これは「記事投稿キャンペーン_ChatGPT」の記事です!
1. はじめに
新しいBingのチャット機能を試したことはありますか?
質問を投げると、その質問の回答となる情報をWebから検索してきて、要約して回答してくれます。論文のように参考文献も対応する位置に表示してくれるので、それが本当かどうかリンクをたどって簡単に確かめることもできます。

自分でもこれを再現できたら面白いですよね!今回はPythonで、OpenAI APIとGoogle Custom Search APIを使って「なんちゃってBing」を作ってみました。
最近はLangChainを使って様々な大規模言語モデル(LLM)を組み合わせて簡単に、かつ驚くほどの精度の機能を実装できることは、いろいろな記事で紹介されています。その中のツールの一つに、「Google検索を自動で行い、重要な情報を抽出してLLMに流す」という機能もありますが、今回はスクレイピングの勉強もかねて、Google Custom Search APIを利用してスクレイピングを自前で行い、ChatGPTに渡してみました。
今回の実装であればスクレイピングした生の情報を編集できるので、場合によってはツールを使わずに手元で処理したほうが良いケースもあるかもしれません。
2. この記事で再現する機能
- 受け取った質問に対して適切な検索ワードを求め、スクレイピングする
- スクレイピングした情報をChatGPTに渡し、質問に回答する
- 文中に文献を表示する
今回は以下のようなフローでBingを再現してみます。
(0. 質問を受け取る)
- 質問に合った検索ワードを生成する(ChatGPT)(3.2で実装)
- その検索ワードでGoogle検索して上位のサイト情報を取得する(3.3で実装)
- 上記のサイトをスクレイピングする(3.4で実装)
- スクレイピングしたテキスト情報をChatGPTに入れて回答させる(3.5で実装)
- 回答のもとになった文献を対応させて出力する(3.6で実装)
ChatGPTを①検索ワード生成と②質問への回答の2段構成にしています。
3. 実装
早速一つ一つ機能を実装してみます。
作成するファイルは、以下の2つのみです。
- google_api.py(3.1で実装)
- chat.py(3.2~3.6で実装)
Google APIキーを事前に取得してください。以下の記事が大変参考になりました。
「Custom Search APIを使ってGoogle検索結果を取得する」
https://qiita.com/zak_y/items/42ca0f1ea14f7046108c
以下の2つの変数をご自身のものに変更してください。
- GOOGLE_API_KEY
- GOOGLE_CSE_ID
Open AIのAPIキーについても事前に取得してください。
- OPENAI_API_KEY
必要なライブラリをインストールしてください。
pip install google-api-python-client llama_index langchain
3.1 Google Custom Search APIで検索結果を得るスクリプト
まず、検索ワードを渡してGoogleの検索結果を辞書形式で返してくれる関数を定義しておきます。
import json
from googleapiclient.discovery import build
GOOGLE_API_KEY = "YOUR_API_KEY"
GOOGLE_CSE_ID = "YOUR_CSE_ID"
def search_google(keyword, num=10) -> dict:
"""Google検索を行い、レスポンスを辞書で返す"""
search_service = build("customsearch", "v1", developerKey=GOOGLE_API_KEY)
response = search_service.cse().list(
q=keyword,
cx=GOOGLE_CSE_ID,
lr='lang_ja',
num=num,
start=1
).execute()
response_json = json.dumps(response, ensure_ascii=False, indent=4)
# ファイルに書き出す必要がなければ、以下のブロックは省略できます
with open("response.json", mode='w', encoding="utf-8") as f:
f.write(response_json)
return response["items"]
if __name__ == '__main__':
keyword = input("検索キーワードを入力してください:")
search_google(keyword)
3.2 質問に合った検索ワードを生成する
今後ツールで機能拡張することを見据え、LangChainのフレームワークを利用しました。
以下のスクリプトを順番にchat.pyに貼り付けてください。
# 今回chat.pyで利用するライブラリは以下の通りです。
import os
import re
from llama_index import LLMPredictor, ServiceContext
from llama_index.readers import BeautifulSoupWebReader
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
from google_api import search_google
# APIキーを環境変数に登録しておきます
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
まず質問を入力させ、それに合った検索ワードを出力させるようにChatGPTに指示します。
たったこれだけでChatGPTにプロンプトを投げて答えを得ることができます。
# 質問文からそれに合った検索ワードを出力する
chat = ChatOpenAI(temperature=0)
question = input("質問を入力してください...")
