまとめます
ライブラリはパッケージに入っています。
sklearnライブラリだけ、scikit-learnというパッケージに入っているので注意。
| No. | 足りないライブラリ名 | 必要なパッケージ名称 |
|---|---|---|
| 1 | keras | keras |
| 2 | numpy | numpy |
| 3 | matplotlib | matplotlib |
| 4 | sklearn | scikit-learn |
パッケージのインストール
● anacondaからパッケージの追加
- anacondaを起動し、[
Envionments] -> [python37]をクリック
※PycharmのGUIからやpython37のOpen Terminalからでも同様の設定が可能ですが、今回説明は割愛します。
● kerasパッケージのインストール
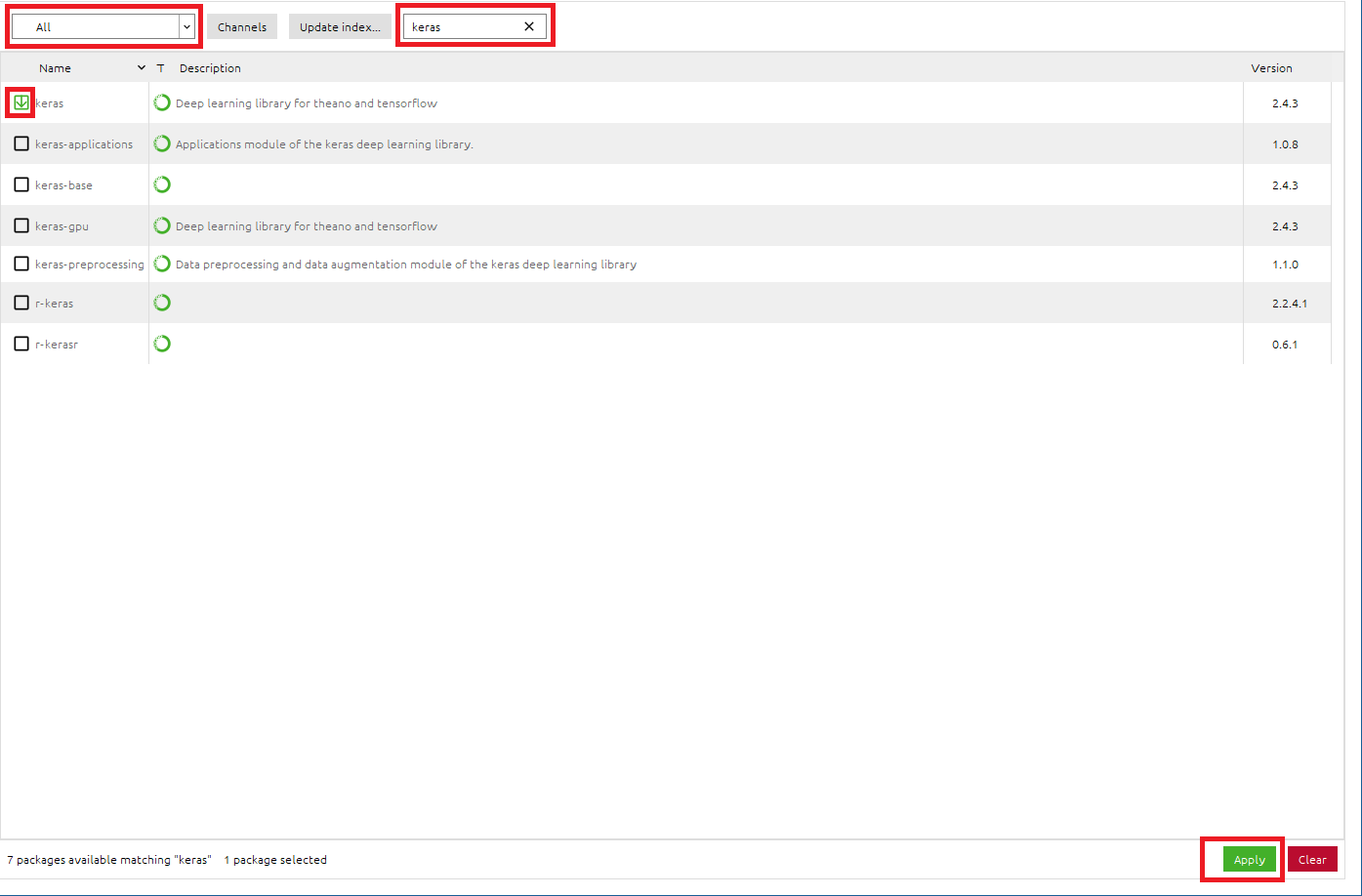
- [
Installed]を[All]に変更 - 検索BOXに[
keras]と入力し、kerasパッケージを検索 - [
keras]のチェックボックスをONに設定 - 右下の[
Apply]をクリックして適応させる
