はじめに
みなさんはGoogle SlideやPowerPointで発表資料を作成する機会がどれくらいあるでしょうか?
多くの方が業務内で多くの時間をかけて使用されていると想定されます。
多くの時間をかける発表資料をPythonで操作でき、かつ、発表内容を自動で編集・更新できれば業務効率化にきっと繋がります。
また、Google SlideはPower Pointとしてppt形式に変換してダウンロードできます。
それでは、人気のPythonでGoogle Slideを操作してみましょう。
概要
本記事では、Google Drive内にあるSlideのタイトルや本文に対して「読み/書き/消去」を行うためのPython Classを公開します。
Slide内のTableを編集する使用例は別記事にて説明予定です。
この記事は元はGoogle APIのReferenceに準拠したものであり、今回はあえてClassを定義しインスタンス化して使用する例を提示します。
インスタンス化することで複数のSlideを同時に編集できますので是非試してみてください。
また、あくまでClassは例ですので、気になった方は自分でカスタマイズしてみてください。
前提
- 本記事ではPandasのDataframeで表を描写して視覚的にわかりやすくするため、Jupyter Notebookを使用しています。ただし、通常のPy fileで使用もできます。
- PythonからGoogle Slides APIに認証できるように以下の記事を実施してください
- 下記の公式URLからtoken.pickleをダウンロードし、"slide_token.pickle"にリネームしてください
- 上記のtokenのダウンロードの仕方を解説付きで確認したい方は以下のURLを参考にしてください
手順
1. 以下のようなSlideを用意
(1ページ目)

(2ページ目)

2. Jupyter Notebookでipynbを作成し、ステップに以下のClass/Defをコピペし実行
コードを見る
from __future__ import print_function
import pickle
import os.path
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
class SlidesApi:
def __init__(self,PRESENTATION_ID):
self.presentation_id = PRESENTATION_ID
self.service = self.launch_api()
self.read_slides()
self.get_elements()
def launch_api(self):
SCOPES = ['https://www.googleapis.com/auth/presentations']
creds = None
if os.path.exists('slede_token.pickle'):
with open('slede_token.pickle', 'rb') as token:
creds = pickle.load(token)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('slede_token.pickle', 'wb') as token:
pickle.dump(creds, token)
service = build('slides', 'v1', credentials=creds)
return service
def read_slides(self):
presentation = self.service.presentations().get(presentationId=self.presentation_id).execute()
self.slides = presentation.get('slides')
def get_elements(self):
self.read_slides()
self.page_element_list = []
for page_num in range(0,len(self.slides),1):
for element in self.slides[page_num]['pageElements']:
if "shape" in list(element.keys()):
self.page_element_list.append({"page": page_num,"type":element['shape']['placeholder']['type'],\
"objectId":element['objectId'],"contents":extract_text_from_shape(element['shape'])})
elif "table" in list(element.keys()):
