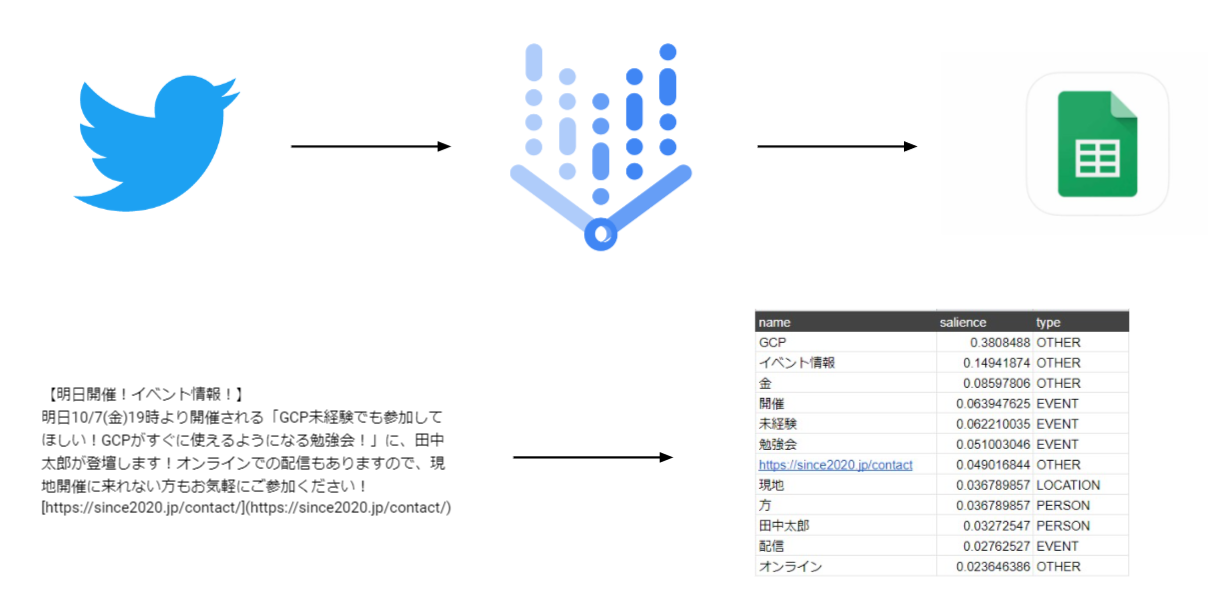
この記事では「Natural language API」を使用してツイートを数値化し分析をしてみます。
目次
- 分析の目的は「Twitterをバズらせる!」
- 「Natural language API」の値の意味
- 分析で何を行ったのか
- BQMLで分析
- データポータルで可視化
- データの加工
- データ分析の結果
- まとめ
分析の目的は「Twitterをバズらせる!」
本分析の目的は 「潜在ニーズの表出」と「SNS(twitter)からのサイトへの流入」であり、
本分析の目標は「この単語を使うとエンゲージメント率(サイトURLクリック率)が上がりますよ!」と言えるようになることです。
手順は以下の通りです。
- GASを使用して、スプレッドシート経由でツイートを自然言語処理
- 数値化されたツイートをBigQueryに挿入
- データポータルで可視化、BQMLで分析
この記事では手順3のデータポータルで可視化、BQMLで分析の部分の記事です。
「Natural language API」の値の意味
ここでそれぞれの値の意味を改めて確認します。
| name | 検出された単語 |
| salience | その単語の重要度(1最大値でそれぞれの単語に分配されて行きます) |
| type | その単語がどんな単語か(詳しくはドキュメントを参照してくださいhttps://cloud.google.com/natural-language/docs/reference/rest/v1/Entity#Type_1) |
| score | -1.0~1.0の間で値が小さいほどネガティブ、大きいほどポジティブです |
| magnitude | その単語の感情の強度 |
今回は特に、「name」「salience」の二つの値を主に使っています。
分析で行ったこと
まずは以下のサイトを参考に回帰分析を行いました。
https://www.magellanic-clouds.com/blocks/blog/other/try_to_use_bigquery_ml/
# モデル作成
create model `モデルの作成先を指定`
options(model_type='linear_reg') as
select
<フィールド名>,
<フィールド名> as label--labelをつけることによって被説明変数を指定
from `モデルを作るテーブルを指定`
where DATETIME1 between '2020-04-01 00:00:00 UTC' AND '2022-03-31 00:00:00 UTC';--データの範囲を指定する
上記サイトを参考にした回帰分析モデルの作成クエリです。
この回帰分析を行って出てきた反省点
- 回帰分析の種類
ロジスティック回帰分析と線形回帰分析があり、ロジスティック回帰を使用していた。
ロジスティック回帰:説明変数から二値の結果を予測します。例)合格か不合格か
線形回帰:説明変数から値を予測します。例)気温や曜日から電力消費量を予測する
今回の分析では「この単語を入れたらどれくらいインプレッション率が上がるか」を知りたかったので、少なくともロジスティック回帰分析は適していませんでした。
これ以外にも
- モデル作成の期間設定
モデル学習データの期間を1カ月分しか指定していなかったため、決定係数が高く出てしまった。 - 変数の多重共線性
説明変数の中に、説明変数どうしが互いに相関関係にあるものを採用してしまった点
以上のことからあまり良い結果を得ることができませんでした。
ここで行ったのがデータの可視化です。
データの可視化
可視化では散布図やグラフにデータを起こしてみました。エンゲージメント率の平均を時間帯ごとに棒グラフに起こしたり、分類ごとのエンゲージメント率の平均を円グラフにしました。しかし、ここでも間違ったやり方をしてしまいました。
