流れ
- 開発環境について
- 開発環境の構築
- Pythonの復習
- Titanic問題(Kaggle)
開発環境について
Cloud9
- アプリケーションの開発やデータベース操作などをクラウド環境で利用できるサービス(クラウドIDE)
- ブラウザ上で動くので、PC(OS)に依存しないで利用可能
- AWSが買収(2016年)
Jupyter Notebook
- ノートブックと呼ばれる形式で作成したプログラムを実行し、実行結果を記録しながら、データの分析作業を進めるためのツール
- 実行結果やメモを簡単に保存できるため、チーム開発やスクールでも導入されている
- 旧IPython Notobook
開発環境の構築
Cloud9でWorkspaceの作成
- ログイン https://c9.io/login
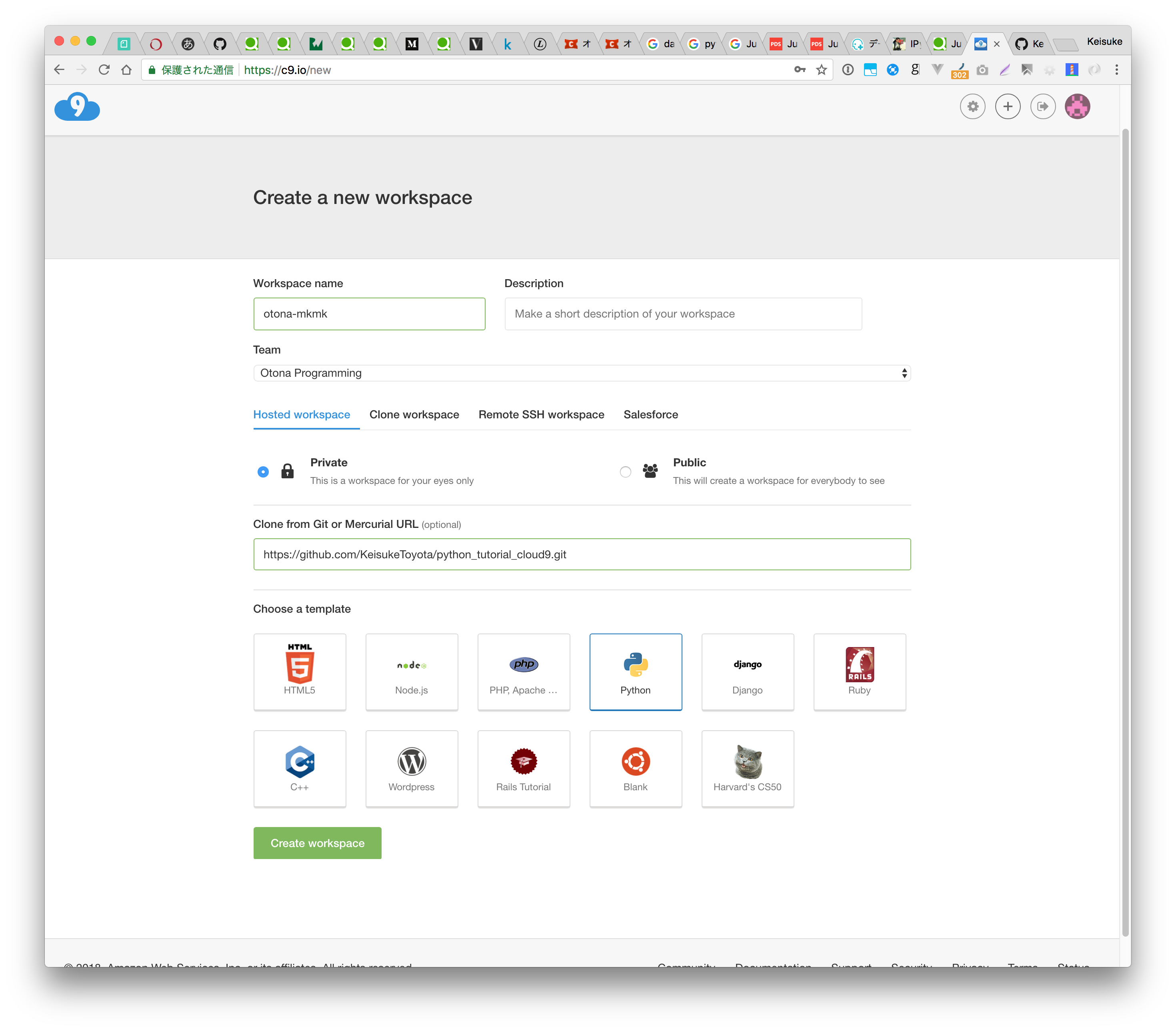
- Create a new workspace
- Workspace name : otona-mkmk
- Team : Otona Programming
- Git : https://github.com/KeisukeToyota/python_tutorial_cloud9.git
- template : Python
Jupyter Notebookの起動
- ライブラリのインストール
$ sh init.sh # 結構時間かかります
- パスの設定
$ source ~/.bashrc
- Jupyter Notebookの起動
$ jupyter notebook
# https://<workspace name>-<user name>.c9users.io:8080/
※Cloud9内のブラウザで起動しないのでブラウザタブで開いてください

Notobookを作成
- New > Python[Root]


Pythonの復習
よく使う
# 変数宣言
a = 1
a = 'hoge'
# プリント文
print('Hello world')
# 型出力
type(10) # <class 'int'>
# ライブラリのインポート
import math
from math import e # ローカルスコープにコピー
from math import e as napiers_constant # 別名つける
"""
複数行
コメント
"""
数値
num = 1
num = 3.14
num = 1 + 1j #jは虚数
# 演算
num = 1 + 1 # 2
num = 1 - 1 # 0
num = 1 * 2 # 2
num = 5 / 2 # 2.5
num = 5 // 2 # 2 (切り捨て)
num = 5 % 2 # 1 (剰余)
num = 2 ** 3 # 8 (累乗)
i += 1 #インクリメント
i -= 1 #デクリメント
文字列
str1 = 'abc'
str2 = "def"
str3 = '''ghi
jkl
mno'''
# 結合
join1 = 'hoge' + 'moge' # 'hogemoge'
join2 = ','.join(['aaa', 'bbb', 'ccc']) # 'aaa,bbb,ccc'
# 分割
record1 = 'aaa bbb ccc'.split() # ['aaa', 'bbb', 'ccc'] デフォルトでは空白で分割
record2 = 'aaa,bbb,ccc'.split(',') # ['aaa', 'bbb', 'ccc']
