前提
異なるデータベース(RDBMS)間でテーブルの一部をコピーしたいという要件を考えます。
なぜ Data Pipeline?
DMS
データベース間の論理的なテーブルコピーではDMSが思い浮かびます。
しかし、データベースがたくさんあり(数十とか)、テーブルもたくさんあるような(数百とか)環境においては、DMSによる差分コピーは運用面が大変になる可能性があります。
Read Replica
データベース若しくはテーブルをまるごと扱うには優れています。しかし、多くのデータベースからテーブルの一部をかき集めるような場合には向きません。
Glue
大規模なETLではETLに特化したマネージドEMRをバックに持つGlueは優れたソリューションです。しかし、小さなETLでは逆にオーバーヘッドが大きくなってしまいます。また、ソースやターゲットのRDBMSに対してSQLを書こうと思うとHiveでのステージングを活かしきれず、自分でSQLで取得したデータとSQLのマッピングを管理しなければなりません。
Data Pipeline
Data Pipelineは、小規模で、かつSQLを自分で書きたい場合には優れた選択肢となる可能性があります。SQLで取得されたデータの管理は不要であり、開発者は入力のためのSQLと出力のためのSQLに集中できます。ただし、1つのジョブはEC2上のJVMの1つのスレッドで実行されますので、Glueのように大規模分散ジョブを実行するには向きませんし、DMSのように差分をDBから自動的に取る機能を持っているわけでもありません。
本稿では、まとまった情報としてあまり見当たらない RDBMS to RDBMS の Data Pipeline について実際の例を示していきます。RDS for PostgreSQL を用います。
準備
RDSとEC2インスタンスを作成し、検証のためのテーブルも作成しておきましょう。
RDS
RDS for PostgreSQL を1台立てるか、既にあるのであればそちらを使用します。今回はシンプルにするため、ソースとターゲットを同一RDSインスタンスとします。
まだ立てていなければ、「PostgreSQL DB インスタンスを作成して PostgreSQL DB インスタンスのデータベースに接続する」を参考に構築しておきましょう。検証であればインスタンスタイプはt2.microなどで十分です。
EC2
前節のRDSにpsqlコマンドで接続できるEC2インスタンスを1つ用意します。このインスタンスにおいて、後述の TaskRunnner を立てたり、検証のためのSQLを発行したりします。動作の検証であればt2.microなどで十分です。
以下のように、RDSのエンドポイントに対してpsqlでRDSに接続できるようにしておきます。
$ psql -U ***** -h postgres-test.****************.ap-northeast-1.rds.amazonaws.com -d postgres_test
psql (9.6.6)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres_test=>
検証用のテーブル
以下のようにt_sourceとt_destテーブル、そしてt_sourceに値を挿入または更新するプロシージャを作成しておきます。
create table t_source (
id numeric(50,0) primary key,
value text,
last_modified timestamp
);
create index idx_t_source_lm on t_source (last_modified);
create table t_dest (
id numeric(50,0) primary key,
value text,
last_modified timestamp
);
create index idx_t_dest_lm on t_dest (last_modified);
create or replace function ins_tab(v_start_num integer, v_count integer) returns void as $$
declare
maxid integer;
v_id integer;
begin
for v_id in v_start_num .. v_start_num+v_count-1 loop
insert into t_source (id, value, last_modified)
values (v_id, 'INSERT', current_timestamp)
on conflict on constraint t_source_pkey do
update set value = 'UPDATE'
, last_modified = current_timestamp;
end loop;
end;
$$ LANGUAGE plpgsql;
postgres_test=> \i cretab.sql
CREATE TABLE
CREATE INDEX
CREATE TABLE
CREATE INDEX
postgres_test=> \i crefunc.sql
CREATE FUNCTION
次のように、ins_tabファンクションに開始IDと件数を入れると、UPSERTが実行されます。
postgres_test=> select ins_tab(1, 5);
ins_tab
---------
(1 行)
postgres_test=> select count(*) from t_source;