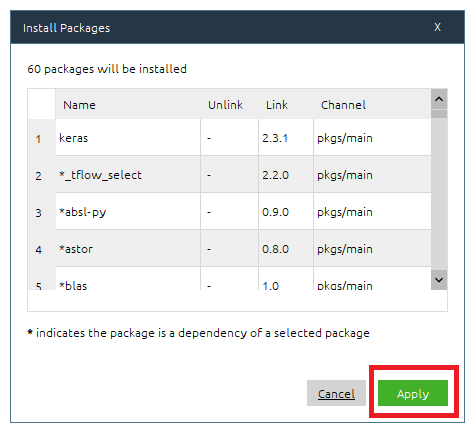
- Install PackagesのメッセージBOXが出たら、[
Apply]をクリックして、kerasパッケージをインストール
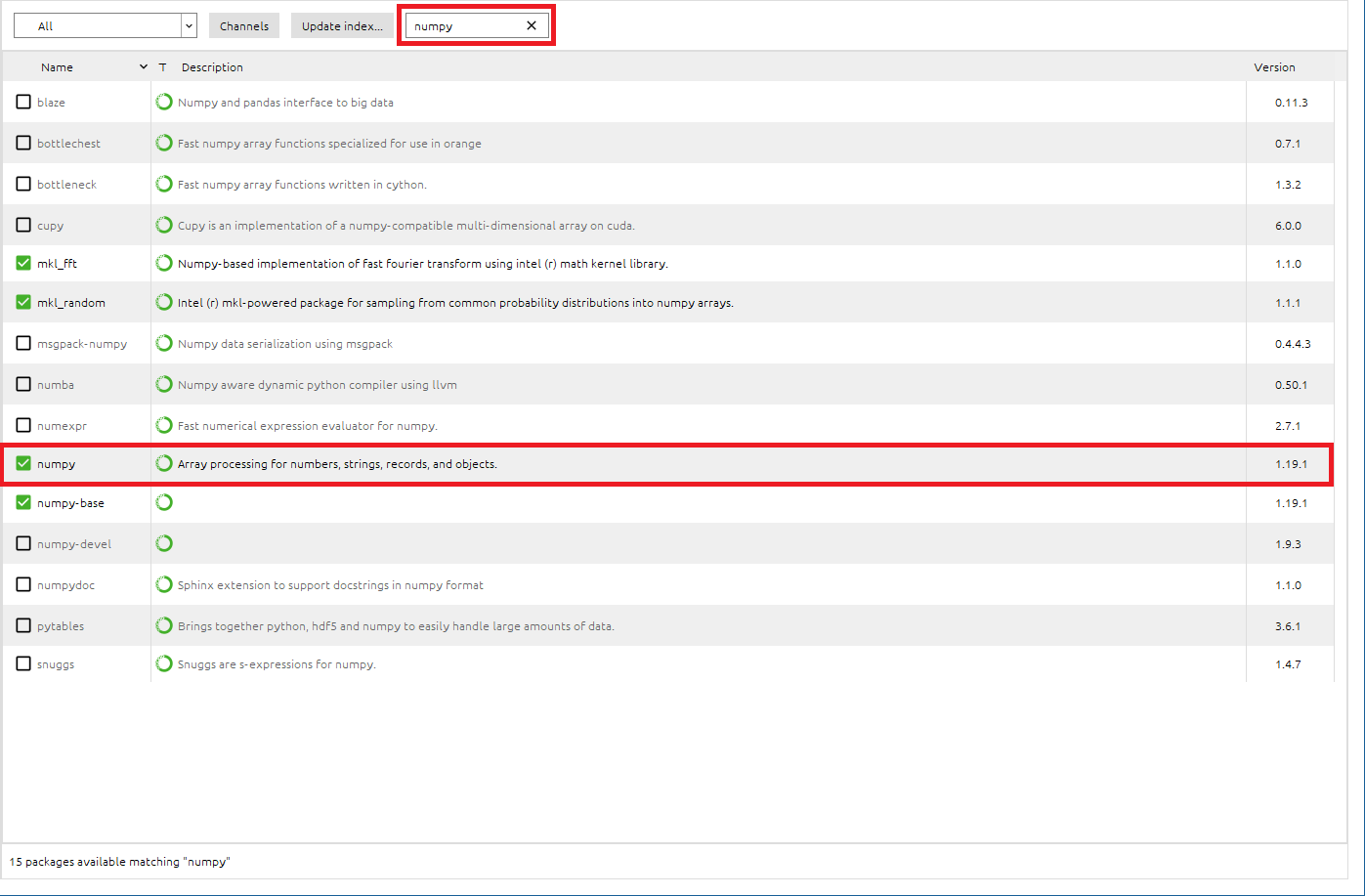
● numpyパッケージのインストール
- 検索BOXに[
numpy]と入力し、numpyパッケージを検索 - numpyパッケージがInstallされていることを確認できました。
kerasはnumpyを使用するため、依存関係からkerasパッケージのインストール時に、numpyも自動的にインストールされていました。ということで、numpyのインストール作業は割愛できました。
● matplotlibパッケージのインストール
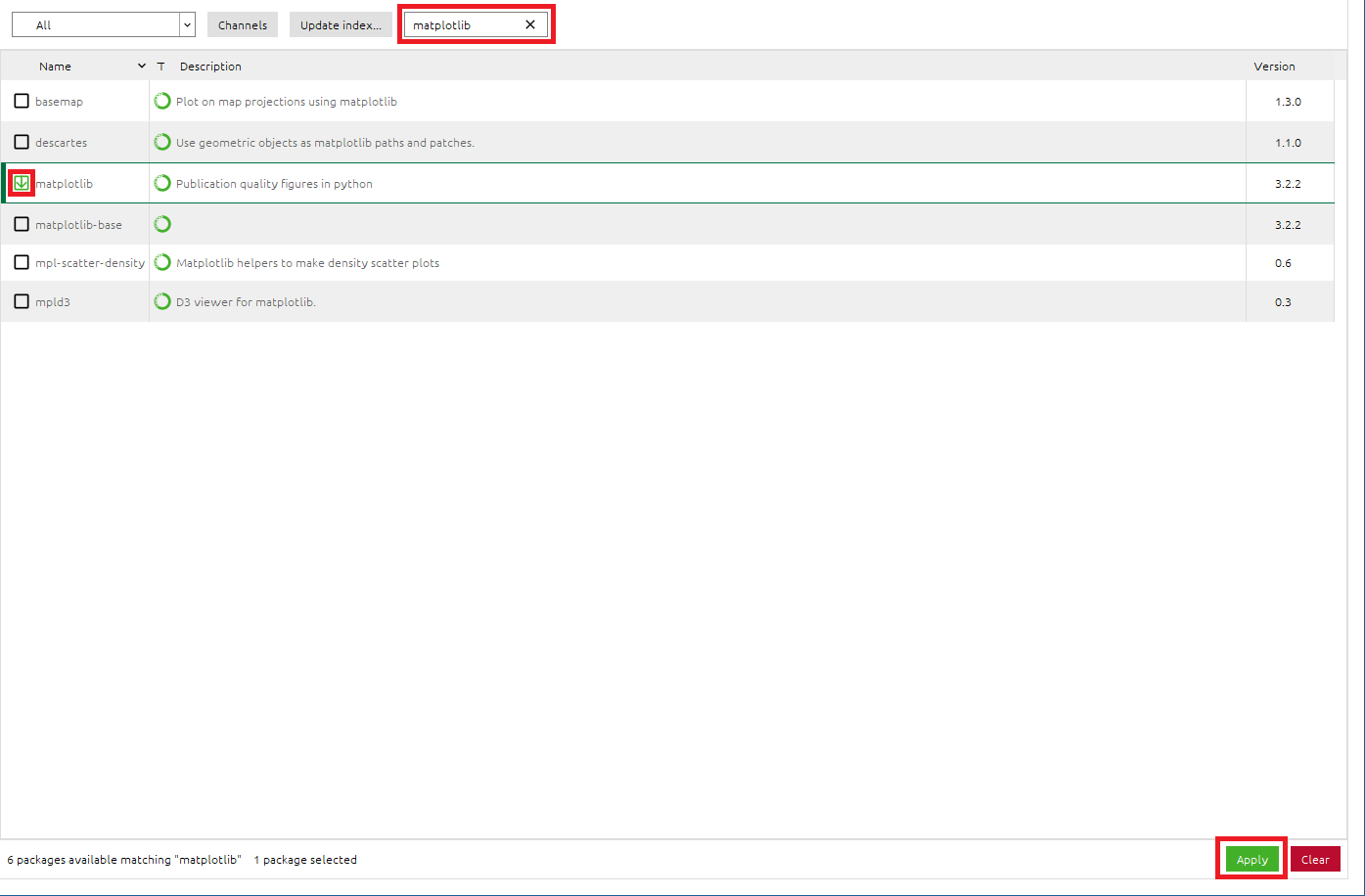
- 検索BOXに[
matplotlib]と入力し、matplotlibパッケージを検索 - [
matplotlib]のチェックボックスをONに設定 - 右下の[
Apply]をクリックして適応させる - Install PackagesのメッセージBOXが出たら、[
Apply]をクリックして、matplotlibパッケージをインストール