# 長さ(文字数)
length = len('Supercalifragilisticexpialidocious') # 34
# 切り出し
# [start:stop]の形で指定して切り出す
substr1 = '0123456789'[:3] # '012' 0~stop-1を切り出す
substr2 = '0123456789'[3:6] # '345' start~stop-1を切り出す
substr3 = '0123456789'[6:] # '6789' start~末尾を切り出す
# 検索
result = 'abcd'.find('cd') # 見つかった場合はその位置、見つからなかった場合は-1が返る
論理型(ブーリアン)
beef = True
chicken = False
print(not chicken)
# chickenではない=True
print(beef and chicken)
# beefかつchicken=False
print(beef or chicken)
# beefまたはchicken=True
リストとタプル
# リスト:配列。どんな型のものでも含むことができる。
list1 = []
list2 = [0, 1, 2]
# タプル:配列。要素の追加や削除ができない。
tuple1 = ()
tuple2 = (1,)
tuple3 = (0, '1', 2, [3], -4)
# 要素の代入
list2[0] = 100
tuple4[0] = 1 # エラー
# 要素数
len(list3) # 5
len(tuple4) # 5
array = [1, 2, 3, 4]
# 任意の要素を取り出す
first = array.pop(0) # first == 1, array == [2, 3, 4]
# 任意の要素を追加する
array.insert(0, 5) # array == [5, 2, 3]
# 末尾を取り出す
last = array.pop() # last == 3, array = [5, 2]
# 末尾に追加
array.append(9) # array == [5, 2, 9]
# 末尾にリストを追加
array.extend([0, 1]) # array == [5, 2, 9, 0, 1]
ディクショナリ
# ディクショナリ:連想配列。キーには数値、文字列、タプルが指定できる。
dic = {} # 空ディクショナリ
dic = {'a': 1, 'b': 2} # key:value, ... の形式で初期化
# 要素の参照
dic['a'] # 1
# 要素の代入
dic['a'] = 100
# キーの取得
dic.keys() # ['a', 'c', 'b'] (辞書式順や追加順に並ぶとは限らない)
# 値の取得
dic.values()
# キーの存在確認
'a' in dic # True
# ハッシュのキーの削除
del dic['a']
制御文
# if文
if a==0: # 条件
print 'true'
else:
print 'false'
# while文
i = 0
while i < 5:
# 処理
i += 1
# for文
for i in [0, 1, 2, 3, 4]:
# inの右に渡されたリスト等の要素がiに順次代入されて処理される
print i
関数
def funcTest(object):
print("Hello world " + object)
funcTest("Python!!")
