みなさん、今年の4月、5月は何してましたか?
緊急事態宣言が出てステイホームしていた人も多いと思いますが、在宅でできるデータ分析の仕事と言えばKDD CUPですよね!(無理矢理)
ドコモの落合です。KDD Cupはデータマイニングの国際学術会議であるKDDで開催されている、1997年からの歴史がある世界最高峰のデータ分析コンペです。
ドコモR&DではAI・データサイエンス分野での実力向上のために2016年から毎年KDD CUPに参加していて(KDD CUPは業務時間内に取り組んでいいことになっています)、昨年は1つのトラックで優勝しました。今年は、3部門で入賞1,2することができました。ML Track1については初日の記事で紹介しています。
この記事では、ML Track2で446チームが参加したなかで4位に入賞した手法について解説します。
KDD Cup 2020 ML Track2
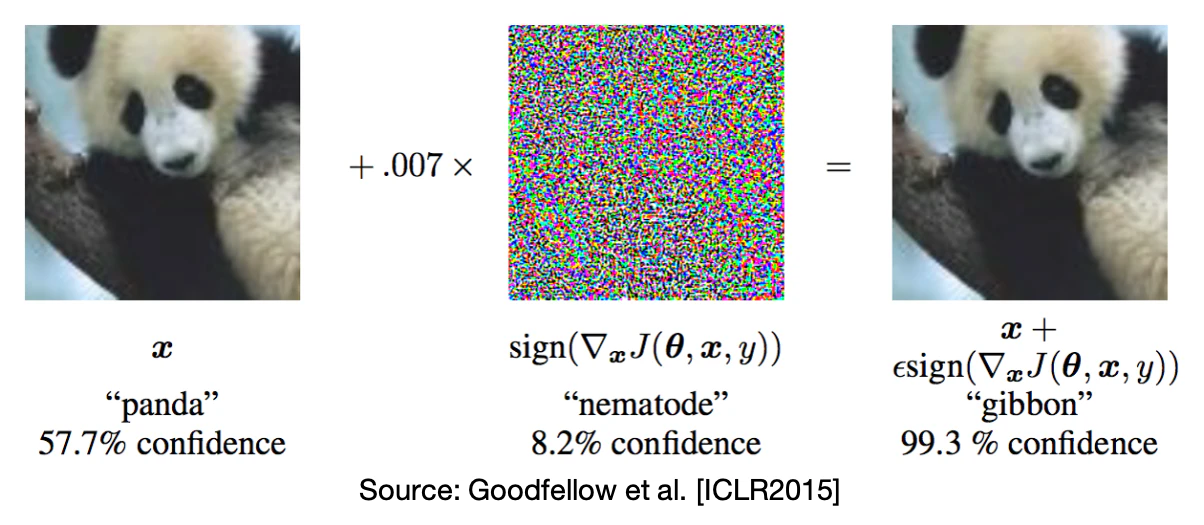
数年前から深層学習モデルに対して、わずかに値を変動させることでモデルを誤認識させる攻撃であるAdversarial Attackという攻撃が知られています。有名なのは下の図の例3で、パンダの画像にノイズのような画像を加えることで認識結果がテナガザル(gibbon)になっています。人間にはパンダに見えますが、深層学習モデルは誤認識してしまいます。
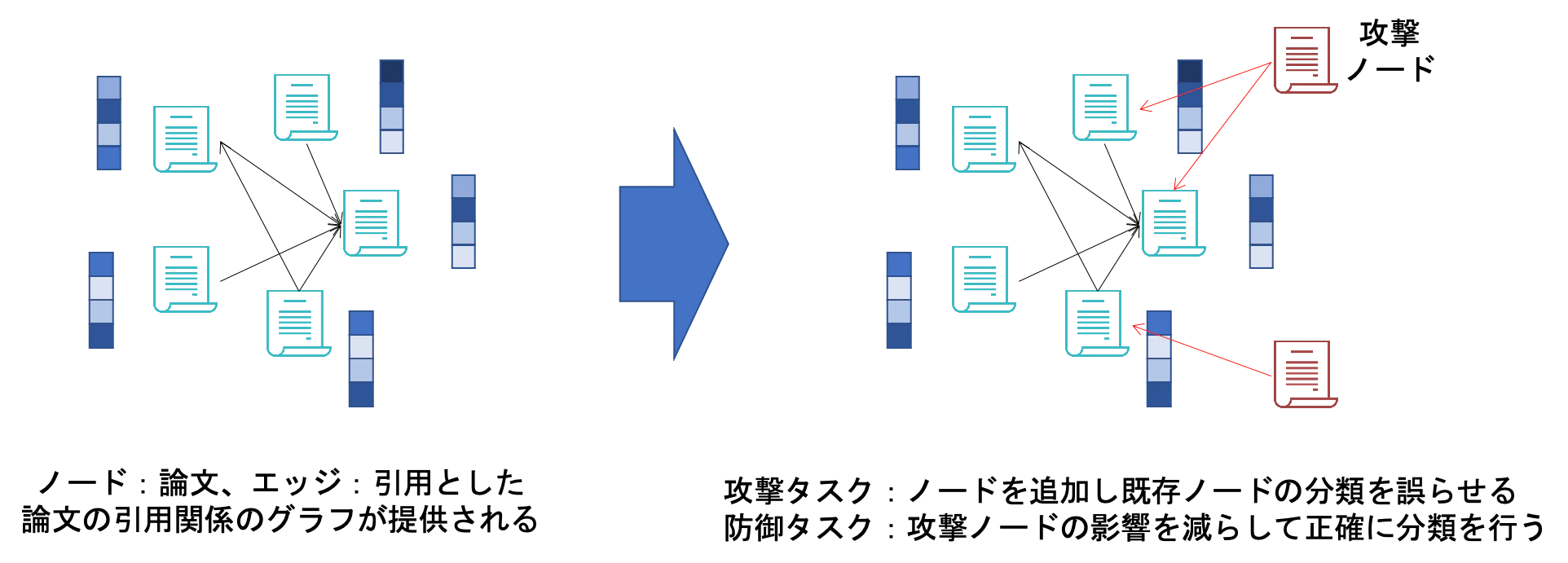
このトラックのタスクは、グラフ構造のデータにこのようなAdversarial Attackを行って推定精度を下げることと、攻撃を受けても精度が下がらない防御モデルを作ることです。
タスクでは、論文の引用関係のデータが提供されます。ノードが論文、エッジが引用関係を表し、各論文の内容を表す特徴量が各ノードにはあります。論文(ノード)が約60万あり、それに対して攻撃ノードを500個まで追加でき、攻撃ノードから100個までエッジを張ることができるという設定で攻撃と防御のモデルを考えます。
このコンペの面白いところは、各参加者の攻撃モデルと防御モデルを総当たりで戦わせて、攻撃モデルについては精度の低下度合い、防御モデルについては精度そのものが最終的なスコアになるという点です。運営が定期的に各参加者の攻撃モデルと防御モデルを総当たりで戦わせてリーダーボードを更新するので、他のチームがどうやって攻撃/防御しているのか推察しながら自分たちのモデルを考えていきます。詳しくはこのトラックの公式ページを見てください。
スケジュールとしては、こんな感じでした。
- 2020/4/20 データ公開&コンペ開始
- 2020/4/25 Phase1スタート(攻撃側のみを作って運営が用意した防御モデルを攻撃する)
