はじめに
こんにちは、KCCS デジタルプラットフォーム部のヤンです。
私たちの部門ではDatabricksを活用したデータ分析基盤の構築や技術検証、Databricksの構築における課題の解決を行なっています。
前回の記事AutoML Regression編では、一般的な回帰モデルに Lag(時差)変数や移動平均 などの時間的特徴量を手動で組み込み、需要予測を行いました。しかし、手動での特徴量生成には限界があり、時間の複雑なパターンを完全に捉えきれない部分がありました。
今回は、前回のアーキテクチャを継承しつつ、時間の文脈を自律的に理解して学習する Databricks AutoMLのForecasting(時系列予測)モード を活用した関西エリアの電力需要予測事例と、その過程で得られたインサイトを共有します。
プロジェクトの概要および技術スタック
本プロジェクトの実験環境は前回と同様であり、Databricks環境上でMLモデルのみを時系列最適化モードに拡張して実施しました。
今回の実験は、気象データなどの外部変数を除外した単変量(Univariate)モデリングを基準としています。
📋 プロジェクト概要
- 目的: 関西電力の需給実績データを活用した時間別需要予測システムの構築
- 核となる課題: 時系列データ特有の不規則性を前処理(クレンジング)し、外部変数(気象データなど)が存在しない条件におけるAutoML Forecastの基本性能と限界を検証すること
🛠 技術スタックと全体アーキテクチャ
- Platform: Databricks (Runtime 16.4 LTS / Unity Catalog)
- Core Logic: PySpark (Spark 3.5)
- AI/ML: Databricks AutoML, MLflow
- Architecture: Medallion Architecture (Bronze → Silver → Gold)
💡 データの出典と取り扱いについて
本記事で参照している需給実績データは、経済産業省資源エネルギー庁の「系統情報の公表の考え方」に基づき、関西電力送配電株式会社が公式に公表している情報です。 ご利用にあたって等は、公式サイトに記載されている「サイトのご利用にあたって」および「取り扱い・免責事項」などの注意事項を必ずご確認ください。
⚠️ 免責事項
本記事は技術検証を目的としており、予測結果の正確性を保証するものではありません。
なぜ「回帰」ではなく「時系列(Forecasting)」専用モードなのか?
前回の回帰分析で、私たちが手動でLag変数や時間特徴量を投入した理由を覚えていますか? それは電力データに以下のような特性があるためです。
-
季節性 (Seasonality): 出勤時間の急増、昼休みの需要減、週末のパターンなど繰り返されるリズム。