# "Hello world Python!!"
データ分析 with Python
- math : 数学にまつわる変数と関数
- pandas : 表データを効率的に扱う
- numpy : 行列計算等の学術計算を行う
- scikit-learn : 機械学習用のライブラリ
- matplotlib : グラフの描画
Titanic問題(Kaggle)
Kaggleとは
- 世界中の統計家やデータ分析家がその最適モデルを競い合う、予測モデリング及び分析手法関連プラットフォーム(Wikipedia)
- コードが説明付きで公開されており、データ分析の勉強に役立つ
Titanic問題
- Kaggleのチュートリアル
Titanic: Machine Learning from Disaster | Kaggle - タイタニック号の乗船客リストから沈没を生き延びたかどうかを予測
- 891人分の訓練データから418人の生存予測を行う
流れ
- データセットの確認
- データセットの事前処理
- 予測モデル
データセットの確認
-
Titanic問題のページからcsvをダウンロード(要登録。今回はレポジトリに含まれています)
- test.csv : テスト用データセット
- train.csv : トレーニング用データセット
train.csvの内容
import pandas as pd
import numpy as np
train = pd.read_csv("csv/train.csv")
train.head() # データフレームの先頭から返す(デフォルト5件)
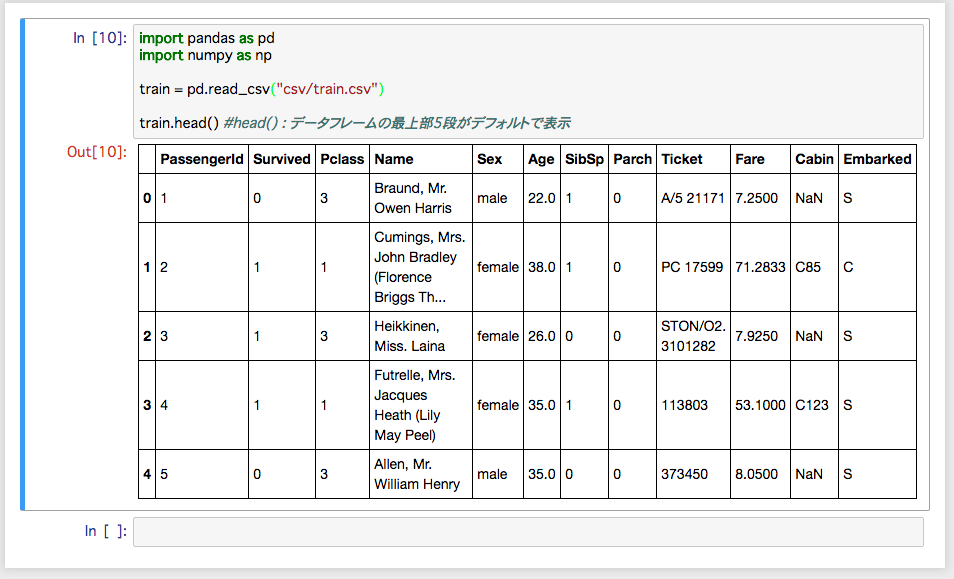
- 各カラムの内容
- PassengerId – 乗客識別ユニークID
- Survived – 生存フラグ(0=死亡、1=生存)
- Pclass – チケットクラス(1=上層クラス, 2=中級クラス, 3=下層クラス)
- Name – 乗客の名前
- Sex – 性別(male=男性、female=女性)
- Age – 年齢
- SibSp – タイタニックに同乗している兄弟/配偶者の数
- parch – タイタニックに同乗している親/子供の数
- ticket – チケット番号
- fare – 料金
- cabin – 客室番号
- Embarked – 出港地(C=Cherbourg, Q=Queenstown, S=Southampton)