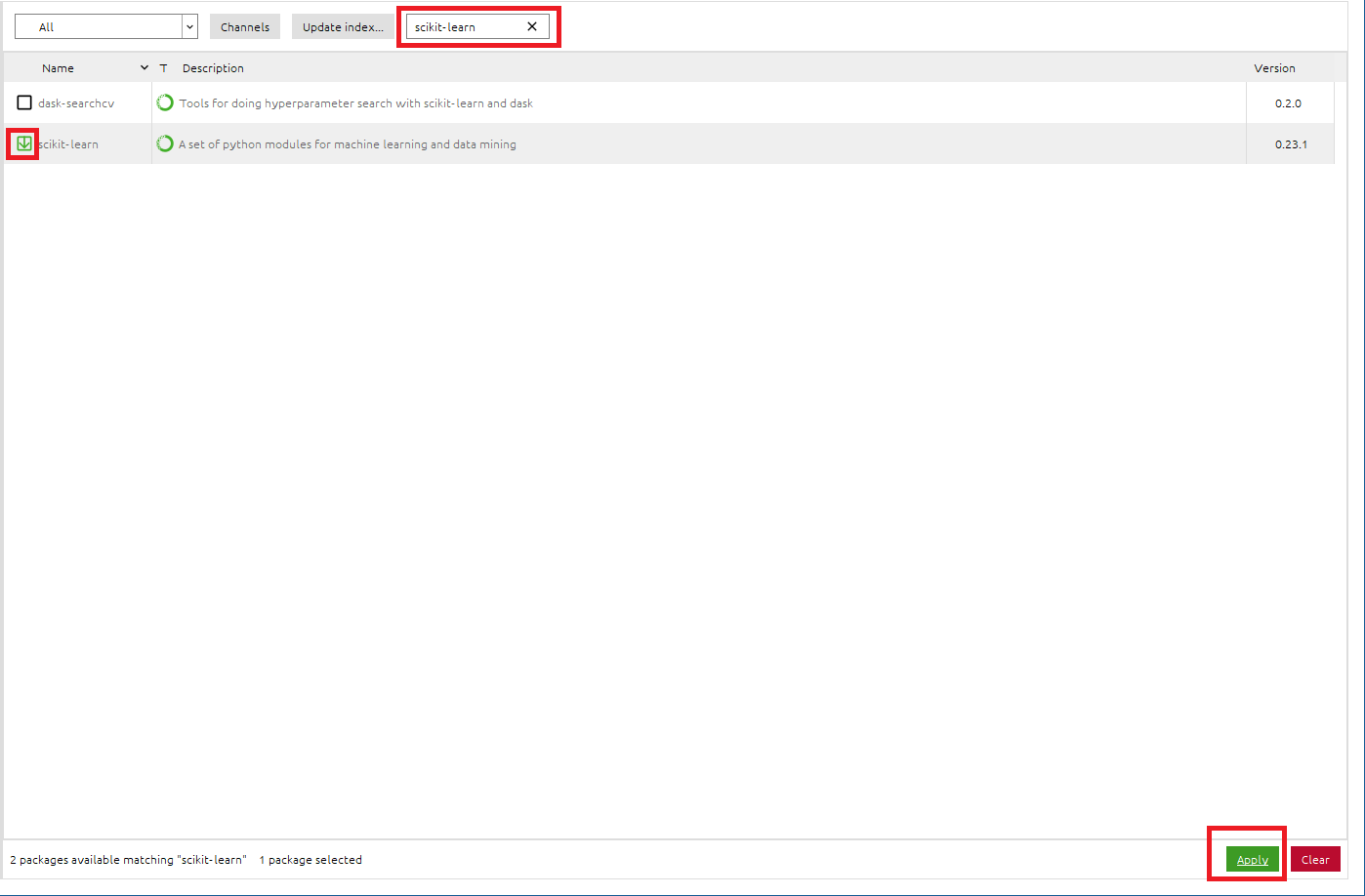
● scikit-learnパッケージのインストール
- 検索BOXに[
scikit-learn]と入力し、scikit-learnパッケージを検索 - [
scikit-learn]のチェックボックスをONに設定 - 右下の[
Apply]をクリックして適応させる - Install PackagesのメッセージBOXが出たら、[
Apply]をクリックして、scikit-learnパッケージをインストール
※sklearnライブラリは、scikit-learnパッケージに入っています。
プログラム実行
- エラーが全てなくなっていることを確認します。
- [
Problems]をクリック - Problemsに
!赤丸が出ていないことを確認

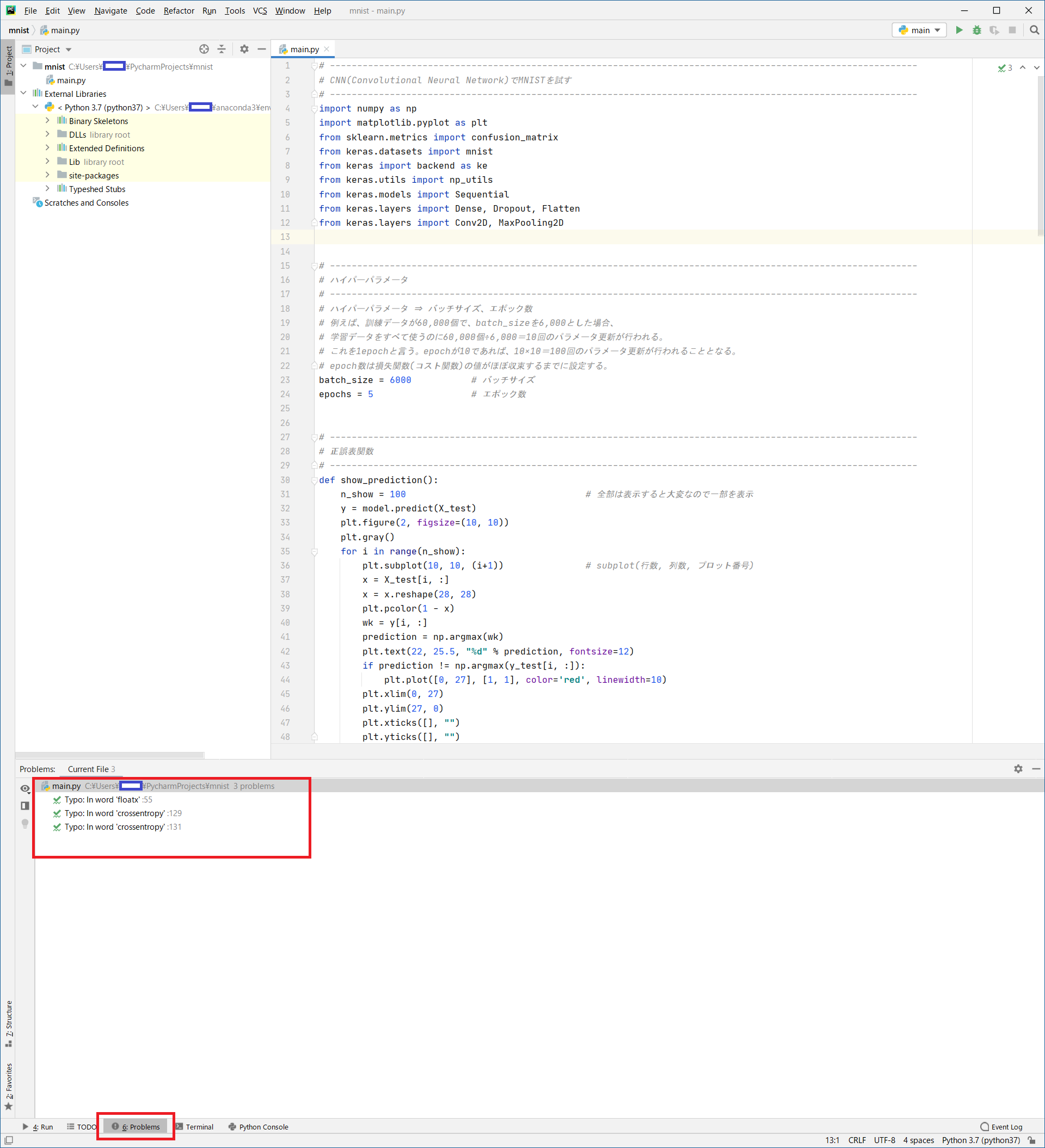
- 右上の「
▶」をクリックしてプログラムを実行してください。
出力結果
- きちんとできると、以下のような結果が得られます。
- 今回は「Test accuracy: 0.9359999895095825」と結果が得られたので、認識率は93.4%でした。
C:\Users\xxxx\anaconda3\envs\python37\python.exe C:/Users/xxxx/PycharmProjects/mnist_sample/qiita.py
Using TensorFlow backend.
●ネットワーク定義
2020-08-06 11:36:11.346263: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
conv2d_2 (Conv2D) (None, 28, 28, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 14, 14, 32) 9248
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 7, 7, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 1568) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 200832
_________________________________________________________________
dense_2 (Dense) (None, 10) 1290
=================================================================
Total params: 216,170
Trainable params: 216,170
Non-trainable params: 0
_________________________________________________________________
●学習スタート
Train on 60000 samples, validate on 10000 samples
Epoch 1/5
2020-08-06 11:36:12.480915: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 602112000 exceeds 10% of system memory.
2020-08-06 11:36:14.075159: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 602112000 exceeds 10% of system memory.