ret = chat([HumanMessage(content="以下の例題にならって、知りたい情報を得るための適切な検索語句を出力してください。\n"
"例:「今年のWBCのMVPは誰ですか?」:「WBC 2023 MVP」\n"
"例:「初代ポケットモンスターのゲームに登場するポケモンは何種類か知りたい。」:「初代 ポケモン 種類」\n"
"例:「Linuxで使えるコマンドとその意味を分かりやすくリストアップしてほしい」:「Linux コマンド 一覧 初心者」\n"
f"問題:「{question}」")])
# ChatGPTの出力は「<検索ワード>」となるはずなので、「」の中身を取り出す
search_query = re.findall('「(.*?)」', f"{ret.content}")[0]
3.3 Google検索して上位のサイト情報を取得する
先ほど作成したgoogle_api.pyの関数にChatGPTで生成した検索キーワードを渡すだけです。
print(f"検索しています:{search_query}")
url_data = search_google(search_query) # 上位10件取得する
url_dataには、検索結果のリンクやサイトのタイトル、埋め込み情報などが含まれています。
3.4 取得したリンク先のサイトをスクレイピングする
スクレイピングも、BeautifulSoupWebReaderを使えば複数サイトの取得も一発です。。
サイトによってはスクレイピングを禁止しているサイト、アクセスできないサイトがあるので、見つけ次第ブラックリストに格納しておくことで、スクレイピングのエラーを回避します。
print(f"Webページをまとめています...")
# ブラックリスト
black_list_domain = ["hoge.com", "fuga.co.jp"]
def is_black(link): # 特定のリンクがブラックリストにあるかどうか
for l in black_list_domain:
if l in link:
return True
return False
# スクレイピングできないサイトデータは除去
url_data = [data for data in url_data if not is_black(data["link"])]
# URLのみ渡してスクレイピング
documents = BeautifulSoupWebReader().load_data(urls=[data["link"] for data in url_data])
documentsに、スクレイピングしたサイトのテキスト情報が格納されています。これを用いてChatGPTに入れるテキストdocuments_textを作成します。以下のようなイメージで、文献の番号とそのサイトのテキストを対応させておきます。
例:Qiitaについてサイトをスクレイピングした場合
【文献1】Qiitaを紹介(スニペット)
Qiitaは情報共有サービスで・・・
【文献2】Qiitaはどんなサービスなのか?特徴をご紹介!
プログラミングに特化した情報共有・・・
ChatGPTには最大のトークン数があるので、各サイトのテキストの長さをある程度で制限しておきます。また、documents_text全体の文字数も制限をかけておきます。
また、取得したサイトによっては404エラー、「ページが見つかりませんでした」など適切でないものもあるので、その語句が出現した場合はdocuments_textに含めないようにします。
max_texts = 500
documents_text = ""
references = {}
black_list_text = ["JavaScript is not available.", "404", "403", "ページが見つか", "不適切なページ", "Server error"]
def is_black_text(text):
for bt in black_list_text:
if bt in text:
return True
return False
for i in range(len(url_data)):
if is_black_text(documents[i].text):
continue
# 余分な空白や改行を除去
text = documents[i].text.replace('\n', '').replace(" ", " ").replace("\t", "")
# テキストの最初の方はサイトのメニュー関連が多いので、テキストの一部だけを抽出するなど前処理をする
# text = text[len(text)//10:]
documents_text += f"【文献{i + 1}】{url_data[i]['snippet']}\n{text}"[:max_texts] + "\n"
references[f"文献{i + 1}"] = {
"title": url_data[i]['title'],
"link": url_data[i]['link']
}
if len(documents_text) > 3000:
documents_text = documents_text[:3000]
break
3.5 スクレイピングしたテキスト情報をChatGPTに入れて回答させる
あとは、文献データをChatGPTに投げて、質問に答えてもらうだけです。
print(f"回答を生成しています...")
