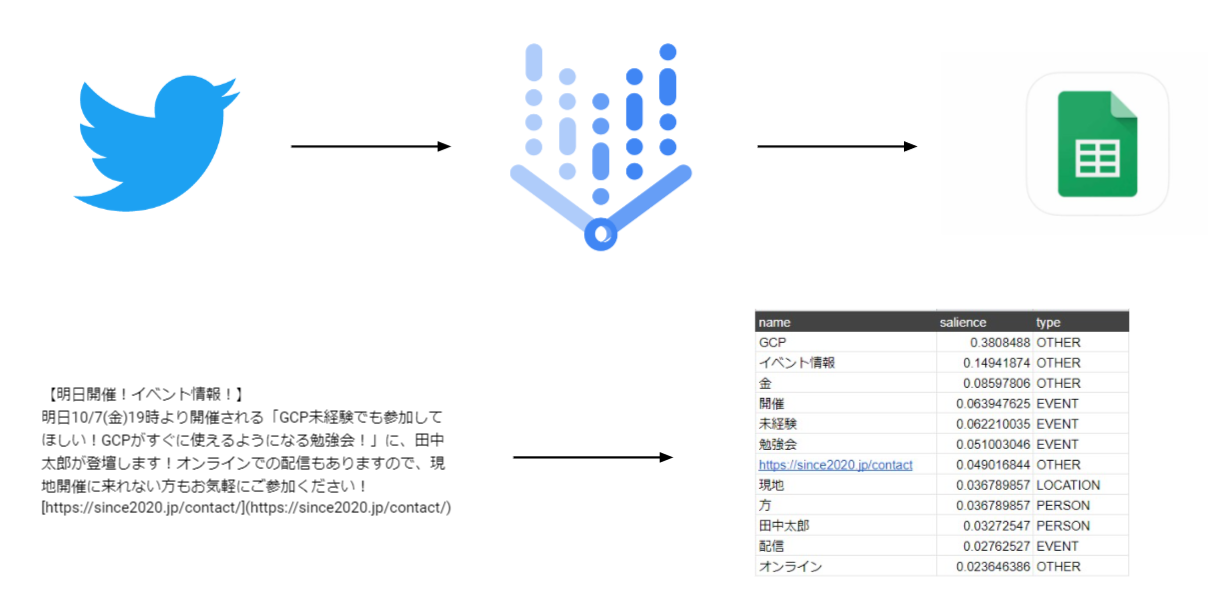
この記事では「Natural language API」を使用してツイートを数値化し分析をしてみます。
目次
- 分析の目的は「Twitterをバズらせる!」
- BigQueryにデータをアップ
- BigQueryに表形式データ、またはCSVをアップするやり方
- フィールド名が「_」になってしまう
- ツイートの数値化データとアナリティクスデータを結合しながらテーブルを作成
- 時間データが文字列型(String型)で入ってしまう
分析の目的は「Twitterをバズらせる!」
本分析の目的は 「潜在ニーズの表出」と「SNS(twitter)からのサイトへの流入」であり、
本分析の目標は「この単語を使うとエンゲージメント率(サイトURLクリック率)が上がりますよ!」と言えるようになることです。
手順は以下の通りです。
- GASを使用して、スプレッドシート経由でツイートを自然言語処理
- 数値化されたツイートをBigQueryに挿入
- データポータルで可視化、BQMLで分析
この記事では手順2の数値化されたツイートをBigQueryに挿入する部分の記事です。
BigQueryにデータをアップ
「Natural language API」で数値化したデータをBigQueryにアップする方法と、問題点を載せておきます。
- BigQueryに表形式データ、またはCSVをアップするやり方
- フィールド名がバグってしまう
- ツイートの数値化データとアナリティクスデータを結合しながらテーブルを作成
- 時間データが文字列型(String型)で入ってしまう
BigQueryに表形式データ、またはCSVをアップするやり方
テーブルの作成からアップロードを選択
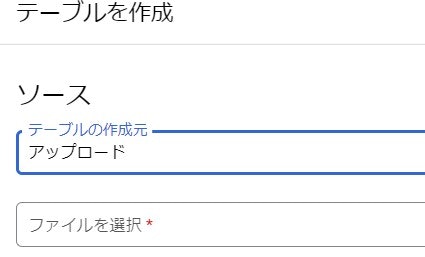
テーブルの作成からアップロードを選択し、アップしたスプシファイルを選択することでアップの準備をすることができます。
スキーマの自動検出
チェックを入れておくと、自動的にスキーマ(データ形式)を検出してくれます。

引用された改行
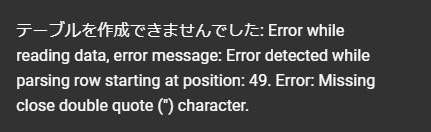
このエラーが出てきた場合には、下記の画像のように「引用された改行」にチェックを入れてください。

SCV形式のデータをアップする際に、CSVファイルに改行がある際に起きてしまうエラーのようです。チェックを入れることで自動で処理してくれるようになります。
ツイートの数値化データとアナリティクスデータを結合しながらテーブルを作成
「Natural language API」の分析結果のnameごとにツイート本文をつけていたので、今回はツイート本文を使いテーブルを結合します。
SELECT
*
FROM
`テーブル名A`
JOIN
`テーブル名A`
ON
テーブル名Aのツイート本文のカラム名 = テーブル名Bのツイート本文のカラム名
二つのテーブルのを結合したいときに、同じ定義のカラムがあるなら簡単にテーブルの結合をすることができます。
フィールド名が「_」になってしまう
BigQueryではカラム名に日本語が入っていると日本語が「_」に変換されてしまい、データの使い勝手が悪くなってしまいます。
解決方法
--データセットIDとテーブルIDを指定する
ALTER TABLE `<datasetID>.<tableID>`
--<変更したいフィールド名>と<変更した後のフィールド名の名前を入力>
RENAME COLUMN <fieldNameA> TO <fieldNameB>,
このSQLはフィールド名をからに変換するものです。これを使用して英数字を使用したフィールド名に変換しましょう。
時間データが文字列型(String型)で入ってしまう
Twitterアナリティクスデータは表形式データ、またはCSVでした。BigQueryにアップした際に「2022-01-01 00:00 +0000」がString型で入ってしまいました。
解決方法
SELECT
カラム名
,timestamp(concat(trim(rtrim(times,'+0000')),':00')) as DATETIME1
FROM
`テーブル名`
今回のデータが「2022-01-01 00:00 +0000」で入力されていたためこの形のコードになっています。
時間型に変換するには、どんな形のString型で入ってきたかによってキャストを変えなくてはなりません。今回のコードはその一助としてお使いください。
まとめ
BigQueryを使用したのが初めてだったので、どういう風にデータが入るのかなどで戸惑う点が多くありました。時間型に関しては自分のデータ型に合わせてトリムしなくてはならないので、どうやれば指定ができるのかなどをしっかりと調べる必要があります。
今回載せている問題点はすごく簡単な部分ではありますが、一度はつまずく点だと思いますので、その解決の手助けとして役立ててください。
また問題点ではありませんが、BigQueryのデータをいじっていくうちにテーブルをどんどんと作成していってしまいました。これでは自分以外がデータを触ることができなくなってしまいます。こういった点にも配慮して見やすいデータを心がけていきたいです。
次回記事はこのデータを使って分析していくところです。