-
自己相関 (Autocorrelation): 「直近の需要が現在の需要に強く影響する」というデータの慣性。
一般的な回帰モデルがエンジニアによる「加工された特徴量」に依存するのに対し、Forecastingモード はデータの時系列構造を直接把握します。
以前の回帰モデルでは、エンジニアが Lag特徴量、移動平均、時間特徴量(hour/dayなど) を一から手動で作成し、モデルにインプットしていました。しかし、今回の Forecastingモード では、これらの複雑な工程をアルゴリズムが自動で処理します。これは単なる自動化ではなく、データの中に隠れた多層的な周期性をAutoMLが自ら発見し、最適化することを意味します。
成功のための前処理 (Engineering)
AutoMLが真価を発揮するためには、「連続性」が確保された高品質なデータが必要です。
- 2重ソート (Double Sorting):時間軸に沿ってデータを厳密に整列させ、過去から未来への因果関係を明確にします。
- 欠損値補完 (Interpolation): データの欠落(Gap)を補完し、AIが24時間/7日のリズムを完璧に把握できるようにします。
import pandas as pd
# Pandasを活用した時系列データのクレンジング
# データ量がメモリに収まるサイズ(数万件程度)であるため、柔軟な時系列処理が可能なPandasに変換
pdf = df_silver.toPandas()
pdf['timestamp'] = pd.to_datetime(pdf['timestamp'])
pdf = pdf.set_index('timestamp')
# 1時間単位の再サンプリングと線形補完
pdf_gold = pdf.resample('1H').mean().interpolate(method='linear')
pdf_gold = pdf_gold.reset_index()
📚 参考文献
AutoMLの実行と結果分析 (Horizon: 24h)
from databricks import automl
# AutoML Forecastingの呼び出し
forecast_summary = automl.forecast(
dataset=pdf_gold,
target_col="demand",
time_col="timestamp",
horizon=24, # 未来24時間の予測(短期シナリオ)
frequency="h", # 時間単位
country_code="JP", # 日本の祝日パターンを自動反映
primary_metric="rmse"
)
📚 参考文献
