VIZBIとは?

VIZBI Poster 2015: http://www.vizbi.org/2015/
生物学というのは専門性の高い分野なので、他分野の人々が参入するにはかなりのハードルがあります。しかし実験技術の飛躍的な進歩により、そこで生み出されるデータは大量かつ多岐にわたり、分野外の人々にも興味深い話題が多い分野でもあります。生物学者自身も、生命という複雑なシステムを理解するための新たな手法やツールを計算機科学などの分野から求めており、そう言った人々が集う場として6年前から始まったVIZBI (Visualizing Biological Data)と言う学会があります。基本構成は一般的な学会と同じく、専門的な生物学の各トピックを掘り下げる発表とポスターセッションですが、そこにアートの発表や、著名なツールを学ぶハンズオン形式のチュートリアル、可視化分野での著名人を招いてのキーノートを挟むというのが特徴的な部分です。私自身も第一回を含め数回参加しているのですが、今年は初めて講師としても参加しました。全体を通じて感じたのは、この分野では、我々のような実務家がやるべき仕事はまだまだ多いということです。そこで今回は、実際にデータ可視化アプリケーションを作る開発者の方々にも興味深いであろう可視化一般の話題について、キーノートをまとめるという形で書いてみます。
キーノート1: Data Visualization Principles by John Stasko
初日のキーノートはジョージア工科大学の可視化研究者による、データ可視化一般についてのトークでした。主に科学分野で使う計算機ベースの可視化システムを作成する場合、どういった点に気をつけるべきなのかという点がテーマでした。
可視化はどんな時に有効なのか?
彼は、計算機ベースの可視化が最も効果的なのは、その作業が__探索的__な場合であると定義していました。すなわち
- データが何を意味しているのかまだ不明で、ユーザー自身もまだ何を導き出そうとしているのかはっきりしない時
- 専門家がインタラクティブに意味のある発見を行おうとする場合
対照的に、昔からある紙ベースの可視化は解析の結果を発表する時に効果的です。科学論文などはまさにその典型例です。従って、紙を超えた機能性をそれ相応の開発リソースを消費して提供する場合、その投資に見合う効果が得られるようにシステムをデザインする必要があります。
解析とプレゼンテーション
データ可視化と言う言葉は、基本的に2つの意味を持ちます。それは
- 解析
- プレゼンテーション
です。この2つはどちらも重要ですが、非常に異なる概念でもあります。計算機をバックグラウンドに持つ人々の可視化コミュニティでは、伝統的にはプレゼンテーション部分は軽視されがちだったそうです。これは私の想像ですが、データをプレゼンテーションするという基本技術(技法)はコンピューターの発達を待つまでもなく、Tufteを始めとする先駆者により基礎理論が構築され、紙ベースのものでかなりの事が既に実現されていたからではないでしょうか。しかし現在は、マスメディアでのインフォグラフィックの多用やウェブ関連技術の発達により、プレゼンテーション部分にも再び注目が集まりつつあるそうです。
インタラクティブ性の力
計算機ベースの可視化が紙と大きく異なるのはそのインタラクティブ性です。それを生かすにはどのようにすればよいのでしょうか。
複数のビューの利用: RepresentationとInteraction
計算機を使えば、同じデータセットに複数のビューをつけることは容易です。これは可視化ソフトウェアを作る場合のデザインパターンにもなっています。
- Software Design Patterns for Information Visualization by Jeffrey Heer and Maneesh Agrawala (2.9 Rendererパターン参照)
彼は、複数のビュー(representations)を作り、それらをユーザーが任意のタイミングでトランジションで繋ぐ(interaction)というのはコンピュータを使わないと出来ない手法であり、データを多面的に眺める事につながるので、探索的なツールを作る場合には効果的な方法だと述べていました。ここで言う複数のビューというのは、同じデータセットに対する異なる可視化手法の適用ということです。例えば階層構造(ツリー)データであれば、TreeMapとNode-Link図を組み合わせるのはよくある手法です。
また、こういったアプリケーションにはマルチモニタの活用が非常に効果的だとも補足していました。
インタラクションにおける7つのアクション
可視化アプリケーションにおいてユーザーが取りうるアクションを、彼は7つに分類していました。
- 選択 (Select)
- 探索 (Explore)
- 再設定 (Reconfigure)
- 符号化 (Encode)
- 抽象化と詳細表示の切り替え (Abstract/Elaborate)
- フィルタリング (Filter)
- 接続 (Connect)
基本的に全てのインタラクションはこの内のどれかのアクションを通して行われるということです。アプリケーションをデザインするとき、自分が作ろうとしている機能はこのうちのどれに当たるものなのかを考えながら、典型的なパターン/ベストプラクティスがあればそれを利用することも大切です。
良いインタラクションをデザインするには?