6000/60000 [==>...........................] - ETA: 36s - loss: 2.3063 - accuracy: 0.0653
12000/60000 [=====>........................] - ETA: 32s - loss: 2.2858 - accuracy: 0.1563
18000/60000 [========>.....................] - ETA: 29s - loss: 2.2630 - accuracy: 0.2346
24000/60000 [===========>..................] - ETA: 24s - loss: 2.2374 - accuracy: 0.2971
30000/60000 [==============>...............] - ETA: 20s - loss: 2.2083 - accuracy: 0.3415
36000/60000 [=================>............] - ETA: 16s - loss: 2.1742 - accuracy: 0.3779
42000/60000 [====================>.........] - ETA: 12s - loss: 2.1342 - accuracy: 0.4095
48000/60000 [=======================>......] - ETA: 8s - loss: 2.0883 - accuracy: 0.4363
54000/60000 [==========================>...] - ETA: 4s - loss: 2.0373 - accuracy: 0.4610
60000/60000 [==============================] - 44s 733us/step - loss: 1.9787 - accuracy: 0.4864 - val_loss: 1.3384 - val_accuracy: 0.7674
Epoch 2/5
6000/60000 [==>...........................] - ETA: 39s - loss: 1.3002 - accuracy: 0.7305
12000/60000 [=====>........................] - ETA: 37s - loss: 1.2238 - accuracy: 0.7381
18000/60000 [========>.....................] - ETA: 33s - loss: 1.1505 - accuracy: 0.7432
24000/60000 [===========>..................] - ETA: 27s - loss: 1.0788 - accuracy: 0.7513
30000/60000 [==============>...............] - ETA: 23s - loss: 1.0145 - accuracy: 0.7597
36000/60000 [=================>............] - ETA: 18s - loss: 0.9617 - accuracy: 0.7652
42000/60000 [====================>.........] - ETA: 14s - loss: 0.9165 - accuracy: 0.7698
48000/60000 [=======================>......] - ETA: 9s - loss: 0.8742 - accuracy: 0.7754
54000/60000 [==========================>...] - ETA: 4s - loss: 0.8390 - accuracy: 0.7804
60000/60000 [==============================] - 50s 831us/step - loss: 0.8084 - accuracy: 0.7856 - val_loss: 0.4861 - val_accuracy: 0.8541
Epoch 3/5
6000/60000 [==>...........................] - ETA: 41s - loss: 0.4924 - accuracy: 0.8445
12000/60000 [=====>........................] - ETA: 36s - loss: 0.4970 - accuracy: 0.8453
18000/60000 [========>.....................] - ETA: 32s - loss: 0.5020 - accuracy: 0.8486
24000/60000 [===========>..................] - ETA: 28s - loss: 0.5005 - accuracy: 0.8508
30000/60000 [==============>...............] - ETA: 23s - loss: 0.4866 - accuracy: 0.8547
36000/60000 [=================>............] - ETA: 19s - loss: 0.4774 - accuracy: 0.8578