- 2020/7/3 Phase2スタート(参加者同士のマッチング)
- 2020/7/26 コンペ終了
初期検討
攻撃/防御方法を考えるために既存論文のサーベイをしていたところ、いくつかオープンソースのAdversarial Attack/Defenseのライブラリがありました4ので、いきなり自前でモデルを作るより感触がわかっていいかなと思い、今回のデータに適用してみました。その結果、、、

という感じで、ノード数が多いグラフではかなり大容量のメモリが必要で全然動きませんでした。
これはライブラリでは任意のノードに対して攻撃できる設定になっているため、全ノードに対して微分の情報を持っておくために大量のメモリが必要になると推測しています。
攻撃モデル
グラフに対する攻撃は1. グラフ構造に対する攻撃、2.特徴量に対する攻撃の2つの攻撃があります。
グラフ構造に対する攻撃
グラフ構造に対する攻撃は文献5を調べてわかった知見を使い以下の方法を採用しました。
- 次数が低いノードは攻撃しやすい → 次数が10以下のテストノードを対象に攻撃
- 攻撃ノードを多く追加するほど攻撃しやすい → 最大の500ノードを追加
- 上限である100にするとすぐに攻撃とバレてしまう → 攻撃ノードから張るエッジ数は50-90の間でランダムに設定
ここで少し実装の説明です。こんな感じで隣接行列(adj)、特徴量(features)、教師ラベル(lables)を読み込んで、隣接行列を使って各ノードの次数を計算します。
import numpy as np
import scipy.sparse
adj = np.load("./kdd_cup_phase_two/adj_matrix_formal_stage.pkl", allow_pickle=True)
features = np.load("./kdd_cup_phase_two/feature_formal_stage.npy", allow_pickle=True)
labels = np.load("./kdd_cup_phase_two/train_labels_formal_stage.npy", allow_pickle=True)
# 次数が低いノードを攻撃する
deg = adj[test_indices].getnnz(axis=1)
deg_th = 10
law_deg_test_indices = test_indices_np[np.where(np.array(deg)<=deg_th)[0]]
extended_adj, extended_features = make_adv_data(target_indices=law_deg_test_indices)