self.page_element_list.append({"page": page_num,"type":"TABLE",\
"objectId":element['objectId'],"contents":extract_text_from_table(element['table'])})
return self.page_element_list
def find_shape_by_page(self,find_type,find_page):
self.result_shape = []
for lst in self.page_element_list:
if (lst['page'] == find_page) and (lst['type'] == find_type):
self.result_shape.append(lst)
return self.result_shape
def get_shape(self,find_type,find_page = None,find_title = None):
self.result_shape = []
if find_page is not None:
self.result_shape= self.find_shape_by_page(find_type,find_page)
elif find_title is not None:
page_num = None
for lst in self.page_element_list:
if (find_title in lst['contents'][0]) and (lst['type'] == find_type):
page_num = lst['page']
if page_num is not None:
self.result_shape = self.find_shape_by_page(find_type,page_num)
return self.result_shape
def clear_shape_contents(self,objectId):
requests = []
requests.append({
"deleteText": {
"objectId": objectId,
"textRange": {
"type": "ALL",
}
}
})
try:
body={'requests':requests}
response=self.service.presentations().batchUpdate(presentationId=self.presentation_id, body=body).execute()
self.read_slides()
self.get_elements()
print("Result: Clear the contents successfully")
except:
print("Exception: Failed to clear contents in the table ")
def writes_text_to_shape(self,objectId,text,default_index = 0):
requests = []
requests.append({
"insertText": {
"objectId": objectId,
"text": text,
"insertionIndex": default_index
}})
try:
body={'requests':requests}
response= self.service.presentations().batchUpdate(presentationId=self.presentation_id, body=body).execute()
self.read_slides()
self.get_elements()
except:
print("Exception: Failed to add contents to the table ")
def extract_text_from_shape(element_dict):
text_box = []
if "text" not in list(element_dict.keys()):
pass
else:
element_dict['text']['textElements']
for lst in element_dict['text']['textElements']:
if "textRun" in list(lst.keys()):
text_box.append(lst["textRun"]['content'])
return text_box
3. 定義したClassを元に、前項1.のSlide IDを引数にしてインスタンスを作成
※Slide IDはSlideのURLの"/edit"の直前に英数字で記載されています。
# PRESENTATION_IDに引数でIDを入力(str)
test_slides = SlidesApi(PRESENTATION_ID='XXXXXXXXXXX')