42000/60000 [====================>.........] - ETA: 14s - loss: 0.4730 - accuracy: 0.8603
48000/60000 [=======================>......] - ETA: 9s - loss: 0.4721 - accuracy: 0.8622
54000/60000 [==========================>...] - ETA: 4s - loss: 0.4641 - accuracy: 0.8648
60000/60000 [==============================] - 52s 862us/step - loss: 0.4574 - accuracy: 0.8666 - val_loss: 0.3624 - val_accuracy: 0.9004
Epoch 4/5
6000/60000 [==>...........................] - ETA: 44s - loss: 0.3941 - accuracy: 0.8850
12000/60000 [=====>........................] - ETA: 40s - loss: 0.3863 - accuracy: 0.8882
18000/60000 [========>.....................] - ETA: 34s - loss: 0.3731 - accuracy: 0.8912
24000/60000 [===========>..................] - ETA: 29s - loss: 0.3659 - accuracy: 0.8943
30000/60000 [==============>...............] - ETA: 25s - loss: 0.3545 - accuracy: 0.8971
36000/60000 [=================>............] - ETA: 20s - loss: 0.3461 - accuracy: 0.8987
42000/60000 [====================>.........] - ETA: 15s - loss: 0.3417 - accuracy: 0.9001
48000/60000 [=======================>......] - ETA: 10s - loss: 0.3421 - accuracy: 0.9008
54000/60000 [==========================>...] - ETA: 5s - loss: 0.3367 - accuracy: 0.9023
60000/60000 [==============================] - 52s 874us/step - loss: 0.3332 - accuracy: 0.9033 - val_loss: 0.2740 - val_accuracy: 0.9225
Epoch 5/5
6000/60000 [==>...........................] - ETA: 44s - loss: 0.2830 - accuracy: 0.9168
12000/60000 [=====>........................] - ETA: 39s - loss: 0.2939 - accuracy: 0.9151
18000/60000 [========>.....................] - ETA: 35s - loss: 0.2872 - accuracy: 0.9168
24000/60000 [===========>..................] - ETA: 30s - loss: 0.2782 - accuracy: 0.9193
30000/60000 [==============>...............] - ETA: 25s - loss: 0.2782 - accuracy: 0.9188
36000/60000 [=================>............] - ETA: 20s - loss: 0.2733 - accuracy: 0.9200
42000/60000 [====================>.........] - ETA: 15s - loss: 0.2686 - accuracy: 0.9217
48000/60000 [=======================>......] - ETA: 10s - loss: 0.2684 - accuracy: 0.9222
54000/60000 [==========================>...] - ETA: 4s - loss: 0.2654 - accuracy: 0.9233
60000/60000 [==============================] - 52s 872us/step - loss: 0.2634 - accuracy: 0.9236 - val_loss: 0.2180 - val_accuracy: 0.9360
●検証結果
32/10000 [..............................] - ETA: 5s
320/10000 [..............................] - ETA: 2s
608/10000 [>.............................] - ETA: 2s
928/10000 [=>............................] - ETA: 1s