count
-------
5
(1 行)
postgres_test=> select ins_tab(3, 5);
ins_tab
---------
(1 行)
postgres_test=> select * from t_source;
id | value | last_modified
----+--------+----------------------------
1 | INSERT | 2018-03-15 05:32:32.686245
2 | INSERT | 2018-03-15 05:32:32.686245
3 | UPDATE | 2018-03-15 05:32:55.760427
4 | UPDATE | 2018-03-15 05:32:55.760427
5 | UPDATE | 2018-03-15 05:32:55.760427
6 | INSERT | 2018-03-15 05:32:55.760427
7 | INSERT | 2018-03-15 05:32:55.760427
構築
スケジューラについて
Data Pipelineにはビルトインされたスケジューラ(Scheduler)や、内部で自動的にEC2を立ててくれるリソースオブジェクト(Ec2Resource)があるのですが、本稿では使用しません。
まず、スケジューラについては、粒度の小さなタスクを実行したい場合には、Schedulerの最小15分間隔という制限が制約になる可能性があるため使用せず、オンデマンド実行の機能を利用することとします。
また、オンデマンド実行の場合、Ec2Resourceを使用していると実行の度にEC2インスタンスが起動する時間がオーバーヘッドとなるため、外部のEC2インスタンスにTask Runnerを起動することにします。
というわけで、今回構築するのは、Task RunnerとPipelineです。
Task Runner
「Task Runner を使用した既存のリソースでの作業の実行」に沿ってEC2上にTask Runnerをインストールします。
$ java -version
openjdk version "1.8.0_161"
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
javaが1.6以上かをチェック。
$ curl https://s3.amazonaws.com/datapipeline-us-east-1/us-east-1/software/latest/TaskRunner/TaskRunner-1.0.jar -O
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 44.3M 100 44.3M 0 0 2498k 0 0:00:18 0:00:18 --:--:-- 3448k
Task Runnerをダウンロードします。
{
"access-id": "AKIAIXXXXXXXXXXXXXXX",
"private-key": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
}
接続情報。当該access-idにはAWSDataPipeline_FullAccess(または同一定義のAWSDataPipeline_PowerUser)ポリシーを付与しておきます。
# !/bin/sh
WORKERGROUP=rdstordswg
LOGURI=s3://<your bucket>/datapipeline-error-logs
REGION=ap-northeast-1
java -jar TaskRunner-1.0.jar --config credentials.json --workerGroup=${WORKERGROUP} --region=${REGION} --logUri=${LOGURI}
Task Runnerの実行の際には、接続情報の他、Worker Groupとログの格納先を指定する必要があります。
Worker Groupは、Task RunnerがData Pipelineにポーリングして、設定されたWorker Groupのアクティビティがあればそれを取得するという仕組みで使用されます。ここではrdstordswgという名前にしています。
ログはcredentials.jsonで設定したアクセスキーIDで格納可能なS3のパスを指定します。Task Runnerでエラーが発生した場合に<logUriで指定したパス>/<パイプラインID>/<Task Runner ID>/にログがアップロードされます。
$ ./runTaskRunner.sh
log4j:WARN No appenders could be found for logger (amazonaws.datapipeline.objects.PluginModule).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Starting log pusher...
Log Pusher Started. Region: ap-northeast-1, LogUri: s3://xxxxx-logs/datapipeline-error-logs
Build info: commit=unknown, timestamp=2017-11-01 03:35:38 UTC
Initializing drivers...
Starting task runner...