データ可視化の手法の中には、広く使われているが改善の余地のあるものはたくさんあります。トークの中で彼はいくつかの実験的手法をあげていましたが、その中の例としてグラフデータの可視化について見てみたいと思います。
Node-Link Diagram

(これはCytoscapeの機能デモとして作った人間のインタラクトームの可視化。このような単純な可視化から洞察を得るのは難しい)
上の図のように、最近の高性能なワークステーションやラップトップを使えば大量のノードとエッジをNode-Link Diagramとして表示するのは特に難しいことではありません。しかし、ただ単に大量のデータをこういった手法で表示しただけでは、何らかの洞察を得るのは難しいです(これは以前書いた記事で述べた通り)。多くの場合は、__なぜその手法を利用しているのか__と言う部分についてよく考えられずに使われています。
こういったオブジェクトの関係性を表すデータを扱う場合に、一つの改良例としてCitevisと言うアプリケーションを紹介していました。
Citevis
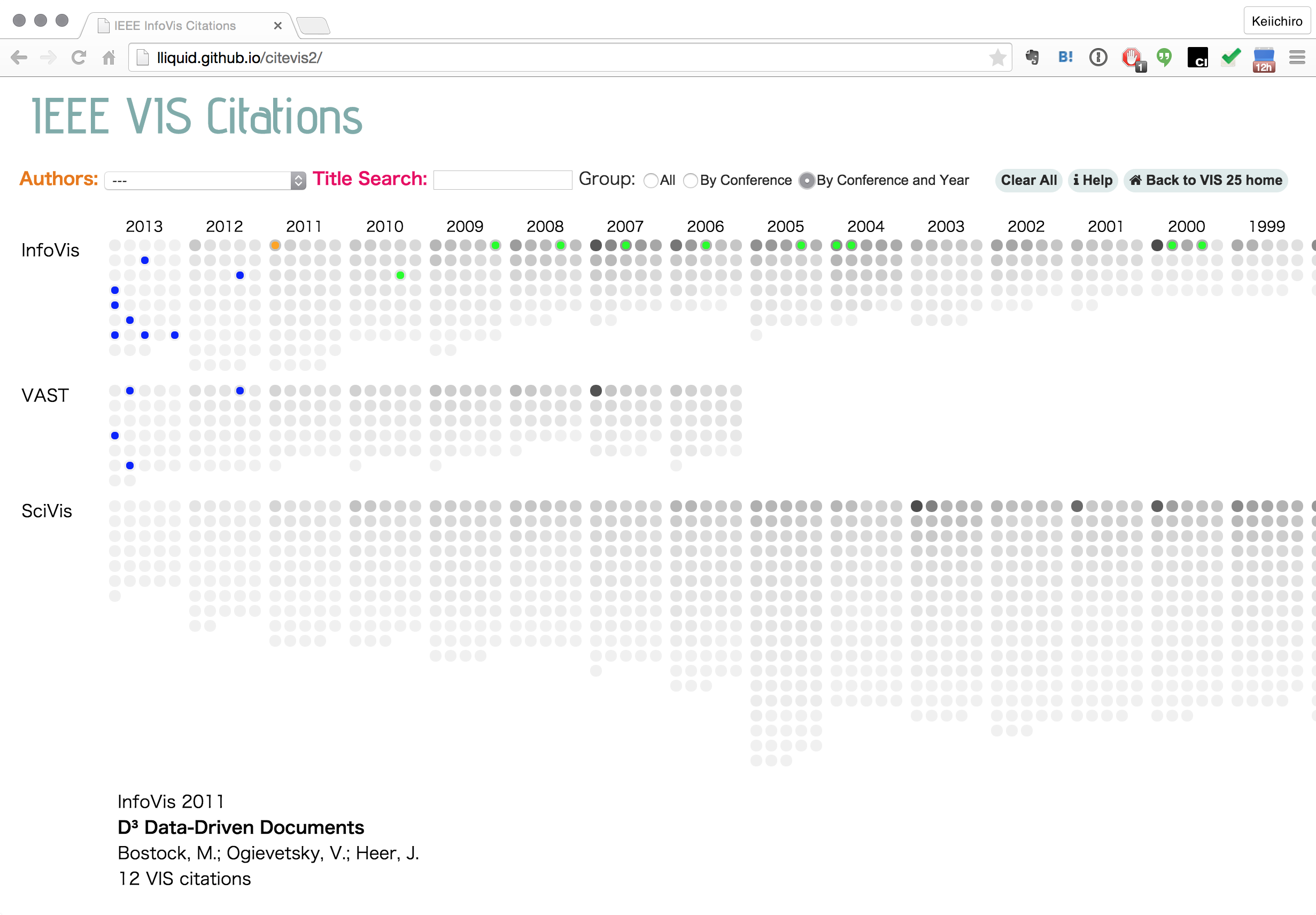
詳細はウェブサイトの方を参照していただきたいのですが、これは論文の引用関係をインタラクティブなアプリケーションとして表現したものです。上の例だと、2011年に発表されたD3.jsの論文がどの論文を引用しどの論文から引用されているのかと言う関係性を表しています。マウスを各ポイント(一つの点がひとつの論文を表す)の上に持って行くと、引用/被引用の関係を、点の色を変化させることによって表現しています。つまり、これはnode-link図では通常以下のように表現されます:
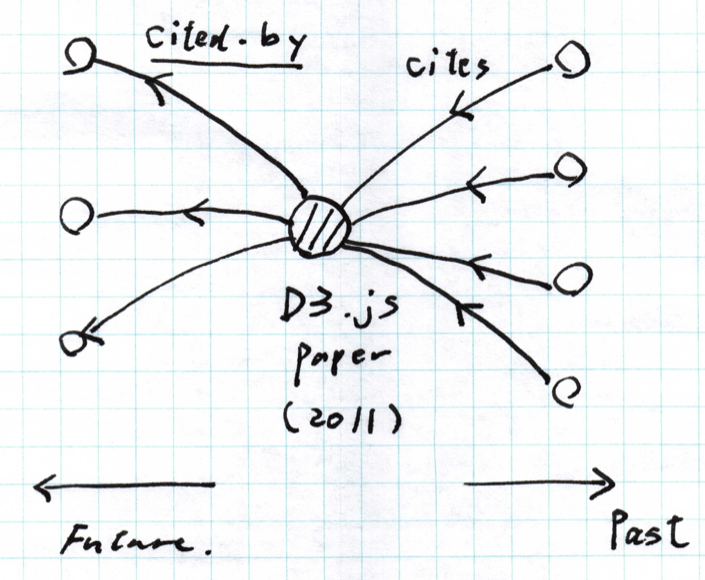
すなわち、インタラクションによって動的に関係性を表すことにより、エッジを表示する必要性をなくしています。彼は、グラフデータを可視化する場合、ほとんど場合において全ての関係性(エッジ)を同時に表示する必要性はないという点に着目して、関係性の表示をインタラクションによってトリガーされるように置き換えたということです。