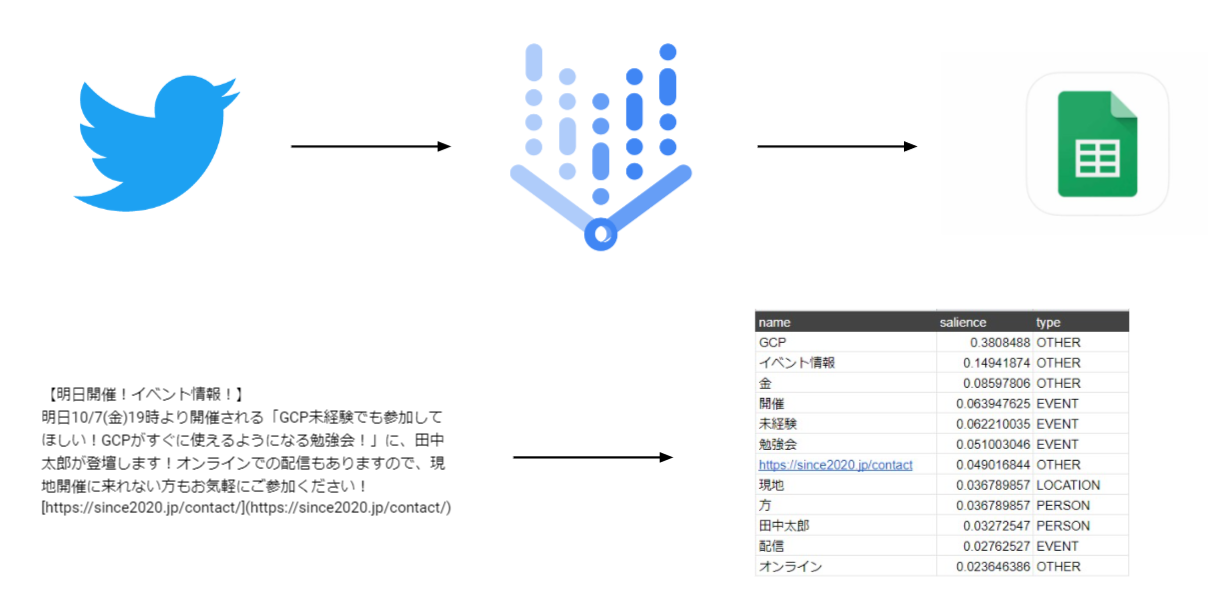
この記事では「Natural language API」を使用してツイートを数値化し分析をしてみます。
目次
- 分析の目的は「Twitterをバズらせる!」
- Natural language APIで自然言語処理ができる
- Natural language APIを使ってみる
- NLAPI(Natural language API)をGCPにて有効化する
- NLAPI(Natural language API)をスプシで使う
- NLAPI(Natural language API)の分析結果の解釈
分析の目的は「Twitterをバズらせる!」
本分析の目的は 「潜在ニーズの表出」と「SNS(twitter)からのサイトへの流入」であり、
本分析の目標は「この単語を使うとエンゲージメント率(サイトURLクリック率)が上がりますよ!」と言えるようになることです。
手順は以下の通りです。
- GASを使用して、スプレッドシート経由でツイートを自然言語処理
- 数値化されたツイートをBigQueryに挿入
- データポータルで可視化、BQMLで分析
この記事では手順1のツイートを自然言語処理する部分の記事です。
「Natural language API」で自然言語処理ができる
Cloud Natural Language | Google Cloud
「Natural language API」とはGoogleが提供する自然言語処理APIです。このAPIでは、「構文解析」「感情分析」「エンティティ分析」「エンティティ感情分析」「コンテンツの分類」を行うことができます。今回のTwitter分析では「エンティティ感情分析」を使用しました。
Natural language APIを使ってみる
ツイートを数値化し、分析できる形に変換します。
以下の記事を参考に行っていきます。
Natural Language API でお手軽センチメント分析(感情分析) - Qiita
NLAPIをGCPにて有効化する
Cloud Natural Language | Google Cloud
途中でクレジットカードの登録が必要です。
左上のナビゲーションメニューから、「APIとサービス」→「ライブラリ」→「Natural language API」で検索し、有効化します。