ret = chat([HumanMessage(content=f"以下の文献を要約して、下の質問に答えてください。\n"
f"◆文献リスト\n{documents_text}\n"
f"◆質問:{question}\n"
f"◆回答する際の注意事項:文中に対応する参考文献の番号を【文献1】のように出力してください。"
f"◆回答:"
)])
# ChatGPTの回答を格納
answer = ret.content
3.6 回答のもとになった文献を対応させて出力する
回答の中に文献番号を出力させているので、referencesを用いて、引用された対応する文献を一緒に出力させます。必ずしもすべての文献を使って回答しているわけではないので、番号をリセットします。
i = 0 # 参考文献の番号をリセット
add_ref_text = ""
for ref in references.keys():
if ref in answer:
i += 1
answer = answer.replace(f"【{ref}】", f"[{i}]")
answer = answer.replace(ref, f"[{i}]")
add_ref_text += f"[{i}] {references[ref]['title']}. {references[ref]['link']}.\n"
answer += f"\n【参考文献】\n{add_ref_text}"
完成です!!
chat.pyを実行して質問を入力すると、Bingのように答えてくれます。
4. 質問と回答サンプル
実際にBingで聞いた結果と比較してみます。
ガジェットからアニメ、映画までいろいろ聞いてみました。
2023年最新のスマートフォンの機種を3つほど教えてください。
質問を入力してください...2023年最新のスマートフォンの機種を3つほど教えてください。
検索しています:スマートフォン 最新機種 2023
Webページをまとめています
回答を生成しています...