make_adv_dataは自作関数で、攻撃対象のノードのインデックスを受け取って攻撃後の隣接行列と特徴量を出力します。
特徴量に対する攻撃
特徴量に対する攻撃では冒頭で紹介したパンダの例と同じ仕組みをグラフデータの特徴量に対して適用しました。このとき、計算量を削減するためにKDD2018の論文5で提案されているようにGraph Neural Networkのモデルの代理モデル(surrogate model)を作ります。代理モデルでは活性化関数を線形にすることで計算を簡単にします。今回は1層のGCNモデルを代理モデルとして使いました。1層のGCNモデルで活性化関数を線形にすると以下の行列の積を計算することになります。
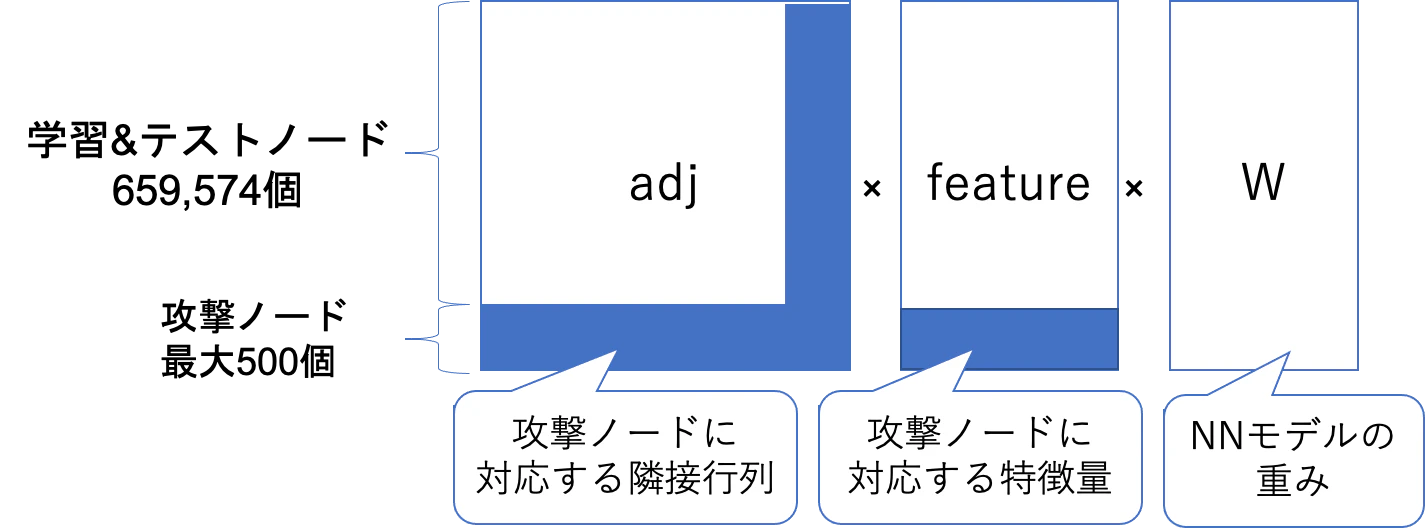
ここで、通常のNNの学習では重みWを微分によって求めていきますが、今回は隣接行列、攻撃ノード以外の特徴量、重みが固定で、攻撃ノードの特徴量だけが変数とみなして微分を行います。
# 攻撃ノード以外のノード特徴量は固定する
features_fix = torch.tensor(features, requires_grad=False).float()
# 攻撃ノードの特徴量は勾配計算する
features_adv = torch.tensor(extended_features, requires_grad=True).float()
features_adv = features_adv.detach().requires_grad_()
# 攻撃ノードとそれ以外の特徴量を連結する
features_merge = torch.cat([features_fix, features_adv])
# GCN_WとGCN_biasは事前に学習した代理モデルの重みとバイアス
y =torch.matmul(torch.sparse.mm(adj, features_merge), GCN_W) + GCN_bias
loss = nn.CrossEntropyLoss()
# テストデータのラベルは別途推定し、テストデータに対するlossを計算する
output = loss(y[test_indices], labels[test_indices])
# 勾配を計算する
output.backward()
防御モデル
防御側は主に前処理と、攻撃がなければ精度が高いGNNモデルを作ることをやりました。
前処理
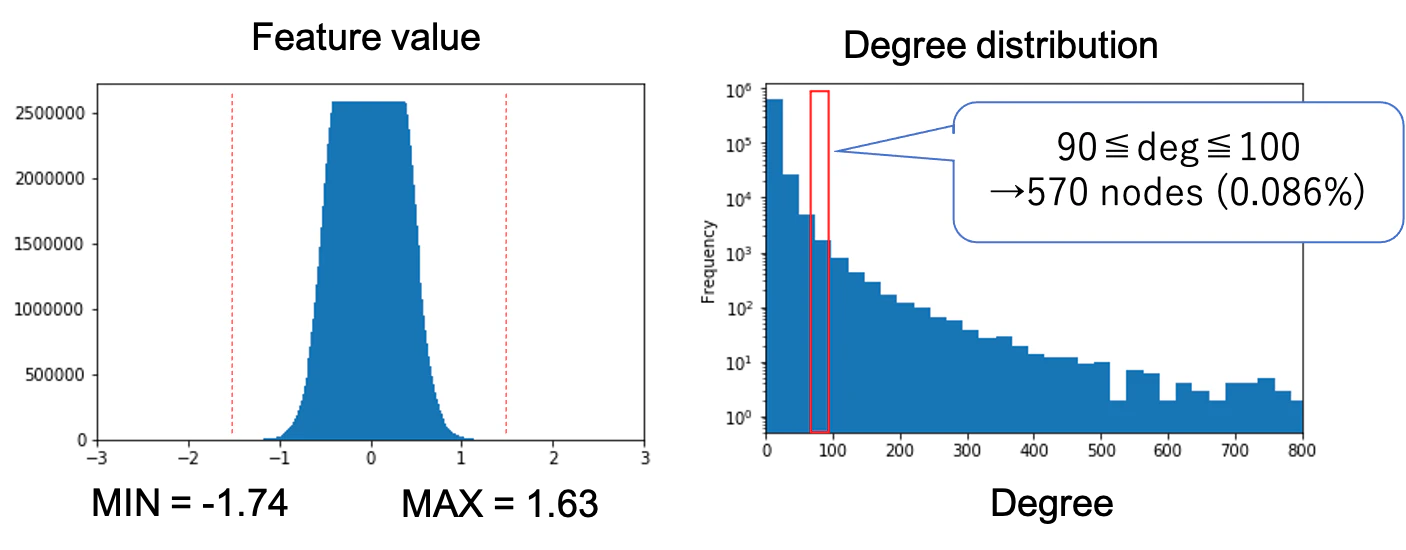
学習データの統計値を計算し、特徴量の値の範囲やノードの次数で閾値処理を行います。
特徴量はヒストグラムを作り大半の値が収まる[-1.74, 1.63]に入っていなければ除去、次数が[90, 100]のノードはもともと全体に占める割合がかなり少なく、攻撃の疑いがあるので除去というルールにしました。