test.csvの内容
test = pd.read_csv("csv/test.csv")
test.head()
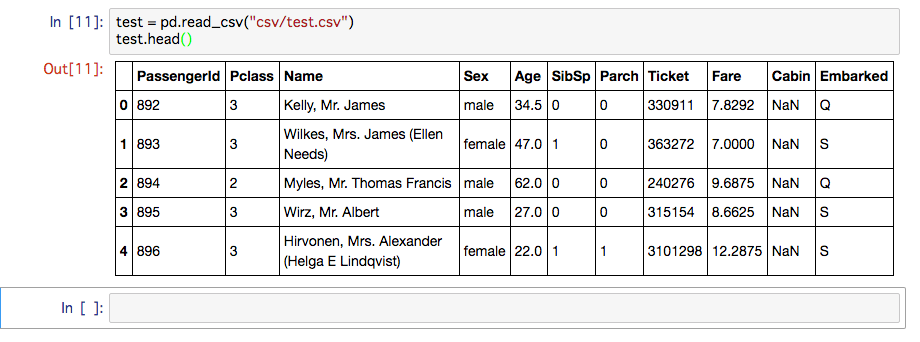
- train.csvの情報と生存データからtest.csvの生存データ(Survived)を予測する
サイズ
print(train.shape)# 行数、列数
print(test.shape)
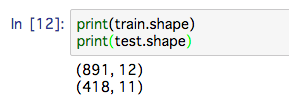
- 891名と418名の情報
統計情報
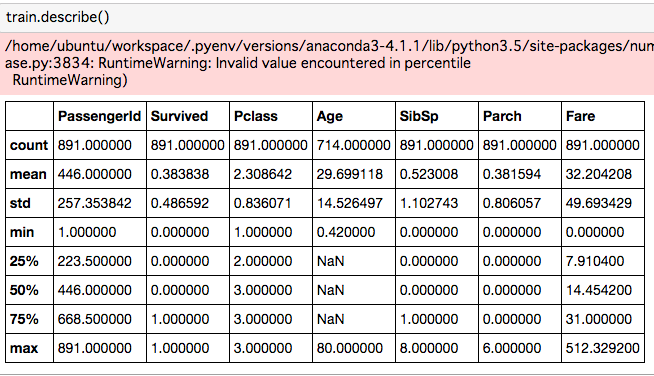
train.describe() # 平均や標準偏差、最大値、最小値、最頻値などの要約統計量を取得
- 欠損データがあるためエラーが出る
相関係数
train.corr() # 各列間の相関係数を算出
# -1.0から-0.7 強い負の相関
# -0.7から-0.4 負の相関
# -0.4から-0.2 弱い負の相関
# -0.2から+0.2 ほとんど相関がない
# +0.2から+0.4 弱い正の相関
# +0.4から+0.7 正の相関
# +0.7から+1.0 強い正の相関

import matplotlib.pyplot as plt
%matplotlib inline
plt.switch_backend('agg')
plt.matshow(train.corr()) # ビジュアライズ

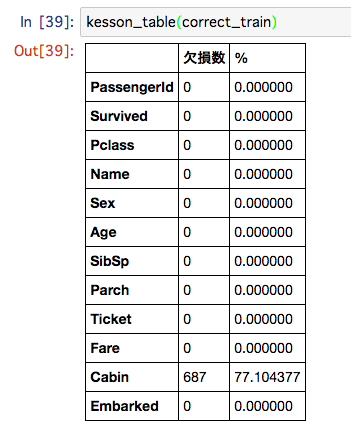
データセットの欠損の確認
def kesson_table(df):
# isnull() : NaNがあるかどうか, sum() : 加算
null_val = df.isnull().sum()
# len() : 長さ,
percent = 100 * null_val/len(df)
# concat() : データフレームの連結, axis=1で横方向連結
kesson_table = pd.concat([null_val, percent], axis=1)
kesson_table_ren_columns = kesson_table.rename(
columns = {0 : '欠損数', 1 : '%'})
return kesson_table_ren_columns