このように起動されます。停止はkillやctrl+cなどですが、停止まで若干時間がかかりますので焦らず待ちましょう。ちなみにタスクを実行してもコンソールには何も出力されません。
Pipeline
パイプラインの実装には、コンソールも使用可能ですが、ここではjsonをCLI経由でアップロードする方法を用います。Data Pipelineのjsonは複雑ではないですし、修正してテストを実施するサイクルがとても速くなります。
{
"objects": [
{
"id": "Default",
"name": "Default",
"pipelineLogUri": "#{myErrorLogS3Bucket}",
"failureAndRerunMode": "CASCADE",
"resourceRole": "DataPipelineDefaultResourceRole",
"role": "DataPipelineDefaultRole",
"scheduleType": "ondemand"
},
{
"id": "rds_postgres",
"name": "rds_postgres",
"type": "RdsDatabase",
"region": "#{myRegion}",
"rdsInstanceId": "#{myRDSInstanceName}",
"username": "#{myRDSUsername}",
"*password": "#{*myRDSPassword}"
},
{
"id": "SourceRDSTable",
"name": "SourceRDSTable",
"type": "SqlDataNode",
"database": {
"ref": "rds_postgres"
},
"table": "#{mySourceTable}",
"selectQuery": "#{mySourceSelectQuery}"
},
{
"id": "DestinationRDSTable",
"name": "DestinationRDSTable",
"type": "SqlDataNode",
"database": {
"ref": "rds_postgres"
},
"table": "#{myDestTable}",
"insertQuery": "#{myDestInsertQuery}"
},
{
"id": "RDSToRDSCopyActivity",
"name": "RDSToRDSCopyActivity",
"type": "CopyActivity",
"output": {
"ref": "DestinationRDSTable"
},
"input": {
"ref": "SourceRDSTable"
},
"workerGroup": "#{myWorkGroup}"
}
]
}
パイプライン本体は5つのオブジェクトで構成されています。それぞれの固有の値はパラメータ化しています。
- Defaultオブジェクト: 全体の設定等を記載する特殊なものです。今回はスケジューラを用いずにオンデマンド実行しますので、
"scheduleType": "ondemand"としています。 - RdsDatabase: RDSのインスタンス名とユーザ名/パスワードを指定することでRDSへの接続を作成してくれるオブジェクトです。
- ソース用のSqlDataNode: ソースに関する情報を記載するオブジェクトです。RdsDatabaseを通じてselectQueryからデータを取得するように表現しています。
- デスティネーション用のSqlDataNode: デスティネーションに関する情報を記載するオブジェクトです。RdsDatabaseを通じてinsertQueryにてデータを更新するように表現しています。
- CopyActivity: SqlDataNodeを組み合わせて値のコピーを表現するアクティビティです。Data Pipelineの実行履歴はアクティビティ単位で記録されます。
{
"parameters": [
{
"id": "myRegion",
"type": "String",
"description": "Region"
},
{
"id": "myRDSInstanceName",
"type": "String",
"description": "RDS Instance Name"
},
{
"id": "myRDSUsername",
"type": "String",
"description": "RDS PostgreSQL username"
},
{
"id": "*myRDSPassword",
"type": "String",
"description": "RDS PostgreSQL password"
},
{
"id": "myErrorLogS3Bucket",
"type": "String",
"description": "Data Pipeline error log destination"
},
{
"id": "myWorkGroup",
"type": "String",
"description": "Work Group"
},
{
"id": "mySourceTable",
"type": "String",
"description": "Source Table"
},
{
"id": "mySourceSelectQuery",
"type": "String",
"description": "Query for selecting source table"
},
{
"id": "myDestTable",
"type": "String",
"description": "Destination Table"
},
{
"id": "myDestInsertQuery",
"type": "String",
"description": "Query for inserting destination table"