- [AutoML 時系列アルゴリズム(Prophet, ARIMA)の詳細]https://docs.databricks.com/ja/machine-learning/automl/how-automl-works.html#algorithms)
🏆 結果:MAPE 4.1% を達成
AutoMLから導出されたベストモデル「Prophet(1時間単位予測)」の実質的な有効性を検証するため、時系列予測のオーソドックスなベースライン手法であるSeasonal Naive - Weekly(週間季節性ナイーブ)モデルと、同一のテストセットを用いて比較を行いました。

結果として、AutoML(Prophet)モデルは単純なベースライン手法と比較して、誤差率(MAPE)を約半減させる予測性能を示しました。
💡 Seasonal Naiveとは?
正確に「1週間前の同時刻の実績値」をそのまま現在の予測値として用いるシンプルな手法です。
※ 事前検証として、1ヶ月前、1週間前、前日と同時間帯の実績値を用いるモデルをそれぞれ比較した結果、1週間前(Weekly)を参照する手法が最も高い性能を示したため、今回の比較対象として選定しています。
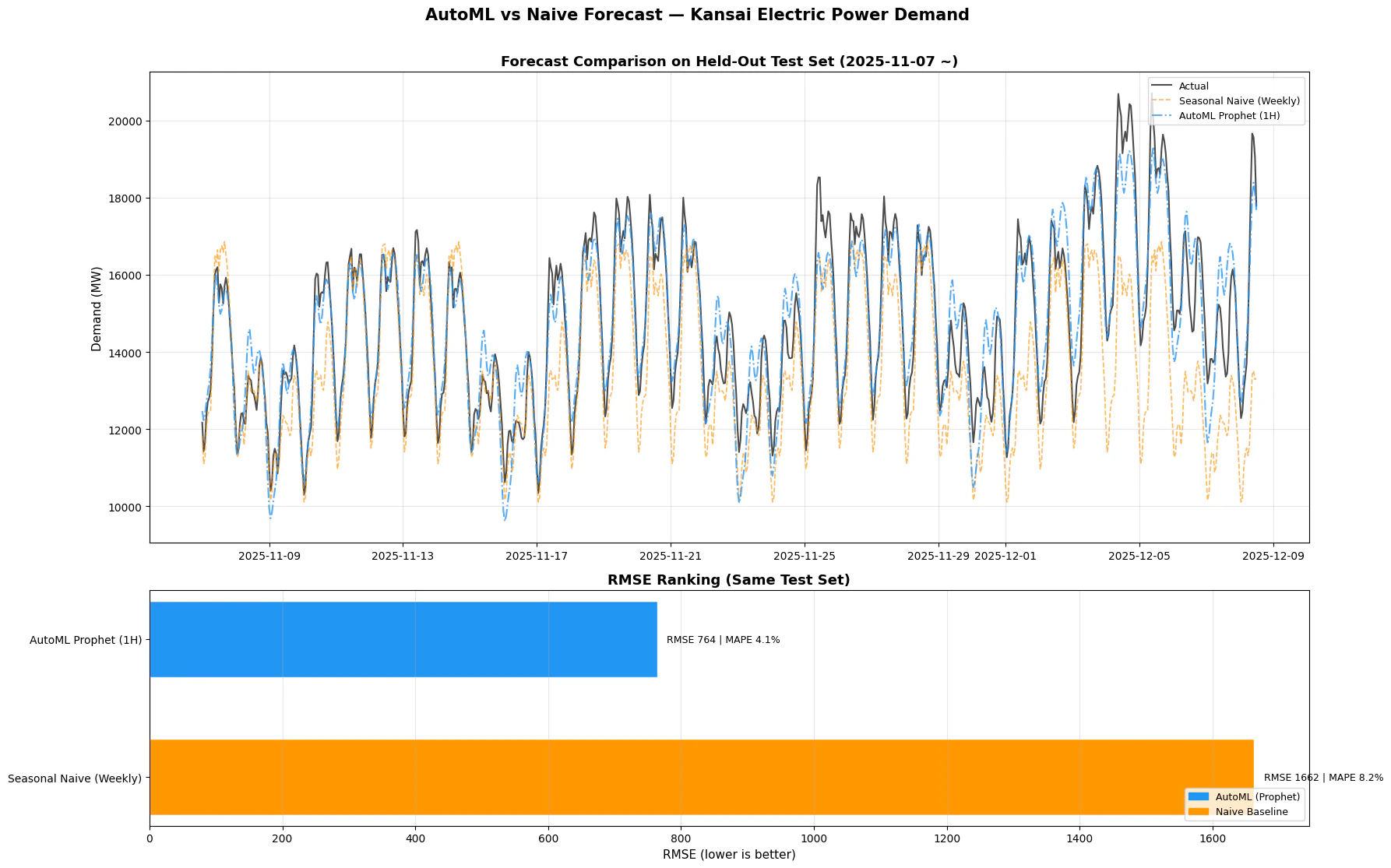
11月中旬までは平易な需要パターンが繰り返されており、2つのモデル間に大きな差はないように見えます。
しかし、11月下旬から12月上旬にかけて、気温の低下などの要因により電力需要の全体的な水準(トレンド)が急上昇する区間が発生します。この時、過去(1週間前)のデータのみを盲目的に追従するSeasonal Naiveモデルは、急激な需要の変化に全く追いつけず、継続的に過小予測(Under-prediction)を引き起こしてしまいます。
一方で、AutoML(Prophet)は、データに内在する長期的なトレンド(Trend)の変化と複合的な季節性(日次・週次パターン)を分離して学習しています。そのため、ベースラインモデルが追従できないような需要の急増区間においても、実績値(Actual)の軌跡をしっかりと捉えることができました。
MAPE(Mean Absolute Percentage Error, 平均絶対パーセント誤差)は、実績値に対して予測値が平均して何パーセントの誤差があるかを示す指標です。0%に近いほどモデルの精度が高いことを意味し、一般的に10%未満のMAPEは「精度の高い予測(Highly Accurate Forecasting)」であると評価されます。
[反転] 1ヶ月(720時間)予測で直面した「MAPE 20%」の罠
設定を変更し、予測期間(Horizon:24→720)を1ヶ月に延ばしたところ、誤差率(MAPE)が 20.35% まで急増しました。
短期予測(MAPE 4.1%)とは全く同じモデルを使用しているにもかかわらず、なぜこれほどまでの差が出るのでしょうか?