kesson_table(train)

データの事前処理
- 文字データを数値に変換
- 欠損値の補正
def correct_data(titanic_data):
# fillna() : 欠損値を穴埋め, median() : 中央値
# Ageの欠損データを中央値で穴埋めする
titanic_data.Age = titanic_data.Age.fillna(titanic_data.Age.median())
# replace() : 置換
# Sexのデータを数値に変換
titanic_data.Sex = titanic_data.Sex.replace(['male', 'female'], [0, 1])
# Embarkedの欠損データをSで埋め、数値に変換
titanic_data.Embarked = titanic_data.Embarked.fillna("S")
titanic_data.Embarked = titanic_data.Embarked.replace(['C', 'S', 'Q'], [0, 1, 2])
# Fareの欠損データを中央値で穴埋め
titanic_data.Fare = titanic_data.Fare.fillna(titanic_data.Fare.median())
return titanic_data
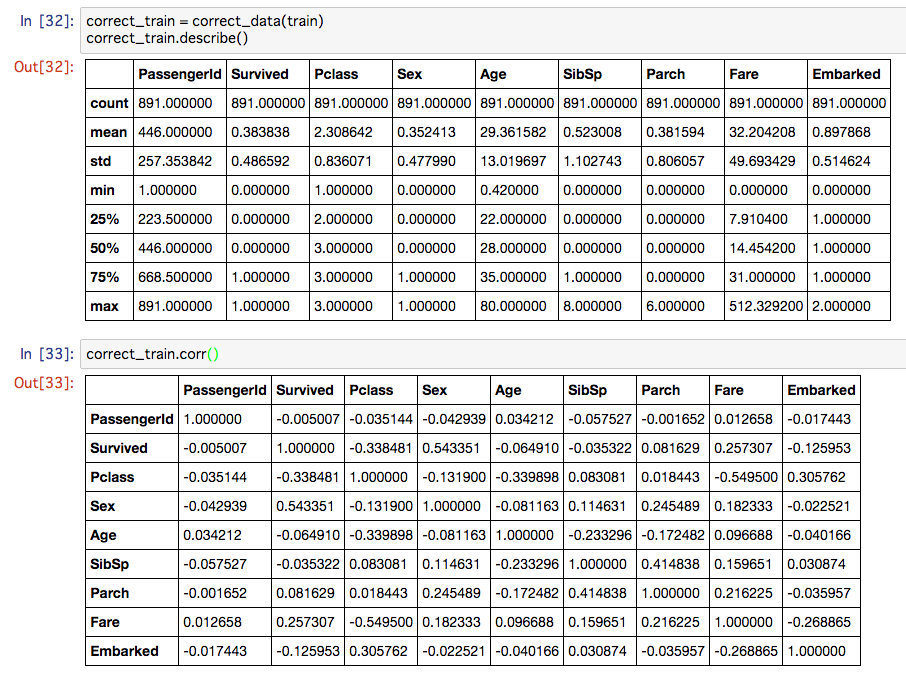
correct_train = correct_data(train)
correct_train.describe()
correct_train.corr()
kesson_table(correct_train)
予測モデル
- 今回は決定木(Decision tree)をつかいます
from sklearn import tree
# 「train」の目的変数と説明変数の値を取得
target = correct_train["Survived"].values
features_one = correct_train[["Pclass", "Sex", "Age", "Fare"]].values
# 決定木の作成
my_tree_one = tree.DecisionTreeClassifier()
my_tree_one = my_tree_one.fit(features_one, target)