このインスタンスを作成すると同時に、Slideから全シートのElement(タイトル/本文/テーブル等)のリストが抽出されます。
4. Slideから取得したElementの一覧をprintで確認
print(test_slides.page_element_list)
# 出力結果
[{'type': 'CENTERED_TITLE', 'objectId': 'i0', 'page': 0, 'contents': ['Page1 Sample Tiltle\n']}, {'type': 'SUBTITLE', 'objectId': 'i1', 'page': 0, 'contents': ['Page1 Sample Subtitle\n']}, {'type': 'TITLE', 'objectId': 'g600b545905_0_1', 'page': 1, 'contents': ['Page2 Sample Title\n']}, {'type': 'BODY', 'objectId': 'g600b545905_0_2', 'page': 1, 'contents': ['Page2 body description 1\n', 'Page2 body description 2\n', 'Page2 body description 3\n', '\n']}, {'type': 'TABLE', 'objectId': 'g634fca277e_0_0', 'page': 1, 'contents': [['a\n', 'a\n', 'a\n'], ['a\n', 'a\n', 'a\n'], ['a\n', 'a\n', 'a\n'], ['a\n', 'a\n', 'a\n']]}, {'type': 'TABLE', 'objectId': 'g294209d42ab89e2c_1', 'page': 1, 'contents': [['b\n', 'b\n', 'b\n'], ['b\n', 'b\n', 'b\n'], ['b\n', 'b\n', 'b\n'], ['b\n', 'b\n', 'b\n']]}, {'type': 'TITLE', 'objectId': 'g600b545905_0_6', 'page': 2, 'contents': ['Page3 Sample Title\n']}, {'type': 'BODY', 'objectId': 'g600b545905_0_7', 'page': 2, 'contents': ['Page3 body description 1\n']}]
これだとわかりにくいのでPandasで変換しましょう
5. 手順4のPython ListをPandas Dataframeに変換し、読み取った値を確認
以下を実行します。
import pandas as pd
df = pd.DataFrame(test_slides.page_element_list)
df.loc[:, ['page', 'type', 'objectId', 'contents']]

Slideを構成するElementが全て記載されていますね。ただ、APIの特性上Pageのindexが1ではなく0から始まっていることに注意してください。
また、Slide のマスター機能に詳しいならご存知だと思いますが、SlideのElementには主に以下の属性があります。
- CENTERED TITLE
- SUBTITLE
- TITLE
- BODY
- TITLE
手順1であげたページ画像を参考に、どのElementがどの属性かを判断してみてください。
6. メソッドを使用して2ページ目の本文(BODY)を消去する
インスタンスのメソッドを利用して2ページ目の本文(BODY)を削除してみましょう。
抽出結果の表によると、2ページ目(page1)の本文(BODY)のIDは"g600b545905_0_2"です

以下を実行します。
test_slides.clear_shape_contents('g600b545905_0_2')
7. 値の消去が反映されているかを確認
スライドを確認すると「クリックしてテキストを追加」となり文章が消えていますね。
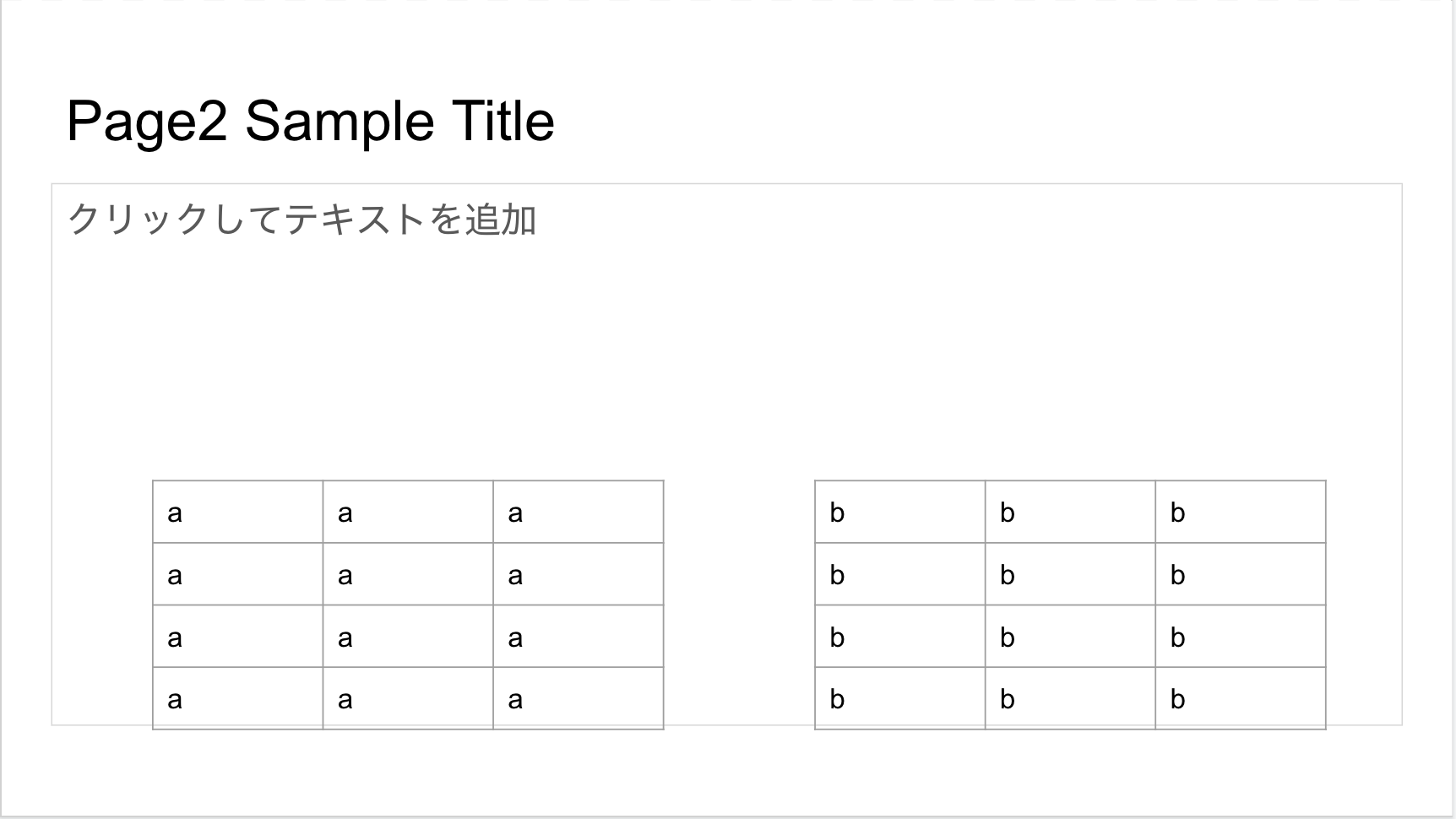
8.2ページ目の本文内容を書き込む
2ページ目の消した本文(BODY)に新たな値を書き込みましょう。
以下のメソッドを使用して"sample change"と書き込みます。
test_slides.writes_text_to_shape(objectId = 'g600b545905_0_2',text = "sample change" ,default_index = 0)
9.2ページ目の書き込まれた本文を確認
Slideを確認すると"sample change"と書き込まれていますね。