GNNモデル
ノードのカテゴリを推定するモデルにはGINモデル6を採用しました。4層のGINモデルで、Adamで最適化を行い、ハイパーパラメーターの最適化にはOptunaを使いました。GNNの実装にはPytorch Geometricを使っています。
防御モデルの制約
ルール上、防御モデルは以下の要件を満たす必要がありました。
- Dockerでコンテナ化して提出
- 10秒以内に推定を行い結果を返却
- モデルファイルは1GB以内
最初、Dockerの実行環境があまり詳しく公開されておらず、本番環境で動作するDockerファイルを作る部分でも苦労しました。
最後に
GNNは近年の機械学習の国際会議で論文投稿数が急増しており注目されている技術だと思います。一方、画像などに比べて外部から攻撃しやすいという性質もあり、このトラックに参加することで様々な知見を得ることができました。
また、このタスクにはチームメンバー6人で挑戦したのですが、GNNモデルに詳しい人、基礎集計やしっかりやってデータの特徴を見つける人、Dockerでのコンテナ化まわりで実装に詳しい人など各自の得意なことをうまく組み合わせて取り組めたこともよかったです。
こちらにスライドも公開していますので参考に。
https://www2.slideshare.net/NTTDOCOMO-ServiceInnovation/kddcup2020-ml-track2
-
世界最高峰のデータ分析競技会「KDD CUP 2020」の3部門で入賞 https://www.nttdocomo.co.jp/binary/pdf/info/news\_release/topics\_200827\_00.pdf ↩
-
KDD CUP 2020入賞 https://www.nttdocomo.co.jp/binary/pdf/corporate/technology/rd/technical\_journal/bn/vol28_3/vol28\_3\_018jp.pdf ↩
-
Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. "Explaining and harnessing adversarial examples," ICLR 2015! ↩
-
Zügner, Daniel et al. “Adversarial Attacks on Neural Networks for Graph Data.” KDD (2018): 2847-2856. ↩ ↩2
-
Xu, Keyulu, et al. "How Powerful are Graph Neural Networks?." ICLR 2018 ↩