ここで注意したいのは、このアプリケーションはグラフデータを表示するための一つの手法を提示するサンプルとして使われていることです。つまりこれは既存の手法の置き換えではなく補完する方法であるということです。つまり、先に触れたRendererパターンを用いて同一データから既存のNode-Link図などと切り替えて表示できるようにデザインすれば、ユーザーがより多面的にデータを眺められるようになるということです。
インタラクションのための道具の進化
少し前まで可視化アプリケーションといえば、ワークステーションかラップトップで実行するのが普通でした。しかし今はタッチパネルを装備したデバイスが大量に出まわっており、当然そういったものを考慮に入れた新しいインタラクションも必要です。
ここでは、既存の可視化手法に、新しいスタイルのインタラクションをデザインすると言う例です。同じ散布図やバーチャートでも、タッチに最適なものにデザインし直すことによって使い勝手は向上しますし、
より良い可視化を目指す
良い可視化アプリケーションを作成するためには、まず今の段階でどうして可視化がデータを理解するのに強力なツールとなるのか、背景を理解しておくのが大切です。この論文は、可視化の有用さを専門家が分かりやすく紹介していますので、一読をお薦めします。
実装することの大切さ
公開データの数は飛躍的に増えています。しかし、実際にはそれらはただの数字としてネットの何処かに埋もれている場合がほとんどです。データの有用さ、面白さは可視化してみて初めてわかるということもしばしばです。一例として、彼の学生プロジェクトでの一件を紹介していました。
このクラスの期末プロジェクトで、公開されている大学教授の給与を多面的に表示できるアプリケーションを作りました。これ自体は、ずっと公開されているデータを可視化しただけなのですが、アプリケーションを公開した直後から他の教授からの苦情が殺到して、最終的に公開中止にしたそうです。この例が興味深いのは__誰もがアクセスできる公開データでも、可視化アプリケーションとして見やすくまとめるとオーディエンスの反応が全く異なる__という点です。これはすなわち可視化の力を表している例で、データジャーナリズムなどという言葉がもてはやされる理由の一つでもあります。
良い可視化とは?