[2]によると、2023年2月に「AQUOS sense7」の限定カラーや「Xperia 5 IV」が登場したと報じられています。また
、[1]によると、2022年最新のスマートフォンを価格帯別で紹介したランキング形式で、15機種が紹介されています
。[3]によると、SIMフリーのAndroidスマートフォンおすすめ10選の特集で、OPPO Reno7 Aが紹介されています。
【参考文献】
[1] 【2023年3月】 おすすめスマホランキング!15機種を価格帯や用途 .... https://mobareco.jp/a162253/.
[2] 「AQUOS sense7」の限定カラーや「Xperia 5 IV」が登場――SIM .... https://k-tai.watch.impress.co.jp/do
cs/sim/1483926.html.
[3] 【特集】SIMフリーのAndroidスマートフォンおすすめ10選【2023年 .... https://pc.watch.impress.co.jp/doc
s/topic/feature/1479058.html.
機種を箇条書きでリストアップこそしてくれませんでしたが、「AQUOS sense7」「Xperia 5 IV」「OPPO Reno7 A」を紹介してくれました。
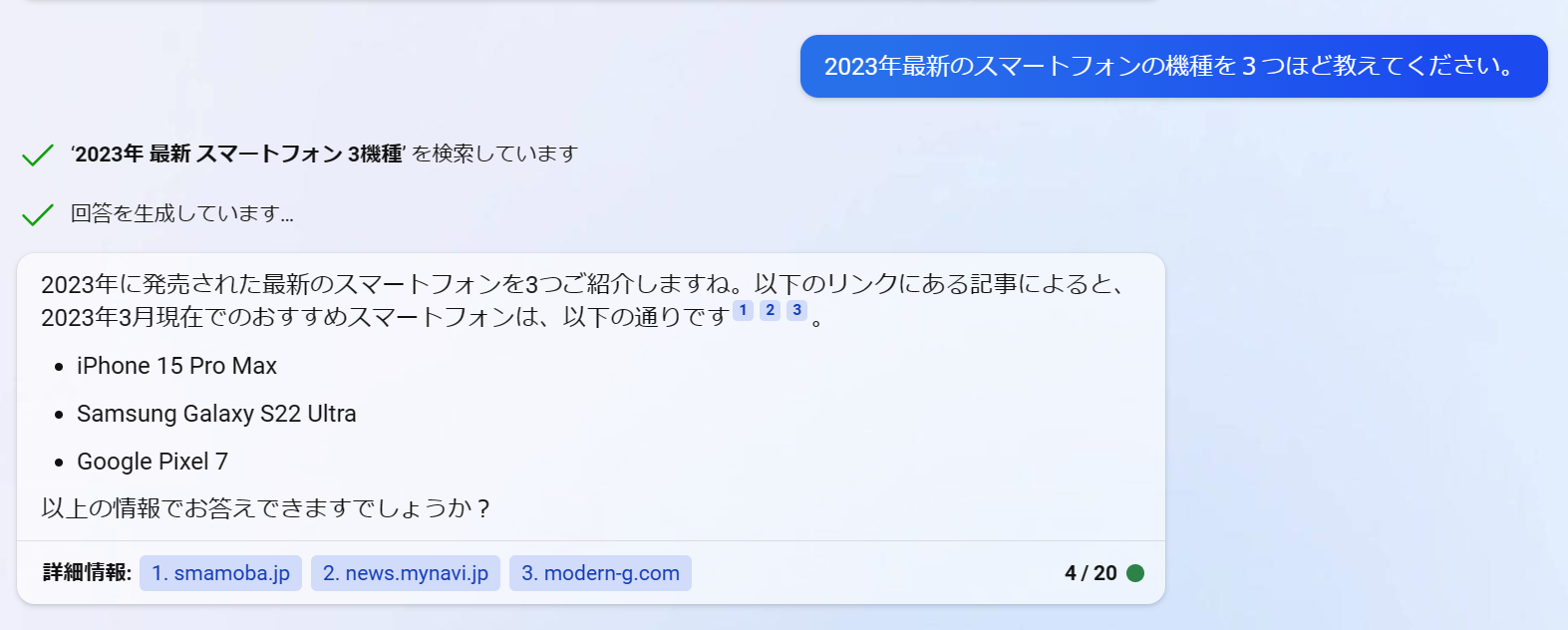
![]() 記事作成時点でiPhone 15シリーズはまだ発売されていません。Bingはたまに嘘も言ってしまうようです。「2023年に発売された」と言っているので、もしかすると今後の発売予定を紹介したサイトの文章を考慮しているのかもしれません。
記事作成時点でiPhone 15シリーズはまだ発売されていません。Bingはたまに嘘も言ってしまうようです。「2023年に発売された」と言っているので、もしかすると今後の発売予定を紹介したサイトの文章を考慮しているのかもしれません。
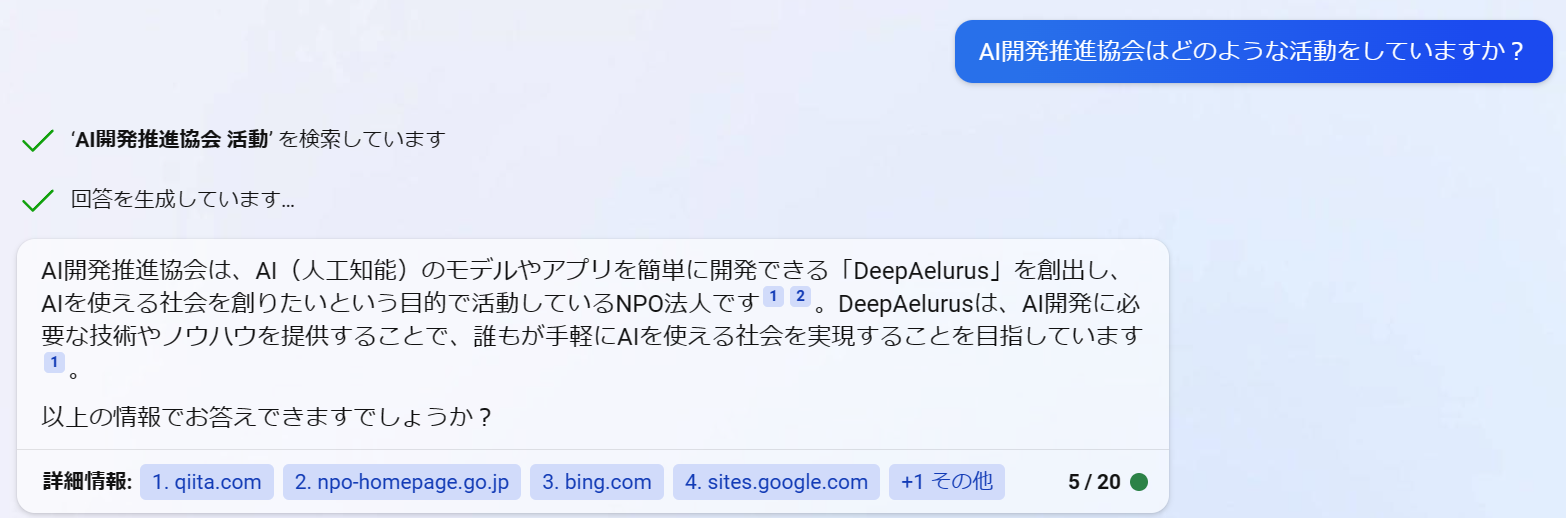
AI開発推進協会はどのような活動をしていますか?