}
]
}
{
"values": {
"myRegion": "ap-northeast-1",
"myRDSInstanceName": "<Your RDS Instance Name>",
"myRDSUsername": "<Your RDS User Name>",
"*myRDSPassword": "<Your RDS Password>",
"myErrorLogS3Bucket": "s3://<Your S3 Bucket and Path>",
"myWorkGroup": "rdstordswg",
"mySourceTable": "t_source",
"myDestTable": "t_dest",
"mySourceSelectQuery": "select id, value, last_modified from t_source where last_modified >= current_timestamp - interval '1 hours'",
"myDestInsertQuery": "insert into t_dest (id, value, last_modified) values (cast(? as integer), ?, cast(? as timestamp)) on conflict on constraint t_dest_pkey do update set value = excluded.value, last_modified = cast(excluded.last_modified as timestamp)"
}
}
パラメータ値について、RDSのインスタンス名(ここで指定するのはdbidやエンドポイントではなく、インスタンス名であることに注意)、ユーザー名、パスワード、ログを格納するバケット名は環境に合わせて設定してください。
なお、SQLとしては1時間前までに更新されたデータを取り出し、同一構成のテーブルにupsertするというものです。selectで取り出された値はその順序のままinsertのバインド変数にセットされます。データベース上の型に依らずすべて文字列型でバインドされますので、数値型など他の型に対してはcastします。upsertにおけるupdate側ではexcluded表を用いてバインド変数を増やさないようにしています。
では、デプロイしてみましょう。
# !/bin/sh
NAME=rds-to-rds-by-wg
UQID=rdstordswg
PIPELINE_DEF=file://rdstords.json
PIPELINE_PARAMETER_DEF=file://rdstords-parameters.json
PIPELINE_PARAMETER_VALUE=file://rdstords-values.json
echo "INFO: creating..."
COMMAND="aws datapipeline create-pipeline --name ${NAME} --unique-id ${UQID}"
echo ${COMMAND}
PIPELINE_ID=`$COMMAND | jq ".pipelineId" | sed "s/\"//g"`
echo "INFO: created: ${PIPELINE_ID}"
echo "INFO: deploying..."
COMMAND="aws datapipeline put-pipeline-definition --pipeline-id ${PIPELINE_ID} --pipeline-definition ${PIPELINE_DEF} --parameter-objects ${PIPELINE_PARAMETER_DEF} --parameter-values-uri ${PIPELINE_PARAMETER_VALUE}"
echo ${COMMAND}
PUT_RESULT=`${COMMAND}`
ERRORED=`echo ${PUT_RESULT} | jq ".errored" | sed "s/\"//g"`
if [ "${ERRORED}" = "true" ]; then
echo ${PUT_RESULT} | python -m json.tool
exit 1
elif [ "${ERRORED}" != "false" ]; then
echo ${PUT_RESULT}
exit 1
fi
echo "INFO: activating..."
COMMAND="aws datapipeline activate-pipeline --pipeline-id ${PIPELINE_ID}"
echo ${COMMAND}
${COMMAND}
if [ $? -ne 0 ]; then exit 1; fi
echo "INFO: completed."
$ ./dpdeploy.sh
INFO: creating...
aws datapipeline create-pipeline --name rds-to-rds-by-wg --unique-id rdstordswg
INFO: created: df-05080758GGYTM3CCZ0R
INFO: deploying...
aws datapipeline put-pipeline-definition --pipeline-id df-05080758GGYTM3CCZ0R --pipeline-definition file://rdstords.json --parameter-objects file://rdstords-parameters.json --parameter-values-uri file://rdstords-values.json
INFO: activating...
aws datapipeline activate-pipeline --pipeline-id df-05080758GGYTM3CCZ0R
INFO: completed.