可視化の__価値__を客観的に評価するのは容易ではありません。残念ながら、可視化の良さを定量的に評価する汎用的な手法は未だありません。
V = T + I + U + E + C
厳密な方法ではありませんが、ある程度客観的な評価を下す方法として、彼は以下の指標(と言うよりはスローガン)を提案していました。
__V__alue = __T__ime + __I__nsights + __U__nexpected + __E__ssence + __C__onfidence
- Value (可視化の価値、有用さ)
- Time (そのツールによって短縮可能なユーザーの時間)
- Insights (洞察を得られるか)
- Unexpected (偶然の発見の可能性。いわゆるセレンディピティ)
- Essence (全体像を得ることが出来るかどうか)
- Confidence (得られる情報の信頼性)
つまり、その__可視化が価値のあるものかどうかを判定する場合は、この各ポイントについて考察し、それらが高い次元で実現されているかどうかを判断基準とする__ということです。
良い可視化の例: Edward Tufteの著書に掲載されているNYTによる気候プロット
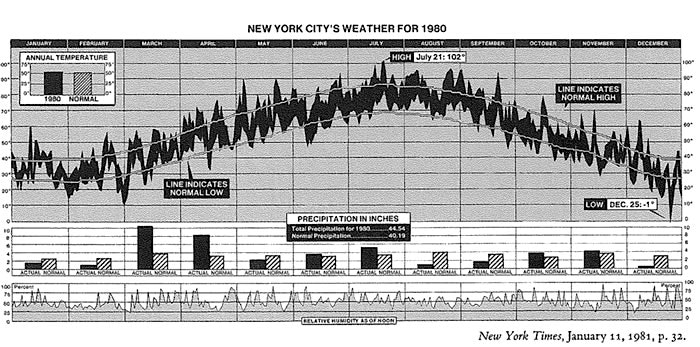
New York City's Weather for 1980 (1981. By New York Times)
このプロットは、ニューヨーク市の1980年一年間の気象データを可視化したものです。しかしその中には、2000を超えるデータポイントがエンコードされています。もしそれを生の数字のまま眺めたとしても、恐らく何も洞察は得られないと思います。このように適切に可視化することにより、大量のデータを短時間に人間が把握できる状態にすることが出来るという例なので、これは良い可視化の例と言えます。
未解決の課題
大きな力を持つデータ可視化という技術ですが、まだ解決すべき課題は山積みです。Stasko教授は、最後にまとめとして未解決の問題をいくつかあげていました。
可視化アプリケーションの作成ツールの改善
今は、多くの可視化アプリケーションがウェブブラウザ上で、広く使われているWeb系の技術で実装される時代です。すなわち、多くの人はJavaScriptやCanvas、WebGLと言った技術を使ってアプリケーションを実装します。ここで問題になるのはそれらのツールが本当に使いやすいものかどうかという点です。具体的には、D3.jsのようなライブラリが、本当にすべての人にとってベストな解なのかどうかと言う部分です。D3.jsはたしかに素晴らしいツールですが、それなりに学習コストがありますし、専業プログラマ以外にはなかなか扱いづらいものではあります。この辺りにオープンソースプロジェクトが貢献できる余地はまだまだ大きいです。
現実世界の巨大なデータ
_ビッグデータ_と言う言葉を目にしない日はないほどに大規模データの話題はあちこちで話題に上がります。しかし、それを可視化する場合、どういった手法や技術を用いるのがベストなのかというのは未だに未解決の問題です。印象的だったのは、「データが本当に『大きい』ものならば、そもそも可視化を用いるのが適当でない場合もある」と彼が言っていた点です。巨大なデータから何を得たいのかを考えずに漫然と既存の可視化手法を用いることは、上の例であげた「巨大な毛玉」のような結果に陥りがちです。計算機のパワーがあるのでそれをとりあえず使ってみる、と言うアプローチよりも、「何を見たいのか?」と言う問題点に立ち返りながら手法とツールの両方をブラッシュアップしてゆく必要がありそうです。
まとめ
今回はVIZBIと言う、恐らく多くの方にとっては馴染みのない学会での講演を紹介してみましたが、どうでしょう?おそらく多くの方が、想像よりも広い話題が扱われていると感じたのではないでしょうか。これらはコンピュータを扱う分野の人間にも十分興味深い分野であると知っていただければ幸いです。
後日、二日目のキーノート(データを使ったコンピュータ・アートを作成すると言う試みでは先駆者のJer Thorp氏によるものです)に続きます。