質問を入力してください...AI開発推進協会はどのような活動をしていますか?
検索しています:AI開発推進協会 活動内容
Webページをまとめています
回答を生成しています...
AI開発推進協会は、誰でも手軽にAIを使える社会を目指し、「DeepAelurus®︎」というAI 開発デザイナを創出し、デ
ータサイエンスのオンライン学習教材やAIモデルの解説書、オンライン講習会も提供しています。また、2022 Adven
t CalenderではAIの開発・体験ツールや学習コンテンツを作成し活動しています。[1][2]
【参考文献】
[1] NPO法人AI開発推進協会. https://sites.google.com/deepaelurus.com/aboutus/.
[2] NPO法人AI開発推進協会のカレンダー | Advent Calendar 2022 - Qiita. https://qiita.com/advent-calendar/
2022/deepaelurus.
サイトの紹介文ほぼそのままのようにも見えますが、それが「AI開発推進協会はどのような活動をしていますか?」に対する回答そのものと解釈したようです。
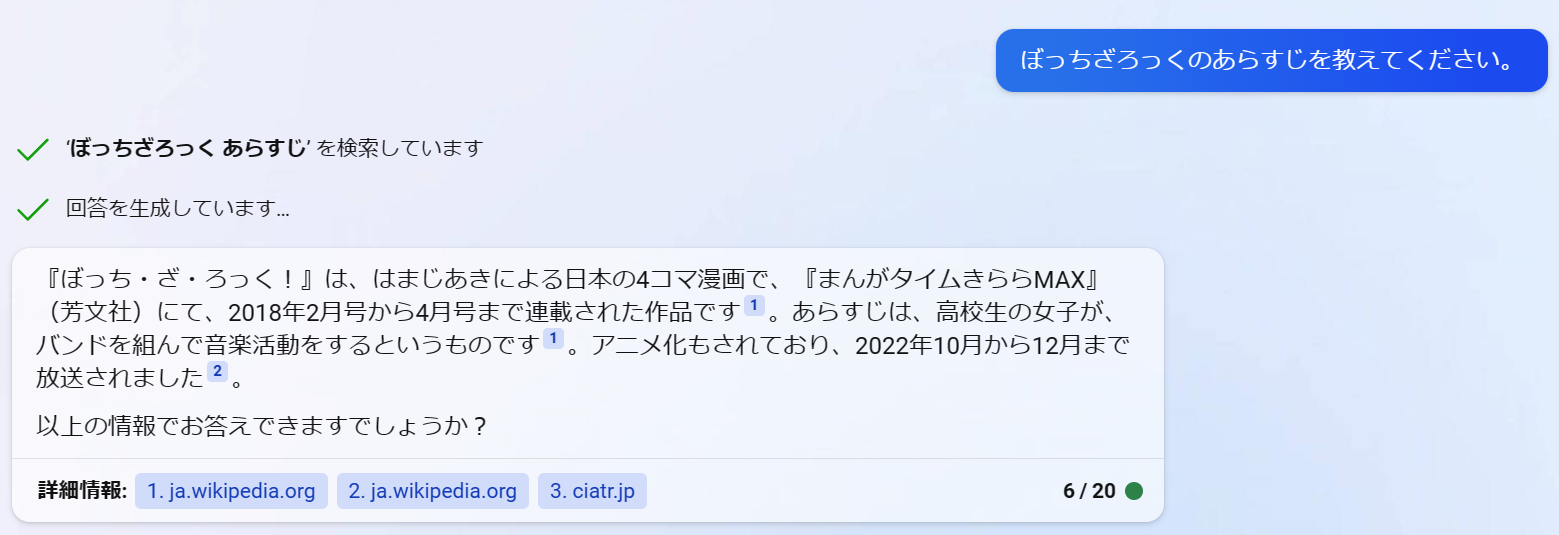
ぼっちざろっくのあらすじを教えてください。
質問を入力してください...ぼっちざろっくのあらすじを教えてください。
検索しています:ぼっちざろっく あらすじ
Webページをまとめています
回答を生成しています...