create-pipeline、put-pipeline-definition、activate-pipelineの3つのAPIを使用します。
- create-pipelineではunique idを指定して(空の)パイプラインを作成します。既に同じunique idのパイプラインが存在する場合でもエラーにはならず、そのIDを返してくれます。
- put-pipeline-definitionが成功すると、errored=falseを含むJSONが返されます。そうではない場合はエラーです。
- activate-pipelineを呼び出すすることでアクティビティが実行されます。パラメータ値を変更しないのであれば、activateする度にアクティビティが実行されます。
コンソールを確認すると、以下のように RDSToRDSCopyActivity が FINISHED になっていることを確認できるはずです。
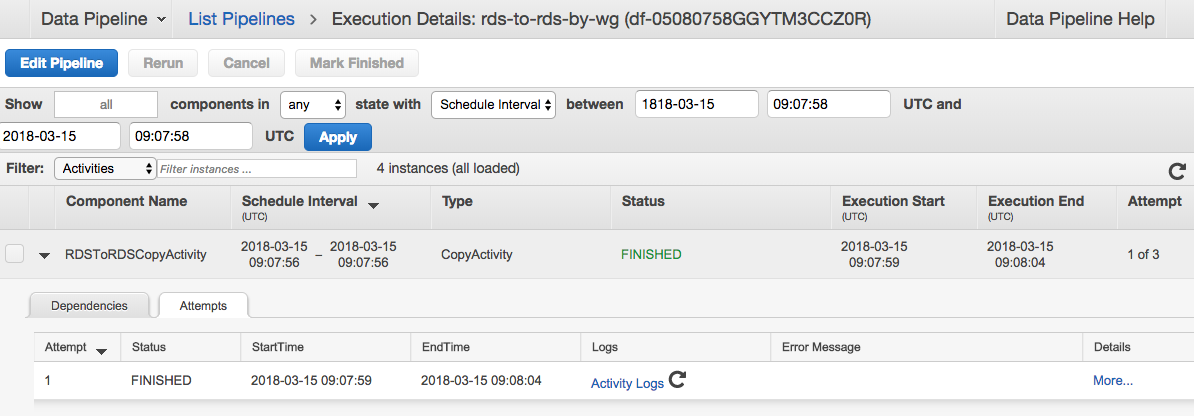
うまくいかない場合はステータスやログを確認しましょう。
- WAITING_FOR_DEPENDENCIESのまま: Task Runnerが立ち上げられていることと、設定しているWork Group名が一致していることを確認しましょう。
- ERROR: アクティビティのログと、S3のバケットからTask Runnerのログを確認しましょう。
- activateの際に
Web service limit exceededと返される: デフォルトではパイプラインの多重度は1ですから、前回activateしたアクティビティが終了していない場合は新たなアクティビティをactivateすることはできません。前回実行したものを待つか、コンソールやAPIでCancelするなどしましょう。
検証
動作時間
以下の結果は t2.microのRDS for PostgreSQLに対してc4.large上のTask Runnerから実行したものです。PostgreSQLではSQLログも出力しているので、あくまで参考まで。
10000件のコピーがどの程度で実行されるかを見てみましょう。まず、10000件のデータをソース側に用意します。
postgres_test=> select ins_tab(1, 10000);
ins_tab
---------
(1 行)
postgres_test=> select count(*) from t_source;
count
-------
10000
(1 行)
postgres_test=> select count(*) from t_dest;
count
-------
0
(1 行)
activateを実行してアクティビティを実行します。コマンドはデプロイ時に出力されたものを利用します。
$ aws datapipeline activate-pipeline --pipeline-id df-05080758GGYTM3CCZ0R
$
今回はコンソールではなく、list-runsを実行して結果を確認してみましょう。
$ aws datapipeline list-runs --pipeline-id df-05080758GGYTM3CCZ0R
Name Scheduled Start Status
ID Started Ended
---------------------------------------------------------------------------------------------------
(省略)
13. DestinationRDSTable 2018-03-15T09:43:27 FINISHED
@DestinationRDSTable_2018-03-15T09:43:27 2018-03-15T09:43:29 2018-03-15T09:43:35
14. RDSToRDSCopyActivity 2018-03-15T09:43:27 FINISHED
@RDSToRDSCopyActivity_2018-03-15T09:43:27 2018-03-15T09:43:29 2018-03-15T09:43:34
15. SourceRDSTable 2018-03-15T09:43:27 FINISHED
@SourceRDSTable_2018-03-15T09:43:27 2018-03-15T09:43:29 2018-03-15T09:43:30
Task Runnerに渡って開始してから5-6秒で終了していることがわかります。
postgres_test=> select count(*) from t_dest;
count
-------
10000
(1 行)
コピーもされていますね。
では、10万件ではどうなるかやってみましょう。
postgres_test=> select ins_tab(1, 100000);
ins_tab
---------
(1 行)
postgres_test=> select count(*) from t_source;
count
--------
100000
(1 行)