# データの事前処理
test_correct = correct_data(test)
# 「test」の説明変数の値を取得
test_features = test_correct[["Pclass", "Sex", "Age", "Fare"]].values
# 「test」の説明変数を使って「my_tree_one」のモデルで予測
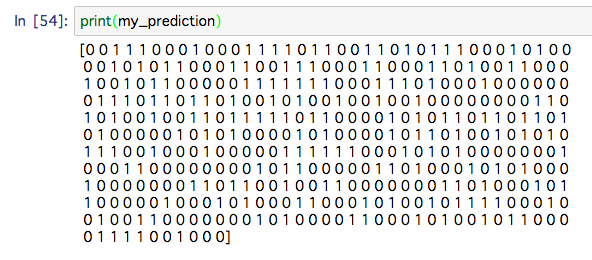
my_prediction = my_tree_one.predict(test_features)
# 結界の表示
print(my_prediction)
フォーマットを整えてCSVに出力
import numpy as np
# PassengerIdを取得
PassengerId = np.array(test["PassengerId"]).astype(int)
# my_prediction(予測データ)とPassengerIdをデータフレームへ落とし込む
my_solution = pd.DataFrame(my_prediction, PassengerId, columns = ["Survived"])
# my_tree_one.csvとして書き出し
my_solution.to_csv("my_tree_one.csv", index_label = ["PassengerId"])
Cloud9からダウンロードしてKaggleへSubmit
- Titanic: Machine Learning from Disaster | Kaggle のSubmit Predictionsから投稿
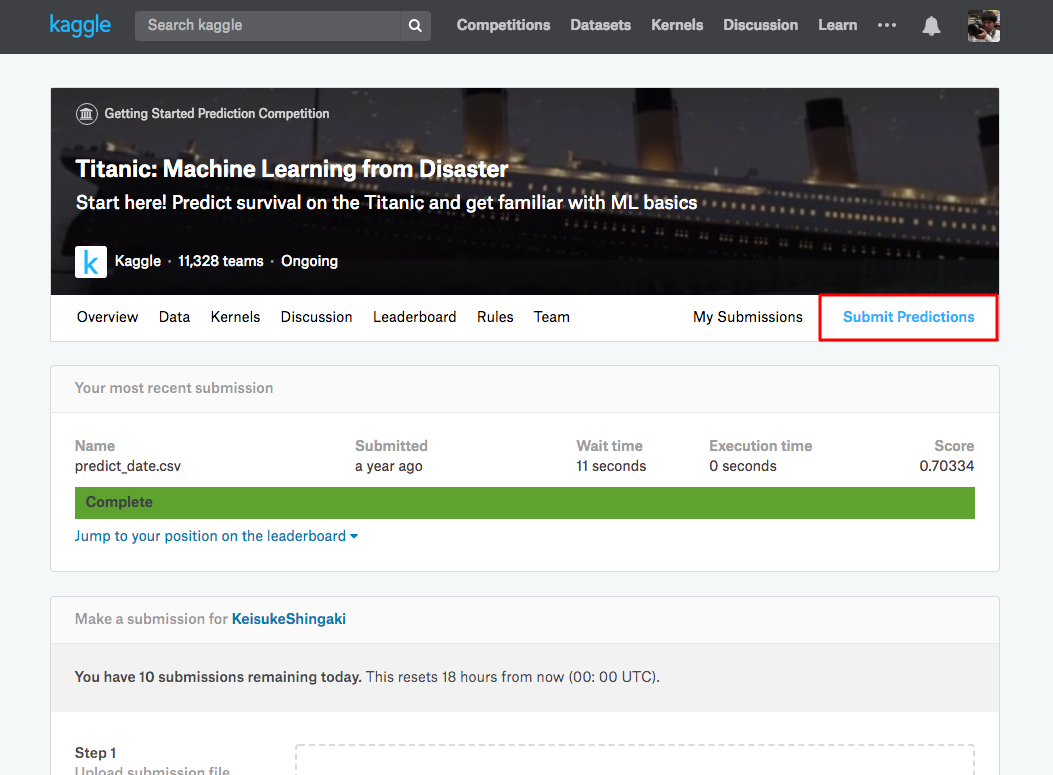


- 結果が表示される
- 他のモデルでもやってみましょう
参考
第2回オトナのPython入門@未来会議室 · オトナのプログラミング勉強会
Python基礎文法最速マスター - LazyLife@Diary
Pythonの基本文法まとめてやんよ!!! | ときどきWEB
KaggleチュートリアルTitanicで上位3%以内に入るには。(0.82297) - IMACEL Academy -人工知能・画像解析の技術応用に向けて-|LPixel(エルピクセル)
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?