はじめに
最近のKaggleのテーブルデータのコンペでLightautoML(LAMA)というAutoMLが使われているので、試してみました。
LightAutoML(LAMA)
LAMAは表形式のデータを扱うタスクに使えるオープンソースのAutoMLのライブラリです。従来のAutoMLがニューラルネットワークのような計算量の多い手法を使っていたのに対して、少数のGBDTと線形モデルに集中することで、処理速度と性能のバランスを保ち効率を向上させています。
Colabでの実行
有名なTitanicのデータを使ってLightAutoMLの実力を確認します。
それではチュートリアルに沿って実行していきましょう!
手順は以下の通りです。
(1) ライブラリのインストール
!pip install -U lightautoml
(2) ライブラリのインポート
# 一般的なPythonのライブラリ
import os
# データ分析用のライブラリ
import numpy as np
import pandas as pd
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
import torch
# LightAutoMLのライブラリ
from lightautoml.automl.presets.tabular_presets import TabularAutoML, TabularUtilizedAutoML
from lightautoml.tasks import Task
from lightautoml.report.report_deco import ReportDeco, ReportDecoUtilized
(3) 定数の設定
Titanicのデータ(train.csv, test.csv, gender_submission.csv)はGoogle Drive直下に"data"というフォルダを作って入れてください。
N_THREADS = 2
N_FOLDS = 5
RANDOM_STATE = 42
TEST_SIZE = 0.2
TIMEOUT = 300
TARGET_NAME = 'Survived'
DATASET_DIR = '/content/drive/MyDrive/data/'
DATASET_NAME = 'train.csv'
DATASET_FULLNAME = os.path.join(DATASET_DIR, DATASET_NAME)
(4) Google Driveのマウント
from google.colab import drive
drive.mount("/content/drive")
os.listdir(DATASET_DIR)
(5) データの確認
data = pd.read_csv(DATASET_DIR + DATASET_NAME)
data.head()

(6) validationデータの分割
train_data, val_data = train_test_split(
data,
test_size=TEST_SIZE,
stratify=data[TARGET_NAME],
random_state=RANDOM_STATE
)
print(f'Data is splitted. Parts sizes: train_data = {train_data.shape}, val_data = {val_data.shape}')
train_data.head()
(7) LightAutoMLの設定
task = Task('binary')
roles = {
'target': TARGET_NAME
}
automl = TabularAutoML(
task = task,
timeout = TIMEOUT,
cpu_limit = N_THREADS,
reader_params = {'n_jobs': N_THREADS, 'cv': N_FOLDS, 'random_state': RANDOM_STATE},
)
(8) モデルの学習と評価
out_of_fold_predictions = automl.fit_predict(train_data, roles = roles, verbose = 1)
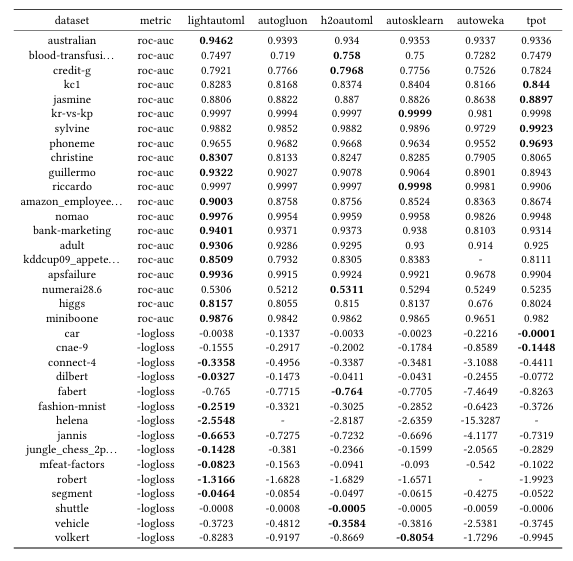
評価結果を見ると良さそうですね!
