目的
Triton Inference Serverにおける推論リクエストの流れと、Dynamic Batching・モデルインスタンス数(instance count)とレイテンシ/スループットの関係について整理をします。
Triton Inference Serverのリクエストの流れ
Triton Inference Serverにおける推論リクエストの流れは、概念的には以下のようになります。
- クライアントから推論リクエストを受信
- Dynamic Batchingを行う場合はリクエストをバッチとしてためる(行わない場合はそのまま次へ)
- モデルインスタンスごとの Scheduler queueにバッチ(または単一リクエスト)が渡される
- 推論実行
- レスポンス返却
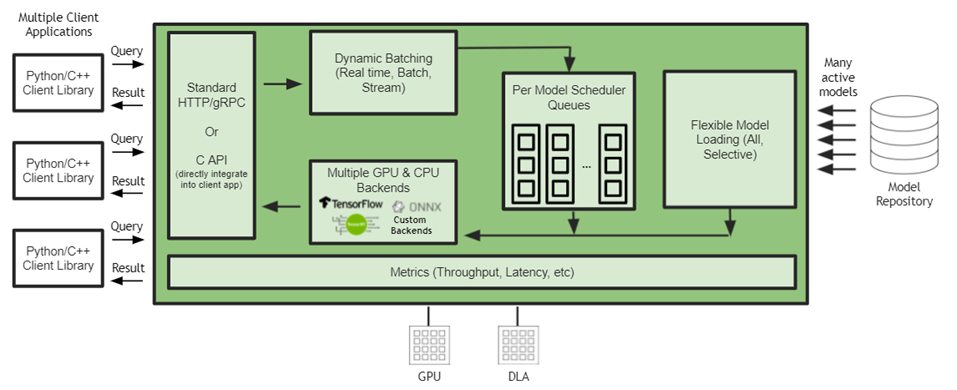
Triton Inference Serverにおける性能調整の主なポイント
Triton Inference Serverでは、主に以下の2点の設定によってスループットやレイテンシが大きく変化します。
- バッチ処理の有無およびバッチサイズ
- モデルインスタンス数(instance count)
モデルの種類やシステム要件によって最適な設定は大きく異なりますが、「バッチングを使うかどうか」が最も大きな分岐点になります。
レイテンシを優先する場合
レイテンシを最優先したい場合、Dynamic Batchingを有効化せず、逐次的に推論リクエストを処理するのが有効です。
設定例としては以下のようになります。
max_batch_size: 0
instance_group {
kind: KIND_GPU
count: 1 ← 並列度を増やしたい場合はこの値を増やす
}
この場合の特徴は以下の通りです。
- queue にリクエストを溜めない
- Dynamic Batchingによるqueueing delay(待ち時間)がほぼ発生しない
- 各リクエストが到着次第、すぐに実行される
これにより推論リクエストを待ち時間なくすぐさま処理するため、スループットではなくレイテンシを優先したい要件には有効です。
また、instance countを増やすことでモデルインスタンス数を増やし、同時に処理できるリクエスト数(並列度)を高めることが可能です。
ただしinstance countを増やしすぎるとGPUメモリ使用量の増加やリソース競合により、逆にパフォーマンス悪化を引き起こす可能性があります。その点は注意が必要です。
スループットを優先する場合
スループットを優先したい場合は、Dynamic Batchingを有効化して複数リクエストをまとめて処理するのが有効です。
設定例として以下になります。
max_batch_size: 16
dynamic_batching {
// 優先バッチサイズ
preferred_batch_size: [4, 8, 16]
// 最大キュー遅延(マイクロ秒)
max_queue_delay_microseconds: 100
}
instance_group {
kind: KIND_GPU
count: 2 ← ここでも並列度を増やしたい場合はこの値を増やす
}
この設定では、
- 可能な限りbatch sizeを4・8・16のバッチを作成する
- 最大でも 100µs以上は待たない
といった制御が行われます。
Dynamic Batchingを有効化すると、queueに溜まった複数のリクエストをまとめてGPUに渡すことができ、計算効率が大きく向上し、スループットが高くなります。
レイテンシの悪化をある程度許容しつつ、スループットを上げたい場合はDynamic Batchingを有効にするのが良さそうです。
まとめ
今回はTriton Inmference Serverのチューニングポイントをまとめてみました。
モデルごとにチューニングすべき点やレイテンシ・スループット要件が異なると思いますが、参考にしていただければ幸いです。
参考文献
- https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/user_guide/optimization.html
- https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/user_guide/batcher.html?utm_source=chatgpt.com
- https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/tutorials/Conceptual_Guide/Part_2-improving_resource_utilization/README.html?utm_source=chatgpt.com