ドコモの落合です。この記事では,データマイニングの国際会議であるKDD2019のApplied Data Science Trackにオーラル発表で採録された我々の論文「Real-time On-Device Troubleshooting Recommendation for Smartphones」を紹介します。論文はKDDの論文紹介ページからダウンロードできます。

3行でまとめると
- 課題:スマートフォンが日常的に使われるようになり操作方法がわからないという状況に遭遇することがあり,ユーザーの利便性を損ねている。
- 提案:ユーザーが操作に困っている内容を,アプリの利用履歴や端末の操作履歴を元に推定し,操作のヒント(手順)を推薦するシステムを提案した。
- 結果:推定精度は89.7%,推論時間は10.4msと高精度かつ高速に推定できた。
KDD2019概要
KDDはデータマイニング分野のトップカンファレンスで今年は8月4日〜8日にアラスカのアンカレッジで開催されました。論文は技術的な新規性を重視するResearch Trackと実問題への応用を主とするApplied Data Science Trackという2つのトラックがあります。Research Trackは1179件の投稿から174件が採択されました(採択率:14.7%)。一方,Applied Data Science Trackは700件の投稿で,145件が採択されました(採択率:20.7%)。その中でも,オーラル発表は45件(採択率6.4%)と非常に狭き門でした。
背景
スマートフォンを日常的に使っていると操作方法がわからないという状況に遭遇することがあります。操作方法がわからないときに携帯電話事業者のコールセンターに電話して解決してもらうということが考えられますが,スマートフォンユーザが増えるにつれてコールセンターの稼働も逼迫してきます。この状況を解決するために,自動でユーザーに操作方法のヒント(手順)を提示できるシステムがあれば,ユーザーにとっても携帯電話事業者にとっても有益です。
ユーザーが困っている内容を検出するのに,ルールセットを作って検出することが考えられますが,スマートフォンの使い方は多様なのでルールでは対処できるパターンが限られます。そこで機械学習を使うことを考えます。
問題定義
スマートフォンの利用ログ$l$は以下のようなデータで,ユーザー$u$,タイムスタンプ$t$,class name $a$の3つ組$l=(u,t,a)$で表せます。Class nameはアプリの画面ごとの識別子です。
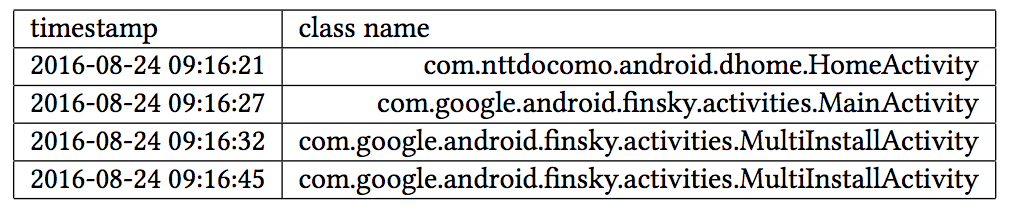
ある時間幅$T$の利用ログ$l$をスマートフォン利用ログ系列$x$とし,$x={l_1, l_2, \cdots, l_s}$とします。ユーザーの困りごとのカテゴリはWiFiやアカウント設定,メールなど大カテゴリ$c_1$と,メールの中の迷惑メール設定やメール送信方法などの小カテゴリ$c_2$の2段階のカテゴリとします。
すると,スマートフォンの利用ログを使った困りごとの推定は,入力$x$からカテゴリ$c_1$および$c_2$を推定する分類問題として定義できます。
アプローチ
スマートフォンの操作はリアルタイム性があるのでデバイス上で推論するという制約があり,機械学習のフレームワークとしてTensorFlow Liteを選びました。論文を書いていた2018年12月時点ではMLPしか使えなかったのでMLPをメインのモデルとしました。MLPモデルの入力にはClass nameに対してTF・IDFを計算し,上位k個のClass nameに絞って利用しています。
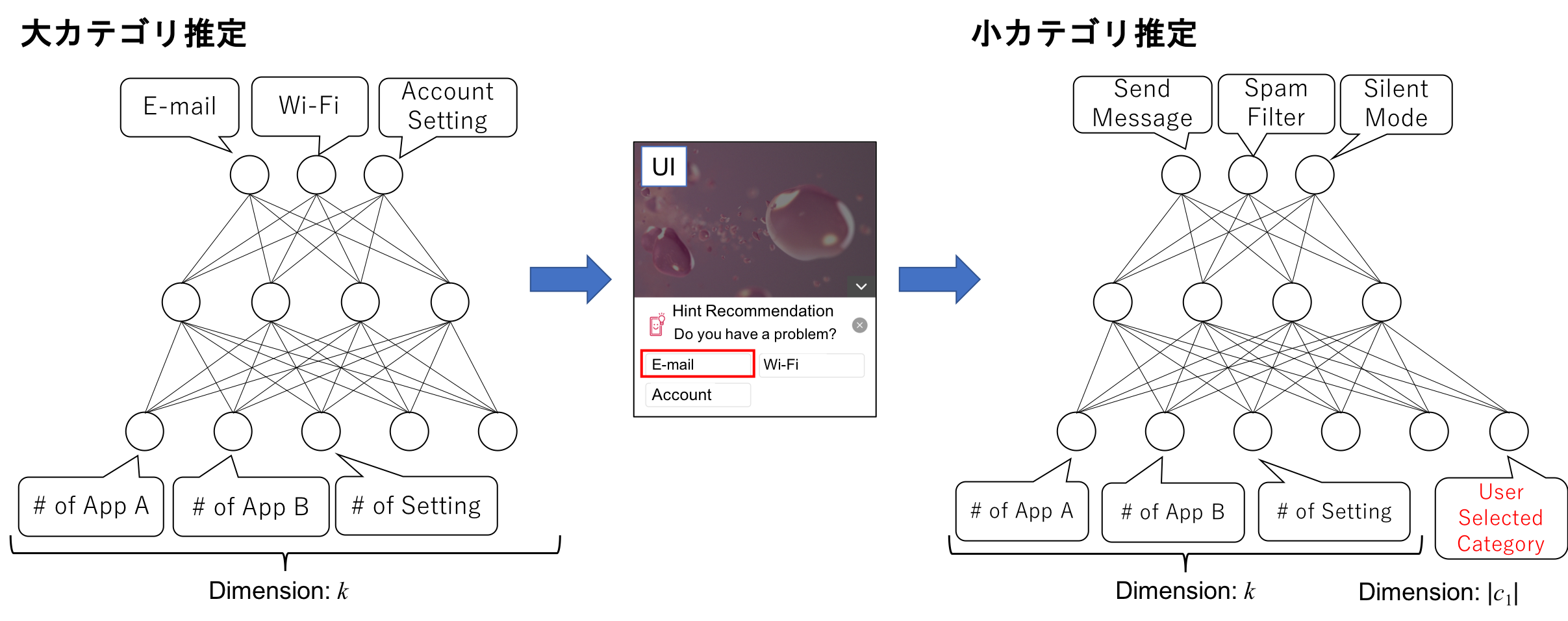
MLPモデルでは,最初に大カテゴリを推定します。その後,ユーザーに確率が高い大カテゴリを提示し,困っているカテゴリを選択してもらいます。そして,大カテゴリを推定するときと同じ特徴量に加え,ユーザー選択カテゴリを入力して小カテゴリを推定します。
評価
精度評価