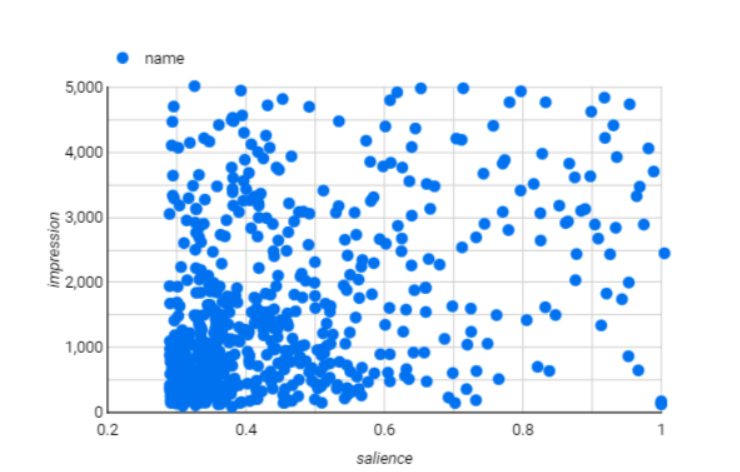
例えばこの散布図です。これだけ散らばりがあると相関性がなく回帰分析などの説明変数として使うことはできないように思えます。
しかしここで使っている値が、「インプレッション数」と「重要度」です。インプレッション数はそのツイートが何回ユーザーの目に入ったかであり、重要度はNLAPIによって本文が単語分けされ、その単語が文の中でどれだけの重要度を持っているかを表しています。
文の中で重要度高ければインプレッション数が上がるというのはおかしな話になってしまいます。考えるなら、文の中にインプレッション数が高いツイートに頻出している単語が多く入っているのでインプレッション数が上がるなどということです。なので全く役に立たない散布図を作ってしまいました。
改善点
データを可視化するにも、重回帰分析をするにも変数に対する理解度を上げ、必要に応じて加工をしなくてはいけません。この状態でAutoMLを使用した分析も行ってしまい、結果につながらないモデルを作成してしまいました。まずは、データを可視化することによってそのデータがどういうことを表しているのかをしっかりと理解することを最初に行いたいと感じました。
データの加工
NLAPI(Natural language API)を使用してデータを作成しているわけですから、そのデータがどうすれば使えるようになるのかはしっかりと吟味していかなくてはなりません。
例えば、NLAPIで出てきた「重要度」という値はその文のなかの単語の重要度を表しているので、そのままではエンゲージメント率について説明する値にはなりません。なので、ツイートのエンゲージメント率を重要度に応じて単語に分配するということが必要になります。これをすればその単語がエンゲージメント率をどれくらい保有しているかがわかります。
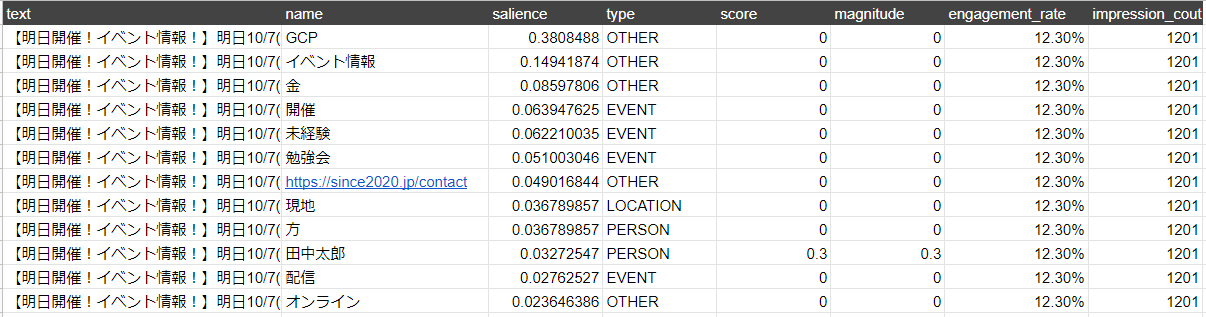
これはNLAPIで数値化されたデータと、Twitterアナリティクスのデータを組み合わせたテーブルです。(これはサンプルであり、実際のTwitterアナリティクスは様々な数値があります)

(エンゲージメント率×重要度)でエンゲージメント率を単語ごとに重みづけし、それを降順に並べました。
重要度から見ると、GCPという単語がインプレッション率を4.68%保持している可能性があるということがここでわかります。
このようにデータが使えるのか使えないのか、どうやったら使えるようになるのかはよく考える必要があります。
データの分析結果
今回のデータ分析でできるようになったことは「Twitterアナリティクス情報を単語ごとに分配することです」これによって、単語ごとにアナリティクス情報を見れるようになりました。
そこから、エンゲージメント率を高めたければこの単語を使う。インプレッション率を高めたければこの単語を使うといった情報を見ることができます。
これらをさらに組み合わせてもっと深い分析も行っていきたいです。
まとめ
ここまでで「Natural language API」による自然言語処理によってツイートを数値化し、それをBigQueryにアップ、そしてBQMLなどを使用して分析するいう流れをやってきました。
分析の部分に関しては、データがあるからまずはやってみようという形で回帰分析などに取り組んでしまったため、目的・目標にそぐわない分析を行ってしまいました。これがぶれないようにするには「データの可視化」が鍵であると感じました。データを可視化する工程で作成したデータがどういうものなのか、どうすれば目的・目標に近づけるのかが自分の中でわかってきます。
今回の分析を糧により的確な結果を出していけるようになりたいと思います。これで「SNSを自然言語処理で分析」の記事は終わりになります。ご覧くださりありがとうございました。