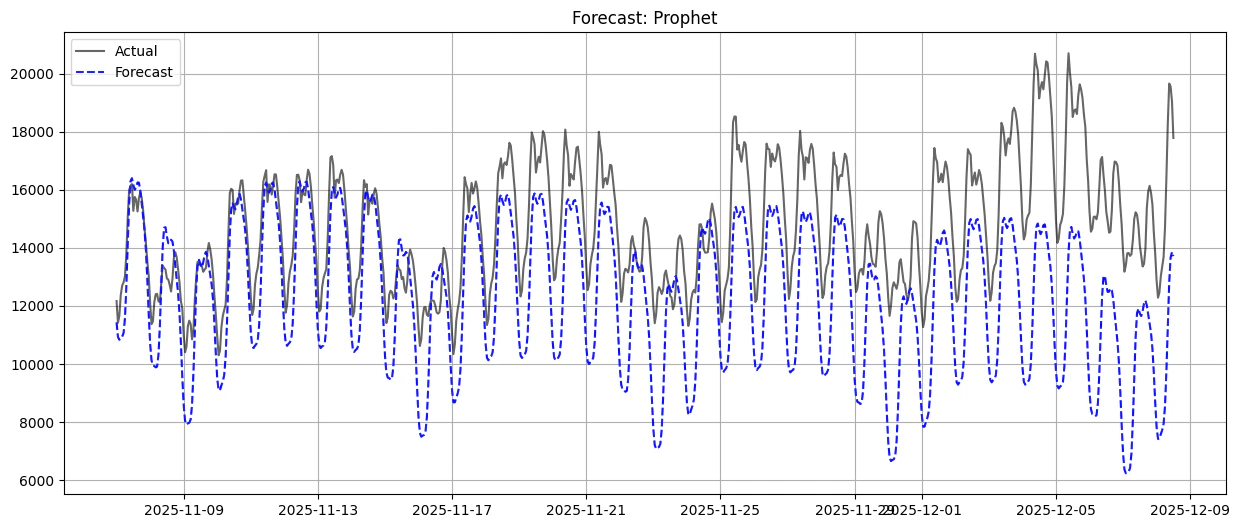
これは時系列予測において構造的な限界とモデル評価条件の違いが大きく影響したと考えています。
-
誤差の累積 (Recursive Drift)
短期予測は1時間ごとに実績値を見て軌道修正できましたが、1ヶ月予測は「目隠しで1ヶ月間走り続ける状態」です。直近の小さな予測ズレが、雪だるま式に蓄積して大きな誤差に膨れ上がります。 -
外部変数の欠如
1ヶ月先の電力需要は、過去のパターンよりも「その日の気温」に大きく依存します。気温などの外部変数を持たない単変量(Univariate)モデルでは、急な寒波などの天候変化に一切対応できません。 -
平均回帰
未来が遠く不確実になるほど、モデルは極端なピークを予測して外すリスクを避け、安全な「過去の平均的なトレンド」に収束しようとします。その結果、実際の需要スパイク(ピーク)を捉えきれず、過小評価してしまいます。
実務におけるエンジニアへの提言
-
Horizonの最適化:長期予測そのものを目的とするよりも、ビジネスの意思決定に本当に必要な最小限の期間に設定し、リトレーニングのサイクルを短く維持する方が有利だと考えられます。
-
信頼区間の活用:予測スコアの数値だけでなく、将来に向かって拡大していく信頼区間(Confidence Interval)も継続的にモニタリングし、不確実性を踏まえた運用を検討することが重要だと考えます。
-
多変量への拡張:特に1週間以上の長期予測を行う場合には、気温や湿度などの外生変数(Exogenous Variables)を取り入れた多変量モデルの設計が必要になると考えられます。
おわりに
今回の検証を通じて、Databricks AutoMLが短期予測において非常に高い精度(MAPE 4.1%)を発揮できる一方で、長期予測においては単変量モデルとしての限界があることを確認できました。
ここで強調したい点は、「Databricks AutoMLの真の価値」についてです。多くの自動化ツールが「ブラックボックス」であるのに対し、Databricks AutoMLは学習に使用されたソースコード(Python Notebook)をそのまま提供してくれる透過性を備えています。
-
効率的なベースラインの構築: ゼロからコーディングするのではなく、AutoMLが選定した「最良のモデル構造」をベースラインとして即座に活用できます。
-
エンジニアによる高度な最適化: 自動生成されたコードを基盤とし、エンジニアが自ら特徴量エンジニアリングや詳細なパラメータ調整を加えることで、モデルをさらに進化させることが可能です。
結論として、AutoMLはエンジニアを代替するものではありません。むしろ、エンジニアがより本質的な課題解決に集中できるよう導いてくれる「強力な副操縦士(Co-pilot)」であると確信しています。
次回の投稿では、今回の実験で見えた課題を打破するため、気象データを結合した「多変量(Multivariate)時系列予測への挑戦」について共有したいと思います!