オフライン評価では,MLPの次元数,層数を変えたり,Dropoutを使う/使わないなどのパターンで検証しました。その結果,大カテゴリの推定精度はacc@3で0.598,小カテゴリの推定精度は0.897でした。
このモデルをドコモの商用サービスで提供開始しオンライン評価を行いました。オンライン評価では,2016年からルールベースでヒント表示を行なっていたものと比較しました。実際のサービスではヒント表示後に「このヒントは役に立ちましたか?」というメッセージが表示され「はい」「いいえ」が選択できます。この「はい」を押した割合(問題解決率と呼んでいます)をルールベースと機械学習ベースの手法で比較したところ,ルールより機械学習ベースの手法が相対値で30%程度問題解決率を向上させることができました。
スマートフォン上での推論性能評価
今回の取り組みではスマートフォン上でTensorflowLiteで推論を行うため,バッテリ消費やCPU使用率などの端末のリソース消費についても評価を行いました。10秒ごとにバックグラウンドで推論処理を実行したと仮定してリソース消費量を実機(Nexus 5X)で計測しました。その結果が以下の表です。CPUやメモリの使用率が低いことがこの表からわかると思います。バッテリ消費量についてはこのままではわかりにくいので,どれくらいバッテリが持つか試算したところ約34時間は通常通り使用できるという結果でした。詳細は論文を読んでください。
| バッテリ消費量(mAh/回) | CPU使用率 | メモリ使用率 |
|---|---|---|
| 0.02205 | 5.63 | 1.04 |
このプロジェクトから得られた知見
KDDのApplied Data Science Trackでは,実問題への適用を重視しており,論文募集でもLESSONS LEARNED(得られた知見)を書くように推奨しています。このへんが他の機械学習系の国際会議とKDDが違うところかなと思います。
今回の案件から得られた知見は大きく2つあります。1つは教師データを効率的に作るために異種データを組み合わせることが有効であること,もう1つは機械学習とUIの組み合わせが重要であることです。ここでは2つめの話を詳しく書きたいと思います。
論文にも書いていますが,最初は2段階で推定せずにいきなり小カテゴリを推定するという問題設定で検証をしていました。しかしながら,精度が全然出なく(小カテゴリを直接推定したときの精度はacc@3で30%くらいでした),その結果考えたのが「ユーザーに聞けばいいのではないか」という案でした。そのため,アプローチのところの図のように,大カテゴリを推定した時点でユーザーに推定結果を提示し,ユーザーの選択結果も加味して2段階目で小カテゴリを推定するというモデルになりました。この経験の教訓は,機械学習だけで問題を解こうとすると難しい問題でも,UIをうまく組み合わせることで問題の難しさを緩和できることがあるということです。技術者としてはつい全部を技術で解決したくなりますが,技術を使うことが目的ではなく問題を解決するために技術があるということを忘れないようにしたいと感じました。
最後に
Applied Data Science Trackのオーラル発表で日本からの発表は、私が調べた限りでは私たちの研究だけだったようです(違ったらすみません)。KDDはデータサイエンスに携わっている人であれば一度は行ってみたい憧れの学会で,その学会で発表できたことは大変光栄に思います。
昨年もアドベントカレンダーを書いたのですが(去年の記事はこちら)、その記事の中で
人工知能分野はビジネスと研究の距離が近いので,実務の課題を元に研究してサービスを世に出し,そこで得られたデータで研究をさらに進めるという循環を回していきたいと思います。
と書いていました。KDD2019の論文はまさにその通りになりました。ドコモでデータ分析を業務で行なっているということはあまり認知されていないと思います。ドコモのデータ分析に関する認知度向上のため学会発表などの対外活動を通じて認知度を向上させたいと考えており,これからもKDDなどのトップカンファレンスに挑戦していきたいと思います。