[1]によると、「ぼっち・ざ・ろっく!」はコミュニケーションが苦手で友達がいない「後藤ひとり」という主人公
が、バンド活動を通じて成長していく姿を描いた音楽漫画です。中学時代から陰キャラで友達ができず、高校でも孤
独な毎日を送っていましたが、"結束バンド"というバンドを組んで部員たちと共に成長し始めます。
【参考文献】
[1] ぼっち・ざ・ろっく!(漫画)- マンガペディア. https://mangapedia.com/%E3%81%BC%E3%81%A3%E3%81%A1%E3%8
3%BB%E3%81%96%E3%83%BB%E3%82%8D%E3%81%A3%E3%81%8F%EF%BC%81-3iy4p4ji1.
文献が1つしかないので少しボリューム不足感がありますが、主人公の名前やバンド名まで分かりました。
しかし、愛称が「ぼっちちゃん」であるなどの追加情報は教えてくれませんでした。スクレイピングしたほかのサイトのテキストが不要なものを多く含んでいたことが原因かもしれません。
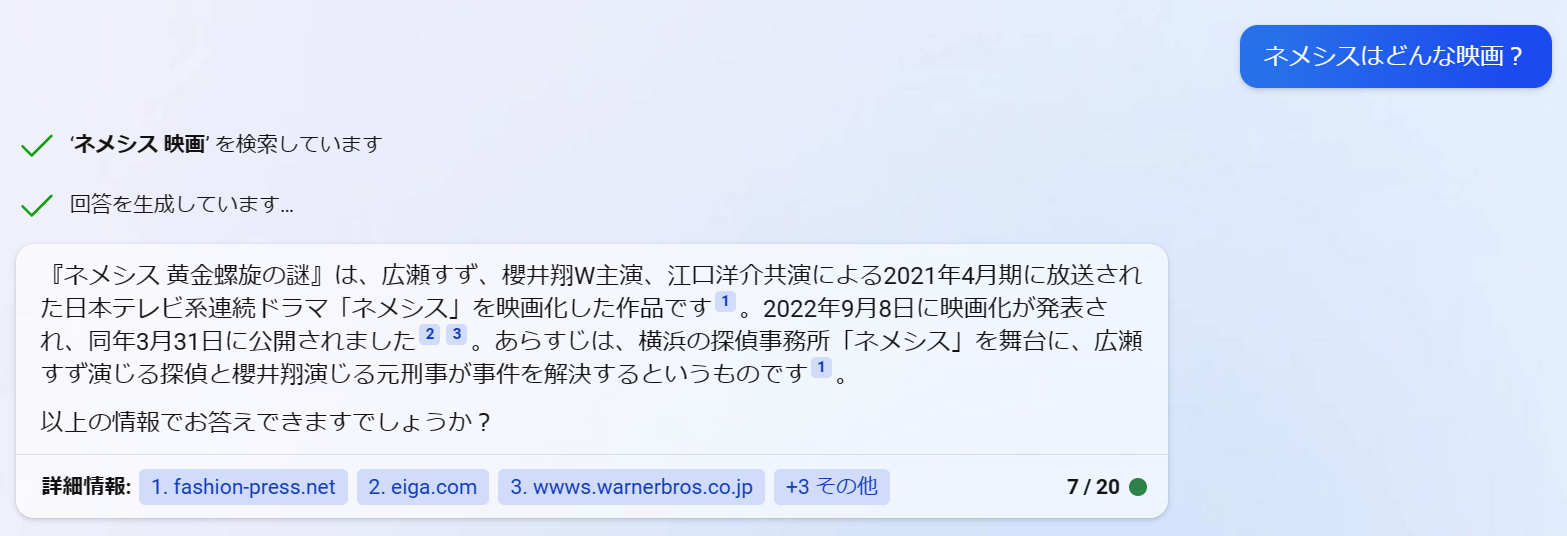
ネメシスはどんな映画?
質問を入力してください...ネメシスはどんな映画?
検索しています:ネメシス 映画 概要
Webページをまとめています
回答を生成しています...