postgres_test=> select count(*) from t_dest;
count
-------
10000
(1 行)
$ aws datapipeline activate-pipeline --pipeline-id df-05080758GGYTM3CCZ0R
$
$ aws datapipeline list-runs --pipeline-id df-05080758GGYTM3CCZ0R
Name Scheduled Start Status
ID Started Ended
---------------------------------------------------------------------------------------------------
(省略)
16. DestinationRDSTable 2018-03-15T09:51:47 WAITING_ON_DEPENDENCIES
@DestinationRDSTable_2018-03-15T09:51:47 2018-03-15T09:51:49
17. RDSToRDSCopyActivity 2018-03-15T09:51:47 RUNNING
@RDSToRDSCopyActivity_2018-03-15T09:51:47 2018-03-15T09:51:49
18. SourceRDSTable 2018-03-15T09:51:47 FINISHED
@SourceRDSTable_2018-03-15T09:51:47 2018-03-15T09:51:49 2018-03-15T09:51:49
SELECT中です。SourceRDSTableがFinishというのは接続が完了しているという意味ですね。
$ aws datapipeline list-runs --pipeline-id df-05080758GGYTM3CCZ0R
Name Scheduled Start Status
ID Started Ended
---------------------------------------------------------------------------------------------------
(省略)
16. DestinationRDSTable 2018-03-15T09:51:47 FINISHED
@DestinationRDSTable_2018-03-15T09:51:47 2018-03-15T09:51:49 2018-03-15T09:52:05
17. RDSToRDSCopyActivity 2018-03-15T09:51:47 FINISHED
@RDSToRDSCopyActivity_2018-03-15T09:51:47 2018-03-15T09:51:49 2018-03-15T09:52:04
18. SourceRDSTable 2018-03-15T09:51:47 FINISHED
@SourceRDSTable_2018-03-15T09:51:47 2018-03-15T09:51:49 2018-03-15T09:51:49
終わったようです。10万件では15-16秒かかりました。
postgres_test=> select count(*) from t_dest;
count
--------
100000
(1 行)
コピーもされています。
同様に100万件を実行してみました。
19. DestinationRDSTable 2018-03-15T09:57:27 FINISHED
@DestinationRDSTable_2018-03-15T09:57:27 2018-03-15T09:57:29 2018-03-15T09:59:45
20. RDSToRDSCopyActivity 2018-03-15T09:57:27 FINISHED
@RDSToRDSCopyActivity_2018-03-15T09:57:27 2018-03-15T09:57:29 2018-03-15T09:59:44
21. SourceRDSTable 2018-03-15T09:57:27 FINISHED
@SourceRDSTable_2018-03-15T09:57:27 2018-03-15T09:57:30 2018-03-15T09:57:30
135秒程度となりました。
気をつけるべきこと
Data PipelineはTask RunnerのJVMにすべての行を取り込んでからOutput側のクエリを実行しています。そのため、JVMのヒープについては注意するようにしましょう。JVMのガベージコレクションについてのログを取得し、必要に応じてヒープ設定を加えるべきです。そもそも、大量のデータを扱うのであればGlueなどを用いる方が良いでしょう。
なお、PostgreSQLのログを確認したところ、executeBatch()によるバッチ更新となっており、コミットは200件に1回程度実行されていました。この更新方法や頻度、バインド変数が文字列でバインドされるなどの挙動は制御できませんので、きちんと検証して目的に合うことを確認する必要があるでしょう。