ハイパーパラメータ調整したLightGBMの寄与が低いのはちょっと意外です。
val_predictions = automl.predict(val_data)
print(f'OOF score: {roc_auc_score(train_data[TARGET_NAME].values, out_of_fold_predictions.data[:, 0])}')
print(f'HOLDOUT score: {roc_auc_score(val_data[TARGET_NAME].values, val_predictions.data[:, 0])}')
print(automl.create_model_str_desc())

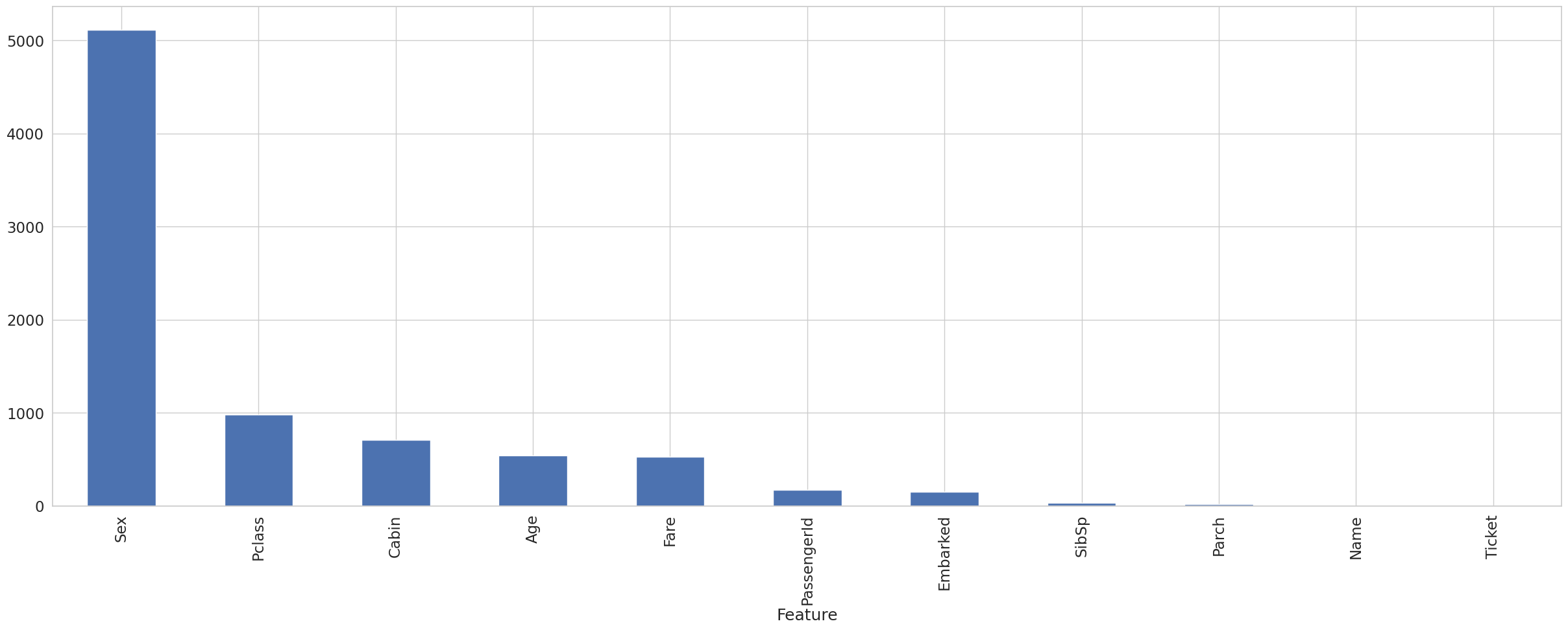
(9) 特徴量重要度の計算
RD = ReportDeco()
automl_rd = RD(
TabularAutoML(
task = task,
timeout = TIMEOUT,
cpu_limit = N_THREADS,
reader_params = {'n_jobs': N_THREADS, 'cv': N_FOLDS, 'random_state': RANDOM_STATE}
)
)
out_of_fold_predictions = automl_rd.fit_predict(train_data, roles = roles, verbose = 1)
fast_fi = automl_rd.model.get_feature_scores('fast')
fast_fi.set_index('Feature')['Importance'].plot.bar(figsize = (30, 10), grid = True)
(10) testデータとsubmit用ファイルの読み込み
test_data = pd.read_csv(DATASET_DIR + "test.csv")
submit = pd.read_csv(DATASET_DIR + "gender_submission.csv")
(11) 推論とsubmitファイルの作成
probabilities = automl.predict(test_data).data[:,0]
predictions = (probabilities > 0.5).astype(int)
submit['Survived'] = predictions
submit.to_csv(DATASET_DIR + "submit.csv", index=None)
提出結果は Score: 0.76076
残念ながらサンプルファイル(Score: 0.76555)以下😥
TitanicのようなきちんとEDAと前処理をしないといけないようなデータに対してはまだまだAutoMLでは力不足でした。
モデルに頼りきらず、データをよく見て自分の頭で考え適切な特徴量の選定やエンジニアリングを行うことが必要です。