[1]によると、「映画 ネメシス 黄金螺旋の謎」は広瀬すずと櫻井翔がW主演する大ヒットドラマ「ネメシス」を映画
化した超ミステリーエンターテイメントで、誰かが死ぬ付箋だらけの謎解きが99分間展開されるとあります。[2]に
よると、テレビでは描けなかった巨大な謎を壮大なスケールで描くとも述べられています。
【参考文献】
[1] 『映画 ネメシス 黄金螺旋の謎』公式サイト. https://wwws.warnerbros.co.jp/nemesis-movie/.
[2] ネタバレ厳禁!広瀬すず×櫻井翔たちの前に最悪の敵・佐藤浩市が .... https://otocoto.jp/news/nemesis-mo
vie1118/.
複数の文献を組み合わせて回答してくれました。「複数の文献を使って情報を補足し、かつそれぞれの文献と引用した内容を対応させて回答してもらう」ことこそ、今回実装したかったことです!
ポケモンSVのライバル的存在は誰?
質問を入力してください...ポケモンSVのライバル的存在は誰?
検索しています:ポケモンSV ライバル 性格 名前
Webページをまとめています
回答を生成しています...
ポケモンSVには複数のライバルが登場しますが、特に注目されているのはネモというキャラクターです。[1][2]
【参考文献】
[1] 『ポケモンSV』、ライバルキャラに起きた「異変」 ”アレ”が変わっ .... https://sirabee.com/2022/11/23/
20162978658/.
[2] ネモ(トレーナー) (ねも)とは【ピクシブ百科事典】. https://dic.pixiv.net/a/%E3%83%8D%E3%83%A2%28%E3%83
%88%E3%83%AC%E3%83%BC%E3%83%8A%E3%83%BC%29.
複数の文献を組み合わせて、「ライバルは『ネモ』というキャラクターだ」という情報に信憑性を持たせて回答してくれました。
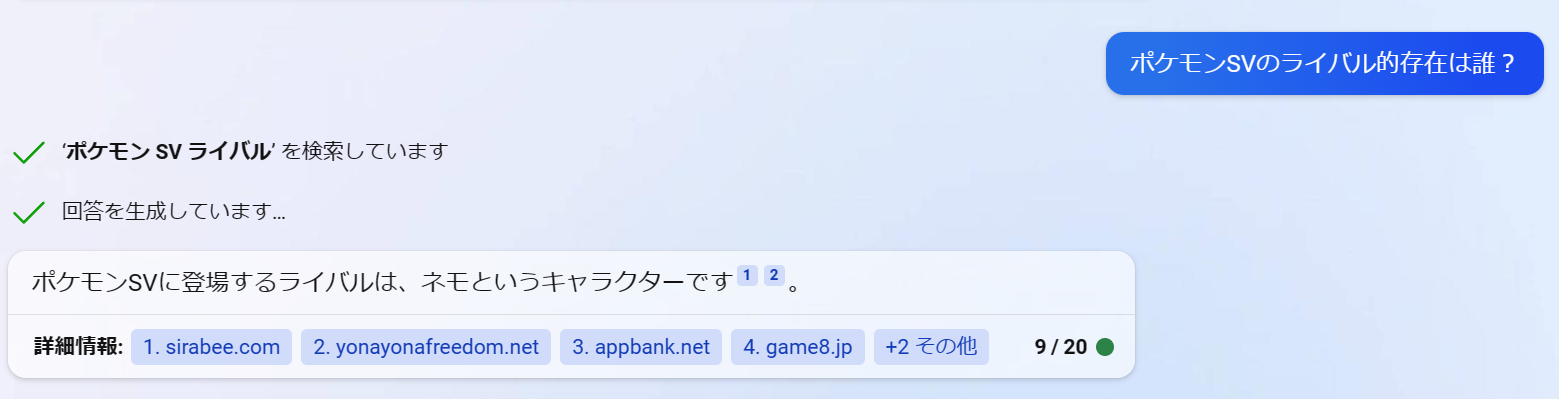
この質問においては、Bingの方が質素すぎるようにも見えます。今回のChatGPTによる実装では「ポケモンSVには複数のライバルが登場しますが、」と周辺の情報も前置きで付け加えられています。
5. さいごに
いかがでしょうか。簡単に実装でき、ほとんどの質問をBingと同じレベルで的確に答えてくれるチャットAIを作成することができました。
LangChainのいろいろなツールを組み合わせればさらに高度なAIが作れそうですね。