↑有効化された画面
その後、「APIとサービス」→「認証情報」→「認証情報を作成」からAPIキーを作成してください。APIキーはこの後スクリプトで使います。
料金について
5000ユニットまでは無料で分析を行うことができます。詳しくはドキュメントの料金の欄をご覧ください。
Pricing | Cloud Natural Language | Google Cloud
今回の筆者の分析は、今回は1800ツイートほど分析しました。1000文字=1ユニットであり、Twitterの文字制限は280文字です。つまり1800ユニットであり、無料枠の中で分析をすることができました。
NLAPIをスプシで使う
使用するのは「エンティティ感情分析」です。
サンプルコード
//mySheetの定義
//スプシのIDを自動で取得
var mySheet = SpreadsheetApp.openById(SpreadsheetApp.getActiveSpreadsheet().getId()).getSheetByName(SpreadsheetApp.getActiveSpreadsheet().getSheetName());
//Natural Language APIキー
var apiKey = "ここに先ほどのAPIキーを入力してください";
//指定した範囲のテキストを取得して、配列に保存、配列の長さを取得してlenに入力
const ss = SpreadsheetApp.getActiveSheet()
const cont = ss.getActiveRange().getValues();
var len = cont.length
main(len,cont)
//シートの分析結果の値のクリア
var range = mySheet.getRange("B2:G5000");
// そのセル範囲にある値のみクリア
range.clearContent();
//onOpenメソッドから呼び出される。センチメント分析をする範囲を引数として渡す
function main() {
getSentiment(2, len);
}
//センチメント分析を行うメソッド。引数で指定された範囲のセルを分析
function getSentiment(start, end) {
//エンティティの取り出しのための変数定義
var c = 0;
//エンティティの分析結果を書き出すセルを指定するための変数の定義
var e = 2;
//1から繰り返してendより大きくなったら終了
for (i = start; i <= end + 1; i++) {
//分析文を取得したcontから文を取得
var tweet = cont[c]
Logger.log(cont)
c += 1
//セルから取得した文字列をAPIへ送信
var response = retrieveSentiment(tweet[0]);
//JSONをGASで読み込めるようにする
var json = JSON.parse(response);
//json(分析結果)の単語の個数を取得
var jsonlen = json["entities"].length;
//分析結果を挿入
for (a = 0; a<jsonlen; a++){
var score = json["entities"][a]["sentiment"]["score"];
var magnitude = json["entities"][a]["sentiment"]["magnitude"];
var name = json["entities"][a]["name"];
var type = json["entities"][a]["type"];
var salience = json["entities"][a]["salience"];
mySheet.getRange(e, 1).setValue(tweet);
mySheet.getRange(e, 2).setValue(name);
mySheet.getRange(e, 3).setValue(salience);
mySheet.getRange(e, 4).setValue(type);
mySheet.getRange(e, 5).setValue(score);
mySheet.getRange(e, 6).setValue(magnitude);
e = e + 1;
}
}
}
//APIに送る型の指定
function retrieveSentiment(textData) {
//行う分析のHTMLを指定する。今回はエンティティ感情分析
var apiEndpoint =
"https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=" +
apiKey;
//ドキュメントの型の指定
var docDetails = {
//言語の指定
language: "ja-jp",
//テキストのタイプの指定
type: "PLAIN_TEXT",
//分析する文の指定
content: textData,
};
var nlData = {
//入力テキスト
document: docDetails,
//どの文字コード系で符号化されているか
encodingType: "UTF8",
};
var nlOptions = {
method: "post",
contentType: "application/json",
payload: JSON.stringify(nlData),
};
var response = UrlFetchApp.fetch(apiEndpoint, nlOptions);
Logger.log("json is :" + response);
return response;
}
function onOpen() {
SpreadsheetApp
.getActiveSpreadsheet()
.addMenu('カスタムメニュー', [
{name: 'センチメント分析', functionName: 'main'}
]);
}
onOpen();
- スプレッドシートを新規作成し、拡張機能から「AppScript」を選択

2.サンプルコードをペーストする

APIキーを自分のAPIキーに変更してください。その後シートに戻ってF5で更新すると、「カスタムメニュー」が表示されるので、A列に分析したい文章を入力し範囲選択することによって分析をすることができます。

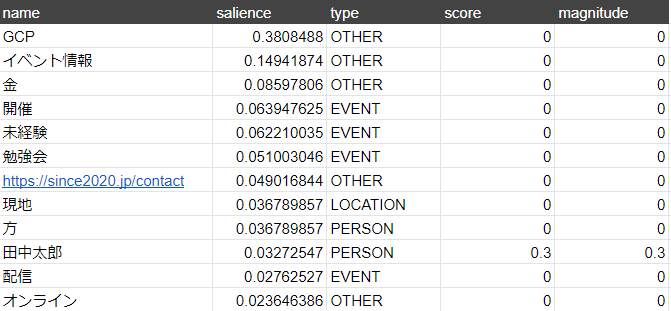
このように結果が表示されれば分析成功です。
結果の解釈
| name | 検出された単語 |
| salience | その単語の重要度(1最大値でそれぞれの単語に分配されて行きます) |
| type | その単語がどんな単語か(詳しくはドキュメントを参照してくださいhttps://cloud.google.com/natural-language/docs/reference/rest/v1/Entity#Type_1) |
| score | -1.0~1.0の間で値が小さいほどネガティブ、大きいほどポジティブです |
| magnitude | その単語の感情の強度 |
まとめ
これによって文章を数値データにすることができました。「Natural language API」を使用することによって、Twitterの文章に限らず様々な文章の傾向を数値化することができます。
反省点としては、「エンティティ感情分析」を使用したのですが、テキストの傾向的にscoreとmagunitudeの値がうまく返ってこなかった点です。
次回はこの数値とTwitterのアナリティクスデータをBigQueryにアップし、分析ができるようにしていきます。