1248/10000 [==>...........................] - ETA: 1s
1568/10000 [===>..........................] - ETA: 1s
1920/10000 [====>.........................] - ETA: 1s
2272/10000 [=====>........................] - ETA: 1s
2624/10000 [======>.......................] - ETA: 1s
2976/10000 [=======>......................] - ETA: 1s
3328/10000 [========>.....................] - ETA: 1s
3680/10000 [==========>...................] - ETA: 1s
4032/10000 [===========>..................] - ETA: 1s
4384/10000 [============>.................] - ETA: 1s
4736/10000 [=============>................] - ETA: 0s
5088/10000 [==============>...............] - ETA: 0s
5408/10000 [===============>..............] - ETA: 0s
5728/10000 [================>.............] - ETA: 0s
6048/10000 [=================>............] - ETA: 0s
6368/10000 [==================>...........] - ETA: 0s
6560/10000 [==================>...........] - ETA: 0s
6816/10000 [===================>..........] - ETA: 0s
7104/10000 [====================>.........] - ETA: 0s
7392/10000 [=====================>........] - ETA: 0s
7680/10000 [======================>.......] - ETA: 0s
8000/10000 [=======================>......] - ETA: 0s
8320/10000 [=======================>......] - ETA: 0s
8640/10000 [========================>.....] - ETA: 0s
8960/10000 [=========================>....] - ETA: 0s
9280/10000 [==========================>...] - ETA: 0s
9600/10000 [===========================>..] - ETA: 0s
9920/10000 [============================>.] - ETA: 0s
10000/10000 [==============================] - 2s 196us/step
batch_size = 6000
epochs = 5
Test loss: 0.21799209741055967
Test accuracy: 0.9359999895095825
●混同行列(コンフュージョンマトリックス) 横:識別結果、縦:正解データ
[[ 966 0 1 1 0 1 6 1 4 0]
[ 0 1108 4 2 0 0 3 1 17 0]
[ 12 2 954 18 7 0 7 8 21 3]
[ 2 2 7 938 0 24 0 11 19 7]
[ 1 2 4 1 908 0 10 3 5 48]
[ 5 1 3 18 0 834 9 2 14 6]
[ 18 4 2 2 6 14 906 2 4 0]
[ 1 5 26 7 7 1 0 916 4 60]
[ 10 0 5 23 9 18 8 4 878 19]
[ 10 5 3 13 8 6 0 7 6 951]]
Process finished with exit code 0
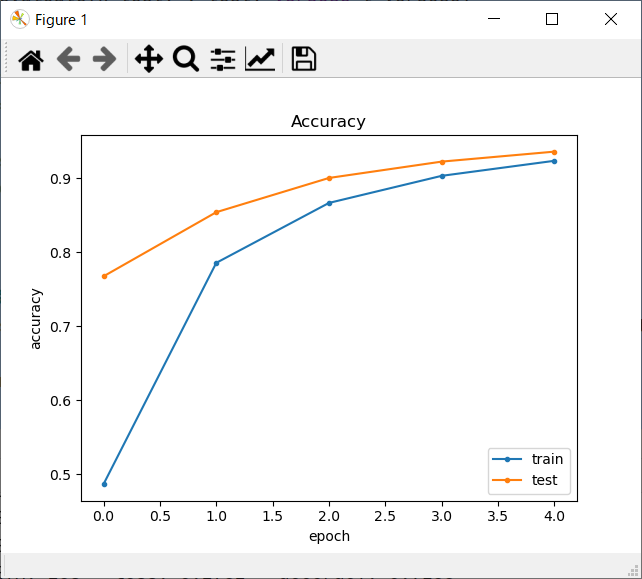
正解率
- 学習回数を増やす度に、正解率がどんどん上昇しているのが分かると思います。
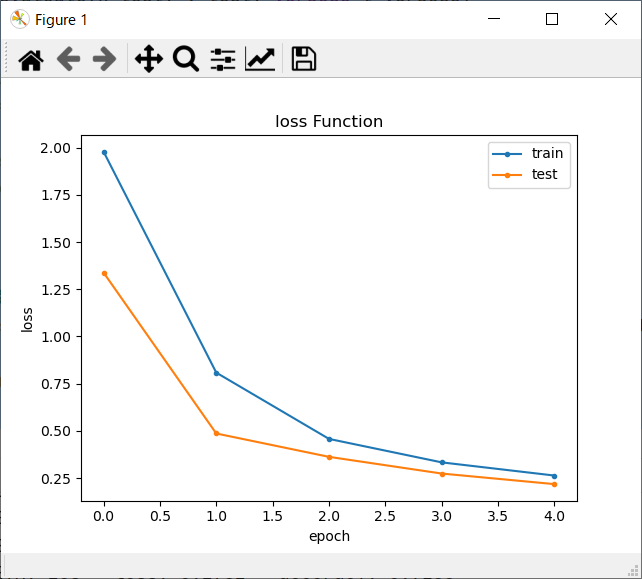
損失関数結果
- 学習回数を増やす度に、損失値がどんどん下降しているのが分かると思います。
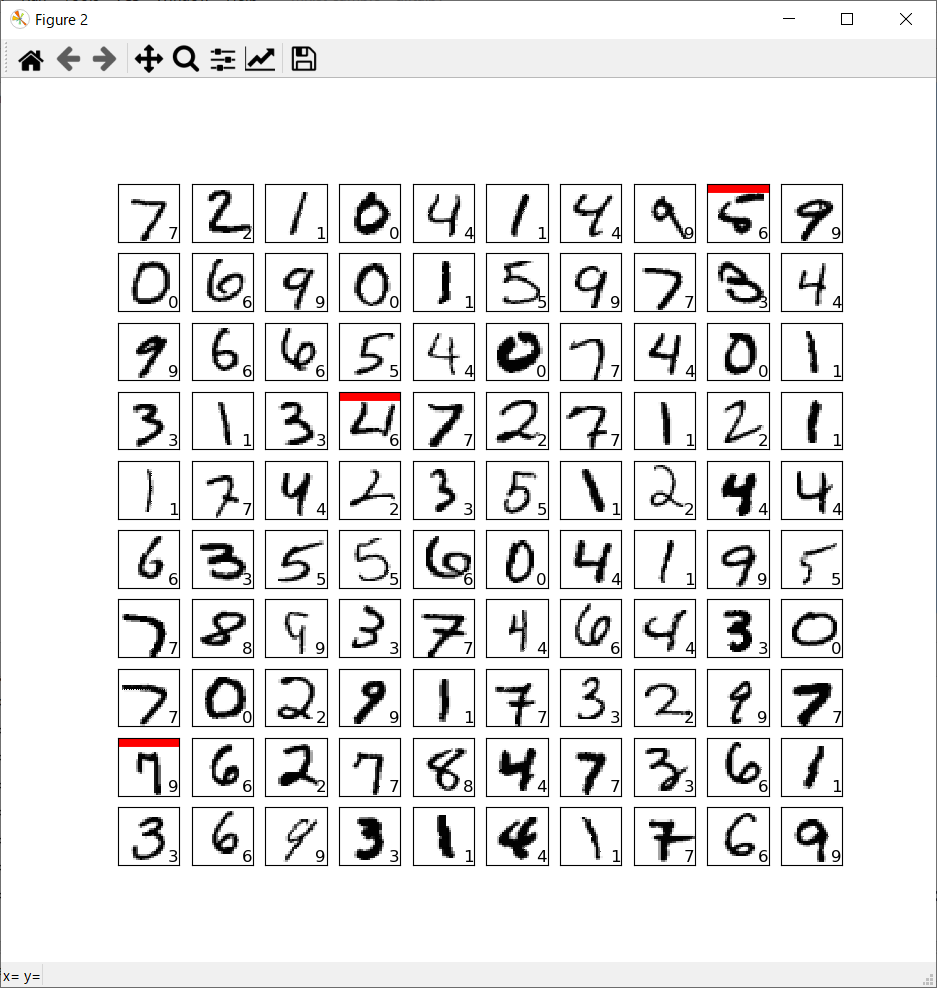
正誤表
- 検証データは10,000枚ありますが、全部出力させると大変なので、最初の100枚まで結果を出力させています。
- 赤色線で示したものが、AIが認識誤りを起こしたものです。
- 枠内右下にAIが認識した数字を記載しています。
以上
例えば、epoc数を5から20へ変更するなどハイパーパラメータを変更したり、ニューラルネットワークのネットワーク定義を変更したりすることで認識率が変わりますので、それを試してみると楽しいと思います。
- お疲れ様でした!